目录
摘要:
本文旨在为读者提供关于Python爬虫的全面了解。我们将探讨爬虫的基本概念,如何使用Python进行网页抓取,以及一些高级技巧和最佳实践。文章将结合实例代码,帮助读者更好地理解和应用Python爬虫技术。
第一章:Python爬虫基础
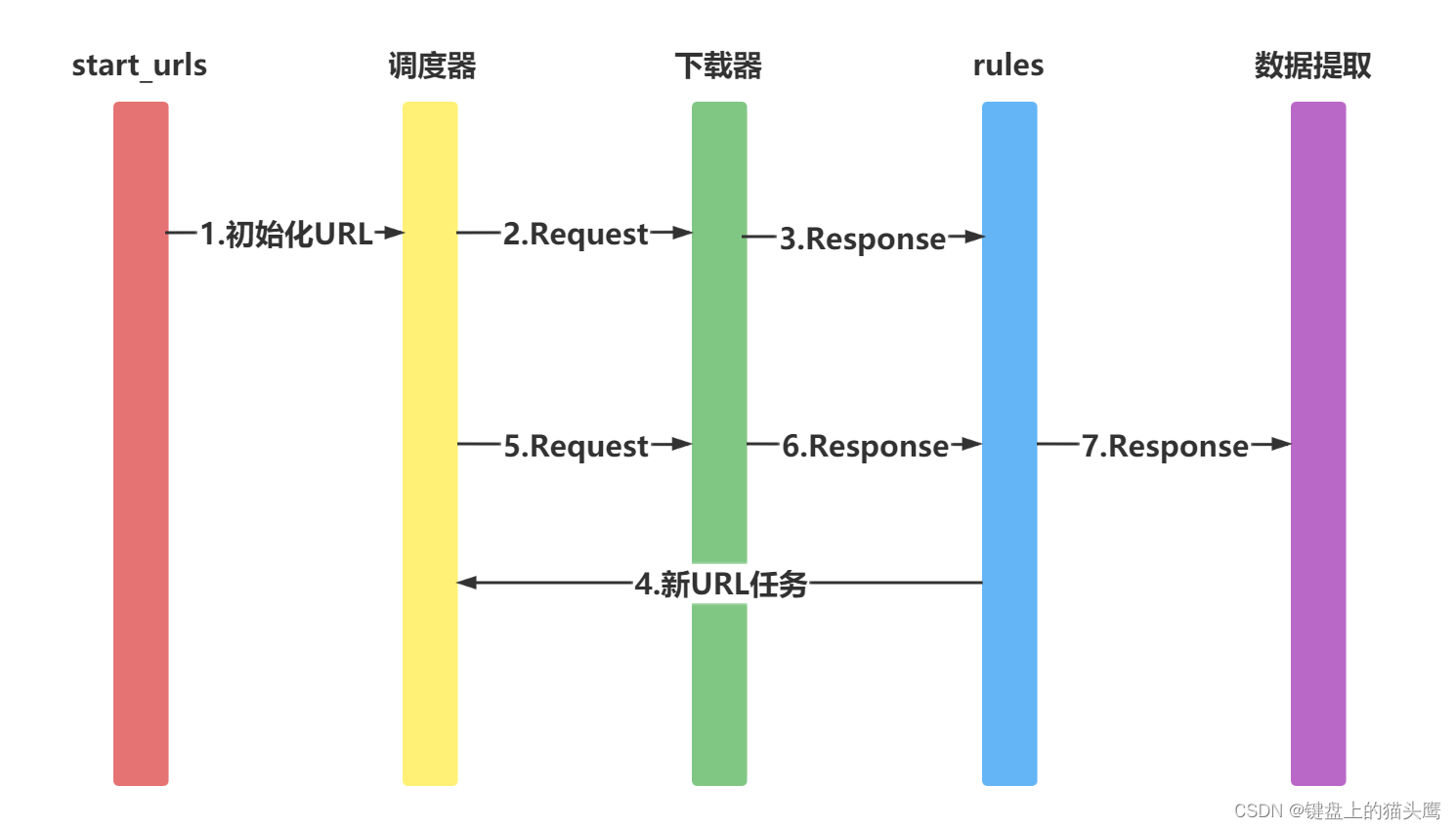
1. 爬虫的概念与作用
爬虫,也称为网络蜘蛛或网络机器人,是一种自动化获取网络上信息的程序。它可以在互联网上自动浏览网页,收集和整理数据。Python因其丰富的库和简洁的语法,成为了实现爬虫的首选语言。
2. Python爬虫库的介绍
Python有几个常用的库用于编写爬虫,包括requests用于发送HTTP请求,BeautifulSoup用于解析HTML和XML文档,以及Scrapy,一个强大的爬虫框架。这些库提供了便捷的方法来抓取和解析网页内容。
3. 第一个Python爬虫实例
让我们通过一个简单的例子来展示如何使用Python进行网页抓取。我们将使用requests和BeautifulSoup库来抓取一个网页,并提取其中的文本内容。
import requests
from bs4 import BeautifulSoup
# 发送HTTP请求
response = requests.get('http://example.com')
# 解析HTML内容
soup = BeautifulSoup(response.text, 'html.parser')
# 提取网页中的文本
text = soup.get_text()
print(text)
在这个例子中,我们首先使用requests库发送一个GET请求到指定的URL。然后,我们使用BeautifulSoup解析返回的HTML内容,并提取其中的文本。
技术总结:
通过本章,我们了解了Python爬虫的基础知识,包括爬虫的概念、Python爬虫库的介绍,以及一个简单的抓取网页内容的实例。接下来的章节将深入探讨更高级的爬虫技术,包括处理JavaScript渲染的页面、绕过反爬机制,以及爬虫的道德和法律问题。通过这些内容的学习,读者将能够熟练地使用Python进行网络数据抓取。
第二章:Python爬虫进阶技巧
1. 处理JavaScript渲染的页面
现代网页越来越多地使用JavaScript来动态加载内容,这对传统的爬虫方法提出了挑战。Python的Selenium库可以模拟浏览器行为,执行JavaScript代码,从而抓取动态内容。让我们通过一个例子来展示如何使用Selenium抓取动态加载的页面。
from selenium import webdriver
# 创建一个Selenium WebDriver实例
driver = webdriver.Chrome()
# 打开网页
driver.get('http://example.com/dynamic')
# 获取动态加载的内容
dynamic_content = driver.page_source
# 关闭浏览器
driver.quit()
# 使用BeautifulSoup解析动态内容
soup = BeautifulSoup(dynamic_content, 'html.parser')
text = soup.get_text()
print(text)
在这个例子中,我们使用webdriver.Chrome()创建了一个Chrome浏览器的实例,然后使用它打开网页并获取动态加载的内容。之后,我们关闭浏览器并使用BeautifulSoup解析这些内容。
2. 绕过反爬机制
一些网站会通过各种手段阻止爬虫访问,例如通过User-Agent检查、验证码、IP封禁等。为了绕过这些机制,我们可以定制请求头,使用代理IP,或者模拟用户行为。下面是一个设置User-Agent和使用代理的例子。
import requests
# 设置请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
}
# 使用代理
proxies = {
'http': 'http://10.10.1.10:3128',
'https': 'http://10.10.1.10:1080',
}
# 发送请求
response = requests.get('http://example.com', headers=headers, proxies=proxies)
在这个例子中,我们设置了请求头以模拟浏览器访问,并配置了代理以隐藏真实的IP地址。
3. 爬虫的道德和法律问题
在进行爬虫活动时,需要遵守相关的道德和法律规范。这包括尊重网站的robots.txt文件,不进行过于频繁的请求以免影响网站正常运营,以及遵守数据保护法规,不抓取和使用个人隐私数据。了解和遵守这些规范对于负责任的爬虫实践至关重要。
技术总结:
本章介绍了Python爬虫的一些进阶技巧,包括如何处理JavaScript渲染的页面,绕过反爬机制的方法,以及爬虫实践中需要遵守的道德和法律规范。通过这些内容的学习,读者可以更有效地进行网络数据抓取,同时确保其行为的合法性和道德性。在接下来的章节中,我们将探讨爬虫的高级应用,如数据存储和自动化处理。
第三章:Python爬虫的高级应用
1. 数据存储与持久化
抓取数据后,通常需要将其存储起来以供后续分析或处理。Python提供了多种数据存储方式,包括文件系统、数据库和云存储。下面是一些常见的数据存储方法的示例。
文件存储
import json
# 假设我们有一个数据列表
data = [{'name': 'Alice', 'age': 25}, {'name': 'Bob', 'age': 30}]
# 将数据存储为JSON文件
with open('data.json', 'w') as file:
json.dump(data, file)
数据库存储
使用SQLite数据库存储数据:
import sqlite3
# 连接到SQLite数据库
conn = sqlite3.connect('example.db')
cursor = conn.cursor()
# 创建一个表
cursor.execute('CREATE TABLE IF NOT EXISTS users (name TEXT, age INTEGER)')
# 插入数据
cursor.execute('INSERT INTO users (name, age) VALUES (?, ?)', ('Alice', 25))
# 提交事务
conn.commit()
# 关闭连接
conn.close()
2. 数据处理与自动化
抓取到的数据往往需要进一步处理。Python提供了强大的数据处理库,如Pandas和NumPy,可以进行数据分析、清洗和转换。此外,可以使用Python的自动化工具,如定时任务调度,来定期执行爬虫任务。
使用Pandas处理数据
import pandas as pd
# 假设我们有一个包含用户数据的DataFrame
df = pd.DataFrame(data)
# 对数据进行排序
df_sorted = df.sort_values(by='age', ascending=False)
# 打印排序后的数据
print(df_sorted)
定时任务调度
使用schedule库设置定时任务:
import schedule
import time
def job():
print("Running scheduled task...")
# 每隔10秒执行一次
schedule.every(10).seconds.do(job)
while True:
schedule.run_pending()
time.sleep(1)
3. 爬虫监控与优化
为了确保爬虫的稳定性和效率,监控和优化是必要的。可以通过日志记录、性能分析和异常处理来实现。Python的logging库提供了强大的日志记录功能,而性能分析工具如cProfile可以帮助识别瓶颈。
日志记录
import logging
# 配置日志
logging.basicConfig(filename='example.log', level=logging.DEBUG)
# 记录日志
logging.debug('This is a debug message')
logging.info('This is an info message')
技术总结:
本章探讨了Python爬虫的高级应用,包括数据存储与持久化、数据处理与自动化,以及爬虫监控与优化。通过这些高级技术的应用,读者可以构建更高效、稳定和自动化的爬虫系统。接下来的章节将探讨爬虫在特定领域的应用案例,如社交媒体分析、价格监控等,以及如何将这些技术应用于实际项目中。
第四章:Python爬虫在特定领域的应用案例
1. 社交媒体分析与监控
社交媒体平台如Twitter、Facebook和Instagram是大量用户生成内容的来源。Python爬虫可以用于监控这些平台上的话题趋势、分析用户行为或收集特定信息。例如,我们可以使用Tweepy库来分析Twitter数据。
社交媒体分析示例
使用Tweepy分析Twitter数据:
import tweepy
# 设置Tweepy
consumer_key = 'YOUR_CONSUMER_KEY'
consumer_secret = 'YOUR_CONSUMER_SECRET'
access_token = 'YOUR_ACCESS_TOKEN'
access_token_secret = 'YOUR_ACCESS_TOKEN_SECRET'
auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(access_token, access_token_secret)
api = tweepy.API(auth)
# 搜索Twitter上的特定话题
public_tweets = api.search('Python', lang='en', count=100)
# 分析和打印搜索结果
for tweet in public_tweets:
print(tweet.text)
2. 价格监控与比较
电子商务网站经常更新产品价格。使用Python爬虫,可以监控这些价格变化,进行价格比较或触发购买提醒。例如,我们可以编写一个爬虫来监控亚马逊上的商品价格。
价格监控示例
监控亚马逊上的商品价格:
import requests
from bs4 import BeautifulSoup
# 亚马逊商品页面URL
url = 'https://www.amazon.com/dp/B07V3NMDBW'
# 发送请求并获取页面内容
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
# 提取价格
price = soup.find(id='priceblock_ourprice').get_text()
print("Current Price:", price)
3. 实时新闻聚合
新闻网站经常更新内容。Python爬虫可以用于实时聚合新闻,创建个性化的新闻摘要。例如,我们可以使用Feedparser库来解析RSS订阅源,然后聚合最新的新闻标题。
实时新闻聚合示例
使用Feedparser聚合新闻:
import feedparser
# RSS订阅源URL
feed_url = 'http://feeds.bbci.co.uk/news/rss.xml'
# 解析订阅源
feed = feedparser.parse(feed_url)
# 打印最新的新闻标题
for entry in feed.entries[:5]:
print(entry.title)
技术总结:
本章通过具体的应用案例,展示了Python爬虫在社交媒体分析、价格监控和实时新闻聚合等领域的应用。这些案例不仅展示了Python爬虫的多样性和实用性,还提供了实际应用中可能遇到的问题和解决方案。接下来的章节将深入探讨如何将这些应用案例整合到更复杂的项目中,以及如何处理大规模数据抓取的挑战。
第五章:整合与扩展:Python爬虫在复杂项目中的应用
1. 集成多源数据抓取
在实际项目中,往往需要从多个来源抓取数据。这要求爬虫能够处理不同网站的结构和反爬策略。本节将展示如何集成多个数据源的数据抓取。
多源数据抓取示例
集成多个网站的数据抓取:
import requests
from bs4 import BeautifulSoup
# 抓取网站A的数据
response_a = requests.get('http://example.com/a')
soup_a = BeautifulSoup(response_a.text, 'html.parser')
data_a = soup_a.find_all('div', class_='data')
# 抓取网站B的数据
response_b = requests.get('http://example.com/b')
soup_b = BeautifulSoup(response_b.text, 'html.parser')
data_b = soup_b.find_all('div', class_='data')
# 整合数据
integrated_data = data_a + data_b
2. 分布式爬虫系统
对于大规模的数据抓取任务,单机爬虫可能不足以满足性能需求。分布式爬虫系统可以通过多台计算机并行工作来提高抓取效率。Scrapy框架支持分布式抓取,可以使用Scrapy-Redis等插件来实现。
分布式爬虫系统示例
使用Scrapy和Scrapy-Redis实现分布式爬虫:
# 安装Scrapy-Redis
# pip install scrapy-redis
# 配置Scrapy项目以使用Scrapy-Redis
# 在settings.py中添加以下配置
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
3. 大规模数据抓取的挑战与解决方案
大规模数据抓取面临许多挑战,包括性能瓶颈、IP封禁、数据存储和处理问题。本节将讨论这些挑战并提供解决方案。
大规模数据抓取挑战与解决方案
- 性能瓶颈:使用分布式系统,优化爬虫逻辑和数据库查询。
- IP封禁:使用代理池,合理设置请求间隔。
- 数据存储:使用高效的数据存储系统,如NoSQL数据库。
- 数据处理:使用流处理或批量处理技术。
技术总结:
本章聚焦于Python爬虫在复杂项目中的应用,包括集成多源数据抓取、构建分布式爬虫系统,以及处理大规模数据抓取的挑战。这些内容为读者提供了将Python爬虫技术应用于实际复杂场景的深入理解。接下来的章节将探讨如何维护和更新爬虫系统,以及如何确保长期项目的稳定性和可持续性。
总结:
通过本文的深入探讨,我们全面了解了Python爬虫的概念、技术和应用。从基础知识到进阶技巧,再到特定领域的应用案例,每一步都揭示了Python在数据抓取领域的强大能力和广泛应用。我们学习了如何使用Python库如requests、BeautifulSoup和Selenium进行网页抓取,处理JavaScript渲染的页面,以及绕过反爬机制。我们还探讨了如何存储抓取到的数据,使用Pandas和NumPy进行数据处理,以及如何构建和优化大规模分布式爬虫系统。
随着互联网数据的不断增长,Python爬虫成为了获取、分析和利用这些数据的重要工具。无论是在社交媒体分析、价格监控,还是新闻聚合等方面,Python爬虫都展现出了其强大的应用潜力。然而,我们也意识到在进行爬虫活动时需要遵守道德和法律规范,尊重网站的robots.txt文件,并保护用户隐私。
总之,Python爬虫不仅是一种技术,更是一种艺术。它要求我们不仅掌握编程技能,还需要理解网络工作原理、数据结构和算法,以及如何高效、合法地利用网络资源。随着技术的不断进步,Python爬虫将继续在数据科学和互联网技术领域扮演关键角色。























![高阶数据结构[2]图的初相识](https://img-blog.csdnimg.cn/direct/c4fda6629cc5432084fb59651eb3a82e.png)