文章汇总
存在的问题
罕见疾病在训练数据中的代表性不足,使其诊断性能不可靠。
解决办法
1:利用预训练的CLIP模型从数据库中检索相似的报告来辅助查询图像的诊断。
2:设计SDL模块根据不同疾病的学习状态自适应调整优化目标。
流程解读
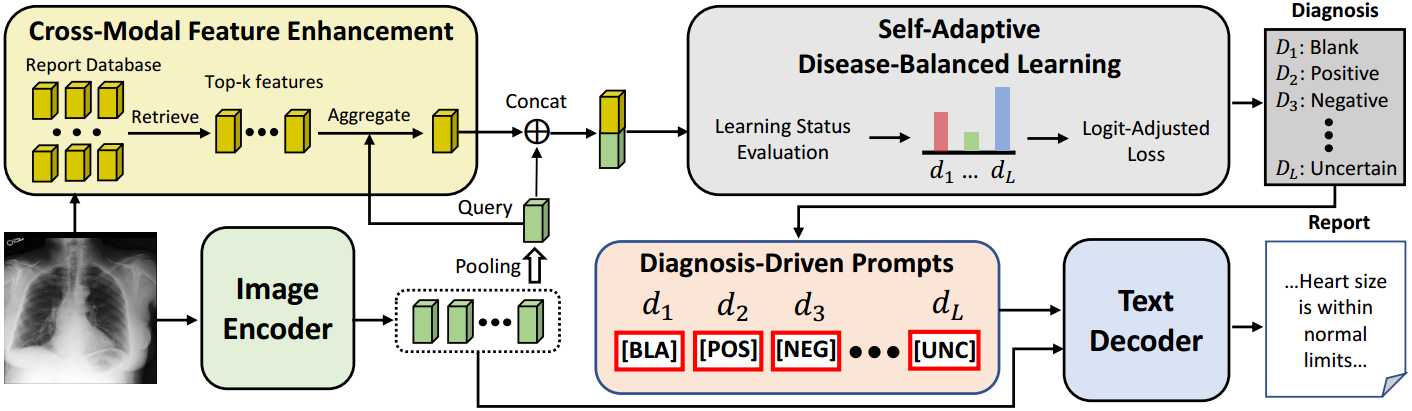
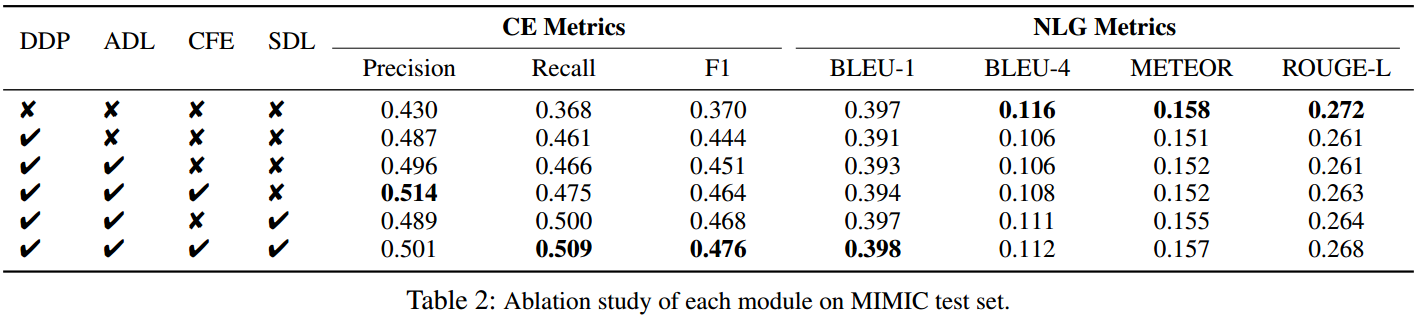
文章涉及了三个模块DDP、CFE和SDL,并且通过LLM来打标记。
Cross-Modal Feature Enhancement(CFE)
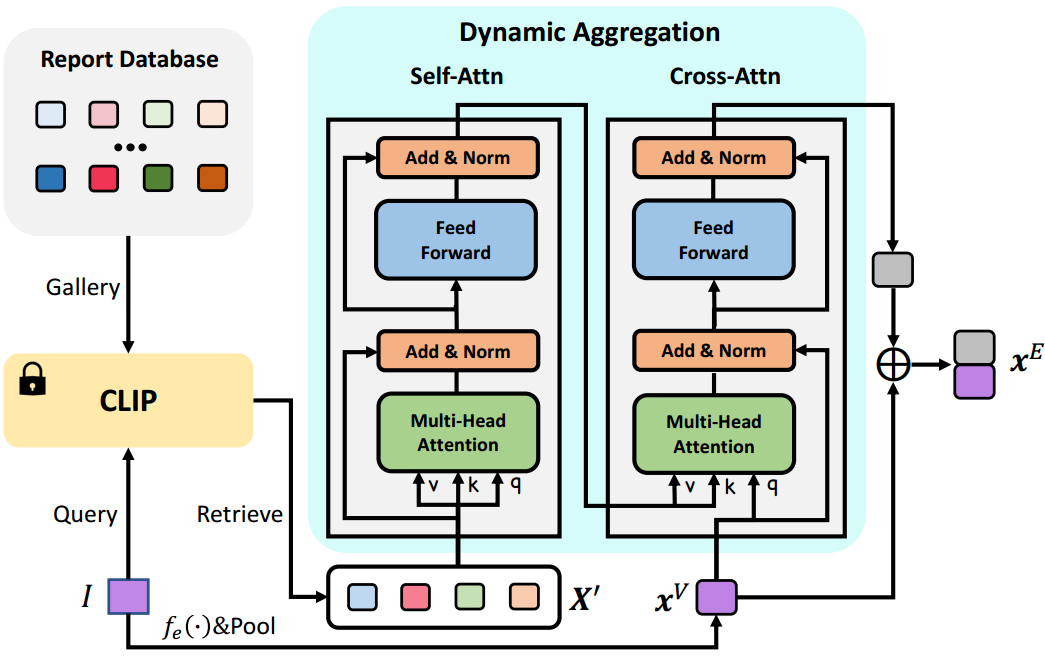
该模块的目的:模仿放射科医生通常访问额外的文档作为参考,借助训练数据的报告数据库(即图中的Report Database)来获得更鲁棒的疾病分类特征。
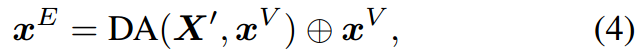
公式中 D A ( X ′ , x V ) DA(X',x^V) DA(X′,xV)就是从数据库这获得的特征。
Self-Adaptive Disease-Balanced Learning(SDL)
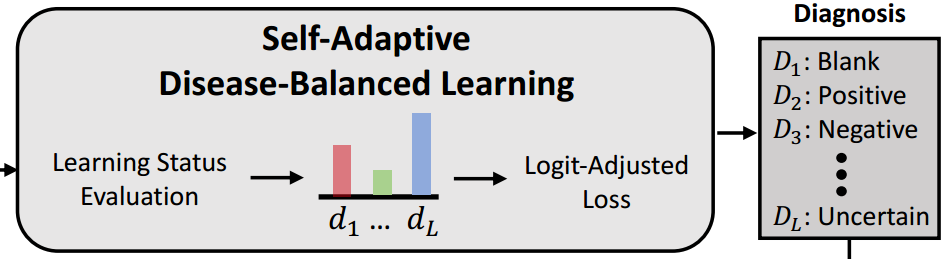
输入为CFE模块得到的 x E x^E xE。这里的目的是**利用预测分数来评估不同疾病的学习状态:分数大表明疾病学习得好,分数小表明疾病学习不够。**SDL的损失记为 L S D L L_{SDL} LSDL。
Diagnosis-Driven Prompt(DDP)
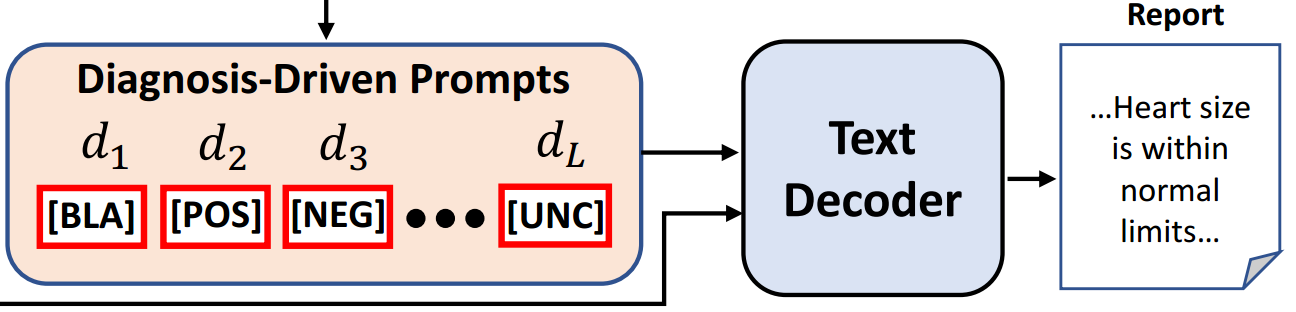
这里通过SDL得到了L个类的分类结果,之后通过CheXbert (Smit et al . 2020)将报告(即标签)转换为14个预定义的疾病标签,可以获得分类标签,并且使用标准交叉熵损失 L C E L_{CE} LCE进行训练。
在推理过程中,将分类结果转换为标记提示,其中每个标记提示对应一种疾病。向词汇表添加了四个新标记,[BLA]、[POS]、[NEG]和[UNC],之后对14个预定义类型标记属于"[BLA]、[POS]、[NEG]和[UNC]"中的哪一个。
用LLM辅助疾病标记
用训练报告作为输入,转换晨会适合大语言模型输入的提示Prompt,最终四个标记[BLA]、[POS]、[NEG]和[UNC]中的其中一个。大语言模型使用的是Vicuna-13B (Zheng et al . 2023)。
摘要
医学报告自动生成(MRG)有很大的研究价值,因为它有可能减轻放射科医生繁重的报告编写负担。尽管最近取得了进展,但由于需要精确的临床理解和疾病识别,准确的MRG仍然具有挑战性。此外,疾病分布的不平衡使得挑战更加明显,因为罕见疾病在训练数据中的代表性不足,使其诊断性能不可靠。为了应对这些挑战,我们提出了诊断驱动的医疗报告生成提示(PromptMRG),这是一个新的框架,旨在通过诊断感知提示的指导提高MRG的诊断准确性。具体来说,PromptMRG是基于编码器-解码器架构,并带有一个额外的疾病分类分支。在生成报告时,来自分类分支的诊断结果将被转换为令牌提示,以显式地指导生成过程。为了进一步提高诊断准确性,我们设计了跨模态特征增强,通过利用预训练CLIP的知识,从数据库中检索相似的报告来辅助查询图像的诊断。此外,基于每种疾病的个体学习状态,通过对分类分支应用自适应逻辑调整损失来解决疾病不平衡问题,克服了文本解码器无法操纵疾病分布的障碍。在两个MRG基准上的实验表明了所提出方法的有效性,在两个数据集上都获得了最先进的临床疗效表现。代码可在https://github.com/jhb86253817/PromptMRG上获得。
介绍
医学图像的自动化分析涉及广泛的任务,如异常检测(Cai et al . 2022),疾病分类(Luo et al . 2022, 2020),病变检测(Luo et al . 2021),地标检测(Jin, Che, and Chen 2023)等。其中,医学报告生成(MRG)是一项自动生成医学图像(例如胸部x光片)的自由文本描述的任务,它提供了图像内容的全面且与上下文相关的摘要。由于核磁共振成像具有减轻放射科医生繁重工作的潜力,近年来提出了许多关于核磁共振成像的工作。
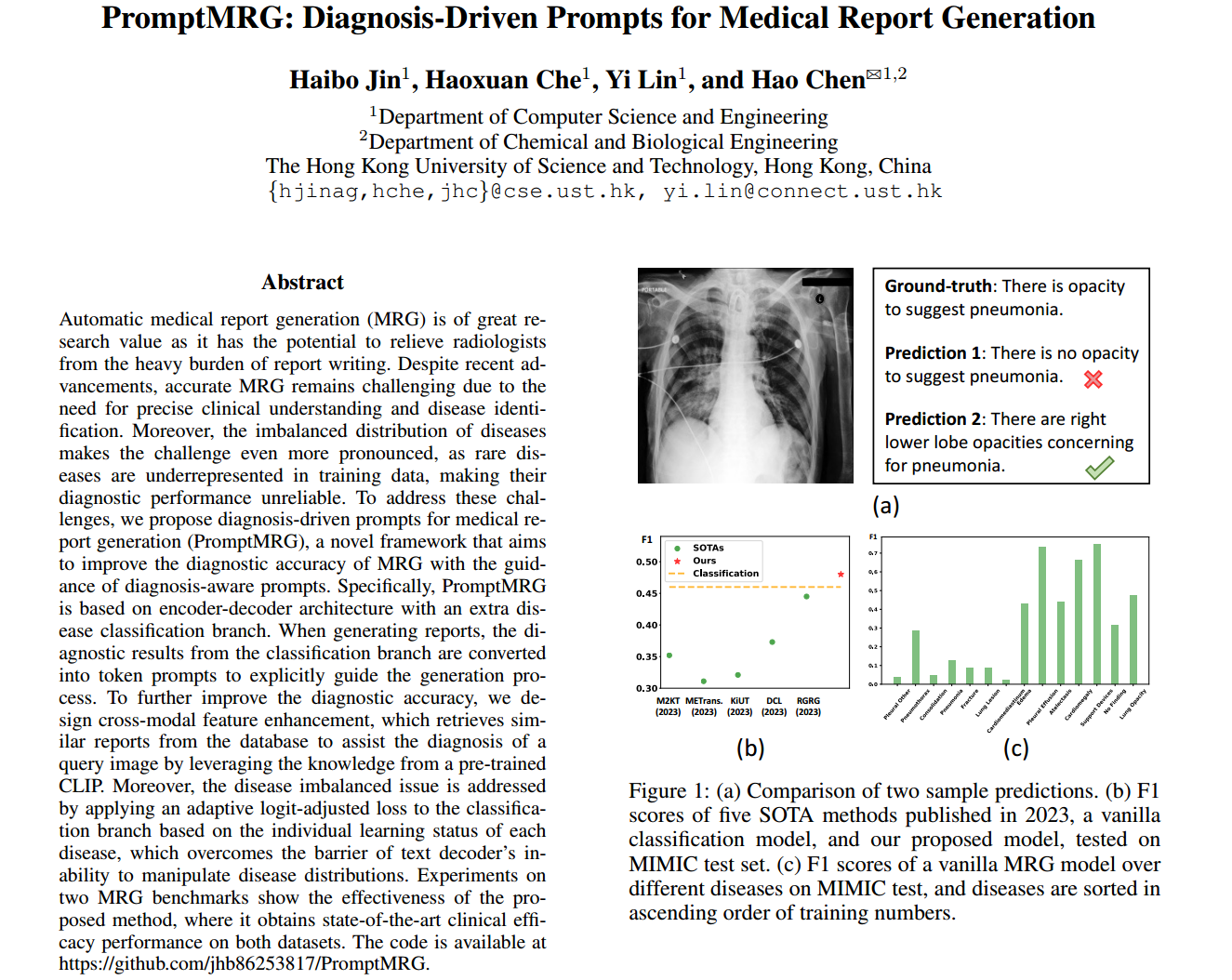
然而,生成准确的医疗报告是具有挑战性的,因为它需要对提供的图片的全面了解,尤其是鉴别临床表现的能力。例如,图1(a)显示了胸部x光片的两个样本预测和ground-truth(GT)。虽然第一个预测的措辞与GT非常相似,但其对不透明和肺炎的诊断是不正确的。相比之下,第二种预测更受欢迎,因为它成功地识别了不透明和肺炎,尽管措辞不同。因此,一个理想的MRG系统应该能够准确地识别异常,然后将结果转换为具有语言精度和临床相关性的文本。
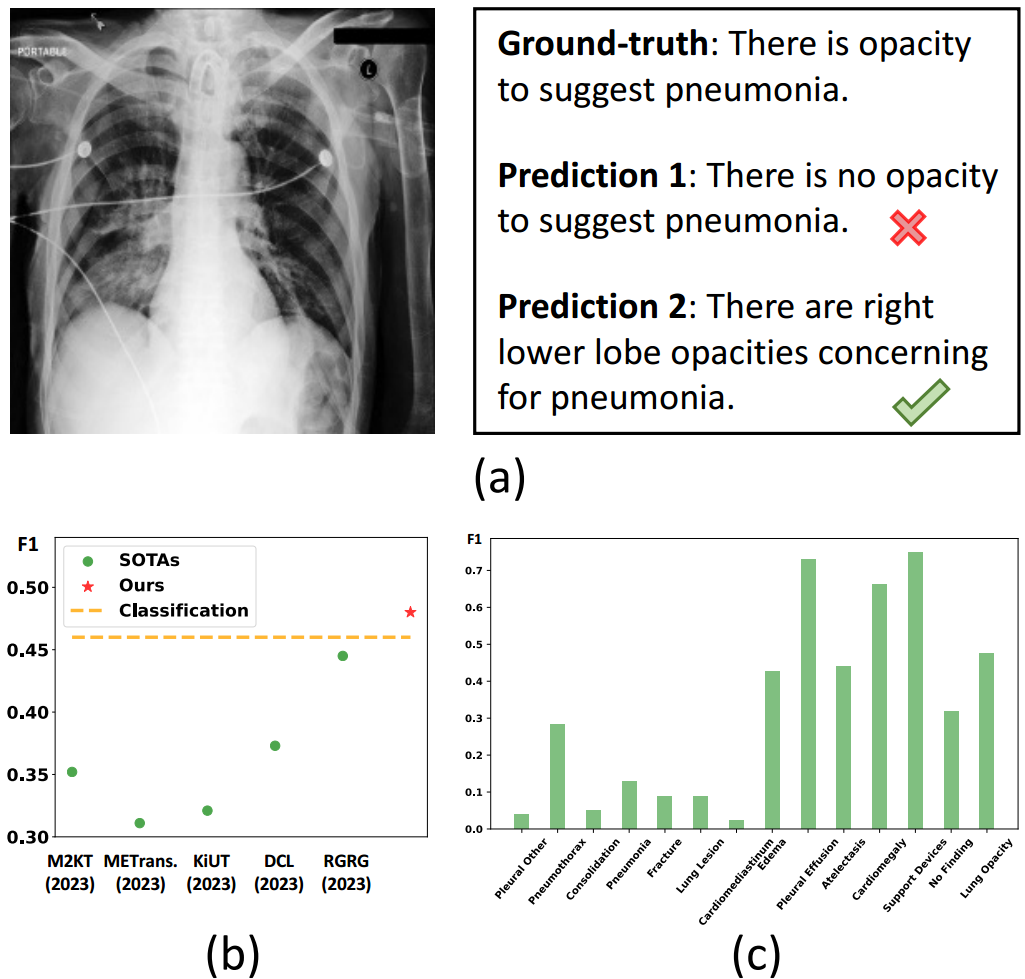
图1:(a)两个样本预测的比较。(b) 2023年发表的5种SOTA方法、香草分类模型和我们提出的模型的F1分数,在MIMIC测试集上进行测试。©在MIMIC测试中,香草MRG模型在不同疾病上的F1分数,疾病按训练次数升序排序。
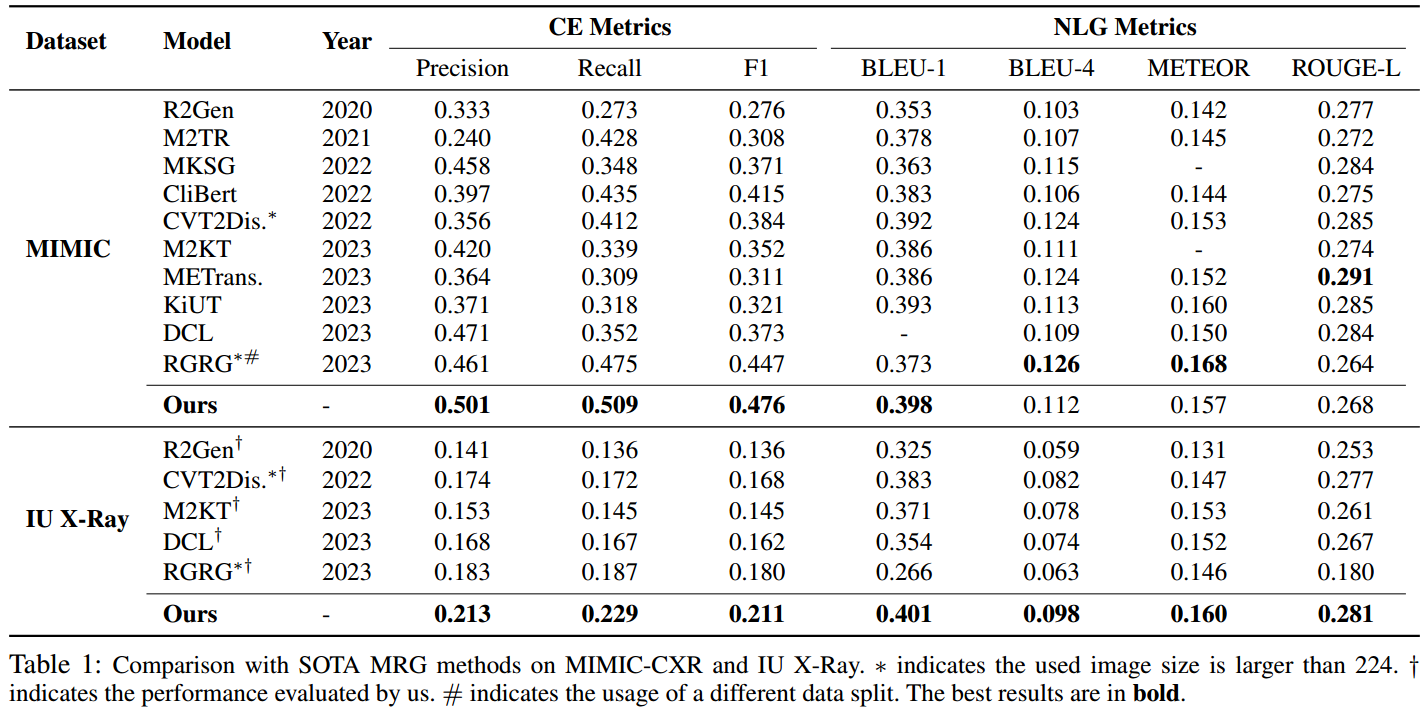
为了获得一个性能令人满意的MRG系统,人们提出了各种方法。例如,知识图是一种通过向模型中注入领域知识来增强特征学习和诊断能力的有效技术(Zhang et al . 2020;Liu et al . 2021a);多任务学习也被广泛用于获得更好的特征表示,除了生成报告外,还可以同时进行额外的辅助任务(Jing, Xie, and Xing 2018;Wang et al . 2022;Yan and Pei 2022)。尽管取得了成功,最先进的(SOTA)方法仍然缺乏生成诊断正确报告的能力。我们的初步实验如图1(b)所示,香草疾病分类模型在临床疗效(CE) F1评分方面明显优于大多数SOTA MRG方法。在MRG中,CE用作评估生成报告的诊断准确性的度量。由此可见,现有的MRG方法并没有充分利用医学图像中的诊断信息(与分类模型相比),这对MRG的应用是一个障碍。此外,疾病分布偏倚导致CE表现不平衡(见图1©)。然而,这一问题在以往的工作中并没有得到明确的解决,这进一步降低了目前MRG模型对罕见病的诊断不可靠的临床价值。
受上述观察结果的启发,我们提出了一个带有诊断驱动提示(DDP)的医疗报告生成框架PromptMRG,旨在通过诊断结果的指导来提高MRG的CE性能。具体来说,基于编码器-解码器架构,PromptMRG还配备了疾病分类分支。在生成报告时,来自分类分支的诊断结果将被转换为令牌提示,以显式地指导生成过程。为了进一步提高诊断的准确性,我们设计了跨模态特征增强(CFE),它通过利用预训练的CLIP模型从数据库中检索相似的报告来辅助查询图像的诊断。此外,疾病失衡问题也通过自适应疾病平衡学习(self-adaptive disease-balanced learning, SDL)得到明确解决,SDL根据不同疾病的学习状态自适应调整优化目标。在两个MRG基准上的实验表明了该方法的有效性,在两个数据集上都获得了SOTA CE性能。我们总结如下贡献。
•我们提出了一个新的MRG框架,该框架利用疾病分类分支通过令牌提示来指导报告生成过程,使模型能够生成诊断正确的报告。
•特征增强模块旨在通过利用来自预训练基础模型的多模态知识来进行类似记录检索,从而提高疾病分类性能。
•提出自适应疾病平衡学习,通过对分类分支应用自适应逻辑调整损失来解决疾病之间的不平衡学习,克服了文本解码器无法操纵疾病分布的障碍。
•我们通过两个流行的基准测试证明了PromptMRG的优越性,它在两个数据集上都获得了SOTA CE性能。
相关的工作
医疗报告生成
大多数MRG模型采用来自图像字幕的编码器-解码器架构(Xu et al . 2015;Lu et al . 2017;Ji et al . 2021),因为这两个任务很相似。然而,MRG比图像标题更具挑战性,因为医学报告通常比标题长得多,而医学图像中的临床异常比自然物体更难以识别。因此,人们提出了各种方法来应对上述挑战。Chen et al(2020)和Yang et al(2023)提出了额外的存储模块来记录过去的类似模式,以便在解码过程中提供信息内容,从而提高生成性能。本文提出的CFE也检索类似的记录作为额外的信息,但不同的是,它利用这些信息来增强疾病分类分支而不是生成过程(Chen et al . 2020;Yang et al . 2023)。
知识图谱已被广泛应用于整合领域知识以辅助报告生成。例如,Zhang et al(2020)和Liu et al (2021a)提出通过图神经网络结合预先构建的图来表示疾病与器官之间的关系,从而可以对异常进行专门的特征学习。后来,Li等人(2023)开发了一种动态方法来代替固定方法,通过动态注入新的知识来动态更新图。Huang, Zhang, and Zhang(2023)设计了一个注入知识蒸馏器,将症状图中的知识融合到最后的解码阶段,这与本文的DDP具有相似的精神。然而,DDP通过不同的引导机制(即提示)明确解决了临床疗效问题,并且在临床疗效方面表现出更强的表现。
多任务学习是促进MRG表征学习的另一种常用技术。在辅助任务中,疾病分类是最受欢迎的一项,因为它有助于模型学习判别特征(Jing, Xie, and Xing 2018;Wang et al . 2022;Yan and Pei 2022)。类似地,Yan等人(2021)引入了弱监督对比学习,作为学习语义有意义空间的辅助任务,以更好地生成报告。此外,还探索了图像-文本匹配(Wang et al 2022, 2021;Yan and Pei(2022)以细粒度的方式学习对齐的图像-文本表示。尽管在这项工作中使用了疾病分类,但我们强调的关键区别如下。以往的方法通常将分类分支视为一个并行任务,并期望它通过学习判别特征以一种隐式的方式对报告生成任务有利。相反,我们通过提示使用分类的诊断结果来明确地指导生成过程。RGRG (Tanida et al . 2023)是与我们最相关的工作,它利用目标检测器作为句子智能生成的区域指导。然而,他们的解码器只关注区域视觉特征,就像大多数以前的工作一样,而我们的解码器同时关注视觉特征和诊断驱动的提示,其中提示使解码器能够明确地利用诊断信息来生成临床正确的报告。另外,我们的模型可以端到端进行优化,而RGRG需要对多个模块进行单独训练,并从候选句子中进行启发式报告融合。
提示作为指导
提示最初是一种来自自然语言处理的技术,用于提高语言模型的泛化(Liu et al . 2023)。在监督学习中,提示不是单独训练各种任务,而是通过修改文本模板的输入,使语言模型能够统一并适应广泛的任务。后来的一些作品(李和梁2021;莱斯特,Al-Rfou和Constant 2021;Liu等人(2021b)采用这种技术进行有效的微调,其中提示符作为可训练的任务特定向量。由于有效性和简单性,进一步将提示调优引入视觉(Jia et al . 2022)和视觉语言模型(Radford et al . 2021);Zhou等2022;Tsimpoukelli等2021;Alayrac et al . 2022)。最近,有一些作品将提示作为改进特定任务表现的指导。例如,**Qin等人(2023)开发了一种自动生成医疗提示的方法,以提高预训练的视觉语言模型对医疗对象检测的知识可转移性。**Ge等(2022)提出将领域信息嵌入到提示符中进行无监督域自适应,使模型根据嵌入的领域信息学习特定于领域的特征。在本文中,我们建议将诊断结果转换为提示以指导报告生成。据我们所知,这是第一个将提示引入核磁共振成像任务的工作。
方法
在本节中,我们首先介绍了我们模型的总体框架,然后分别介绍了我们提出的模块,即DDP、CFE和SDL。
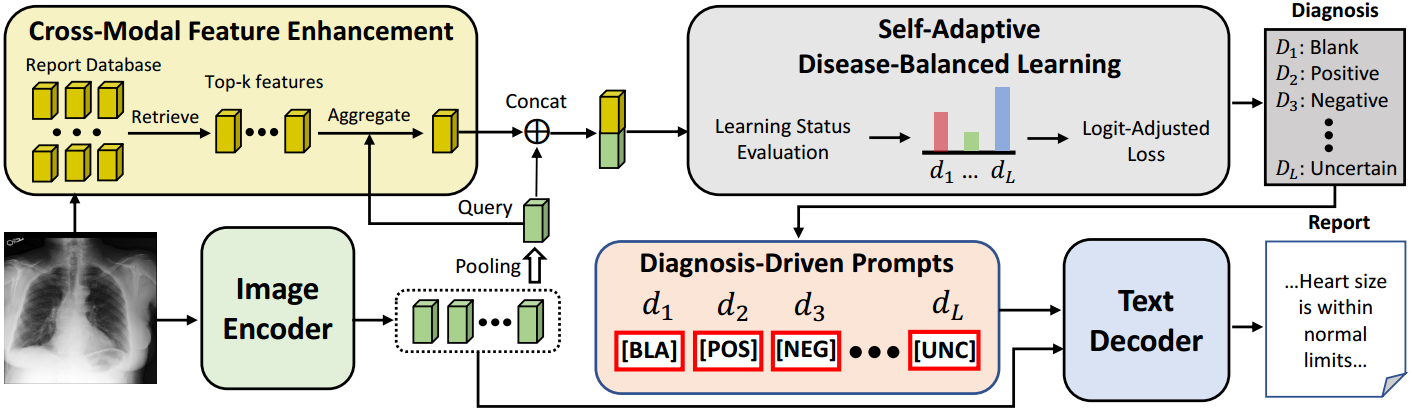
图2:PromptMRG的整体框架,它主要由一个图像编码器和一个用于生成报告的文本解码器组成。提出了诊断驱动提示模块,用于指导解码器生成诊断正确的报告。跨模态特征增强旨在通过报告数据库增强疾病分类的特征。进一步提出了自适应疾病平衡学习来处理疾病间的不平衡性能。
框架
整个体系结构如图2所示。可以看到,PromptMRG遵循主流编码器-解码器架构,其中编码器 f e f_e fe提取图像的视觉特征 I I I,解码器 f d f_d fd生成基于视觉特征和诊断驱动提示的报告 R R R。
形式上,我们将视觉特征提取表示为
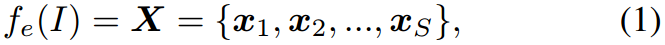
式中 x i ∈ R C x_i \in R^C xi∈RC为patch tokens, C C C为特征维数, S S S为patch数。我们将每个报告表示为 R = { r 1 , r 2 , . . . , r T } , r i ∈ V R=\{r_1,r_2,...,r_T\},r_i \in V R={r1,r2,...,rT},ri∈V,其中每个 r i r_i ri是一个token, T T T是报告的长度, V V V表示词汇表。解码的过程表示为
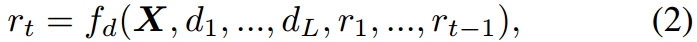
其中 r t r_t rt是在时间步长 t t t和 { d 1 , . . . , d L } \{d_1,...,d_L\} {d1,...,dL}是诊断驱动的提示(参见下一小节)。语言建模损失作为主要损失:
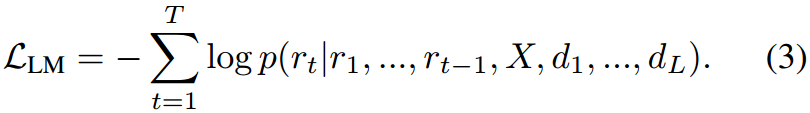
Diagnosis-Driven Prompt
生成与诊断结果一致的文本对MRG的任务至关重要。这是因为医学图像的报告不仅要提供全面的总结,而且要反映临床意义。如果生成的报告在诊断上不准确,它可能会给出错误的检查结论,从而导致严重的后果。然而,我们观察到现有的模型很难产生令人满意的临床疗效报告。具体来说,我们在MIMIC训练集上训练了一个香草疾病分类模型,并将其与SOTA MRG方法在MIMIC测试集上的F1分数进行了比较。从图1(b)所示的结果中,我们看到分类模型在很大程度上优于大多数SOTA方法,这表明现有的MRG模型仍然缺乏生成诊断准确报告的能力。
基于上述观察,我们提出了诊断驱动提示(DDP),它作为文本解码器的指导,通过传递来自疾病分类分支的诊断结果。分支以交叉模态增强的视觉特征平均集合作为输入(见下一小节),通过 L L L个分类头输出分类结果,其中 L L L为疾病数。每个分类头通过一个全连通层进行4类分类任务,即“空白”、“肯定”、“否定”和“不确定”。通过CheXbert (Smit et al . 2020)将报告转换为14个预定义的疾病标签,可以获得分类标签,并且可以使用标准交叉熵损失 L C E L_{CE} LCE进行训练。
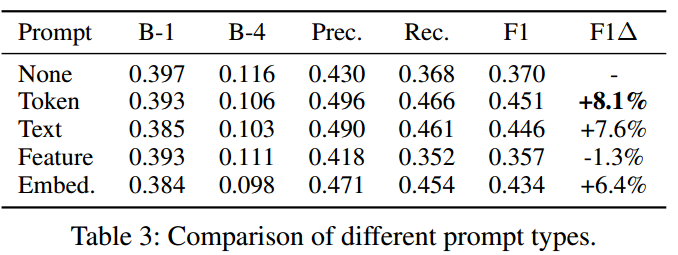
在推理过程中,将分类结果转换为标记提示,其中每个标记提示对应一种疾病。为了实现这一点,我们向词汇表添加了四个新标记,[BLA]、[POS]、[NEG]和[UNC],分别表示这四个分类类。这样,解码器可以明确地参考这些提示,生成具有更好临床疗效的报告。我们还给出了定量结果来比较不同类型的提示和定性示例,以展示提示如何通过注意力权重指导生成过程(见实验)。
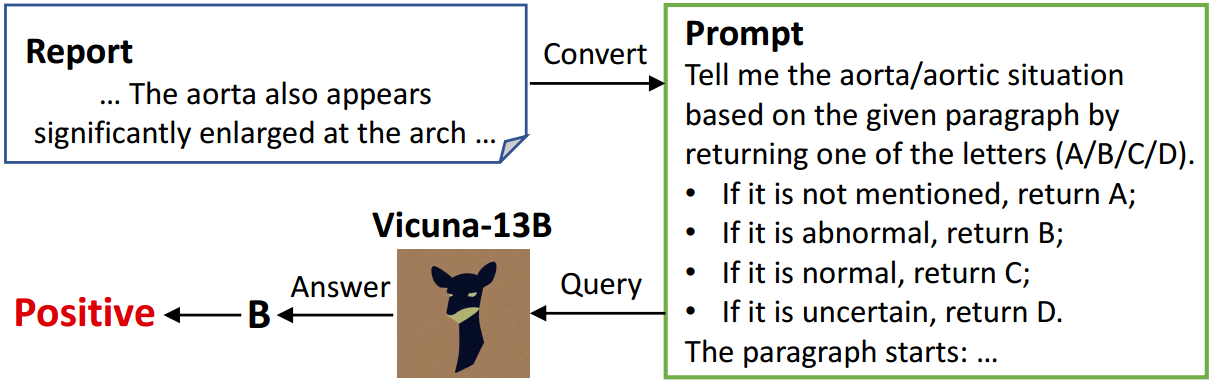
用LLM辅助疾病标记
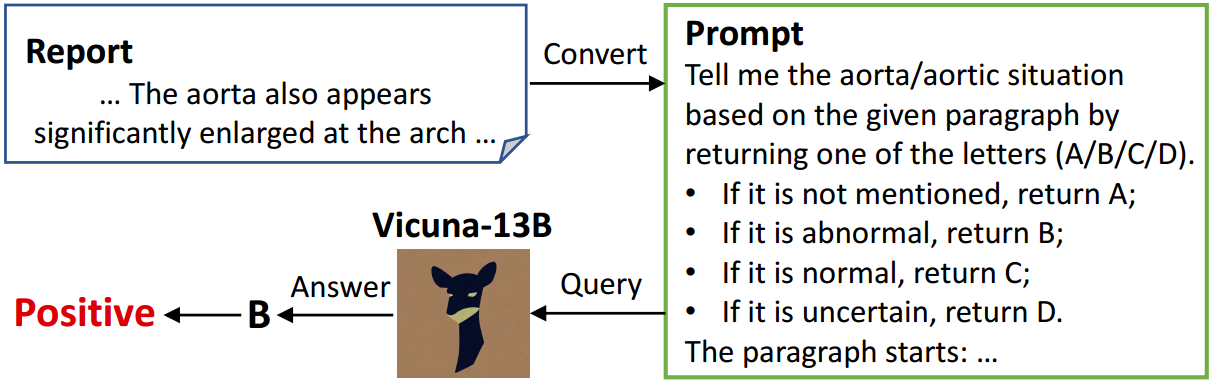
图3:我们用来查询Vicuna-13B中的Aorta标签的示例提示符。
我们发现,我们的训练数据报告涵盖了比预定义的14种疾病更多的异常,这些额外的疾病信息也有助于准确诊断。因此,我们利用大型语言模型(LLMs)的能力来获得四种辅助异常的标签,包括1)主动脉,2)骨/脊柱,3)半隔膜和4)肺容量。具体来说,我们使用Vicuna-13B (Zheng et al . 2023)作为我们的标签助手,我们在报告中提供与疾病相关的提示,用于查询目标疾病的标签。图3显示了一个用于辅助疾病标记的示例提示符
跨模态特征增强
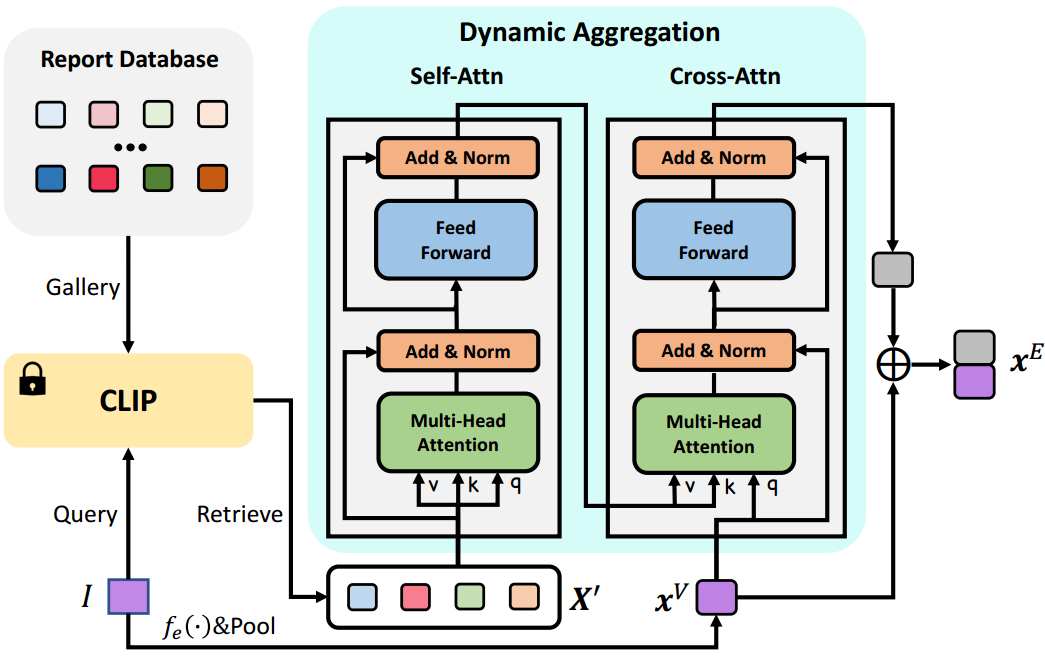
图4:跨模态特征增强的架构。
仅仅基于医学图像进行诊断可能不是最理想的,因为放射科医生通常可以访问额外的文档作为参考,例如患者信息和诊断数据库。受此启发,除了视觉特征外,我们还借助训练数据的报告数据库来获得更鲁棒的疾病分类特征。为此,我们提出了跨模态特征增强(cross-modal feature enhancement, CFE),其架构如图4所示。在CFE中,我们首先利用在MIMIC训练集上预训练的CLIP模型(Endo等 2021)来执行跨模态检索,这为我们提供了给定图像 I I I的top- k k k报告特征,然后这些特征通过动态聚合(DA)模块聚合成嵌入,该模块进一步与疾病分类的视觉特征。形式上,我们有
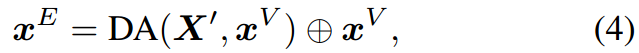
其中 X ′ = { x 1 ′ , . . . , x k ′ } X'=\{x_1',...,x_k'\} X′={x1′,...,xk′}为检索到的top-k个报告特征, x V x^V xV为汇聚的平均视觉特征,⊕表示拼接。为了根据视觉特征 x V x^V xV动态提取报告特征,我们将数据处理实现为Transformer注意力模块(Vaswani et al . 2017)。 X ′ X' X′首先经过自注意层,然后输出作为交叉注意层的键和值,而 X V X^V XV是查询。因此,DA可以表示为
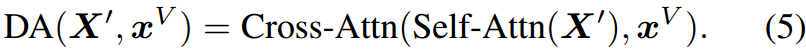
请注意,DA模块是可训练的,而CLIP在训练期间被冻结。我们认为CFE的理念类似于放射科医生的工作流程**。在临床实践中,当放射科医生对新的医学图像的诊断不确定时,他们可能会参考过去的记录进行比较和验证**,从而使结果更加可靠。
自适应疾病平衡学习
由于疾病的偏倚性,有些异常在报告中很常见,而有些则很罕见。这种不平衡的分布会导致疾病学习的不平衡,常见的疾病可以很好地识别,而罕见的疾病表现不佳。这也适用于最大的MRG数据集MIMIC (Chen et al 2020;Nicolson, Dowling, and Koopman 2022)。为了验证这一点,我们在MIMIC上训练了一个香草MRG模型(即我们的基线),并分别绘制了14种疾病的F1评分。从图1©可以看出,不同疾病之间的性能差距可能相当大。这种不平衡问题使得罕见病的诊断不可靠,从而严重影响MRG的临床应用。尽管之前的一些研究已经注意到这个问题(Chen et al 2020;Nicolson, Dowling, and Koopman 2022),没有提出明确解决这个问题的解决方案。这可能是由于文本解码器对疾病不敏感,因为它仅根据可能性生成单词,而不区分不同的疾病。因此,通过解码器操纵疾病的分布并不是直截了当的。
在本文中,我们的目标是通过分类分支来解决不平衡问题,因为它直接关系到不同疾病的学习。当在分类分支中处理不平衡问题时,然后可以使用疾病平衡结果来指导通过建议的提示生成报告。为此,我们提出了自适应疾病平衡学习(self-adaptive disease-balanced learning, SDL)算法,**该算法可以根据不同疾病的学习状态自适应地调整学习目标。**为了平衡疾病之间的学习,我们引入了逻辑调整损失(Menon et al 2020),这鼓励罕见疾病在优化过程中通过减少其逻辑来学习更多。对于给定的疾病 D D D,其对标签P的对数调整损失(即正)表示为
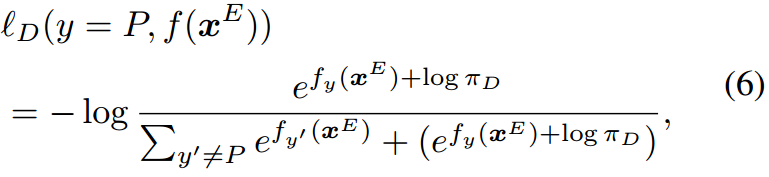
其中 f y ( x E ) f_y(x^E) fy(xE)为 y y y类的logit, π D \pi_D πD为 D D D类疾病的分布。非阳性标签的损失与 L C E L_{CE} LCE相同。
然而,用于logit调整的固定类分布(Menon et al 2020)不能反映疾病的学习动态,因为这些疾病不仅分布不同,而且学习困难也不同。图1©也描述了这个问题,其中疾病按照训练次数的升序排列,并且它们的性能并不一定随着训练次数的增加而提高。受Zhang等人(2021)的启发,**我们提出利用预测分数来评估不同疾病的学习状态:分数大表明疾病学习得好,分数小表明疾病学习不够。**因此,可以用训练数据的统计量初始化类分布 π \pi π,然后用下式自适应更新:
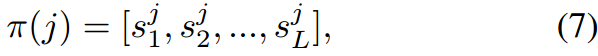
其中, s i j s_i^j sij为第 i i i种疾病在第 j j j个epoch的验证集上的平均预测分数。我们将SDL的损失记为 L S D L L_{SDL} LSDL,我们的模型的总训练损失为
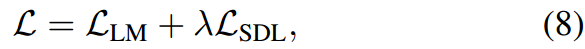
其中 λ \lambda λ是平衡系数。
实验
总结及未来工作
在这项工作中,我们提出了一个MRG框架来解决对CE不满意的问题,其中来自疾病分类分支的诊断结果被转换为提示以指导报告生成。提出了CFE模块,通过跨模态检索和动态聚合增强特征,进一步提高诊断准确率。在两个数据集上进行实验证明了我们方法的优越性,特别是它在生成诊断正确报告方面的优势,弥合了当前MRG模型与临床实践需求之间的差距。
虽然实验是基于胸部x光,但我们的方法可能适用于其他模式。然而,有几个问题需要解决。首先,需要疾病标签来训练分类分支。幸运的是,大多数MRG数据集都包含这样的标签。在没有提供标签的情况下,可以使用无监督聚类算法将报告分组为有意义的聚类。其次,CFE中的CLIP需要足够数量的图像报告对进行域适应,这对于数据有限的域来说是具有挑战性的。FFA-IR (Li et al 2021)是验证我们眼底图像方法的理想数据集,因为它的规模和疾病多样性,我们将其留给未来的工作。此外,我们将利用更丰富和细粒度的信息进行提示,这可能有利于语言精度和诊断准确性。
参考资料
论文下载(AAAI 2024)
https://arxiv.org/abs/2308.12604
代码地址
https://github.com/jhb86253817/PromptMRG
参考文章
https://blog.csdn.net/a14285700/article/details/137528196?spm=1001.2014.3001.5502