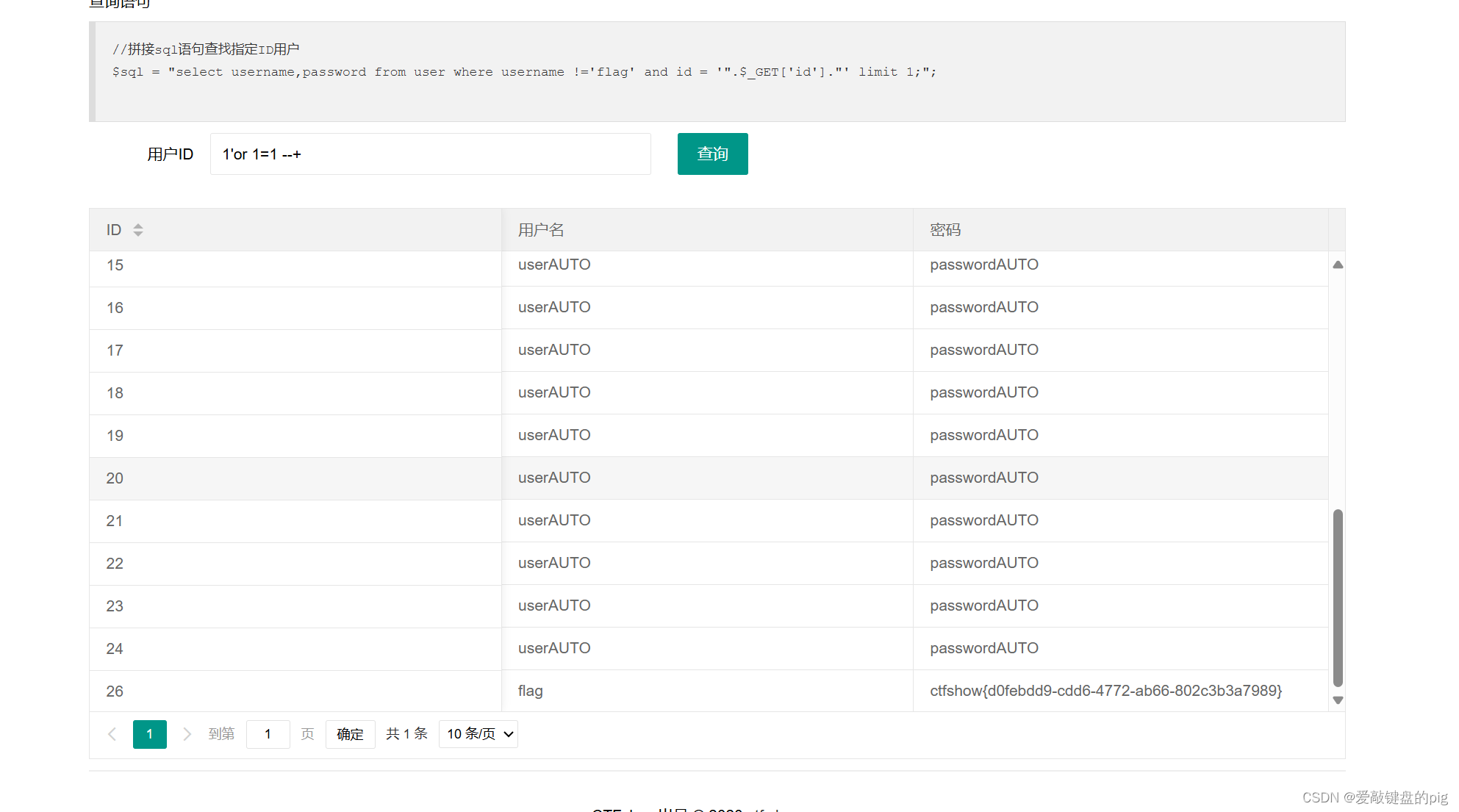
本文会细讲解基于PEFT(Parameter-Efficient Fine-Tuning)技术进行AI大模型微调的理论背景、技术细节和具体实现方法,特别是结合实际的应用案例来探讨如何优化模型性能以及如何评估和验证微调效果。
什么是PEFT?
PEFT(Parameter-Efficient Fine-Tuning)是一种微调大型预训练模型的方法,通过只调整一小部分参数(通常是模型的最后几层或者插入的特定层)来实现模型在特定任务上的优化。相较于传统的全面微调(Full Fine-Tuning),PEFT具有以下优势:
- 高效性:只需调整模型的一部分参数,计算资源需求大大降低。
- 灵活性:可以在不同任务之间快速切换,适应性强。
- 节省内存和存储:调整的参数少,节省了存储空间。
- 减少过拟合:只微调部分参数,可以减少在小数据集上过拟合的风险。
理论背景
参数效率和泛化能力
PEFT背后的核心思想是,神经网络的不同层次对不同任务的敏感性是不同的。通常来说,较低层次的特征表示具有更广泛的泛化能力,而高层次的特征表示则更具任务特异性。通过仅微调高层次的参数,我们可以在保持模型泛化能力的同时,提高模型在特定任务上的性能。
降低参数空间维度
通过只微调一小部分参数,PEFT有效地减少了参数空间的维度,这有助于避免模型在高维空间中搜索最优解时陷入局部最优。同时,这种方式也能显著减少计算成本,特别是对于大规模模型来说,优势更为明显。
PEFT的实现步骤
1. 环境准备和工具选择
确保环境配置正确,包括Python和相关深度学习框架(如PyTorch、TensorFlow等)。
pip install torch transformers peft
2. 选择和加载预训练模型
选择一个适合任务需求的预训练模型,例如,Hugging Face 提供了多种预训练模型,可以根据具体任务选择合适的模型。
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "gpt-3" # 替换为所选模型的名称
model = AutoModelForCausalLM.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
3. 定义微调策略
根据任务的需求和模型的架构,选择合适的微调策略。通常的做法是冻结大部分参数,只微调模型的部分层(如最后几层)。
# 冻结模型的大部分参数
for param in model.parameters():
param.requires_grad = False
# 解冻模型的最后几层
for param in model.transformer.h[-1].parameters():
param.requires_grad = True
4. 准备数据集
准备好特定任务的数据集,并进行适当的预处理。数据格式应与模型输入格式匹配。
data = [
{"input": "你好,今天的天气怎么样?", "target": "今天的天气很好,适合外出。"},
{"input": "请介绍一下你自己。", "target": "我是一个人工智能助手,可以回答各种问题。"},
# 添加更多数据
]
5. 定义损失函数和优化器
选择适当的损失函数和优化器,根据任务需要进行调整。
from torch.utils.data import DataLoader, Dataset
from torch.optim import AdamW
class CustomDataset(Dataset):
def __init__(self, data, tokenizer):
self.data = data
self.tokenizer = tokenizer
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
item = self.data[idx]
inputs = self.tokenizer(item["input"], return_tensors="pt")
targets = self.tokenizer(item["target"], return_tensors="pt")
return inputs, targets
dataset = CustomDataset(data, tokenizer)
dataloader = DataLoader(dataset, batch_size=2, shuffle=True)
optimizer = AdamW(filter(lambda p: p.requires_grad, model.parameters()), lr=5e-5)
6. 训练模型
使用PyTorch或其他深度学习框架,定义训练循环并进行训练。可以选择适当的训练轮次和学习率。
for epoch in range(3): # 根据需求调整训练轮次
for inputs, targets in dataloader:
outputs = model(**inputs, labels=targets["input_ids"])
loss = outputs.loss
loss.backward()
optimizer.step()
optimizer.zero_grad()
print(f"Loss: {loss.item()}")
7. 验证模型
在验证集或测试集上验证模型的性能,确保微调效果。
test_data = [
{"input": "今天天气如何?"},
{"input": "介绍一下你自己。"}
]
for item in test_data:
inputs = tokenizer(item["input"], return_tensors="pt")
outputs = model.generate(**inputs)
print(f"Input: {item['input']}")
print(f"Output: {tokenizer.decode(outputs[0], skip_special_tokens=True)}")
8. 保存和加载模型
保存微调后的模型以便未来使用或进一步优化。
model.save_pretrained("fine-tuned-model")
tokenizer.save_pretrained("fine-tuned-tokenizer")
# 加载模型
model = AutoModelForCausalLM.from_pretrained("fine-tuned-model")
tokenizer = AutoTokenizer.from_pretrained("fine-tuned-tokenizer")
PEFT方法的详细分类
部分层微调(Partial Layer Fine-Tuning)
选择模型的某些层(通常是最后几层)进行微调。这种方法保留了模型的底层特征表示,仅调整高层特征表示以适应新任务。
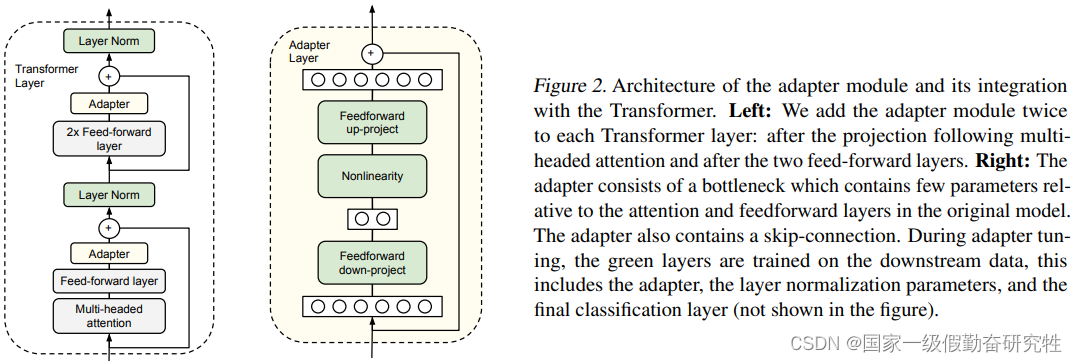
Adapter层(Adapter Layers)
在模型中插入适配层(Adapter),这些层通常是轻量级的、任务特定的,训练时只微调这些适配层的参数。
from transformers.adapters import AdapterConfig
# 添加和激活适配器
adapter_config = AdapterConfig.load("pfeiffer")
model.add_adapter("new-task", config=adapter_config)
model.train_adapter("new-task")
低秩分解(Low-Rank Decomposition)
通过矩阵分解的方法,只调整部分权重矩阵。这种方法通过低秩近似来减少参数数量和计算复杂度。
from torch import nn
class LowRankDecomposition(nn.Module):
def __init__(self, original_layer, rank):
super().__init__()
self.rank = rank
self.U = nn.Parameter(original_layer.weight.data[:, :rank])
self.V = nn.Parameter(original_layer.weight.data[:, rank:])
def forward(self, x):
return self.U @ self.V @ x
剪枝和量化(Pruning and Quantization)
通过剪枝减少不重要的参数,通过量化减少计算复杂度。
from torch.nn.utils import prune
# 剪枝
prune.l1_unstructured(model.layer[0], name="weight", amount=0.2)
# 量化
model.qconfig = torch.quantization.get_default_qconfig('fbgemm')
torch.quantization.prepare(model, inplace=True)
torch.quantization.convert(model, inplace=True)
评估和验证
性能评估
使用常见的指标(如准确率、F1分数等)来评估微调后的模型性能。特别需要关注模型的泛化能力,以确保在新数据集上的表现。
from sklearn.metrics import accuracy_score
def evaluate_model(model, test_data):
predictions = []
targets = []
for item in test_data:
inputs = tokenizer(item["input"], return_tensors="pt")
outputs = model.generate(**inputs)
prediction = tokenizer.decode(outputs[0], skip_special_tokens=True)
predictions.append(prediction)
targets.append(item["target"])
accuracy = accuracy_score(targets, predictions)
print(f"Accuracy: {accuracy}")
模型稳定性
评估模型的稳定性和鲁棒性,尤其是在不同的任务和数据分布下,确保模型的性能不会大幅波动。
内存和计算资源消耗
分析微调模型的内存和计算资源消耗,以确保优化后的模型可以在资源受限的环境下高效运行。
实际应用案例
应用案例:文本分类
在文本分类任务中,使用PEFT微调预训练的BERT模型,减少微调参数的数量以适应特定的分类任务。通过只调整BERT的高层参数,可以实现高效的模型优化,提升分类准确率。
应用案例:图像识别
在图像识别任务中,使用ResNet预训练模型,结合低秩分解方法进行PEFT,减少训练参数,显著提高模型的