Infini-attention机制为Transformer在具有挑战性的长语境任务中释放出了新的能力,对于调整现有模型以适应长输入也非常实用。
谷歌的最新研究成果Infini-attention机制(无限长注意力)将内存压缩引入了传统注意力机制,并在单个Transformer块中构建了掩码局部注意力和长期线性注意力机制。
这一创新使得Transformer架构的大模型能够在有限的计算资源下处理无限长的输入,在内存使用上实现了114倍的压缩比。(相当于一个能够存放100本书的图书馆,通过新技术可以存储11400本书)

当前,Transformer 的改进研究正如火如荼,是学术界的热门话题之一,这次谷歌对Transformer的改进为其后续的上下游任务的研究提供了丰富的研究素材和灵感。
Infini-attention
Leave No Context Behind: Efficient Infinite Context Transformers with Infini-attention
google(DeepMind)
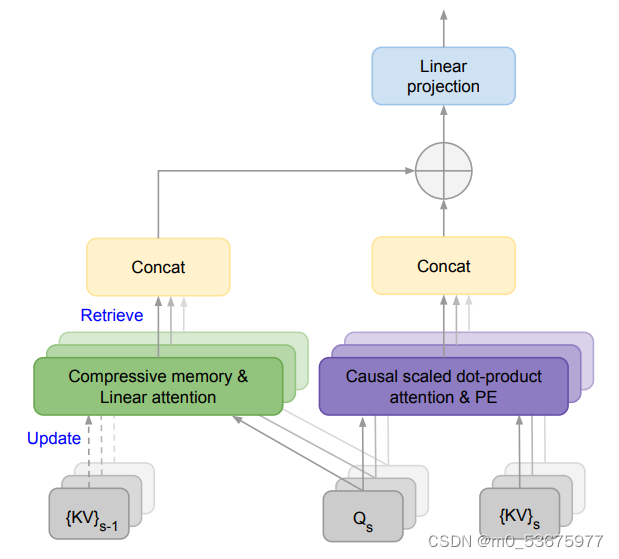
方法:论文介绍了一种有效的策略,能够将基于Transformer的大型语言模型(LLMs)扩展到在有限内存和计算资源条件下处理无限长输入。该策略的关键组成部分是一种称为Infini-attention的新型注意机制。Infini-attention将内存压缩引入传统的注意机制,并在单个Transformer块中结合了掩码局部注意力和长期线性注意力机制。
创新点:
- Infini-attention:引入了一种实用且强大的注意机制,结合了长期压缩记忆和局部因果注意力,有效地对长距离和短距离的上下文依赖关系进行建模。
- 压缩记忆:在Infini-attention中,通过重用点积注意力计算中的查询、键和值状态(Q、K和V),而不是为压缩记忆计算新的记忆条目。这种状态共享和重用实现了点积注意力和压缩记忆之间的高效长上下文适应,并加快了训练和推理的速度。
结语
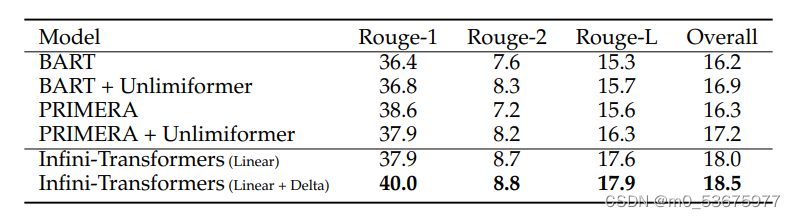
Infini-attention 机制为 Transformer 语言模型处理超长上下文提供了一种高效而强大的方法,同时不会对内存或计算量造成过多的增加。该方法在具有挑战性的长语境任务中释放出了新的能力,对于调整现有模型以适应长输入也非常实用。实验证明,与之前的方法相比,该方法在性能、压缩和泛化方面都有很强的优势。总之,这项工作为提高长语境语言建模的可扩展性和有效性做出了重大贡献