创意名称
墨香戏韵,重塑经典|基于AIGC对戏剧创新
创意概述
京剧作为中国传统戏曲之一,源远流长,承载了丰富的文化内涵和艺术特色。水墨画则是中国传统绘画的瑰宝,以其独特的墨色表达和极简的形式赢得了广泛的赞誉。我们的项目将这两种艺术形式巧妙地结合,通过技术手段将京剧人物与水墨画风格融合在一起,创造出令人惊艳的视觉效果,并以视频表演的形式展现出来,呈现独特的视觉和艺术效果,通过创新的技术手段和文化表达方式,弘扬传统文化、提高对京剧和水墨的认识,并增强大家对传统文化的自信心。
创意目标
- 利用现代技术手段将京剧人物和水墨画风格迁移应用于视频,创造出独特而美观的艺术作品。
- 弘扬传统文化,提高大众对京剧和水墨画的认识和兴趣。
- 创造与传统京剧形式不同的表演方式,吸引年轻观众,增添剧场魅力,促进传统艺术的活力。
创意源头
- 我之所以会选择这个主题来完成项目,这个想法更多的来源我日常的生活所见所感,戏剧与水墨是在爷爷的熏陶下了解的我爷爷可是个老戏迷平时也喜爱画画水墨画练练毛笔字,从小到大让我对戏剧与水墨画有着很大的兴趣,对戏剧与水墨画的文化特色有着深刻的认知和见解,所以我对水墨画和戏剧有着钟情的喜欢。在前不久在校园文化大厅闲逛的时候突然发现多了一个大四艺术学院毕业作品展览,我和朋友便走进去看看学长学姐们的作品,不看不知道一看直接被震撼到,那几十米长的墙上挂满了成千幅画,另我最震惊的便是那几十幅两米长的水墨山水画,我内心有说不出的震撼,原来不止有现代风格的画种令人惊艳,那一幅幅水墨山水画便是经典,但很多人看了只是浅浅的瞄了一眼便说单一,还有通过问卷调查发现很多人都觉得戏剧不好听,听不下去,这使我觉得传统文化随着时代的转变逐渐被没落,所以我们团队致力于使用AIGC技术让传统文化活起来。
大家可以看一下我做的调查问卷结果(这也正说明了戏曲创新的必要性):





创意亮点
- 京剧人物的风格迁移:我将利用风格迁移技术,将传统京剧人物的形象转化为水墨画风格,突出其线条和色彩的简洁美。
- 人物与视频的融合:我们将人物与实时视频融合,通过精确的大模型处理,使人物与背景和场景完美融合,创造出虚实相间的视觉效果。
- 唱戏艺术的创新表达:这种融合形式将使京剧人物在视频中能够更自由地展现不同的动作和表情,进一步增强唱戏的艺术表达力。
创作意义
- 这个创意的意义在于,它将传统文化与现代技术相结合,展现出传统与现代的完美融合。我们以京剧为基础,通过风格迁移和视频融合的创新手段,让这一古老艺术形式焕发出新的生机和活力。
- 我们希望通过这个创意项目,能够让更多的人了解和欣赏京剧这一传统艺术,并且吸引更多年轻观众。我们相信,跨界融合的艺术形式能够激发人们的好奇心和创造力,推动文化的创新和发展。
- 因为当代社会,随着现代化进程的推进,传统文化面临着被边缘化和遗忘的挑战,这是必然的趋势,很多年轻人对传统艺术形式的了解和兴趣不足,因为我们不止能一味的传承,所以我想为传统文化的弘扬与传承贡献自己的力量,需要有新的方式来吸引年轻人,让他们重新认识和喜爱传统文化。正如现如今众多人所做的将唢呐和DJ融合,将古筝和现代音乐融合,将戏剧结合现代流行音乐却又不失去其韵味,所以结合传统与现代的创新尝试:将京剧人物与水墨画风格相结合,是一种有创意的尝试,可以为传统文化注入新的活力,吸引更多年轻人的关注,将京剧人物的形象和水墨画的艺术元素融合在一起,创造出新的视觉体验。
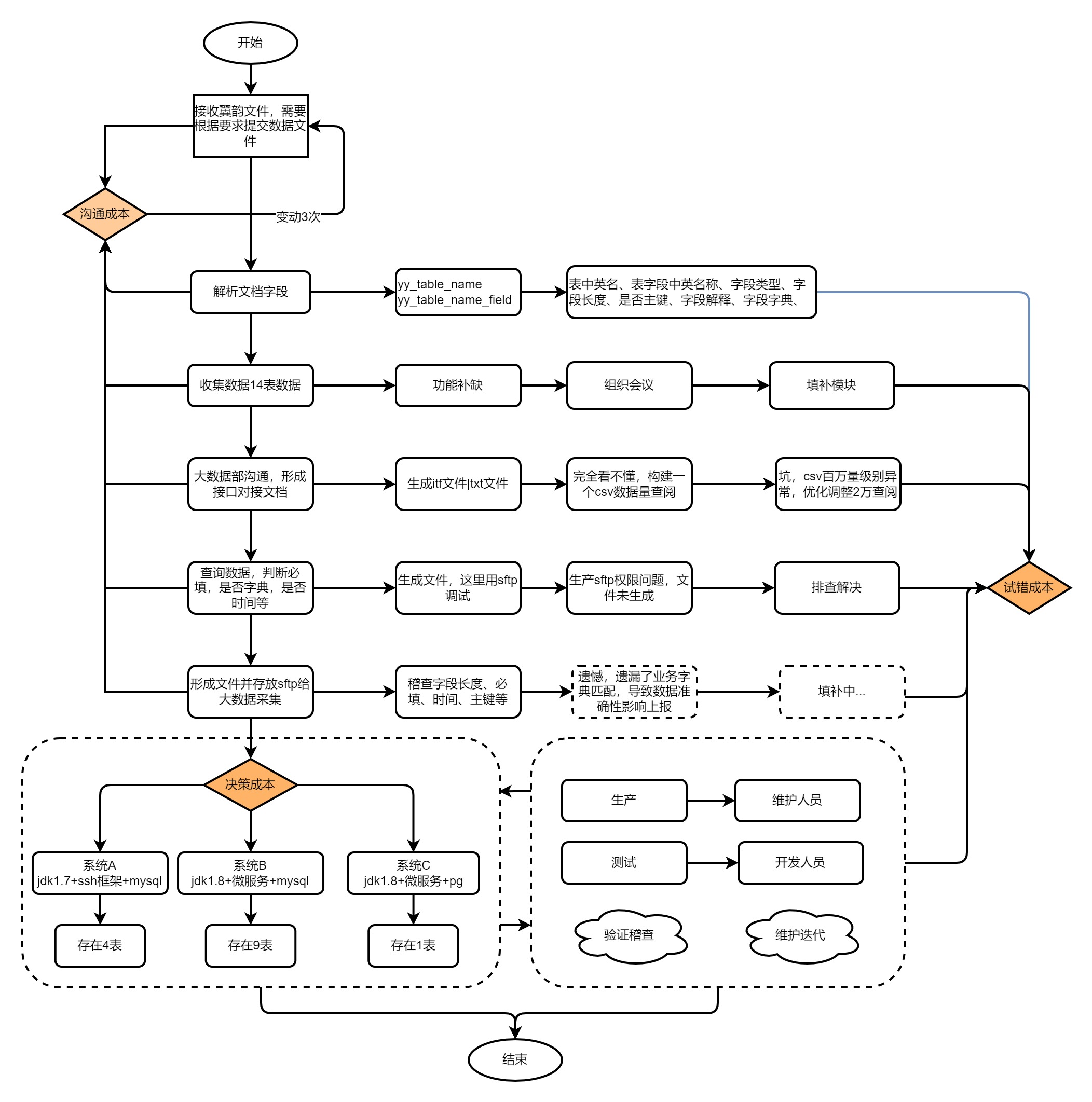
创意技术流程图

技术具体实现
第一步图像风格迁移
In [ ]
#安装paddlehub及其模型
!pip install paddlehub
# 下载模型
%%capture
!hub install stylepro_artistic==1.0.1In [4]
import paddlehub as hub
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
# 设置中文字体和编码
#plt.rcParams['font.sans-serif']=['Microsoft YaHei']
#输入源图片与风格图片
picture = '/home/aistudio/work/image_source.jpg'
style_image = '/home/aistudio/work/style.png'
#选择
stylepro_artistic = hub.Module(name="stylepro_artistic")
#使用Pillow库的convert方法将图像转换为RGB模式,以确保通道数始终为3,不然会报错因为输入图像和风格图像的通道数不匹配引起的。
#根据提示的错误信息,输入图像的通道数为4,而风格图像的通道数为3。风格迁移模型要求输入的图像通道数与风格图像的通道数一致。
content_image = Image.open(picture).convert('RGB')
style_image = Image.open(style_image).convert('RGB')
#因为风格迁移模型要求传递的是图像的数组。
# 将图像转换为NumPy数组
content_image = np.array(content_image)
style_image = np.array(style_image)
# 进行风格迁移
images = [
{
'content': content_image, # 内容图像
'styles': [style_image], # 风格图像
'weights': [0.3] # 风格图像的权重
}
]
result = stylepro_artistic.style_transfer(
images=images,
visualization=True
)
#result = stylepro_artistic.style_transfer(images=[{'content': content_image, 'styles': [style_image]}], visualization=True)
!mv ./transfer_result/* ./transfer_result.jpg
!rm -rf ./transfer_result
!mv ./transfer_result.jpg ./output/transfer_result.jpg
fig, axes = plt.subplots(1, 3, figsize=(12, 4))
# 图像文件路径
image_paths = [
'/home/aistudio/work/image_source.jpg',
'/home/aistudio/work/style.png',
'./output/transfer_result.jpg'
]
# 标题 (该处我尝试了给中文标题但是显示不出来,大家感兴趣可以自己研究研究#plt.rcParams['font.sans-serif']=['Microsoft YaHei'])
titles = [
'Original Image',
'Style Reference Image',
'Output Result'
]
for i, ax in enumerate(axes):
ax.set_title(titles[i])
ax.axis('off')
ax.imshow(plt.imread(image_paths[i]))
print("图片保存路径为/home/aistudio/output/transfer_result.jpg")
# plt.tight_layout()
# plt.show()
# plt.savefig('output/output.jpg')[2024-06-09 19:23:07,856] [ WARNING] - The _initialize method in HubModule will soon be deprecated, you can use the __init__() to handle the initialization of the object
Notice: an image has been proccessed and saved in path "/home/aistudio/transfer_result/ndarray_1717932199.3267796.jpg". 图片保存路径为/home/aistudio/output/transfer_result.jpg

<Figure size 1200x400 with 3 Axes>
风格迁移最终效果




第二步paddlegan实现京剧再现(两种方法)
方法一 First Order Motion model(结合面部和嘴型)
First Order Motion model的任务是image animation,给定一张源图片,给定一个驱动视频,生成一段视频,其中主角是源图片,动作是驱动视频中的动作,源图像通常包含一个主体,驱动视频包含一系列动作。
In [ ]
# 从github上克隆PaddleGAN代码
# 从github上克隆PaddleGAN代码(如下载速度过慢,可用gitee源)
!git clone https://gitee.com/paddlepaddle/PaddleGAN
#!git clone https://github.com/PaddlePaddle/PaddleGAN
# 安装所需安装包
%cd PaddleGAN/
!pip install -r requirements.txt
!pip install imageio-ffmpeg
!pip install ppgan执行命令
- driving_video: 驱动视频,视频中人物的表情动作作为待迁移的对象
- source_image: 原始图片,视频中人物的表情动作将迁移到该原始图片中的人物上\n
- relative: 指示程序中使用视频和图片中人物关键点的相对坐标还是绝对坐标,建议使用相对坐标,若使用绝对坐标,会导致迁移后人物扭曲变形
- adapt_scale: 根据关键点凸包自适应运动尺度
In [ ]
# 生成的结果保存的路径如下 ---> /home/aistudio/PaddleGAN/applications/output/result.mp4
%cd /home/aistudio/PaddleGAN/applications/
!mkdir output
!export PYTHONPATH=$PYTHONPATH:/home/aistudio/PaddleGAN && python -u tools/first-order-demo.py --driving_video ~/work/京剧.MP4 --source_image ~/work/京剧.png --relative --adapt_scale
print("生成的视频路径/home/aistudio/PaddleGAN/applications/output/result.mp4")In [ ]
#使用moviepy为生成的视频加上音乐
!pip install moviepyIn [ ]
#为生成的视频加上音乐 保存的路径为 ----> /home/aistudio/PaddleGAN/applications/output/京剧result.mp4
from moviepy.editor import *
# videoclip_1放入想要加入的音频视频文件后续会提取音频。
videoclip_1 = VideoFileClip("/home/aistudio/work/京剧.MP4")
# videoclip_2 放入上述生成的无声视频。
videoclip_2 = VideoFileClip("./output/result.mp4")
audio_1 = videoclip_1.audio
videoclip_3 = videoclip_2.set_audio(audio_1)
videoclip_3.write_videofile("./output/京剧result.mp4", audio_codec="aac")
print("添加音频后的视频路径为/home/aistudio/PaddleGAN/applications/output/京剧result.mp4")方法二 人物与视频融合(嘴唇动作迁移融合)
Wav2lip模型原理
- PaddleGAN的唇形迁移能力--Wav2lip
- Wav2Lip是一种用于语音合成和嘴唇同步的模型。它通过将语音和嘴部动作之间的联系进行建模,实现从声音到人脸图像的转换。
Wav2Lip的实现过程可以分为以下几个步骤:
声音特征提取:首先,Wav2Lip使用语音识别模型(如DeepSpeech)从输入的声音中提取出声音特征。这些特征描述声音的频谱和时域信息。
嘴部动作提取:接下来,Wav2Lip使用面部关键点检测器(如FaceMesh)从一段视频中提取嘴部动作的关键点位置。这些关键点描述了嘴唇的形状和运动。
嘴部动作对齐:为了将声音和嘴部动作进行关联,Wav2Lip使用一种嘴部动作对齐算法,在时间上对齐声音特征和嘴部动作。这样就能够确保声音和嘴部动作在时间上是同步的。
人脸图像生成:最后,Wav2Lip使用对抗生成网络(GAN)来生成与声音相匹配的人脸图像。GAN包括生成器和鉴别器两个部分。生成器接受声音特征和嘴部动作,并生成与之相匹配的人脸图像。鉴别器则尝试判断生成的人脸图像是否真实。通过生成器和鉴别器之间的博弈,Wav2Lip可以生成逼真的人脸图像。
总的来说,Wav2Lip利用语音和嘴部动作之间的联系,将声音特征与嘴部动作对齐,并使用生成对抗网络生成与声音相匹配的人脸图像。这种模型在实现语音合成和嘴唇同步方面具有较好的效果。
In [ ]
#face: 原始视频,视频中的人物的唇形将根据音频进行唇形合成--通俗来说,是你想让那个照片动起来。
#audio:驱动唇形合成的音频,视频中的人物将根据此音频进行唇形合成--通俗来说,想让这个人怎么说。
%cd /home/aistudio/PaddleGAN/applications/
!python tools/wav2lip.py \
--face /home/aistudio/43.jpeg \
--audio /home/aistudio/京剧.m4a\
--outfile /home/aistudio/output/pp_put.mp4 \
--face_enhancement
print("保存的路径为/home/aistudio/output/pp_put.mp4")