Python爬虫完整代码模版——获取网页数据的艺术
在当今数字化世界中,数据是价值的源泉。如何从海量数据中提取所需信息,是每个数据科学家和开发者必须面对的问题。Python爬虫作为一种自动化工具,专门用于从网站上抓取数据。本文将提供一个Python爬虫的完整代码模板,并配以插图,帮助读者理解这个过程。
Python爬虫是一种用Python编写的程序,它能模拟人的行为,访问网站并提取出有价值的数据。通过爬虫,我们可以自动地、批量地获取所需的信息。
Python爬虫的基本步骤
- 导入必要的库:我们需要导入一些Python库,如requests(用于发送HTTP请求)、BeautifulSoup(用于解析HTML或XML文件)和selenium(用于模拟浏览器行为)。
- 发送HTTP请求:我们使用requests库发送HTTP请求到目标网站,获取网页内容。
- 解析网页内容:使用BeautifulSoup库解析HTML或XML文件,找到我们需要的数据。
- 数据提取:根据解析的结果,提取出我们所需的数据。
- 数据存储:将提取的数据存储到本地文件或数据库中。
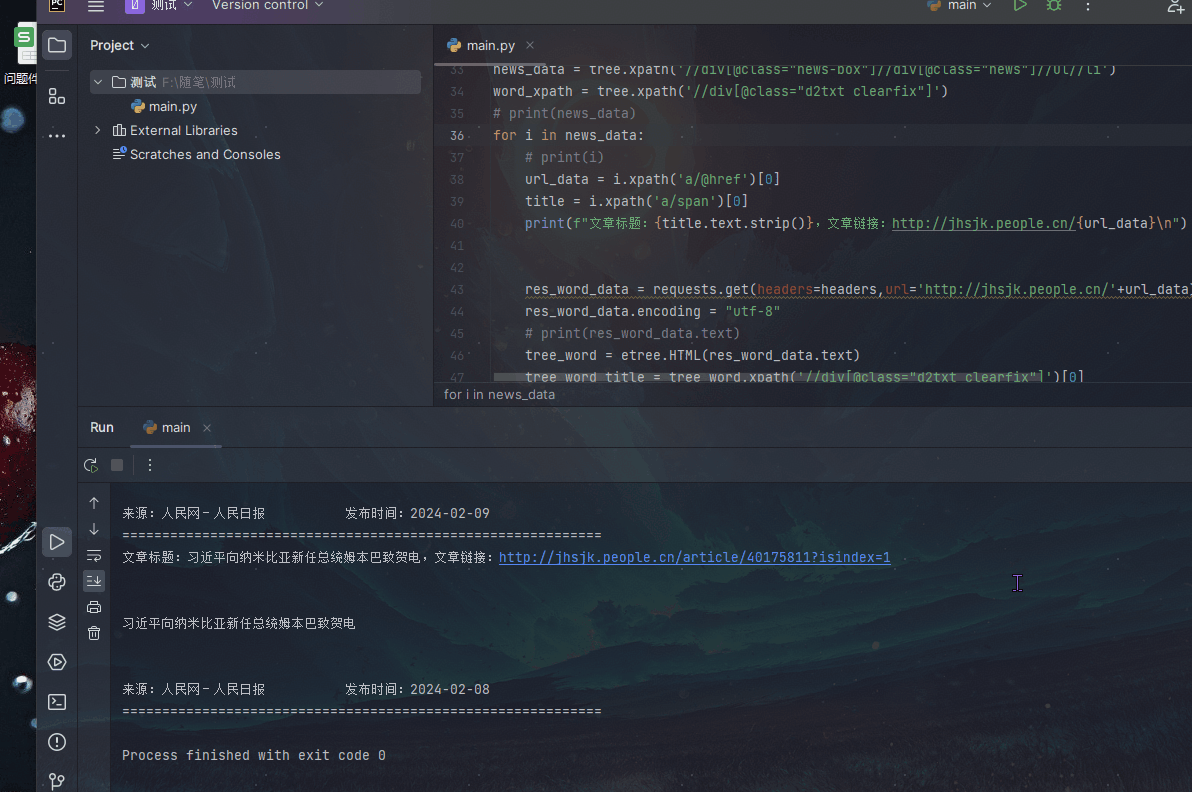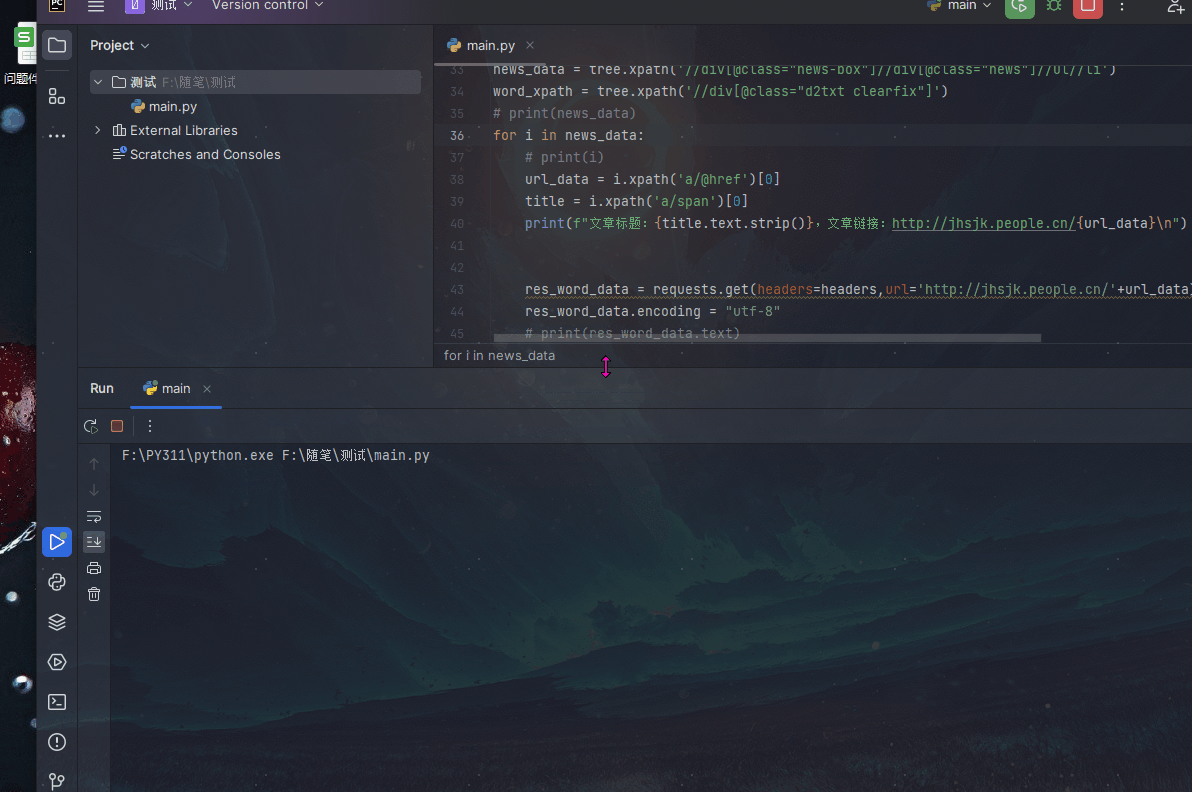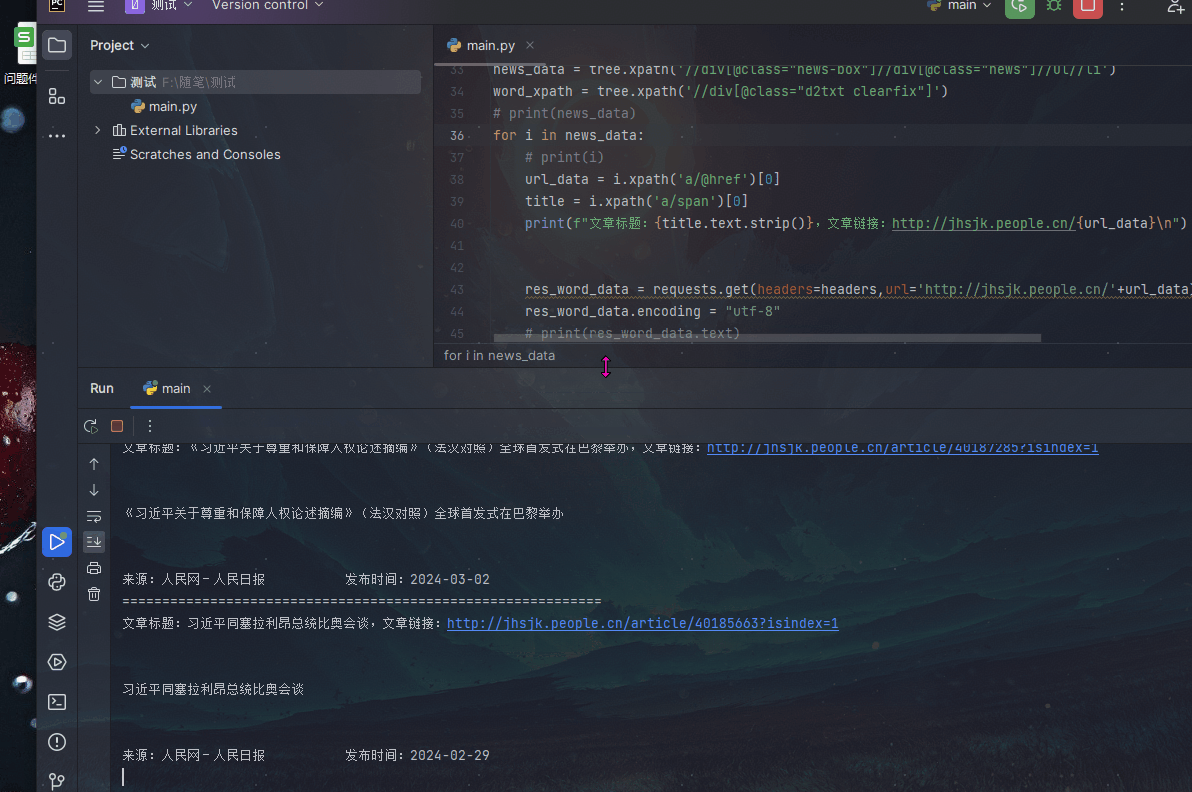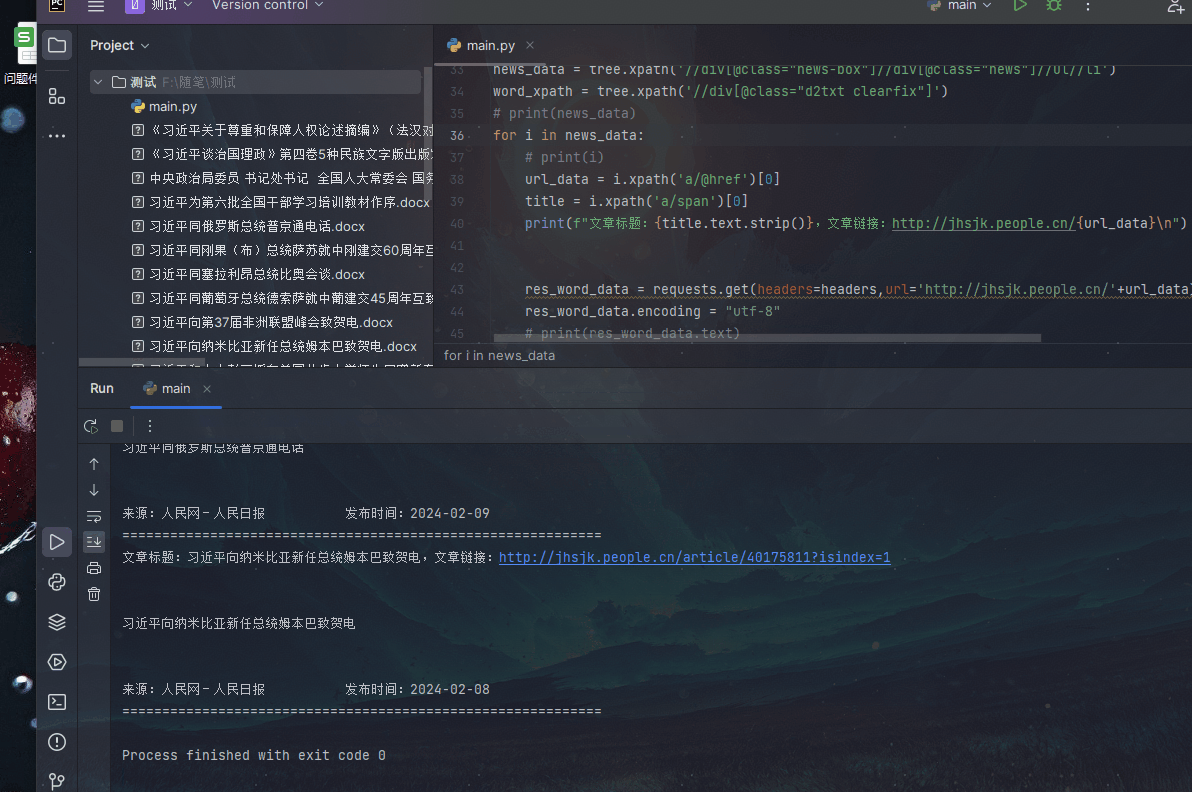
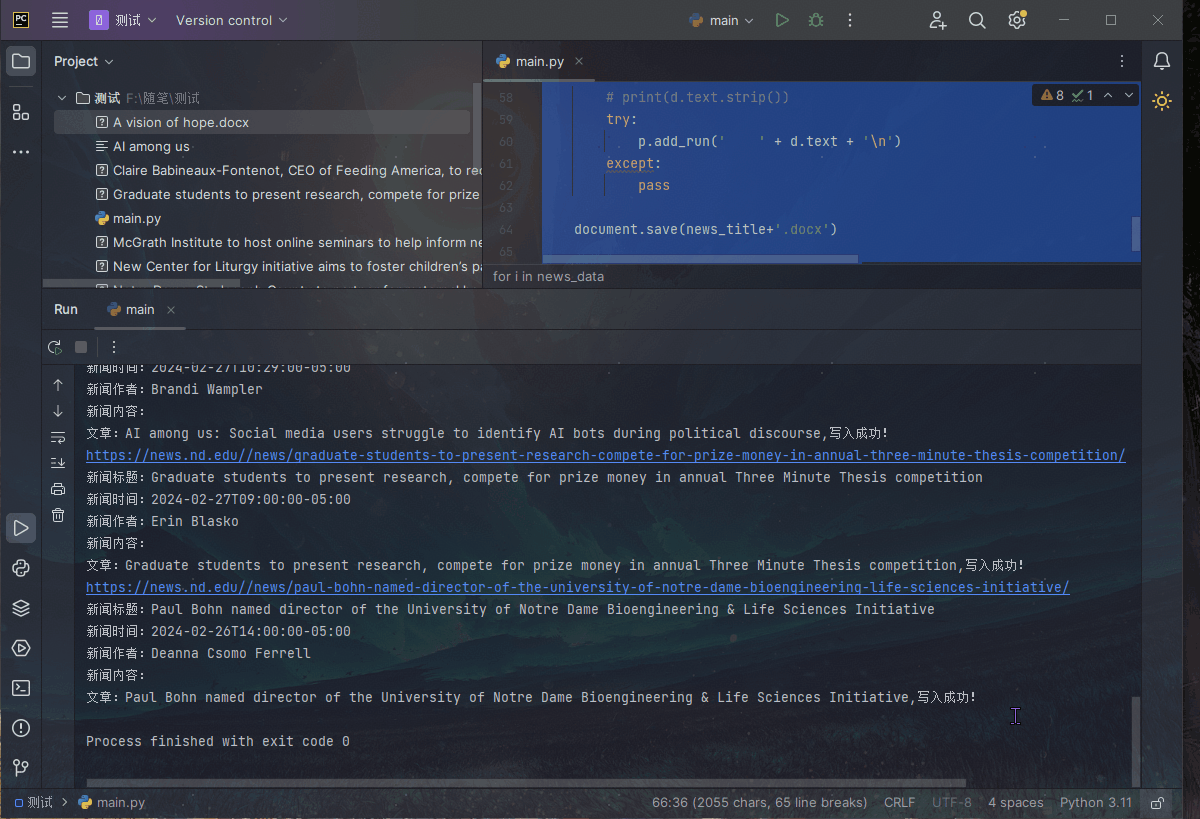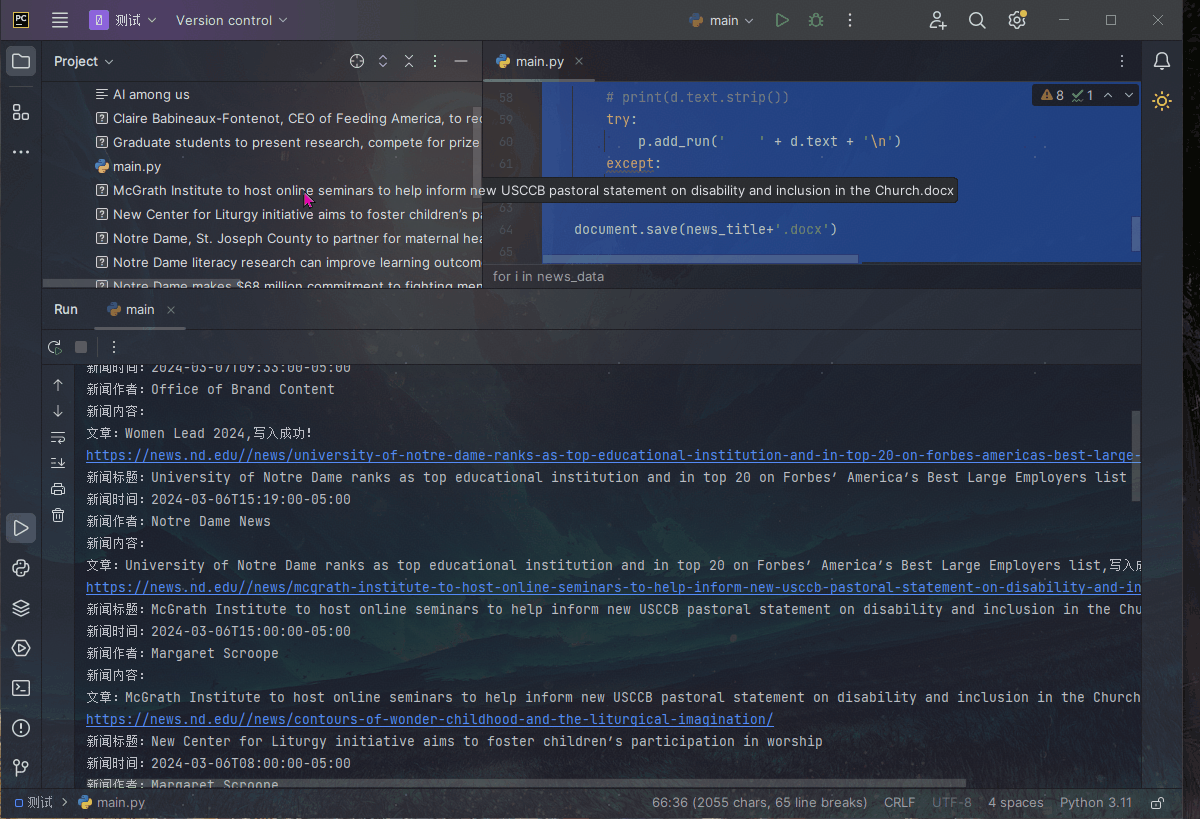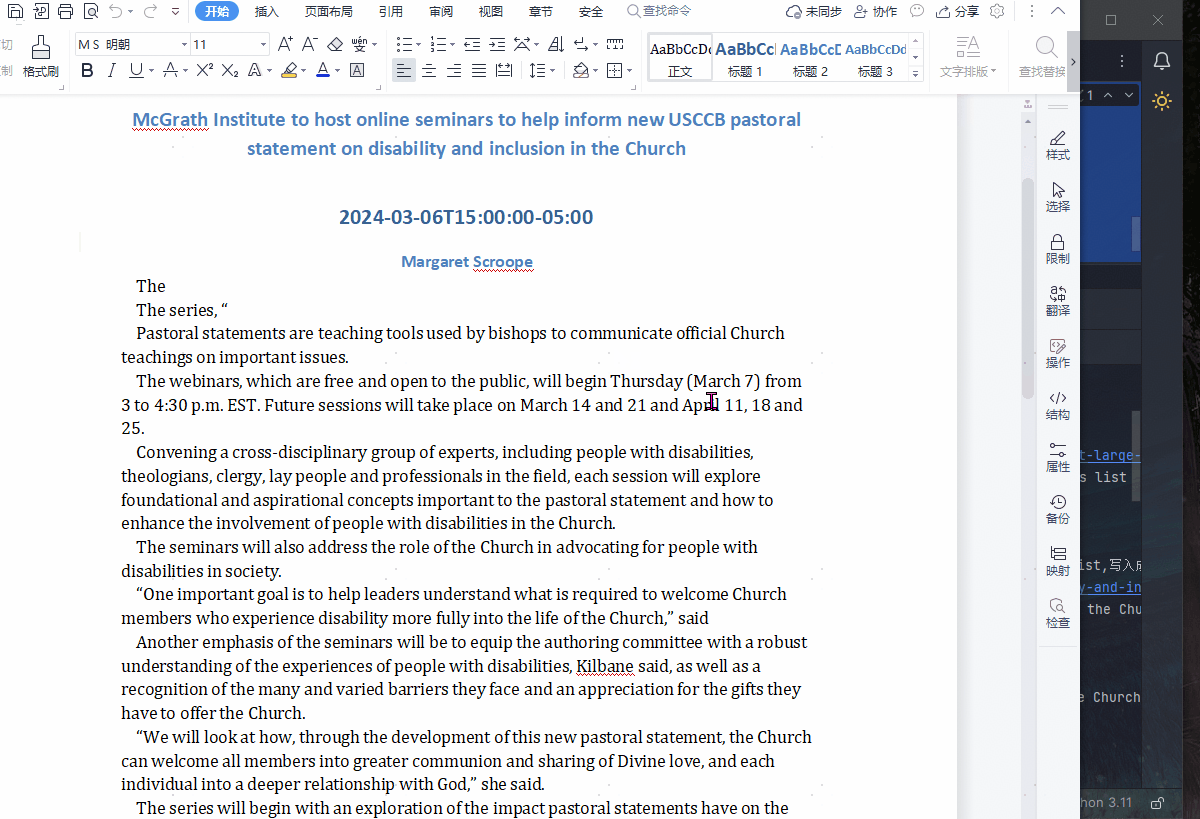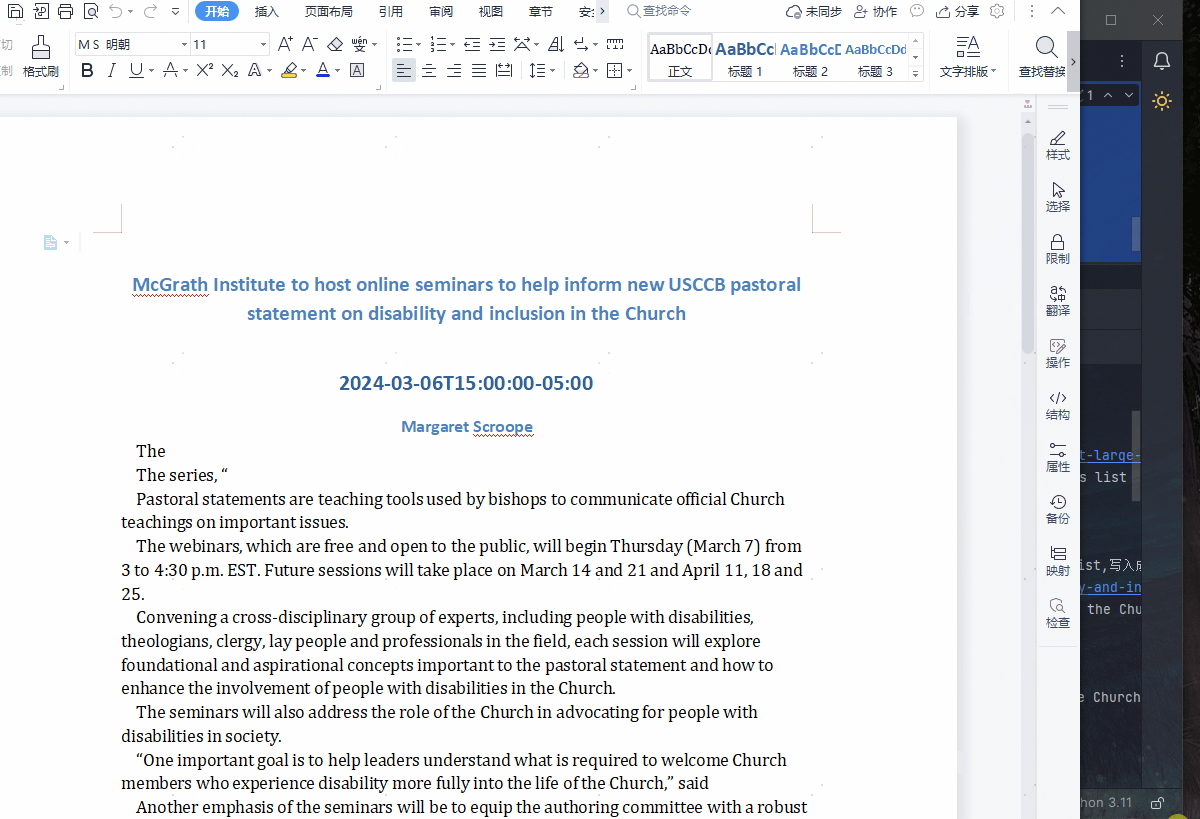
Python爬虫的完整代码模板
以下是一个基本的Python爬虫代码模板:
import requests |
|
from bs4 import BeautifulSoup |
|
from selenium import webdriver |
|
import time |
|
# 定义目标网站URL |
|
url = 'http://example.com' |
|
# 使用requests库发送GET请求 |
|
response = requests.get(url) |
|
# 使用BeautifulSoup库解析HTML文件 |
|
soup = BeautifulSoup(response.text, 'html.parser') |
|
# 定义数据提取的函数 |
|
def extract_data(html): |
|
# 在这里编写提取数据的代码,可以使用BeautifulSoup的方法进行解析和提取。 |
|
pass |
|
# 调用数据提取函数,提取所需数据 |
|
data = extract_data(soup) |
|
# 输出提取的数据 |
|
print(data) |
我们可以看到Python爬虫的工作流程。首先,爬虫通过发送请求获取网页内容。然后,使用BeautifulSoup库对网页内容进行解析,找到我们需要的数据。最后,将提取的数据存储到本地文件或数据库中。通过这个流程,我们可以自动化地获取大量有价值的数据。
Python爬虫是一种强大的工具,可以帮助我们自动化地获取大量数据。通过本文提供的代码模板和插图说明,我们可以了解到爬虫的基本步骤和实现方法。然而,值得注意的是,爬虫的使用必须遵守相关法律法规和网站的robots.txt协议,不得进行恶意攻击或侵犯他人隐私等行为。在合法合规的前提下,Python爬虫将成为我们获取数据的重要工具。