😊你好,我是小航,一个正在变秃、变强的文艺倾年。
🔔本栏讲解【全栈实战】大模型自学:从入门到实战打怪升级。
🔔专栏持续更新,适合人群:本科生、研究生、大模型爱好者,期待与你一同探索、学习、进步,一起卷起来叭!
目录
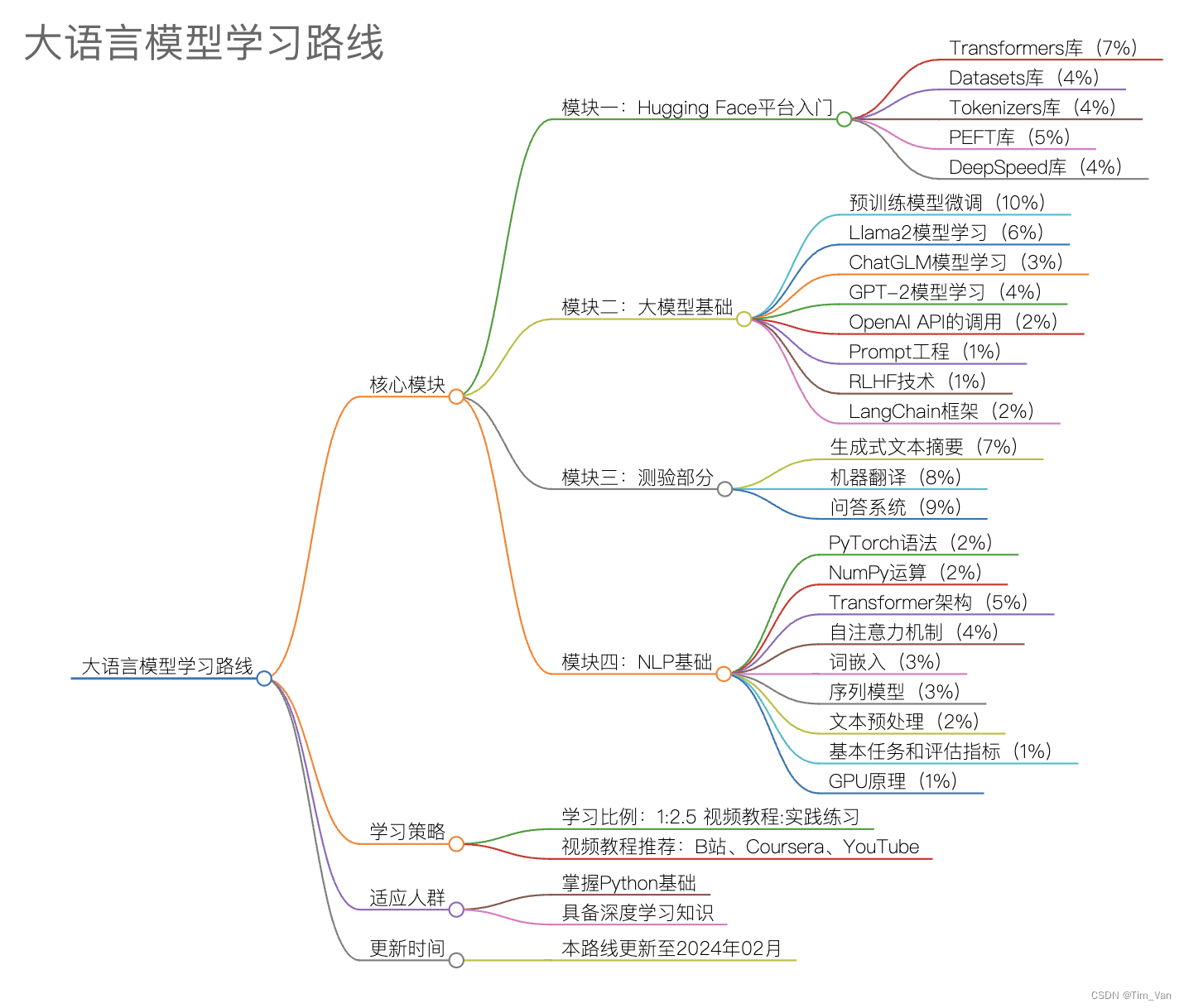
Python(第一周)
编辑器推荐:Prcharm、Vscode
🔗Python入门:菜鸟教程Python(一周) || 廖雪峰Python(一周)【学至内置模块即可】
🔗机器学习数学入门:《白话机器学习的数学》书籍(一周)【最后一章编程觉得困难可不看】

💡 Python历史版本大全,建议3.8+
💡 pip修改国内源:
# 临时换源:
# 清华源
pip install markdown -i https://pypi.tuna.tsinghua.edu.cn/simple
# 阿里源
pip install markdown -i https://mirrors.aliyun.com/pypi/simple/
# 腾讯源
pip install markdown -i http://mirrors.cloud.tencent.com/pypi/simple
# 豆瓣源
pip install markdown -i http://pypi.douban.com/simple/
# 永久换源:
# 清华源
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
# 阿里源
pip config set global.index-url https://mirrors.aliyun.com/pypi/simple/
# 腾讯源
pip config set global.index-url http://mirrors.cloud.tencent.com/pypi/simple
# 豆瓣源
pip config set global.index-url http://pypi.douban.com/simple/
# 换回默认源
pip config unset global.index-url
数据分析(第二周)
🔗数据分析三件套:numpy、pandas、matplotlib(一周)【基础用法跟着敲一遍即可】
🔗数据分析三件套:配套CSV文件,提取码:fbaz
💭 1、2、42节不听
💭 18集完了之后请跳到21集和22集,再返回19集
💭 听不懂就跟着敲代码,只掌握三件套即可,中间涉及到的爬虫、数据库不需要纠结
🔗数据分析三件套,现用现查:菜鸟教程Numpy、菜鸟教程Pandas、菜鸟教程Matplotlib
💡复盘:




人工智能基础原理(第三周)
🚩支线任务:🔗Numpy进阶练习:Numpy题库
🚩主线任务:
🔗人工智能原理速学(用于确定科研方向):小白也能听懂的人工智能原理
深度学习框架(第四周)
🚩主线任务:Pytorch【小白推荐】 || Tenserflow
🔗PyTorch深度学习快速入门教程(绝对通俗易懂!)【小土堆】
🔗Pytorch 下载官网:链接
🔗Pytorch 离线下载:链接
📜 注意事项:
1、使用国内源下载更快:anaconda 清华源

2、安装路径,这里不建议装在C盘,安装完大概3个G左右

3、Conda常用命令
#查询cuda版本
nvidia-smi
#查看当前环境的信息
conda info
#查看已经创建的所有虚拟环境
conda info -e
#切换到xx虚拟环境
conda activate xx
#切换环境
set CONDA_FORCE_32BIT=1 # 切换到32位
set CONDA_FORCE_32BIT=0 # 切换到64位
#创建一个python2.7 名为xxx的虚拟环境
conda create -n xxx python=2.7
#移除环境
conda remove -n env_name --all
#切换root环境
activate root
#删除环境钟的某个包
conda remove --name $your_env_name $package_name
#设置搜索时显示通道地址
conda config --set show_channel_urls yes
#恢复默认镜像
conda config --remove-key channels
#查找某包是否已经安装
conda list xxx #包的名称
#查询已安装包
pip list
4、Conda 虚拟环境envs目录为空
envs 在C:\Users\用户\.conda\envs

5、conda install nb_conda 安装失败
nb_conda -> python[version='>=2.7,<2.8.0a0|>=3.5,<3.6.0a0|>=3.8,<3.9.0a0|>=3.6,<3.7.0a0|>=3.7,<3.8.0a0']
# 如果python版本 >= 3.9
conda install nb_conda_kernels
# 启动命令
jupyter notebook
6、Pytroch(GPU版本)安装检查
python
>>> import torch
>>> torch.cuda.is_available()
>>> True
如果为Fasle,请检查下载版本(可能下载的是CPU版本)是否正确
机器学习(第五周)
推荐书籍:李航《统计学习方法》(第二版)、周志华《机器学习》【文件已附文末】

只需要掌握基础概念+对应方向前置知识即可,不需要深度掌握,书籍主要用于公式随用随查
深度学习(第六周)
李沐-动手学深度学习(花书)【文件已附文末】

入门测试(第七周)
🚩 该阶段主要用于复盘之前学过的知识点,并进行查漏补缺
机器学习:是一门专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能的学科。简单的说,就是“从样本中学习的智能程序”。
深度学习:深度学习的概念源于人工神经网络的研究,是机器学习研究中的一个新的领域,其动机在于建立、模拟人脑进行分析学习的神经网络,它模仿人脑的机制来解释数据,例如图像,声音和文本。不论是机器学习还是深度学习,都是通过对大量数据的学习,掌握数据背后的分布规律,进而对符合该分布的其他数据进行准确预测。

机器学习中典型任务类型:分类任务(Classification)和回归任务(Regression)。
- 分类任务:对
离散值进行预测,根据每个样本的值/特征预测该样本属于类型A、类型B还是类型C,例如情感分类、内容审核,相当于学习了一个分类边界(决策边界),用分类边界把不同类别的数据区分开来。 - 回归任务:对
连续值进行预测,根据每个样本的值/特征预测该样本的具体数值,例如房价预测,股票预测等,相当于学习到了这一组数据背后的分布,能够根据数据的输入预测该数据的取值。

分类任务 VS 回归任务:分类与回归的根本区别在于输出空间是否为一个度量空间。

- 对于分类问题,目的是
寻找决策边界,其输出空间B不是度量空间,即“定性”。也就是说,在分类问题中,只有分类“正确”与“错误”之分,至于分类到了类别A还是类别B,没有分别,都是错误数量+1。 - 对于回归问题,目的是
寻找最优拟合,其输出空间B是一个度量空间,即“定量”,通过度量空间衡量预测值与真实值之间的“误差大小”。当真实值为10,预测值为5时,误差为5,预测值为8时,误差为2。

机器学习分类:
- 有监督学习:监督学习
利用大量的标注数据来训练模型,对模型的预测值和数据的真实标签计算损失,然后将误差进行反向传播(计算梯度、更新参数),通过不断的学习,最终可以获得识别新样本的能力。【每条数据都有正确答案,通过模型预测结果与正确答案的误差不断优化模型参数】 - 无监督学习:无监督学习
不依赖任何标签值,通过对数据内在特征的挖掘,找到样本间的关系,比如聚类相关的任务。有监督和无监督最主要的区别在于模型在训练时是否需要人工标注的标签信息。【只有数据没有答案,常见的是聚类算法,通过衡量样本之间的距离来划分类别】 - 半监督学习:利用
有标签数据和无标签数据来训练模型。一般假设无标签数据远多于有标签数据。例如使用有标签数据训练模型,然后对无标签数据进行分类,再使用正确分类的无标签数据训练模型。【利用大量的无标注数据和少量有标注数据进行模型训练】 - 自监督学习:机器学习的
标注数据源于数据本身,而不是由人工标注。目前主流大模型的预训练过程都是采用自监督学习,将数据构建成完型填空形式,让模型预测对应内容,实现自监督学习。【通过对数据进行处理,让数据的一部分成为标签,由此构成大规模数据进行模型训练】 - 远程监督学习:主要用于关系抽取任务,
采用bootstrap的思想通过已知三元组在文本中寻找共现句,自动构成有标签数据,进行有监督学习。【基于现有的三元组收集训练数据,进行有监督学习】 - 强化学习:强化学习是智能体根据已有的经验,采取系统或随机的方式,去尝试各种可能答案的方式进行学习,并且智能体会
通过环境反馈的奖赏来决定下一步的行为,并为了获得更好的奖赏来进一步强化学习。【以获取更高的环境奖励为目标优化模型】
模型:一个包含了大量未知参数的函数。

训练:通过大量的数据去迭代逼近这些未知参数的最优解。

- 样本:一条数据;
- 特征:被观测对象的可测量特性,例如西瓜的颜色、瓜蒂、纹路、敲击声等;
- 特征向量:用一个d维向量表征一个样本的所有或部分特征;
- 标签(label)/真实值:样本特征对应的真实类型或者真实取值,即正确答案;
- 数据集(dataset):多条样本组成的集合;
- 训练集(train):用于训练模型的数据集合;
- 评估集(eval):用于在训练过程中周期性评估模型效果的数据集合;
- 测试集(test):用于在训练完成后评估最终模型效果的数据集合;
- 误差/损失:样本真实值与预测值之间的误差;
- 预测值:样本输入模型后输出的结果;
- 模型训练:使用训练数据集对模型参数进行迭代更新的过程;
- 模型收敛:任意输入样本对应的预测结果与真实标签之间的误差稳定;
- 模型评估:使用测试数据和评估指标对训练完成的模型的效果进行评估的过程;
- 模型推理/预测:使用训练好的模型对数据进行预测的过程;
- 模型部署:使用服务加载训练好的模型,对外提供推理服务;
梯度:梯度是一个向量(矢量),函数在一点处沿着该点的梯度方向变化最快,变化率最大。换而言之,自变量沿着梯度方向变化,能够使因变量(函数值)变化最大。

学习率(LearningRate,LR):学习率决定了模型参数的更新幅度,学习率越高,模型参数更新越激进,即相同Loss对模型参数产生的调整幅度越大,反之越越小。
- 如果学习率太小,会导致网络loss下降非常慢;
- 如果学习率太大,那么参数更新的幅度就非常大,产生振荡,导致网络收敛到局部最优点,或者loss不降反增。

Batch size:Batch size是一次向模型输入的数据数量,Batch size越大,模型一次处理的数据量越大,能够更快的运行完一个Epoch,反之运行完一个Epoch越慢。
使用Batch size的原因:由于模型一次是根据一个Batch size的数据计算Loss,然后更新模型参数,如果Batch size过小,单个Batch可能与整个数据的分布有较大差异,会带来较大的噪声,导致模型难以收敛。与此同时,Batch size越大,模型单个Step加载的数据量越大,对于GPU显存的占用也越大,当GPU显存不够充足的情况下,较大的Batch size会导致OOM,因此,需要针对实际的硬件情况,设置合理的Batch size取值。
使用Batch size的好处:
- 提高内存利用率,提高
并行化效率; - 一个Epoch所需的
迭代次数变少,减少训练时间; - 梯度计算更加
稳定,训练曲线更平滑,下降方向更准,能够取得更好的效果;

Batchsize需要在合理的范围内设置,如果超出合理范围,Batchsize的增大会导致模型性能下降,泛化能力变差。(https://arxiv.org/pdf/1706.02677.pdf)

大的Batchsize容易收敛到sharpminimum,而小的Batchsize容易收敛到flatminimum,后者具有更好的泛化能力(https://arxiv.org/pdf/1609.04836.pdf)。

Batchsize过大并不是性能下降的直接原因,直接原因是迭代次数过少,因为Batchsize越大,每个epoch执行的迭代次数越少,参数更新次数减少,因此需要更长的迭代次数(https://arxiv.org/pdf/1705.08741.pdf)。

learningrate与batch_size:
- 传统模型在训练过程中更容易过拟合,所以需要设置合理的Batchsize,更多情况下
较小的Batchsize会取得更好的效果; 大模型不易过拟合,所以大模型建议设置更大的Batchsize;- 调整Batchsize与lr的一个常用思路是:调整batch_size时learningrate要进行
等比例的调整,保证收敛稳定性,但是在新的研究中表明这种方式不一定有效(还是得炼丹); - 可以通过增加Batchsize来达到与衰减学习率类似的效果,由于learningrate对收敛影响很大,所以
可以通过增加Batchsize代替衰减(https://arxiv.org/pdf/1711.00489.pdf); - 对于一个
固定的learningrate,存在一个最优Batchsize使得性能最优;
Learning rate scheduler:
合适的学习率对于模型的快速收敛非常重要,学习率下降策略是模型训练过程中一个非常常用且有效的方法。在训练初期,可以使用较大的LR来以较大幅度更新参数,然后逐渐降低LR,使网络更容易收敛到最优解。

Warm up:
- 在训练开始阶段,模型的权重(weights)是随机初始化或者与当前训练数据分布差异较大,此时若
选择一个较大的学习率,模型权重迅速改变,可能带来模型的不稳定(振荡)。 - 选择Warmup预热学习率的方式,可以使得在
训练开始阶段学习率较小,在预热的小学习率下,模型可以慢慢趋于稳定,等模型相对稳定后再选择预先设置的学习率进行训练,使得模型收敛速度变得更快,模型效果更佳。
好处:
- 有助于
减缓模型在初始阶段对mini-batch的提前过拟合现象,保持分布的平稳。 - 有助于保持
模型深层的稳定性。
Warm up && LR decay:
下图为在微调LLaMA-7B初始阶段的LR变化情况。首先通过Warm up策略,从一个非常小的学习率开始,逐步增大,完成warm up过程后,从预设LR开始,进行基于LR decay策略的模型训练。

Step:一次梯度更新的过程。
Epoch:模型完成一次完整训练集的训练。
线性函数:一次函数的别称。
非线性函数:函数图像不是一条直线的函数,如指数函数、幂函数、对数函数、多项式函数等,以及它们组成的复合函数。
激活函数:激活函数是多层神经网络的基础,保证多层网络不退化成线性网络,这样可以使得神经网络应用到更多非线性模型中。

常见激活函数:
sigmoid:

- sigmoid函数具有
软饱和特性,在正负饱和区的梯度都接近于0,只在0附近有比较好的激活特性; - sigmoid导数值最大0.25,也就是反向传播过程中,每层至少有75%的损失,这使得当sigmoid被用在隐藏层的时候,会导致
梯度消失(一般5层之内就会产生); - 函数输出不以0为中心,也就是
输出均值不为0,会导致参数更新效率降低; - sigmoid函数涉及
指数运算,导致计算速度较慢。
为什么希望激活函数输出均值为0?

在上面的参数wi更新公式中, ∂ L ∂ y ∂ y ∂ z \frac{\partial L}{\partial y}\frac{\partial y}{\partial z} ∂y∂L∂z∂y对于所有wi都是一样的,xi是i-1层的激活函数的输出,如果像sigmoid一样,输出值只有正值,那么对于第i层的所有wi,其更新方向完全一致,模型为了收敛,会走Z字形来逼近最优解。
softmax:

tanh:

ReLU:

- ReLU是一个
分段线性函数,因此是非线性函数; - ReLU的发明是深度学习领域最重要的突破之一;
- ReLU
不存在梯度消失问题; - ReLU
计算成本低,收敛速度比sigmoid快6倍; - 函数输出不以0为中心,也就是
输出均值不为0,会导致参数更新效率降低; - 存在
deadReLU问题(输入ReLU有负值时,ReLU输出为0,梯度在反向传播期间无法流动,导致权重不会更新);
为了解决deadReLU问题:
LeakyReLU:

ELU:

Swish:

- 参数不变情况下,将模型中ReLU替换为Swish,
模型性能提升; - Swish
无上界,不会出现梯度饱和; - Swish
有下界,不会出现deadReLU问题; - Swish
处处连续可导。
损失函数(lossfunction):用来度量模型的预测值f(x)与真实值Y的差异程度(损失值)的运算函数,它是一个非负实值函数。损失函数仅用于模型训练阶段,得到损失值后,通过反向传播来更新参数,从而降低预测值与真实值之间的损失值,从而提升模型性能。整个模型训练的过程,就是在通过不断更新参数,使得损失函数不断逼近全局最优点(全局最小值)。
常见损失函数:回归任务中的MAE、MSE,分类任务中的交叉熵损失等。

均方误差(meansquarederror,MSE),也叫平方损失或L2损失,常用在最小二乘法中,它的思想是使得各个训练点到最优拟合线的距离最小(平方和最小)。

平均绝对误差(MeanAbsoluteError,MAE)是所有单个观测值与算术平均值的绝对值的平均,也被称为L1loss,常用于回归问题中。
交叉熵损失:
二分类:

其中,yi为样本i的真实标签,正类为1,负类为0;pi表示样本i预测为正类的概率。
多分类:

其中,M为类别数量;yic符号函数,样本i真实类别等于c则为1,否则为0;预测样本i属于类别c的预测概率。
对于不同的分类任务,交叉熵损失函数使用不同的激活函数(sigmoid/softmax)获得概率输出:
【二分类】
使用sigmoid和softmax均可,注意在二分类中,Sigmoid函数,我们可以当作成它是对一个类别的“建模”,另一个相对的类别就直接通过1减去得到。而softmax函数,是对两个类别建模,同样的,得到两个类别的概率之和是1。
【单标签多分类】
交叉熵损失函数使用softmax获取概率输出(互斥输出)。
【多标签多分类】
交叉熵损失函数使用sigmoid获取概率输出。
优化器(Optimizer):优化器就是在深度学习反向传播过程中,指引损失函数(目标函数)的各个参数往正确的方向更新合适的大小,使得更新后的各个参数让损失函数(目标函数)值不断逼近全局最小。如果损失函数是一座山峰,优化器会通过梯度下降,帮助我们以最快的方式,从高山下降到谷底。

梯度下降算法:
- BGD:批量梯度下降法在全部训练集上计算精确的梯度。为了获取准确的梯度,批量梯度下降法的每一步都把整个训练集载入进来进行计算,
时间花费和内存开销都非常大,无法应用于大数据集、大模型的场景。 - SGD:随机梯度下降法则采样单个样本来估计的当前梯度。随机梯度下降法放弃了对梯度准确性的追求,每步仅仅随机采样一个样本来估计当前梯度,
计算速度快,内存开销小。但由于每步接受的信息量有限,随机梯度下降法对梯度的估计常常出现偏差,造成目标函数曲线收敛得很不稳定,伴有剧烈波动,有时甚至出现不收敛的情况。 - mini-batchGD:mini-batch梯度下降法
使用batch的一个子集来计算梯度。

- Momentum(动量):Momentum优化算法是对梯度下降法的一种优化, 它在原理上模拟了物理学中的动量。
 vt由两部分组成:一是学习速率η乘以当前估计的梯度gt;二是带衰减的前一次步伐vt−1。vt直接依赖于vt−1和gt,而不仅仅是gt。另外,衰减系数γ扮演了阻力的作用。
vt由两部分组成:一是学习速率η乘以当前估计的梯度gt;二是带衰减的前一次步伐vt−1。vt直接依赖于vt−1和gt,而不仅仅是gt。另外,衰减系数γ扮演了阻力的作用。

- AdaGrad:引入
自适应思想,训练过程中,学习速率逐渐衰减,经常更新的参数其学习速率衰减更快。AdaGrad方法采用所有历史梯度平方和的平方根做分母,分母随时间单调递增,产生的自适应学习速率随时间衰减的速度过于激进。

- RMSprop:RMSprop是Hinton在课程中提到的一种方法,是对Adagrad算法的改进,主要是
解决学习速率过快衰减的问题。采用梯度平方的指数加权移动平均值,其中一般取值0.9,有助于避免学习速率很快下降的问题,学习率建议取值为0.001。

- Adam:Adam方法将
惯性保持(动量)和自适应这两个优点集于一身。- Adam记录梯度的
一阶矩(firstmoment),即过往梯度与当前梯度的平均,这体现了惯性保持: 
- Adam还记录梯度的
二阶矩(secondmoment),即过往梯度平方与当前梯度平方的平均,这类似AdaGrad方法,体现了自适应能力,为不同参数产生自适应的学习速率: 
- 一阶矩和二阶矩采用类似于滑动窗口内求平均的思想进行融合,即
当前梯度和近一段时间内梯度的平均值,时间久远的梯度对当前平均值的贡献呈指数衰减。 
- 其中,β1,β2为衰减系数,β1通常取值0.9,β2通常取值0.999,mt是一阶矩,vt是二阶矩。

- 其中,mt^ 和 vt^ 是mt、vt偏差矫正之后的结果。
- Adam记录梯度的
模型评估指标:
分类模型:
准确率(Accuracy):准确率是分类问题中最简单也是最直观的评价指标,但存在明显的缺陷。比如,当负样本占99%时,分类器把所有样本都预测为负样本也可以获得99%的准确率。所以,
当不同类别的样本比例非常不均衡时,占比大的类别往往成为影响准确率的最主要因素。

其中,ncorrect为被正确分类的样本个数,ntotal为总样本个数。混淆矩阵:混淆矩阵是机器学习中总结分类模型预测结果的情形分析表,以矩阵形式将数据集中的记录按照真实的类别与分类模型预测的类别判断两个标准进行汇总。

- TruePositive(TP):真正类。正类被预测为正类。
- FalseNegative(FN):假负类。正类被预测为负类。
- FalsePositive(FP):假正类。负类被预测为正类。
- TrueNegative(TN):真负类。负类被预测为负类。
精准率(Precision):精准率,表示预测结果中,
预测为正样本的样本中,正确预测的概率。

召回率(Recall):召回率,表示在
原始样本的正样本中,被正确预测为正样本的概率。

Precision值和Recall值是既矛盾又统一的两个指标,为了提高Precision值,分类器需要尽量在“更有把握”时才把样本预测为正样本,但此时往往会因为过于保守而漏掉很多“没有把握”的正样本,导致Recall值降低。F1-score是Precision和Recall两者的综合,是一个综合性的评估指标。

Micro-F1:不区分类别,直接使用总体样本的准召计算f1score。
Macro-F1:先计算出每一个类别的准召及其f1score,然后通过求均值得到在整个样本上的f1score。
数据均衡,两者均可;样本不均衡,相差很大,使用Macro-F1;样本不均衡,相差不大,优先选择Micro-F1。
回归模型:
MSE(Mean Squared Error):均方误差,yi-y^i为真实值-预测值。
MSE中有平方计算,会导致量纲与数据不一致。

RMSE(Root Mean Squared Error):均方根误差,yi-y^i为真实值-预测值。
解决量纲不一致的问题。

MAE(Mean Absolute Error):平均绝对误差,yi-y^i为真实值-预测值。

问题:RMSE与MAE的量纲相同,但求出结果后为什么RMSE比MAE的要大一些。
原因:这是因为RMSE是先对误差进行平方的累加后再开方,它其实是放大了较大误差之间的差距。而MAE反应的是真实误差。因此在衡量中使RMSE的值越小其意义越大,因为它的值能反映其最大误差也是比较小的。决定系数(R2):决定系数,分子部分表示真实值与预测值的平方差之和,类似于均方差MSE;分母部分表示真实值与均值的平方差之和,类似于方差Var。

- 根据R2的取值,来判断模型的好坏,其
取值范围为[0,1]: R^2^越大,表示模型拟合效果越好。R2反映的是大概的准确性,因为随着样本数量的增加,R2必然增加,无法真正定量说明准确程度,只能大概定量。
- 根据R2的取值,来判断模型的好坏,其
GSB:常用于两个模型之间的对比,而非单个模型的评测,可以用GSB指标评估两个模型在某类数据中的性能差异。

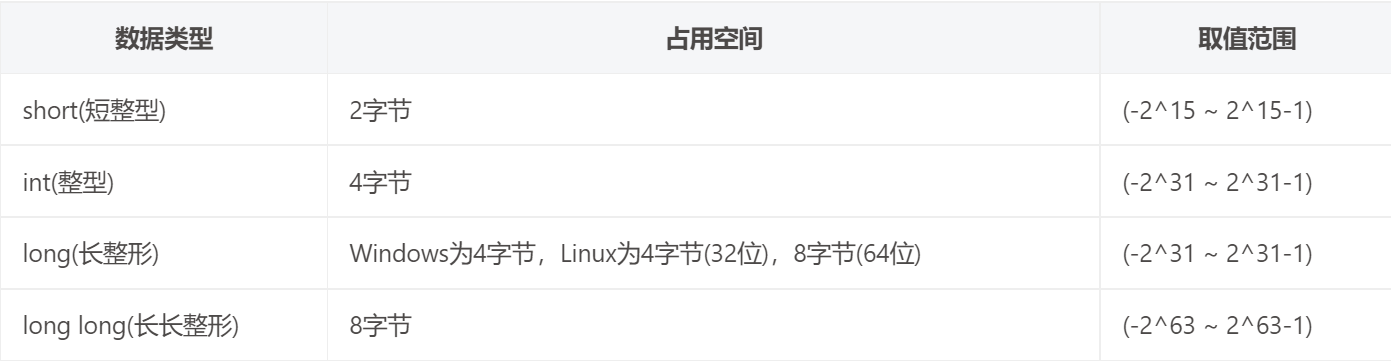
数据精度:
- FP32是
单精度浮点数,用8bit表示指数,23bit表示小数; - FP16是
半精度浮点数,用5bit表示指数,10bit表示小数; - BF16是对FP32单精度浮点数截断数据,即用8bit表示指数,7bit表示小数。

为什么聚焦半精度?
原因:
(1)内存占用更少
fp16模型占用的内存只需fp32模型的一半:
- 模型训练时,可以用更大的batchsize;
- 模型训练时,GPU并行时的通信量大幅减少,大幅减少等待时间,加快数据的流通;
(2)计算更快
主流GPU都有针对fp16的计算进行优化(如英伟达),在这些GPU中,半精度的计算吞吐量可以是单精度的2-8倍;
常用估计模型尺寸大小:
| 模型尺寸 | FP16 类型大小 | FP32 类型大小 |
|---|---|---|
| 6B | 6000000000 * 2byte ≈ 11.18GB | 6000000000 * 4byte ≈ 22.35GB |
| 7B | 7000000000 * 2byte ≈ 13.04GB | 6000000000 * 4byte ≈ 26.08GB |
| 13B | 13000000000 * 2byte ≈ 24.21GB | 6000000000 * 4byte ≈ 48.42GB |
| 175B | 175000000000 * 2byte ≈ 325.96GB | 175000000000 * 4byte ≈ 651.93GB |
当然半精度也会带来一定的问题:
(1)下溢出
- FP32 的表示范围:1.4 * 10-45 ~ 1.7 * 1038
- FP16 的表示范围:6 * 10-8 ~ 65504
由于 fp16 的值区间比 fp32 的值区间小很多,所以在训练过程中很容易出现下溢出(Underflow,<6x10-8)的错误。
(2)舍入误差
对于fp16:
- Weight = 2-3(0.125), Gradient = 2-14(约为0.000061)
- Weightnew= Weight + Gradient = 2-3 + 2-14 = 2-3
在 [2-3, 2-2] 区间,fp16 表示的固定间隔为2-13,也就是说,在fp16表示下,比2-3大的下一个数为 2-3 + 2-13,因此,当梯度小于2^-13^时,会出现舍入误差,梯度被忽略。
解决方案:
(1)保存fp32备份(混合精度训练)
weights, activations, gradients 等数据在训练中都利用FP16来存储,同时拷贝一份FP32的 weights,用于更新。
在前向传播过程中,模型各个层的参数w和层的输入输出都是fp16,但是fp16的精度不够,无法表示特别小的数值,这会导致在进行梯度更新的时候,梯度值下溢,导致被调整参数没有变化。
因此,在参数梯度更新的时候,会使用fp32来进行运算,也就是优化器为每一个训练参数保存一个额外的fp32类型的拷贝,计算完成之后再转成fp16,参与训练过程。
【极大消耗显存】

(2)Loss Scaling
- 前向传播后,反向传播前,
将损失变化(Loss)增大 2^k^倍,确保反向传播时得到的中间变量(激活函数梯度)则不会溢出; - 反向传播过程中,
使用放大的梯度对模型参数进行更新; - 反向传播后,
将权重梯度缩小 2^k^倍,恢复正常值。
如果缩放因子选择得太小,仍然可能会出现小梯度的问题;而如果缩放因子选择得太大,可能会导致梯度爆炸等数值稳定性问题。因此,合理选择缩放因子和监测训练过程中梯度的变化是非常重要的。

(3)Dynamic Loss Scaling
- 动态损失缩放的算法会
从比较高的缩放因子开始(如2^24^),然后开始进行训练迭代中检查数是否会溢出(Infs/Nans); - 如果
没有梯度溢出,则不进行缩放,继续进行迭代;如果检测到梯度溢出,则缩放因子会减半,重新确认梯度更新情况,直到数不产生溢出的范围内; - 在训练的后期,
loss已经趋近收敛稳定,梯度更新的幅度往往小了,这个时候可以允许更高的损失缩放因子来再次防止数据下溢。 - 因此,动态损失缩放算法会尝试
在每N(N=2000)次迭代将损失缩放增加F倍数,然后执行步骤2检查是否溢出。
模型计算练习:【参考文献:https://arxiv.org/pdf/1910.02054.pdf】
对于一个φ个参数的模型,fp16类型:
- 参数:2φ
- 梯度:2φ
- 优化器:12φ(混合精度训练,
每个参数fp32类型的值、momentum值和variance值,各4φ) - 总计:16φ
一个1.6B参数的GPT-2,训练过程就需要24GB的显存。这24GB中,参数和梯度只占了3GB,其余21GB只在模型更新的时候用到,但是在DP的时候,要存在里面。
当使用1.6B模型,序列长度1024,batch_size=32的时候,需要60GB的内存,大概15GB存储中间变量,24GB存储上述训练相关数据。
pytorch在进行模型训练的时候,如果发现没有用到的内存,会释放掉,等用的时候再开出来,反复的析构,会导致碎片内存的出现。
CUDA与炼丹(第八周)
CUDA
CUDA:CUDA中线程也可以分成三个层次:线程、线程块和线程网络。
- 线程(Thread):CUDA中基本执行单元,由硬件支持、开销很小,每个线程执行相同代码;
- 线程块(Block):若干线程的分组,Block内一个块至多512个线程、或1024个线程(根据不同的GPU规格),线程块可以是一维、二维或者三维的;
- 线程网络(Grid):若干线程块Block的网格,Grid是一维和二维的。
GPU有很多线程,在CUDA里被称为Thread,同时我们会把一组Thread归为一个Block,而Block又会被组织成一个Grid。

SM(StreamingMultiprocessor):GPU上有很多计算核心也就是SM,SM是一块硬件,包含了固定数量的运算单元,寄存器和缓存。在具体的硬件执行中,一个SM会同时执行一组线程,在CUDA里叫warp,直接可以理解这组硬件线程warp会在这个SM上同时执行一部分指令,这一组的数量一般为32或者64个线程。一个Block会被绑定到一个SM上,即使这个Block内部可能有1024个线程,但这些线程组会被相应的调度器来进行调度,在逻辑层面上我们可以认为1024个线程同时执行,但实际上在硬件上是一组线程同时执行,这一点其实就和操作系统的线程调度一样。意思就是假如一个SM同时能执行64个线程,但一个Block有1024个线程,那这1024个线程是分1024/64=16次执行。
GPU在管理线程的时候是以block为单元调度到SM上执行。每个block中以warp(一般32个线程或64线程)作为一次执行的单位(真正的同时执行)。
- 一个GPU包含多个SM,而每个SM又包含多个Core,SM支持并发执行多达几百的Thread。
- 一个Block只能调度到一个SM上运行,直到ThreadBlock运行完毕。一个SM可以同时运行多个Block(因为有多个Core)。
- 写CUDAkernel的时候,跟SM对应的概念是Block,每一个Block会被调度到某个SM执行,一个SM可以执行多个block。CUDA程序就是很多的Blocks均匀的喂给若干SM来调度执行。
再看一张图,加深一下理解,CUDA软件和硬件结构:

规格参数:不同的GPU规格参数不一样,执行参数不同,比如Fermi架构:
- 每一个SM上最多同时执行8个Block。(不管Block大小)
- 每一个SM上最多同时执行48个warp。
- 每一个SM上最多同时执行48*32=1536个线程。
内存:一个Block会绑定在一个SM上,同时一个Block内的Thread是共享一块ShareMemory(一般就是SM的一级缓存,越靠近SM的内存就越快)。GPU和CPU也一样有着多级Cache还有寄存器的架构,把全局内存的数据加载到共享内存上再去处理可以有效的加速。

CPU&GPU训练时间对比,直观感受一下差距:
- 模型:BERT-base
- 训练数据集:180000
- batch_size:32
- CPU(Xeon®Gold51182CPU24Core):40:30:00
- CPU(Xeon®Platinum8255C1CPU40Core):16:25:00
- GPU(P40):3:00:00
- GPU(V100):1:17:00
GPU并行方式:
- 数据并行(DataParallelism):在不同的GPU上运行同一批数据的不同子集;
- 流水并行(PipelineParallelism):在不同的GPU上运行模型的不同层;
- 张量并行(TensorParallelism):将单个数学运算(如矩阵乘法)拆分到不同的GPU上运行;
- 混合专家系统(Mixture-of-Experts):只用模型每一层中的一小部分来处理数据。

数据并行:
将整个模型放在一块GPU里,再复制到每一块GPU上,同时进行正向传播和反向误差传播,相当于加大了batch_size。
每个GPU都加载模型参数,被称为“工作节点(workers)”,为每个GPU分配分配不同的数据子集同时进行处理,分别求解梯度,然后求解所有节点的平均梯度,每个节点各自进行反向传播。
各节点的同步更新策略:
①单独计算每个节点上的梯度;
②计算节点之间的平均梯度(阻塞,涉及大量数据传输,影响训练速度);
③单独计算每个节点相同的新参数。
Pytorch对于数据并行有很好的支持,数据并行也是最常用的GPU并行加速方法之一。
模型分层:
将模型按层分割,不同的层被分发到不同的GPU上运行。每个GPU上只有部分参数,因此每个部分的模型消耗GPU的显存成比例减少,常用于GPU显存不够,无法将一整个模型放在GPU上。

layer的输入和输出之间存在顺序依赖关系,因此在一个GPU等待其前一个GPU的输出作为其输入时,朴素的实现会导致出现大量空闲时间。这些空闲时间被称作“气泡”,而在这些等待的过程中,空闲的机器本可以继续进行计算。
张量并行:
如果在一个layer内“水平”拆分数据,这就是张量并行。许多现代模型(如Transformer)的计算瓶颈是将激活值与权重相乘。
矩阵乘法可以看作是若干对行和列的点积:可以在不同的GPU上计算独立的点积,也可以在不同的GPU上计算每个点积的一部分,然后相加得到结果。
无论采用哪种策略,都可以将权重矩阵切分为大小均匀的“shards”,不同的GPU负责不同的部分,要得到完整矩阵的结果,需要进行通信将不同部分的结果进行整合。
混合专家系统:
混合专家系统(MoE)是指,对于任意输入只用一小部分网络用于计算其输出。在拥有多组权重的情况下,网络可以在推理时通过门控机制选择要使用的一组权重,这可以在不增加计算成本的情况下获得更多参数。
每组权重都被称为“专家(experts)”,理想情况是,网络能够学会为每个专家分配专门的计算任务。不同的专家可以托管在不同的GPU上,这也为扩大模型使用的GPU数量提供了一种明确的方法。

Pytorch DDP:
- 在DDP模式下,会有N个进程被启动(一般N=GPU数量),
每个进程在一张卡上加载一个模型,这些模型的参数在数值上是相同的。 - 在模型训练时,
各个进程通过Ring-Reduce的方法与其他进程通讯,交换各自的梯度,从而获得所有进程的梯度; - 各个进程
用平均后的梯度更新自己的参数,因为各个进程的初始参数、更新梯度是一致的,所以更新后的参数也是完全相同的。
Ring all-reduce 算法:
定义 GPU 集群的拓扑结构:
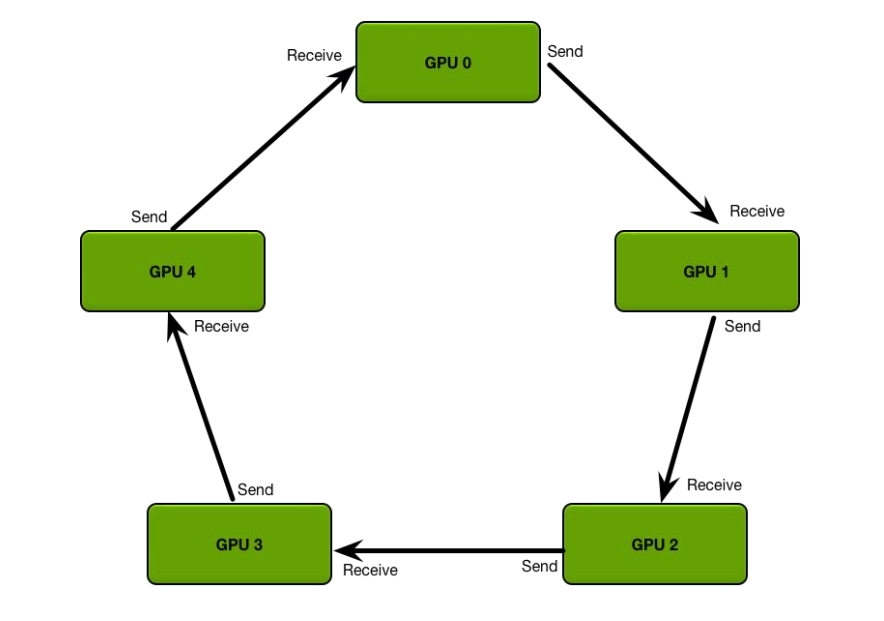
每个 GPU 只从左邻居接受数据、并发送数据给右邻居。
算法主要分两步:(举例:数组求和)
- scatter-reduce:会逐步交换彼此的梯度并融合,最后每个 GPU 都会包含完整融合梯度的一部分。
- allgather:GPU 会逐步交换彼此不完整的融合梯度,最后所有 GPU 都会得到完整的融合梯度
Step1:将数组在每个GPU上都分块

Step2:N-1轮的scatter-reduce,每一轮中,每个GPU将自己的一个chunk发给右邻居,并接收左邻居发来的chunk,并累加。


Allgather:和scatter-reduce操作类似,只不过将每个chunk里面的操作由累加值变为替换。



在上面的过程中,N个GPU中的每一个将分别发送和接收N-1次scatter reduce值和N-1次all gather的值。每次,GPU将发送K/N个值,其中K是在不同GPU之间求和的数组中值的总数。
因此,往返每个GPU的数据传输总量为

由于所有传输都是同步发生的,因此减少的速度受到环中相邻GPU之间最慢(最低带宽)连接的限制。如果为每个GPU选择了正确的邻居,则该算法是带宽最佳的,并且是减少带宽的最快算法(假设与带宽相比,延迟成本可以忽略不计)。
通常,如果一个节点上的所有GPU在环中彼此相邻,则该算法的效果最佳。这样可以最大程度地减少网络争用的数量,否则可能会大大降低GPU-GPU连接的有效带宽。
炼丹
🔗购卡攻略:AutoDL

根据合适的任务选择GPU,以大模型训练为例:
| 任务类型 | 推荐GPU | 备注 |
|---|---|---|
| BERT训练 | RTX3090/RTX3080/RTX2080TI | 可以选择便宜的2080 |
| ⼤模型LoRA微调 | V100 32GB/V100 SXM2 32GB | V100 32GB 起步 |
| ⼤模型FT微调 | A100 40GB PCIE /A100 SXM 80GB | A100 40GB PCIE 起步 |
注意,SXM2/SXM4版本的GPU使⽤NVLINK,多卡性能优于PCIE版本。
GPU性能对⽐⽹址:🔗https://topcpu.net/cpu-c
注意,默认提供50GB硬盘,选择GPU⼀定选择可以扩容更多硬盘的服务器,不同任务的硬盘需求:
| 任务类型 | 推荐拓展硬盘 | 备注 |
|---|---|---|
| BERT训练 | 不需要拓展 | |
| ⼤模型LoRA微调 | 150GB及以上(理想300GB) | 500GB以内即可 |
| ⼤模型FT微调 | 300GB及以上(理想500GB) | 多多益善,不设限 |


选定后选择拓展硬盘、镜像:

配置SSH密钥登录,将⾃⼰电脑的ssh公钥复制到⾥⾯,配置ssh后,所有云服务器可以⽆密登录::

打开cmd终端,输入命令生成公私钥对:
ssh-keygen
我这里之前创建过:


打开git bash,执行cat命令:

添加SSH公钥:

将ssh命令复制到命令行中:

配置服务器网盘:


将模型下载到服务器中:

长时间关注显然使用情况命令:
watch -n -1 nvidia-smi

配置中文编码,防止中文乱码:
vim /etc/profile
#LANG=en_US.UTF-8
#LANGUAGE=en_US:en
#LC_ALL=en_US.UTF-8
export LANG=zh_CN.UTF-8
PATH=/root/miniconda3/bin:/usr/local/bin:/usr/local/nvidia/bin:/usr/local/cuda/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
source /etc/profile
HuggingFace缓存配置:
如果不进⾏HuggingFace缓存配置,在⼤模型加载过程中的临时数据就会存放到系统盘,系统盘只有
25GB,会导致训练过程OOM。
mkdir /root/autodl-tmp/artboy && mkdir /root/autodl-tmp/tmp
vim ~/.bashrc
# enable programmable completion features (you don't need to enable
# this, if it's already enabled in /etc/bash.bashrc and /etc/profile
# sources /etc/bash.bashrc).
#if [ -f /etc/bash_completion ] && ! shopt -oq posix; then
# . /etc/bash_completion
#fi
export HF_HOME=/root/autodl-tmp/artboy/.cache
export TEMP=/root/autodl-tmp/tmp
source /etc/profile
source /etc/autodl-motd
source ~/.bashrc
创建常用目录:
cd /root/autodl-tmp/artboy
mkdir finetune_code && mkdir data && mkdir base_model
ls
# 移动代码
cd finetune_code
mv ~/autodl-tmp/BertClassifier/ .
ls
配置虚拟环境:
conda create -n bert_env python=3.8.5
source activate bert_env
cd BertClassifier
bash install_req.sh
# cat install_req.sh
# pip install -i https://pypi.tuna.tsinghua.edu.cn/simple -r requirements.txt
# pip list
Package Version
------------------------ ----------
certifi 2024.6.2
charset-normalizer 3.3.2
cmake 3.29.3
filelock 3.14.0
fsspec 2024.6.0
huggingface-hub 0.23.3
idna 3.7
Jinja2 3.1.4
joblib 1.4.2
lit 18.1.6
MarkupSafe 2.1.5
mpmath 1.3.0
networkx 3.1
numpy 1.24.4
nvidia-cublas-cu11 11.10.3.66
nvidia-cuda-cupti-cu11 11.7.101
nvidia-cuda-nvrtc-cu11 11.7.99
nvidia-cuda-runtime-cu11 11.7.99
nvidia-cudnn-cu11 8.5.0.96
nvidia-cufft-cu11 10.9.0.58
nvidia-curand-cu11 10.2.10.91
nvidia-cusolver-cu11 11.4.0.1
nvidia-cusparse-cu11 11.7.4.91
nvidia-nccl-cu11 2.14.3
nvidia-nvtx-cu11 11.7.91
packaging 24.0
pip 24.0
PyYAML 6.0.1
regex 2024.5.15
requests 2.32.3
safetensors 0.4.3
scikit-learn 1.3.2
scipy 1.10.1
setuptools 69.5.1
sympy 1.12.1
threadpoolctl 3.5.0
tokenizers 0.19.1
torch 2.0.0
tqdm 4.66.4
transformers 4.41.2
triton 2.0.0
typing_extensions 4.12.1
urllib3 2.2.1
wheel 0.43.0
模型训练:
nohup bash multi_gpu.sh > 20240605_1800.log &
tail -f 20240605_1800.log
loading data from: data/cnew.train_debug.txt
100%|██████████████████████████████████████████████████████████| 1000/1000 [00:05<00:00, 167.75it/s]
loading data from: data/cnew.val_debug.txt
100%|████████████████████████████████████████████████████████████| 500/500 [00:03<00:00, 129.41it/s]
Epoch 1 train: 11%|███▏ | 27/250 [00:41<05:41, 1.53s/it, acc=0, loss=2.08]
科研准备(第九周)
论文写作

科研网站汇总
🔗找前沿论文及实现、找数据集:paperswithcode
🔗找论文:sci-hub
🔗深度学习吴达恩教程:deeplearning
🔗斯坦福课程笔记:stanford-cs324.github.io
🔗找模型(国外,质量比较好):huggingface
🔗找模型(国内):魔搭
🔗找数据集、模型(国内):百度飞桨
🔗找数据集(国内):千言
🔗找文章(国内):智源社区
🔗找资源:B站
🔗科研工具箱:科研者之家
🔗图神经网络实现:dgl.ai
组会汇报
例如:电子科技大学Logo:

色系:RGB(0,64,152)
常用模板【文件已附文末】:

示例大语言模型综述介绍:

📌 [ 笔者 ] 文艺倾年
📃 [ 更新 ] 2024.6.16
❌ [ 勘误 ] /* 暂无 */
📜 [ 声明 ] 由于作者水平有限,本文有错误和不准确之处在所难免,
本人也很想知道这些错误,恳望读者批评指正!