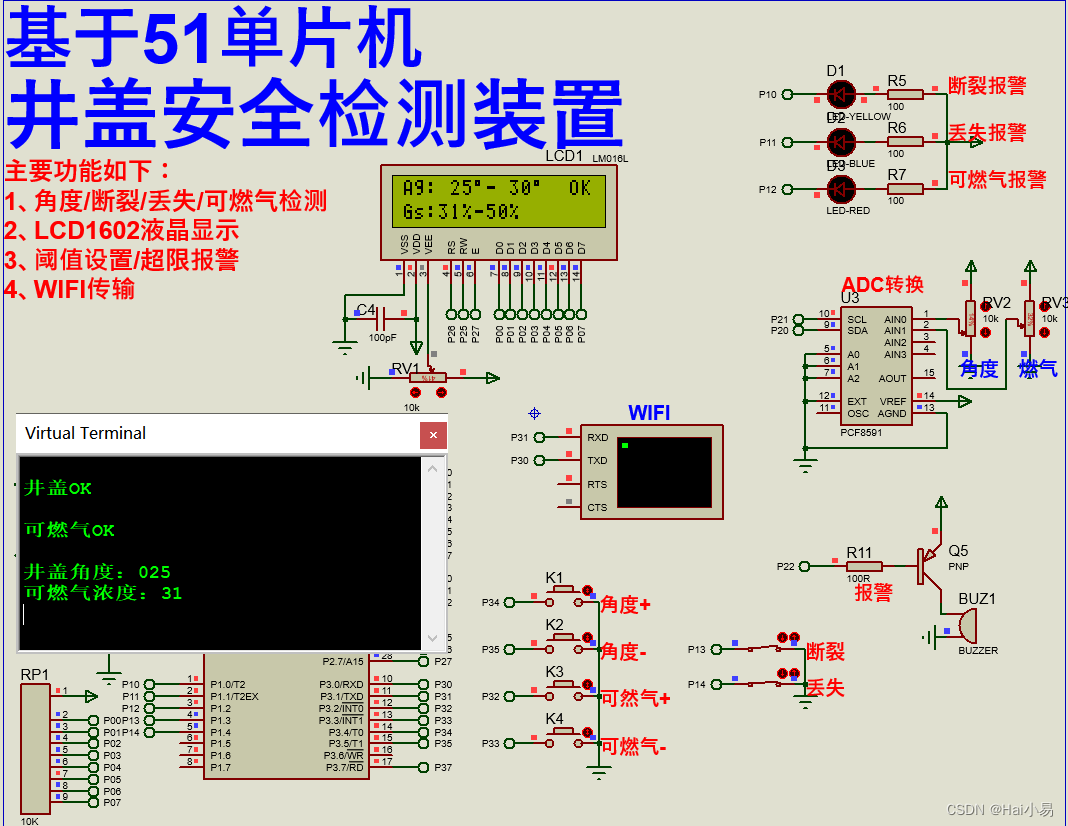
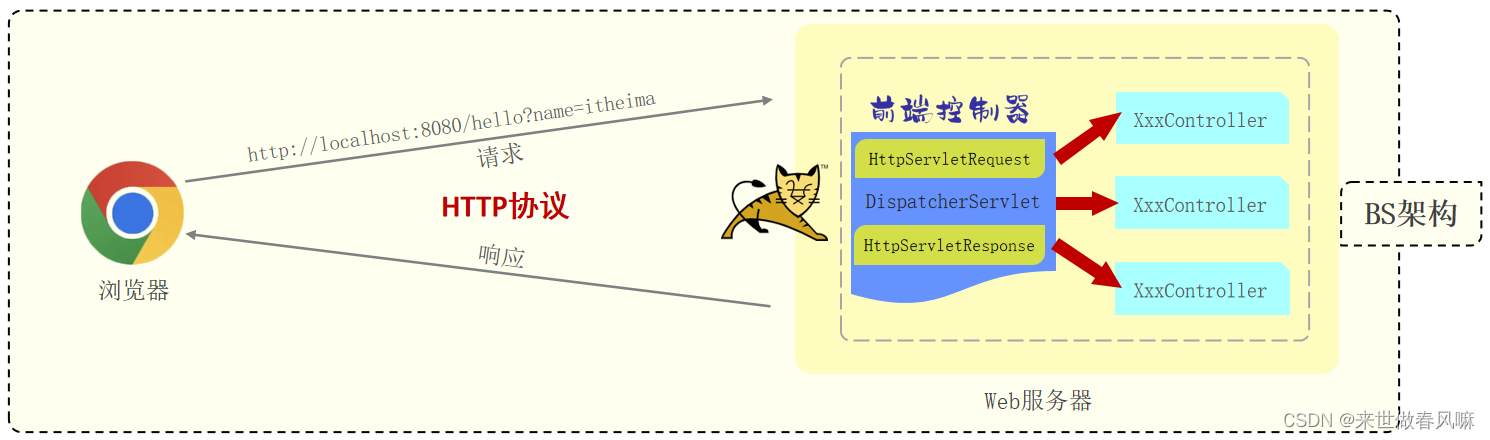
TL;DR
总结:如果你的A、B矩阵都是以行优先的方式去存的,最终想得到行优先的结果矩阵C,那么请放心使用cuBLAS(虽然它要求我们以列优先格式存储),但要注意参数的填写!!!。在使用cuBLAS相关函数时,只需:
m参数填写B矩阵的列数n参数填写A矩阵的行数k参数填写公共维度A参数填写B矩阵的指针lda填写B矩阵的列数B参数填写A矩阵的指针ldb填写A矩阵的列数ldc填写C矩阵的列数
最终写到地址C处的结果,就是行优先的结果矩阵C。
原理阐述
由于cuBLAS默认以列优先方式“理解”矩阵,而我们日常又习惯于以行优先方式来存储矩阵,这中间便存在了一些弯,比较难绕。花了点时间整理了一下,供参考。
理解的关键点如下:
第一点:理解如下三者的关系:数学上的矩阵表示 ⇔ \Leftrightarrow ⇔矩阵在主存上的存储方式 ⇔ \Leftrightarrow ⇔程序眼中的数学上的矩阵;
第二点:cuBLAS一律以列优先方式输出矩阵C。
贴出一篇神中神的文章供参考:【代码分析】cublasSgemm 矩阵乘法详解-CSDN博客
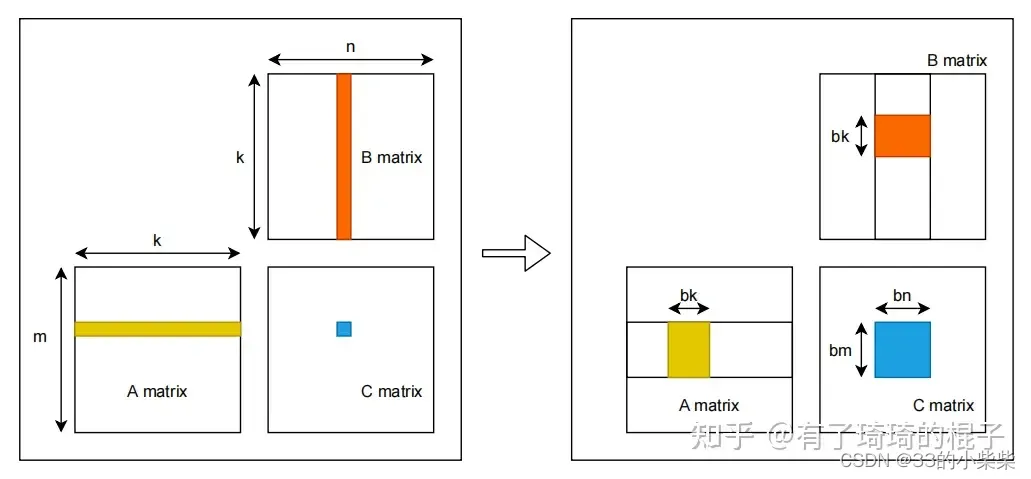
假设我们想做: A × B = C ( A ∈ R m × k , B ∈ R k × n ) \mathrm{A} \times \mathrm{B}=\mathrm{C}\left(\mathrm{A} \in \mathbb{R}^{m \times k}, \mathrm{~B} \in \mathbb{R}^{k \times n}\right) A×B=C(A∈Rm×k, B∈Rk×n)
这里我们给一个具体的例子,(对应上文注意点中的“数学上的矩阵表示”):
A = [ 5 3 7 6 0 5 ] , B = [ 1 5 3 0 1 5 2 9 9 4 9 7 ] \mathrm{A}=\left[\begin{array}{lll}5 & 3 & 7 \\ 6 & 0 & 5\end{array}\right], \mathrm{B}=\left[\begin{array}{llll}1 & 5 & 3 & 0 \\ 1 & 5 & 2 & 9 \\ 9 & 4 & 9 & 7\end{array}\right] A=[563075],B=
119554329097
然后,我们以行优先的形式对矩阵进行存储。所以数据在主存中以如下方式排放:(对应上文注意点中的“矩阵在主存上的存储方式”)
A矩阵在内存中是: [ 5 , 3 , 7 , 6 , 0 , 5 ] [5,3,7,6,0,5] [5,3,7,6,0,5]
B矩阵在内存中是: [ 1 , 5 , 3 , 0 , 1 , 5 , 2 , 9 , 9 , 4 , 9 , 7 ] [1,5,3,0,1,5,2,9,9,4,9,7] [1,5,3,0,1,5,2,9,9,4,9,7]
但是cuBLAS觉得内存中的数据是列优先的,所以cuBLAS认为这两块内存数据, 数学上是下面俩矩阵(对应上文注意点中的“程序眼中的数学上的矩阵”):
A = [ 5 6 3 0 7 5 ] , B = [ 1 1 9 5 5 4 3 2 9 0 9 7 ] \mathcal{A}=\left[\begin{array}{ll}5 & 6 \\ 3 & 0 \\ 7 & 5\end{array}\right], \mathcal{B}=\left[\begin{array}{lll}1 & 1 & 9 \\ 5 & 5 & 4 \\ 3 & 2 & 9 \\ 0 & 9 & 7\end{array}\right] A=
537605
,B=
153015299497
可以看到,cuBLAS眼中的两个矩阵和我们想的A、B矩阵不一样,但好在我们注意到 A = A T , B = B T \mathcal{A}=\mathrm{A}^{T}, \mathcal{B}=\mathrm{B}^{T} A=AT,B=BT。
回到主问题: 想做: A × B = C ( A ∈ R m × k , B ∈ R k × n ) \mathrm{A} \times \mathrm{B}=\mathrm{C}\left(\mathrm{A} \in \mathbb{R}^{m \times k}, \mathrm{~B} \in \mathbb{R}^{k \times n}\right) A×B=C(A∈Rm×k, B∈Rk×n)
以cuBLAS的视角, 它只知道 A , B \mathcal{A}, \mathcal{B} A,B, 那就尽量凑一凑呗
C T = ( A × B ) T = B T × A T = B × A \mathrm{C}^{T}=(\mathrm{A} \times \mathrm{B})^{T}=\mathrm{B}^{T} \times \mathrm{A}^{T}=\mathcal{B} \times \mathcal{A} CT=(A×B)T=BT×AT=B×A
也就是说, B × A \mathcal{B} \times \mathcal{A} B×A 可以得到原本 A × B \mathrm{A} \times \mathrm{B} A×B 的转置 C T \mathrm{C}^{T} CT
B × A = [ 1 1 9 5 5 4 3 2 9 0 9 7 ] × [ 5 6 3 0 7 5 ] = [ 71 51 68 50 84 63 76 35 ] \mathcal{B} \times \mathcal{A}=\left[\begin{array}{lll} 1 & 1 & 9 \\ 5 & 5 & 4 \\ 3 & 2 & 9 \\ 0 & 9 & 7 \end{array}\right] \times\left[\begin{array}{ll} 5 & 6 \\ 3 & 0 \\ 7 & 5 \end{array}\right]=\left[\begin{array}{ll} 71 & 51 \\ 68 & 50 \\ 84 & 63 \\ 76 & 35 \end{array}\right] B×A=
153015299497
×
537605
=
7168847651506335
下面是最精彩的环节, 也是很多资料没有提及的。cuBLAS在写回矩阵C时, 采用的也是列优先的方式!
所以结果矩阵在内存中是这么存的:
r e s u l t = [ 71 , 68 , 84 , 76 , 51 , 50 , 63 , 35 ] result =[71,68,84,76,51,50,63,35] result=[71,68,84,76,51,50,63,35]
此时, 若我们使用行优先的方式去读、去看待这块数据,
便得到:
[ 71 68 84 76 51 50 63 35 ] \left[\begin{array}{llll}71 & 68 & 84 & 76 \\ 51 & 50 & 63 & 35\end{array}\right] [7151685084637635]
而这,恰恰是我们想要的 A × B = C \mathrm{A} \times \mathrm{B}=\mathrm{C} A×B=C当中的 行优先的 C \mathrm{C} C。
总结:如果你的A、B矩阵都是以行优先的方式去存的,最终想得到行优先的结果矩阵C,那么请放心使用cuBLAS(虽然它要求我们以列优先格式存储)。在使用cuBLAS相关函数时,只需:m参数填写B矩阵的列数、n参数填写A矩阵的行数、k参数填写公共维度;A参数填写B矩阵的指针、lda填写B矩阵的列数、B参数填写A矩阵的指针,ldb填写A矩阵的列数,ldc填写C矩阵的列数即可。
参考代码
参考代码来自https://www.cnblogs.com/tiandsp/p/9463396.html,感谢原作者的分享!
原作者写的代码是 A ∈ R m × n , B ∈ R n × k A\in\mathbb{R}^{m\times n},B\in\mathbb{R}^{n\times k} A∈Rm×n,B∈Rn×k,但咱们平常在表示时,通常是将K作为公共维度。我做了些许更改。
//Source code from:https://www.cnblogs.com/tiandsp/p/9463396.html
#include "cuda_runtime.h"
#include "cublas_v2.h"
#include <stdio.h>
#include <stdlib.h>
#include <iostream>
#include <ctime>
using namespace std;
int main()
{
srand(time(0));
int M = 2; //矩阵A的行,矩阵C的行
int K = 3; //矩阵A的列,矩阵B的行
int N = 4; //矩阵B的列,矩阵C的列
float *h_A = (float*)malloc(sizeof(float)*M*K);
float *h_B = (float*)malloc(sizeof(float)*K*N);
float *h_C = (float*)malloc(sizeof(float)*M*N);
for (int i = 0; i < M*K; i++)
{
h_A[i] = rand() % 10;
cout << h_A[i] << " ";
if ((i + 1) % K == 0)
cout << endl;
}
cout << endl;
for (int i = 0; i < K*N; i++)
{
h_B[i] = rand() % 10;
cout << h_B[i] << " ";
if ((i + 1) % N == 0)
cout << endl;
}
cout << endl;
float *d_A, *d_B, *d_C,*d_CT;
cudaMalloc((void**)&d_A, sizeof(float)*M*K);
cudaMalloc((void**)&d_B, sizeof(float)*K*N);
cudaMalloc((void**)&d_C, sizeof(float)*M*N);
cudaMemcpy(d_A, h_A, M*K * sizeof(float), cudaMemcpyHostToDevice);
cudaMemcpy(d_B, h_B, K*N * sizeof(float), cudaMemcpyHostToDevice);
float alpha = 1;
float beta = 0;
//C=A*B
cublasHandle_t handle;
cublasCreate(&handle);
cublasSgemm(handle,
CUBLAS_OP_N,
CUBLAS_OP_N,
N, //矩阵B的列数
M, //矩阵A的行数
K, //公共维度
&alpha,
d_B, //矩阵B的指针
N, //矩阵B实际上以行优先存储,所以主维度为列数
d_A, //矩阵A的指针
K, //矩阵A实际上以行优先存储,所以主维度为列数
&beta,
d_C,
N);
cudaMemcpy(h_C, d_C, M*N * sizeof(float), cudaMemcpyDeviceToHost);
for (int i = 0; i < M*N; i++)
{
cout << h_C[i] << " ";
if ((i+1)%N==0)
cout << endl;
}
cudaFree(d_A);
cudaFree(d_B);
cudaFree(d_C);
free(h_A);
free(h_B);
free(h_C);
return 0;
}
关于lda与ldb
Ref:Leading Dimension及cublasgemm参数理解 - 知乎 (zhihu.com)
In a row-major format, consecutive elements of each row are stored in contiguous memory locations, and the row is called the leading dimension of the matrix. In a column-major format, consecutive elements of each column are stored in contiguous memory locations and the column is called the leading dimension of the matrix.
行优先存储,则主维度(leading dimension)为行;主维度长度即为一行有多少元素(对于二维矩阵来说就是列数);
列优先存储,则主维度(leading dimension)为列;主维度长度即为一列有多少元素(对于二维矩阵来说就是行数);
为什么要有lda、ldb的概念呢?正如我们在对二维数组(假设是列优先存储)定位时,光有行号 i i i、列号 j j j不够,还要知道一列有多少个元素 e l e m elem elem,然后才能做定位( j × e l e m + i j\times elem + i j×elem+i)。有时,我们仅需对一个大矩阵中的子矩阵做运算,知道大矩阵一列有多少元素,才能准确的对子矩阵做定位。
在这篇笔记的环境下,咱们的矩阵都是以行优先去存储的。即便cuBLAS以列优先方式去理解,但是若要正确定位,是需要知道一行有多少个元素的。所以lda、ldb填写的都是列数(也就是一行有多少个元素)。



























![中间件 | RabbitMq - [AMQP 模型]](https://img-blog.csdnimg.cn/direct/01c09f995c1a4d17a8e384fbc40200da.png)