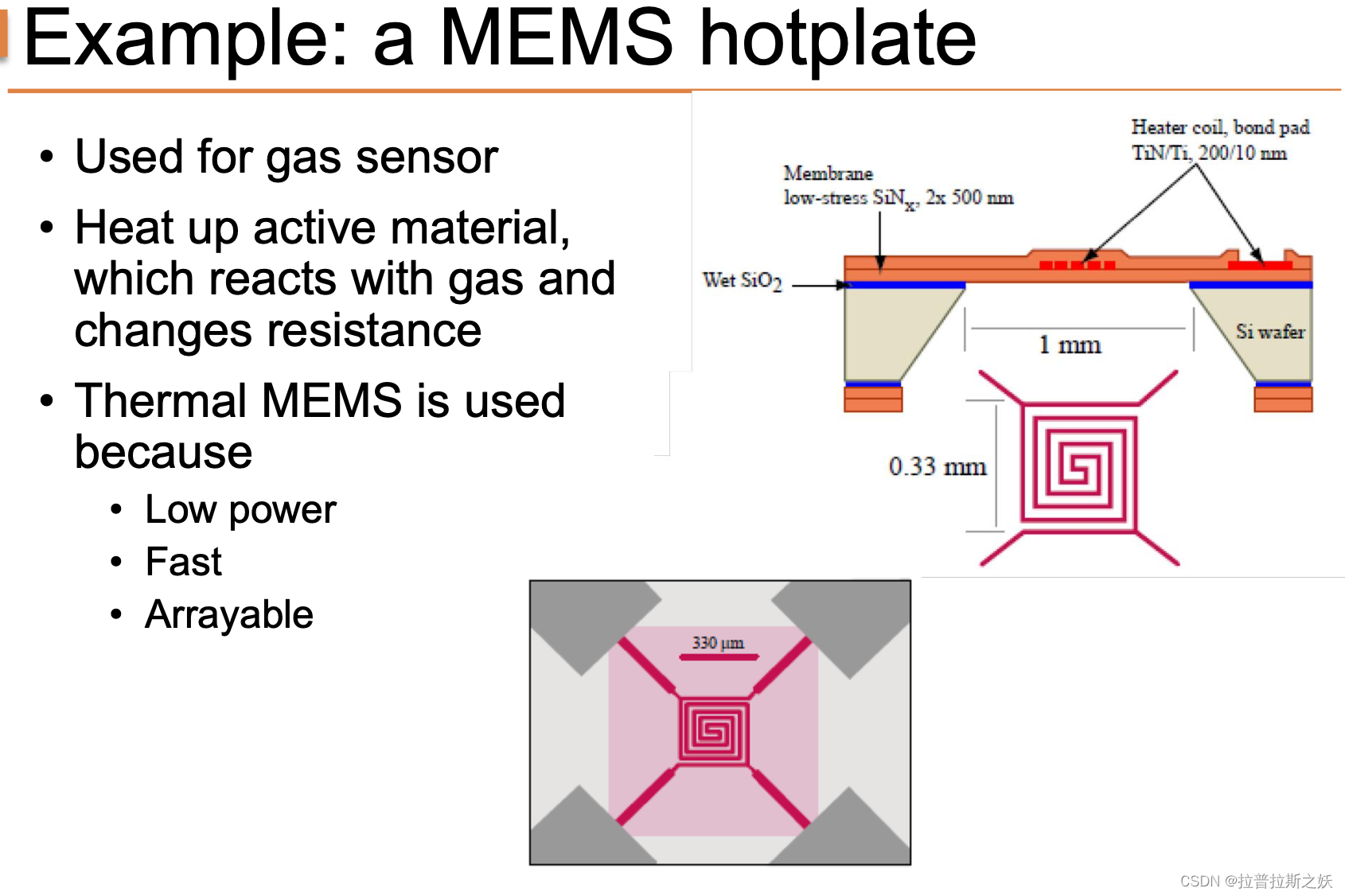
Lecture 9: Feature Analysis and Dimensionality Reduction
特征选择(Feature Selection)
特征选择的定义与目标
定义:特征选择指的是从原始特征集中选择一个子集,以减少特征的数量并提升模型的性能。选择的特征子集应当能最好地表示原始数据,从而提高分类器或回归模型的效果。
目标:
- 提高模型的性能:选择能够提升模型分类准确性或预测效果的特征。
- 减少计算成本:降低数据的维度,从而减少计算复杂度和训练时间。
- 提升模型的泛化能力:通过减少冗余特征和噪声,降低模型过拟合的风险。
- 提高可解释性:减少特征数量,使得模型更容易理解和解释。
特征选择的方法
特征选择算法主要可以分为三类:过滤法(Filter Method)、包裹法(Wrapper Method)和嵌入法(Embedded Method)。
1. 过滤法(Filter Method)
概述:过滤法不依赖于后续的模型训练和验证过程,而是根据特征自身的统计特性来进行选择。这种方法通常简单快速,适用于处理大规模数据。
方法:
- 方差选择法:根据特征的方差大小来选择特征。方差越大,特征越有区分能力。
- 卡方检验:用于分类任务,通过检验特征与标签之间的独立性来选择特征。
- 互信息法:测量特征与标签之间的互信息量,以此来选择特征。
- Fisher’s Score:计算每个特征的Fisher比率,以此来选择具有最大区分能力的特征。
F R = ( μ 1 − μ 2 ) 2 σ 1 2 + σ 2 2 , FR=\frac{(\mu_1-\mu_2)^2}{\sigma_1^2+\sigma_2^2}, FR=σ12+σ22(μ1−μ2)2,
优缺点: - 优点:速度快、计算简单、适合高维数据。
- 缺点:忽略了特征之间的交互作用,可能导致选择的特征子集对模型效果提升有限。
2. 包裹法(Wrapper Method)
概述:包裹法直接利用后续模型的性能作为特征选择的评价标准。它通过不断地添加或删除特征来优化模型的性能,属于一种搜索方法。
方法:
- 前向选择(Forward Selection):从空集开始,逐步添加特征,每次添加一个特征使得模型性能最好。
- 后向选择(Backward Elimination):从完整特征集开始,逐步删除特征,每次删除一个对模型性能影响最小的特征。
- 递归特征消除(Recursive Feature Elimination, RFE):反复构建模型,根据特征的重要性对特征进行排序,每次删除排名最低的特征。
优缺点:
- 优点:考虑了特征之间的交互作用,能够找到与模型最匹配的特征集。
- 缺点:计算开销大,尤其在特征数量多时,训练时间较长。
示例:
- SVM+前向选择:初始化为空集,逐步添加特征,每次添加一个特征后训练SVM,选择对模型性能提升最大的特征,直至达到预定的特征数量。
3. 嵌入法(Embedded Method)
概述:嵌入法将特征选择过程与模型训练过程融合在一起。通过在模型训练过程中对特征进行选择,从而减少计算开销并优化特征集。
方法:
- 正则化方法:通过引入正则化项(如L1正则化)来约束模型参数,自动选择重要的特征。
- 决策树和随机森林:利用树模型的特性,自动进行特征选择,重要性得分较低的特征可以被剔除。
优缺点:
- 优点:计算效率高,能够与模型训练同步进行,适合处理高维数据。
- 缺点:依赖于具体的模型,可能不具有通用性。
示例:
- SVM-RFE(顺序后向选择):从完整特征集开始,训练线性SVM,根据权重系数的大小递归删除权重最小的特征,直到达到预定的特征数量。
特征提取(Feature Extraction)
1. 特征提取的定义与目的
定义:特征提取是通过某种变换或映射,将原始高维特征空间的数据转换为一个低维特征空间。这个低维特征空间可以更好地表示数据的内在结构,减少数据的冗余,并提高模型的学习效率。
目的:
- 降低维度:通过提取新特征,将高维数据转化为低维数据,减少计算复杂度。
- 去除噪声:提取新特征可以过滤掉原始数据中的噪声,提高数据的质量。
- 提高模型性能:通过选择性地提取信息丰富的特征,可以提高模型的分类和回归性能。
- 可视化:将高维数据降维后,便于数据的可视化和解释。
2. 线性特征提取方法
线性特征提取方法是通过线性变换来将原始特征转换为新特征的技术。常见的线性特征提取方法包括主成分分析(PCA)和Fisher判别分析(FDA)。
2.1 主成分分析(PCA)
概述:PCA是一种无监督的线性降维技术,通过找到数据的主成分,将数据投影到一个新的坐标系中,新的坐标轴是数据中方差最大的方向。
步骤:
- 数据标准化:将数据中心化(每个特征减去其均值),并标准化(除以标准差),使数据均值为0,方差为1。
- 计算协方差矩阵:计算标准化数据的协方差矩阵,衡量特征之间的相关性。
- 计算特征值和特征向量:对协方差矩阵进行特征值分解,得到特征值和对应的特征向量。
- 选择主成分:根据特征值的大小选择主要的几个特征向量,这些特征向量是新的坐标轴,即主成分。
- 转换数据:将原始数据投影到主成分上,得到降维后的数据。
数学公式:
设数据矩阵为 X X X,其协方差矩阵为 C = 1 n X T X C = \frac{1}{n} X^T X C=n1XTX。通过对 C C C 进行特征值分解,得到特征值和特征向量:
C v i = λ i v i C v_i = \lambda_i v_i Cvi=λivi
其中, λ i \lambda_i λi 是特征值, v i v_i vi 是对应的特征向量。选择最大的几个特征值对应的特征向量,作为主成分。
优缺点:
- 优点:简单易用,计算效率高,能够有效降低维度。
- 缺点:仅适用于线性相关的数据,不能处理非线性数据关系。
2.2 Fisher判别分析(FDA)
概述:FDA是一种有监督的线性降维技术,通过最大化类间散度和最小化类内散度来找到最优的投影方向,以提高分类的可分性。
步骤:
- 计算类内散度矩阵:对于每一类数据,计算其均值向量,然后计算每个样本与类内均值的差值的平方和。
- 计算类间散度矩阵:计算各类均值向量与总体均值向量的差值的平方和。
- 求解优化问题:通过最大化类间散度与类内散度之比,找到最优的投影向量。
数学公式:
类内散度矩阵 S w S_w Sw:
S w = ∑ i = 1 c ∑ j = 1 n i ( x i j − μ i ) ( x i j − μ i ) T S_w = \sum_{i=1}^c \sum_{j=1}^{n_i} (x_{ij} - \mu_i)(x_{ij} - \mu_i)^T Sw=i=1∑cj=1∑ni(xij−μi)(xij−μi)T
其中, x i j x_{ij} xij 是第 i i i 类的第 j j j 个样本, μ i \mu_i μi 是第 i i i 类的均值向量。类间散度矩阵 S b S_b Sb:
S b = ∑ i = 1 c n i ( μ i − μ ) ( μ i − μ ) T S_b = \sum_{i=1}^c n_i (\mu_i - \mu)(\mu_i - \mu)^T Sb=i=1∑cni(μi−μ)(μi−μ)T
其中, μ \mu μ 是所有样本的总体均值向量, n i n_i ni 是第 i i i 类的样本数。目标函数:
J ( w ) = w T S b w w T S w w J(w) = \frac{w^T S_b w}{w^T S_w w} J(w)=wTSwwwTSbw
通过最大化 J ( w ) J(w) J(w),找到最优的投影向量 w w w。
优缺点:
- 优点:能够有效提高分类器的性能,特别适合处理有监督的分类问题。
- 缺点:假设数据服从正态分布,且只适用于线性可分的情况。
例题
你有一个二分类数据集,其中每个样本有两个特征。目标是使用Fisher判别分析(FDA)进行特征提取,以找到一个一维投影,使得两类样本在这个投影上的可分性最大。
假设数据集如下:
| 样本 | 特征1 | 特征2 | 类别 |
|---|---|---|---|
| 1 | 2.5 | 2.4 | A |
| 2 | 0.5 | 0.7 | A |
| 3 | 2.2 | 2.9 | A |
| 4 | 1.9 | 2.2 | A |
| 5 | 3.1 | 3.0 | A |
| 6 | 2.3 | 2.7 | A |
| 7 | 2.0 | 1.6 | B |
| 8 | 1.0 | 1.1 | B |
| 9 | 1.5 | 1.6 | B |
| 10 | 1.1 | 0.9 | B |
| 11 | 1.2 | 1.0 | B |
| 12 | 1.6 | 1.1 | B |
步骤1:计算类内散度矩阵 S w S_w Sw
类内散度矩阵 S w S_w Sw 衡量同一类样本之间的离散程度。公式为:
S w = ∑ i = 1 c ∑ j = 1 n i ( x i j − μ i ) ( x i j − μ i ) T S_w = \sum_{i=1}^c \sum_{j=1}^{n_i} (x_{ij} - \mu_i)(x_{ij} - \mu_i)^T Sw=i=1∑cj=1∑ni(xij−μi)(xij−μi)T
首先计算每类的均值向量:
类别A的均值向量:
μ A = ( 2.5 + 0.5 + 2.2 + 1.9 + 3.1 + 2.3 6 , 2.4 + 0.7 + 2.9 + 2.2 + 3.0 + 2.7 6 ) = ( 2.1 , 2.32 ) \mu_A = \left( \frac{2.5 + 0.5 + 2.2 + 1.9 + 3.1 + 2.3}{6}, \frac{2.4 + 0.7 + 2.9 + 2.2 + 3.0 + 2.7}{6} \right) = (2.1, 2.32) μA=(62.5+0.5+2.2+1.9+3.1+2.3,62.4+0.7+2.9+2.2+3.0+2.7)=(2.1,2.32)类别B的均值向量:
μ B = ( 2.0 + 1.0 + 1.5 + 1.1 + 1.2 + 1.6 6 , 1.6 + 1.1 + 1.6 + 0.9 + 1.0 + 1.1 6 ) = ( 1.4 , 1.22 ) \mu_B = \left( \frac{2.0 + 1.0 + 1.5 + 1.1 + 1.2 + 1.6}{6}, \frac{1.6 + 1.1 + 1.6 + 0.9 + 1.0 + 1.1}{6} \right) = (1.4, 1.22) μB=(62.0+1.0+1.5+1.1+1.2+1.6,61.6+1.1+1.6+0.9+1.0+1.1)=(1.4,1.22)
然后计算类内散度矩阵:
对于类别A:
S w A = ∑ i = 1 6 ( x i − μ A ) ( x i − μ A ) T S_w^A = \sum_{i=1}^{6} (x_i - \mu_A)(x_i - \mu_A)^T SwA=i=1∑6(xi−μA)(xi−μA)T具体计算每个样本的偏差:
- 样本1: ( 2.5 , 2.4 ) − ( 2.1 , 2.32 ) = ( 0.4 , 0.08 ) (2.5, 2.4) - (2.1, 2.32) = (0.4, 0.08) (2.5,2.4)−(2.1,2.32)=(0.4,0.08)
- 样本2: ( 0.5 , 0.7 ) − ( 2.1 , 2.32 ) = ( − 1.6 , − 1.62 ) (0.5, 0.7) - (2.1, 2.32) = (-1.6, -1.62) (0.5,0.7)−(2.1,2.32)=(−1.6,−1.62)
- 样本3: ( 2.2 , 2.9 ) − ( 2.1 , 2.32 ) = ( 0.1 , 0.58 ) (2.2, 2.9) - (2.1, 2.32) = (0.1, 0.58) (2.2,2.9)−(2.1,2.32)=(0.1,0.58)
- 样本4: ( 1.9 , 2.2 ) − ( 2.1 , 2.32 ) = ( − 0.2 , − 0.12 ) (1.9, 2.2) - (2.1, 2.32) = (-0.2, -0.12) (1.9,2.2)−(2.1,2.32)=(−0.2,−0.12)
- 样本5: ( 3.1 , 3.0 ) − ( 2.1 , 2.32 ) = ( 1.0 , 0.68 ) (3.1, 3.0) - (2.1, 2.32) = (1.0, 0.68) (3.1,3.0)−(2.1,2.32)=(1.0,0.68)
- 样本6: ( 2.3 , 2.7 ) − ( 2.1 , 2.32 ) = ( 0.2 , 0.38 ) (2.3, 2.7) - (2.1, 2.32) = (0.2, 0.38) (2.3,2.7)−(2.1,2.32)=(0.2,0.38)
S w A = ∑ ( ( 0.4 , 0.08 ) ( − 1.6 , − 1.62 ) ( 0.1 , 0.58 ) ( − 0.2 , − 0.12 ) ( 1.0 , 0.68 ) ( 0.2 , 0.38 ) ) × ( ( 0.4 , 0.08 ) ( − 1.6 , − 1.62 ) ( 0.1 , 0.58 ) ( − 0.2 , − 0.12 ) ( 1.0 , 0.68 ) ( 0.2 , 0.38 ) ) T S_w^A = \sum \begin{pmatrix} (0.4, 0.08) \\ (-1.6, -1.62) \\ (0.1, 0.58) \\ (-0.2, -0.12) \\ (1.0, 0.68) \\ (0.2, 0.38) \end{pmatrix} \times \begin{pmatrix} (0.4, 0.08) \\ (-1.6, -1.62) \\ (0.1, 0.58) \\ (-0.2, -0.12) \\ (1.0, 0.68) \\ (0.2, 0.38) \end{pmatrix}^T SwA=∑ (0.4,0.08)(−1.6,−1.62)(0.1,0.58)(−0.2,−0.12)(1.0,0.68)(0.2,0.38) × (0.4,0.08)(−1.6,−1.62)(0.1,0.58)(−0.2,−0.12)(1.0,0.68)(0.2,0.38) T
由于计算过程繁琐,我们简化计算,最终结果为一个2x2矩阵。
对于类别B,采用同样的方法计算 S w B S_w^B SwB。
S w = S w A + S w B S_w = S_w^A + S_w^B Sw=SwA+SwB
步骤2:计算类间散度矩阵 S b S_b Sb
类间散度矩阵 S b S_b Sb 衡量不同类样本之间的离散程度。公式为:
S b = ∑ i = 1 c n i ( μ i − μ ) ( μ i − μ ) T S_b = \sum_{i=1}^c n_i (\mu_i - \mu)(\mu_i - \mu)^T Sb=i=1∑cni(μi−μ)(μi−μ)T
其中, μ \mu μ 是所有样本的总体均值向量:
μ = ( 2.1 + 1.4 2 , 2.32 + 1.22 2 ) = ( 1.75 , 1.77 ) \mu = \left( \frac{2.1 + 1.4}{2}, \frac{2.32 + 1.22}{2} \right) = (1.75, 1.77) μ=(22.1+1.4,22.32+1.22)=(1.75,1.77)
计算类间散度矩阵:
S b = 6 × ( μ A − μ ) ( μ A − μ ) T + 6 × ( μ B − μ ) ( μ B − μ ) T S_b = 6 \times (\mu_A - \mu)(\mu_A - \mu)^T + 6 \times (\mu_B - \mu)(\mu_B - \mu)^T Sb=6×(μA−μ)(μA−μ)T+6×(μB−μ)(μB−μ)T
步骤3:求解优化问题
Fisher判别分析的目标是最大化类间散度与类内散度之比:
J ( w ) = w T S b w w T S w w J(w) = \frac{w^T S_b w}{w^T S_w w} J(w)=wTSwwwTSbw
通过特征值分解,求解最优的投影向量 w w w。
3. 非线性特征提取方法
非线性特征提取方法用于处理非线性数据结构。常见的非线性方法包括核主成分分析(Kernel PCA)和t-SNE(t-Distributed Stochastic Neighbor Embedding)。
3.1 核主成分分析(Kernel PCA)
概述:Kernel PCA通过将数据映射到高维空间,在高维空间中进行PCA,以捕捉数据的非线性结构。先升维(转为线性),再pca
步骤:
- 选择核函数:选择合适的核函数 k ( x , y ) k(x, y) k(x,y),如多项式核、RBF核等。
- 计算核矩阵:计算样本点在高维空间中的内积,形成核矩阵 K K K。
- 特征值分解:对核矩阵进行特征值分解,得到特征值和特征向量。
- 选择主成分:选择最大的几个特征值对应的特征向量,作为新的特征。
优缺点:
- 优点:能够处理非线性数据,捕捉复杂的数据结构。
- 缺点:计算复杂度高,难以选择合适的核函数和参数。
3.2 t-SNE(t-分布随机邻居嵌入)
概述:t-SNE是一种非线性降维技术,特别适合高维数据的可视化。它通过保持局部邻居结构,将高维数据嵌入到低维空间。
步骤:
- 计算高维数据的相似度:计算每对样本之间的欧氏距离,并将其转换为条件概率,表示样本点之间的相似度。
- 计算低维嵌入的相似度:在低维空间中,随机初始化数据点的位置,并计算相应的条件概率。
- 最小化KL散度:通过梯度下降法,最小化高维和低维数据之间的KL散度,调整低维数据的位置,保持高维空间的邻居关系。
优缺点:
- 优点:能够有效地保持数据的局部结构,适合可视化高维数据。
- 缺点:计算复杂度高,适用性较窄,不适合用于实际的特征提取任务。
4. 低维数据表示方法
低维数据表示通过将高维数据映射到低维空间,保留数据的拓扑结构,帮助发现数据的内在模式和规律。常见方法包括多维缩放(MDS)和局部线性嵌入(LLE)。
4.1 多维缩放(MDS)
概述:MDS通过保留数据点之间的距离结构,将高维数据映射到低维空间,常用于数据可视化。
步骤:
- 计算距离矩阵:计算高维数据点之间的欧氏距离矩阵。
- 最小化应力函数:通过迭代优化,找到低维表示,最小化高维和低维数据之间的距离误差。
优缺点:
- 优点:能够直观地展示数据点之间的距离关系。
- 缺点:计算复杂度高,无法处理非线性数据结构。
4.2 局部线性嵌入(LLE)
概述:LLE是一种保持数据局部结构的降维方法,适合发现数据的非线性嵌入。
步骤:
- **计算
最近邻**:对每个数据点,找到其最近邻数据点集合。
2. 计算重构权重:用最近邻数据点线性重构当前数据点,计算重构权重。
3. 最小化嵌入误差:在低维空间中,找到数据点的位置,使得重构误差最小化,保持局部结构。
优缺点:
- 优点:能够有效保持数据的局部邻居关系,适合处理非线性数据。
- 缺点:计算复杂度高,对噪声敏感。
Lecture 10 Clustering
平面聚类 (Flat Clustering)
平面聚类,也称为分区聚类,是将数据集划分为若干个互不重叠的簇,使得每个数据点只能属于一个簇。
2.1 K-means算法
K-means算法是一种迭代优化算法,目标是将数据集分成K个簇,使得簇内数据点的相似性最大化,而簇间的相似性最小化。
2.1.1 K-means算法步骤
输入:
- 数据集: { x 1 , x 2 , . . . , x n } ⊂ R d \{x_1, x_2, ..., x_n\} \subset \mathbb{R}^d {x1,x2,...,xn}⊂Rd,其中每个 x i x_i xi 是d维向量。
- 簇的数量:K。
初始化:
- 随机在数据空间中初始化K个簇中心 μ 1 , μ 2 , . . . , μ K \mu_1, \mu_2, ..., \mu_K μ1,μ2,...,μK。
- 或从数据集中随机选择K个点作为初始簇中心。
迭代过程:
- 分配阶段:
- 将每个数据点 x i x_i xi 分配到最近的簇中心,计算公式为:
C k = { i : k = arg min j ∥ x i − μ j ∥ 2 } C_k = \{i : k = \arg\min_{j} \|x_i - \mu_j\|^2\} Ck={i:k=argjmin∥xi−μj∥2}
- 将每个数据点 x i x_i xi 分配到最近的簇中心,计算公式为:
- 更新阶段:
- 重新计算每个簇的簇中心,即簇中所有数据点的均值:
μ k = 1 ∣ C k ∣ ∑ i ∈ C k x i \mu_k = \frac{1}{|C_k|} \sum_{i \in C_k} x_i μk=∣Ck∣1i∈Ck∑xi
- 重新计算每个簇的簇中心,即簇中所有数据点的均值:
- 重复上述分配和更新步骤,直到簇中心不再变化或达到最大迭代次数。
- 分配阶段:
收敛准则:
- 当簇中心的变化小于设定的阈值或达到最大迭代次数时,算法停止。
2.1.2 K-means目标函数
K-means算法的目标是最小化簇内数据点到簇中心的总距离,即总畸变(total distortion)。目标函数定义为:
J ( μ , r ) = ∑ i = 1 n ∑ k = 1 K r i k ∥ x i − μ k ∥ 2 J(\mu, r) = \sum_{i=1}^{n} \sum_{k=1}^{K} r_{ik} \|x_i - \mu_k\|^2 J(μ,r)=i=1∑nk=1∑Krik∥xi−μk∥2
其中, r i k r_{ik} rik 是一个指示变量,当且仅当 x i x_i xi 属于第k个簇时 r i k = 1 r_{ik} = 1 rik=1,否则 r i k = 0 r_{ik} = 0 rik=0。
- Exact optimization of K-means objective is NP-hard
- ComplexityisO(I∗n∗K∗d)
▶ I=number of iterations, n=number of points, K=number of clusters, d=number of attributes
2.1.3 簇数量选择
选择适当的簇数量K是K-means算法的关键之一。常用的方法包括“肘部法则”(Elbow Method):
- 计算不同K值下的K-means目标函数值(总畸变)。
- 绘制目标函数值与K的关系图。
- 选择“肘部”所在的K值,即目标函数值显著减少的拐点。
2.1.4 K-means初始化问题
簇中心的初始化对K-means算法的结果影响很大,糟糕的初始化可能导致算法收敛到1局部最优解或2收敛速度慢。为缓解这一问题,可以采用以下方法:
- 多次运行K-means算法,选择最佳结果。
- Choose first center as one of examples, second which is
the farthest from the first, third which is the farthest from
both, and so on
2.1.5 K-means的局限性
硬分配:
- K-means对每个数据点进行硬分配,即一个数据点要么完全属于一个簇,要么完全不属于。
- 不能处理软分配情况,例如某点属于多个簇的概率。
对异常值敏感:
- K-means对离群点非常敏感,因为异常值会极大地影响簇中心的计算。
簇形状限制:
- K-means假设簇是凸形的,不适用于处理非凸形的簇。
解决对异常值敏感:K-median Algorithm
与K-means算法类似,但在计算簇中心时使用的是中位数而非均值。由于中位数对离群点不敏感,K-median算法在处理含有异常值的数据时更加鲁棒。使用的是L1范数(曼哈顿距离),即 ∥ x − μ ∥ 1 = ∑ i = 1 d ∣ x i − μ i ∣ \|x - \mu\|_1 = \sum_{i=1}^{d} |x_i - \mu_i| ∥x−μ∥1=∑i=1d∣xi−μi∣
优点:
对离群点不敏感:
- 由于使用中位数计算簇中心,K-median对数据集中的极端值和噪声具有较强的鲁棒性。
稳定性:
- 在处理具有不均衡分布或噪声较大的数据时,K-median通常比K-means更稳定。
缺点:
计算复杂度高:
- 中位数的计算相对均值更复杂,特别是在高维数据和大规模数据集上,计算开销较大。
算法收敛速度较慢:
- 由于中位数的计算复杂度较高,K-median算法在每次迭代中可能比K-means需要更多的时间,导致整体收敛速度较慢。
簇形状限制:
- 与K-means类似,K-median也假设簇是凸形的,不适用于处理非凸形的簇。
层次聚类 (Hierarchical Clustering)
层次聚类是一种将数据点组织成一个层次树(dendrogram)的聚类方法。该方法包括两种主要类型:自底向上(凝聚的,Agglomerative)和自顶向下(分裂的,Divisive)。
3.1 层次聚类的概念
层次聚类通过逐步合并或分裂数据点来构建一棵树状的层次结构。每个节点代表一个簇,叶节点表示单个数据点,而根节点表示包含所有数据点的簇。树状结构的不同层次表示聚类的不同粒度。
主要类型:
- 凝聚的层次聚类(自底向上): 从每个数据点作为一个单独的簇开始,逐步合并最相似的簇,直到所有数据点合并成一个簇。
- 分裂的层次聚类(自顶向下): 从所有数据点组成一个簇开始,逐步将簇分裂成更小的簇,直到每个数据点成为一个单独的簇。
3.2 凝聚的层次聚类算法
凝聚的层次聚类是最常用的层次聚类方法,其基本步骤如下:
输入:
- 数据集: { x 1 , x 2 , . . . , x n } \{x_1, x_2, ..., x_n\} {x1,x2,...,xn},其中每个 x i x_i xi 是d维向量。
初始化:
- 将每个数据点作为一个单独的簇。
迭代过程:
- 计算当前簇之间的相似性或距离。
- 合并最相似的两个簇。
- 更新簇之间的相似性或距离矩阵。
- 重复上述步骤,直到所有数据点合并成一个簇。
3.4 相似性度量方法
层次聚类中簇之间的相似性或距离度量方法有多种,常见的有:
单链(Single Link):
- 两个簇之间最相似的点之间的距离。
- 优点:适用于发现长而稀疏的簇。
- 缺点:容易形成“链”状簇,不适合紧凑簇。
全链(Complete Link):
- 两个簇之间最不相似的点之间的距离。
- 优点:适用于发现紧凑的簇。
- 缺点:对离群点敏感。
组平均(Group Average):
- 两个簇之间所有点对的平均距离。
- 优点:在单链和全链之间取得平衡。
中位数链(Median Link):
- 两个簇之间所有点对的中位数距离。
- 优点:对离群点不敏感。
3.5 分裂的层次聚类算法
分裂的层次聚类较少使用,但在某些场景下也很有效。其基本步骤如下:
输入:
- 数据集: { x 1 , x 2 , . . . , x n } \{x_1, x_2, ..., x_n\} {x1,x2,...,xn},其中每个 x i x_i xi 是d维向量。
初始化:
- 将所有数据点作为一个簇。
迭代过程:
- 选择当前簇中最不相似的点,将其分离出来形成新的簇。
- 更新簇之间的相似性或距离矩阵。
- 重复上述步骤,直到每个数据点成为一个单独的簇。
3.6 层次聚类的优缺点
优点:
直观性:
- 层次树(dendrogram)提供了直观的聚类结果表示,可以显示不同层次的聚类结构。
无须预设簇的数量:
- 不需要像K-means那样预设簇的数量。
灵活性:
- 可以根据需要在不同的层次上查看聚类结果。
缺点:
计算复杂度高:
- 层次聚类的计算复杂度通常为 O ( n 3 ) O(n^3) O(n3),不适合大规模数据集。
对噪声和离群点敏感:
- 离群点会影响簇的合并或分裂过程,导致聚类结果不稳定。
不可逆性:
- 一旦合并或分裂决定做出,不能撤销。这可能导致次优的聚类结果。
谱聚类 (Spectral Clustering)
谱聚类是一种基于图理论的聚类方法,它通过图的拉普拉斯矩阵的特征值和特征向量来进行聚类。谱聚类特别适用于处理非凸形状的簇,在处理复杂结构的数据时表现出色。
谱聚类算法步骤
谱聚类的具体步骤如下:
构建相似度矩阵:
- 给定数据点 { x 1 , x 2 , . . . , x n } \{x_1, x_2, ..., x_n\} {x1,x2,...,xn},计算每对数据点之间的相似度 w i j w_{ij} wij。
- 常用的相似度度量方法是高斯核函数:
w i j = exp ( − ∥ x i − x j ∥ 2 2 σ 2 ) w_{ij} = \exp\left(-\frac{\|x_i - x_j\|^2}{2\sigma^2}\right) wij=exp(−2σ2∥xi−xj∥2) - 得到相似度矩阵 W W W。
计算图拉普拉斯矩阵:
- 计算度矩阵 D D D,其中 D i i = ∑ j w i j D_{ii} = \sum_j w_{ij} Dii=∑jwij。
- 计算非归一化的拉普拉斯矩阵 L = D − W L = D - W L=D−W。
- 归一化的拉普拉斯矩阵 L n o r m = D − 1 / 2 L D − 1 / 2 = I − D − 1 / 2 W D − 1 / 2 L_{norm} = D^{-1/2} L D^{-1/2} = I - D^{-1/2} W D^{-1/2} Lnorm=D−1/2LD−1/2=I−D−1/2WD−1/2。
计算特征值和特征向量:
- 计算归一化拉普拉斯矩阵 L n o r m L_{norm} Lnorm 的前k个最小特征值对应的特征向量。
- 形成矩阵 U ∈ R n × k U \in \mathbb{R}^{n \times k} U∈Rn×k,其中每列为一个特征向量。
特征向量聚类:
- 将矩阵 U U U 的每一行视为一个新的数据点。
- 对这些新的数据点使用K-means算法进行聚类,得到k个簇。
谱聚类示例
给定一个简单的无向图,其中有 4 个顶点和 5 条边,其相似度(边权重)如下:
1
/ \
/ \
2-----3
\ /
\ /
4
边权重如下:
- 边 (1, 2): 1
- 边 (1, 3): 1
- 边 (2, 3): 1
- 边 (2, 4): 1
- 边 (3, 4): 1
1. 构建相似度矩阵 W W W
相似度矩阵 W W W 是一个对称矩阵,表示每对顶点之间的相似度(边权重)。对于没有直接连接的顶点,相似度为 0。
W = ( 0 1 1 0 1 0 1 1 1 1 0 1 0 1 1 0 ) W = \begin{pmatrix} 0 & 1 & 1 & 0 \\ 1 & 0 & 1 & 1 \\ 1 & 1 & 0 & 1 \\ 0 & 1 & 1 & 0 \end{pmatrix} W= 0110101111010110
2. 计算度矩阵 D D D
度矩阵 D D D 是一个对角矩阵,其中每个对角元素 D i i D_{ii} Dii 表示顶点 i i i 的度,即连接该顶点的边的权重之和。
D = ( 2 0 0 0 0 3 0 0 0 0 3 0 0 0 0 2 ) D = \begin{pmatrix} 2 & 0 & 0 & 0 \\ 0 & 3 & 0 & 0 \\ 0 & 0 & 3 & 0 \\ 0 & 0 & 0 & 2 \end{pmatrix} D= 2000030000300002
3. 计算拉普拉斯矩阵 L L L
拉普拉斯矩阵 L L L 定义为 L = D − W L = D - W L=D−W。
$$L = \begin{pmatrix}
2 & 0 & 0 & 0 \
0 & 3 & 0 & 0 \
0 & 0 & 3 & 0 \
0 & 0 & 0 & 2
\end{pmatrix}
\begin{pmatrix}
0 & 1 & 1 & 0 \
1 & 0 & 1 & 1 \
1 & 1 & 0 & 1 \
0 & 1 & 1 & 0
\end{pmatrix}
\begin{pmatrix}
2 & -1 & -1 & 0 \
-1 & 3 & -1 & -1 \
-1 & -1 & 3 & -1 \
0 & -1 & -1 & 2
\end{pmatrix}$$
4. 计算拉普拉斯矩阵的特征值和特征向量
接下来我们需要计算拉普拉斯矩阵 L L L 的特征值和特征向量。这里我们手动进行特征值分解。
特征值分解 L L L:
通过计算,假设得到以下特征值和特征向量(简化计算):
特征值: λ 1 = 0 , λ 2 = 1 , λ 3 = 3 , λ 4 = 4 \lambda_1 = 0, \lambda_2 = 1, \lambda_3 = 3, \lambda_4 = 4 λ1=0,λ2=1,λ3=3,λ4=4
对应的特征向量:
v 1 = ( 1 1 1 1 ) , v 2 = ( 1 1 − 1 − 1 ) , v 3 = ( 1 − 1 0 0 ) , v 4 = ( 0 0 1 − 1 ) v_1 = \begin{pmatrix} 1 \\ 1 \\ 1 \\ 1 \end{pmatrix}, v_2 = \begin{pmatrix} 1 \\ 1 \\ -1 \\ -1 \end{pmatrix}, v_3 = \begin{pmatrix} 1 \\ -1 \\ 0 \\ 0 \end{pmatrix}, v_4 = \begin{pmatrix} 0 \\ 0 \\ 1 \\ -1 \end{pmatrix} v1= 1111 ,v2= 11−1−1 ,v3= 1−100 ,v4= 001−1
5. 选择特征向量进行聚类
我们选择前两个最小的非零特征值对应的特征向量 v 2 v_2 v2 和 v 3 v_3 v3,并将其组成新的矩阵。
U = ( 1 1 1 − 1 − 1 0 − 1 0 ) U = \begin{pmatrix} 1 & 1 \\ 1 & -1 \\ -1 & 0 \\ -1 & 0 \end{pmatrix} U= 11−1−11−100
6. 对特征向量进行K-means聚类
将矩阵 U U U 的每一行视为一个新的数据点,并使用 K-means 算法进行聚类。对于这个例子,我们手动分配聚类:
- 顶点 1 和 2 的特征向量相似,可以分为一类。
- 顶点 3 和 4 的特征向量相似,可以分为另一类。
最终的聚类结果:
- 簇 1: 顶点 1, 2
- 簇 2: 顶点 3, 4
为什么谱聚类有效
谱聚类将数据点映射到一个低维的特征空间,在这个空间中,原来复杂的聚类问题变得容易解决。通过使用拉普拉斯矩阵的特征向量,谱聚类能够捕捉到数据中的非线性结构,使得数据在低维空间中更加可分离。
谱聚类的优缺点
优点:
处理非凸形状的簇:
- 谱聚类能够处理非凸形状的簇,而K-means等方法仅适用于凸形簇。
处理复杂结构的数据:
- 谱聚类能有效处理复杂的结构,通过特征空间的变换使得原本复杂的问题简单化。
无参数初始化问题:
- 谱聚类不依赖初始簇中心,避免了K-means的初始化敏感性问题。
缺点:
计算复杂度高:
- 计算相似度矩阵和特征向量的过程计算量大,适用于中小规模数据集,对于大规模数据集需要优化。
相似度矩阵的选择:
- 相似度矩阵的构建对聚类结果影响较大,选择合适的相似度度量是关键。
Lecture 11: Output Calibration and Learning to Rank
输出校准(Output Calibration)
输出校准是机器学习中一个重要的过程,旨在将分类器输出的数值评分转换为更精确的后验概率。输出校准的目标是找到一个映射,将分类器生成的数值评分转换为准确的后验概率。这个过程要求评分与后验概率之间存在单调关系,即评分越高,后验概率越大。
2.1 分箱法(Binning)
分箱法是最简单的校准方法之一,其步骤如下:
- 排序:将所有样本按照分类器给出的评分从高到低排序。
- 分箱:将排序后的样本划分为k个大小相等的部分(即箱),每个箱包含相同数量的样本。
- 概率计算:对每个箱,计算其中正例的比例,作为该箱的后验概率。
具体计算公式为:
p i = n i , + n i , i = 1 , … , k p_i = \frac{n_{i,+}}{n_i}, \quad i = 1, \dots, k pi=nini,+,i=1,…,k
其中, n i , + n_{i,+} ni,+表示第i个箱中的正例数量, n i n_i ni表示第i个箱中的样本总数。
分箱法的优点是简单直观,计算成本低;但缺点是分箱数k的选择对结果有较大影响,且对于评分分布较为连续的情况,分箱法可能不够精细。
2.2 Sigmoid函数映射(Mapping with Sigmoid Function)
在某些数据集中,支持向量机(SVM)的输出评分与后验概率之间常常表现出Sigmoid函数关系。因此,使用Sigmoid函数进行校准是一种有效的方法。
Sigmoid函数的形式为:
p ^ ( c ∣ x ) = 1 1 + exp ( A s ( x ) + B ) \hat{p}(c|x) = \frac{1}{1 + \exp(As(x) + B)} p^(c∣x)=1+exp(As(x)+B)1
其中, A A A和 B B B是需要通过数据拟合得到的参数, s ( x ) s(x) s(x)是分类器给出的评分。
拟合参数的方法:
- 常用的拟合方法是通过最大似然估计(MLE),即选择参数 A A A和 B B B使得在训练数据上的对数似然函数最大化。
Sigmoid函数映射的优点在于它可以处理评分与后验概率之间的非线性关系,适用于许多实际应用场景。但它也有一定的局限性,特别是当评分分布并不呈现出Sigmoid形状时,校准效果可能不佳。
2.3 邻近对违反者(Pair-Adjacent Violators, PAV)
PAV算法用于解决单调回归问题,即在保证单调性的前提下最小化误差。具体步骤如下:
- 排序:将所有样本按照分类器给出的评分从高到低排序。
- 遍历相邻样本:从排序后的样本中选取任意两个相邻样本,记为样本i和样本j,其中评分 s c o r e ( i ) > s c o r e ( j ) score(i) > score(j) score(i)>score(j)。
- 校准步骤:
- 如果两个样本标签相同,或者样本i是负例而样本j是正例,则调整这两个样本的后验概率为它们评分的平均值。
- 重复遍历和调整步骤,直到**没有违反单调性的相邻对(高分正低分负)**为止。
输出校准方法的具体应用例题
方法一:分箱法(Binning)
例题描述:
假设我们有一个简单的二分类问题,分类器对10个样本进行了评分,评分和真实标签如下表所示:
| 样本 | 评分 | 标签 |
|---|---|---|
| 1 | 0.9 | 1 |
| 2 | 0.8 | 1 |
| 3 | 0.7 | 0 |
| 4 | 0.65 | 1 |
| 5 | 0.6 | 0 |
| 6 | 0.55 | 0 |
| 7 | 0.5 | 1 |
| 8 | 0.45 | 0 |
| 9 | 0.4 | 1 |
| 10 | 0.35 | 0 |
步骤:
排序和分箱:
- 按评分从高到低排序后,样本序列为:1, 2, 3, 4, 5, 6, 7, 8, 9, 10。
- 将样本分成5个箱,每个箱包含2个样本。
分箱结果:
- 箱1:样本1和样本2(评分0.9和0.8)
- 箱2:样本3和样本4(评分0.7和0.65)
- 箱3:样本5和样本6(评分0.6和0.55)
- 箱4:样本7和样本8(评分0.5和0.45)
- 箱5:样本9和样本10(评分0.4和0.35)
计算每个箱的后验概率:
- 箱1:两个样本均为正例,后验概率为 2 2 = 1 \frac{2}{2} = 1 22=1。
- 箱2:一个正例一个负例,后验概率为 1 2 = 0.5 \frac{1}{2} = 0.5 21=0.5。
- 箱3:两个样本均为负例,后验概率为 0 2 = 0 \frac{0}{2} = 0 20=0。
- 箱4:一个正例一个负例,后验概率为 1 2 = 0.5 \frac{1}{2} = 0.5 21=0.5。
- 箱5:一个正例一个负例,后验概率为 1 2 = 0.5 \frac{1}{2} = 0.5 21=0.5。
结果:
- 样本1和2的校准后后验概率为1。
- 样本3和4的校准后后验概率为0.5。
- 样本5和6的校准后后验概率为0。
- 样本7和8的校准后后验概率为0.5。
- 样本9和10的校准后后验概率为0.5。
通过分箱法,我们将分类器的评分成功地转换为后验概率。
方法二:Sigmoid函数映射(Mapping with Sigmoid Function)
例题描述:
同样地,我们有一个分类器对一组样本进行了评分,并希望将这些评分校准为后验概率。假设评分如下:
| 样本 | 评分 | 标签 |
|---|---|---|
| 1 | 2.5 | 1 |
| 2 | 1.5 | 1 |
| 3 | 1.0 | 0 |
| 4 | 0.5 | 0 |
| 5 | 0.0 | 1 |
步骤:
Sigmoid函数:
我们采用以下Sigmoid函数进行映射:
p ^ ( c ∣ x ) = 1 1 + exp ( A s ( x ) + B ) \hat{p}(c|x) = \frac{1}{1 + \exp(A s(x) + B)} p^(c∣x)=1+exp(As(x)+B)1
假设通过数据拟合得到的参数A和B分别为1和-1。校准评分:
- 样本1: s ( 1 ) = 2.5 s(1) = 2.5 s(1)=2.5
p ^ ( c ∣ 1 ) = 1 1 + exp ( 1 ⋅ 2.5 − 1 ) = 1 1 + exp ( 1.5 ) ≈ 0.182 \hat{p}(c|1) = \frac{1}{1 + \exp(1 \cdot 2.5 - 1)} = \frac{1}{1 + \exp(1.5)} \approx 0.182 p^(c∣1)=1+exp(1⋅2.5−1)1=1+exp(1.5)1≈0.182 - 样本2: s ( 2 ) = 1.5 s(2) = 1.5 s(2)=1.5
p ^ ( c ∣ 2 ) = 1 1 + exp ( 1 ⋅ 1.5 − 1 ) = 1 1 + exp ( 0.5 ) ≈ 0.378 \hat{p}(c|2) = \frac{1}{1 + \exp(1 \cdot 1.5 - 1)} = \frac{1}{1 + \exp(0.5)} \approx 0.378 p^(c∣2)=1+exp(1⋅1.5−1)1=1+exp(0.5)1≈0.378 - 样本3: s ( 3 ) = 1.0 s(3) = 1.0 s(3)=1.0
p ^ ( c ∣ 3 ) = 1 1 + exp ( 1 ⋅ 1.0 − 1 ) = 1 1 + exp ( 0 ) = 0.5 \hat{p}(c|3) = \frac{1}{1 + \exp(1 \cdot 1.0 - 1)} = \frac{1}{1 + \exp(0)} = 0.5 p^(c∣3)=1+exp(1⋅1.0−1)1=1+exp(0)1=0.5 - 样本4: s ( 4 ) = 0.5 s(4) = 0.5 s(4)=0.5
p ^ ( c ∣ 4 ) = 1 1 + exp ( 1 ⋅ 0.5 − 1 ) = 1 1 + exp ( − 0.5 ) ≈ 0.622 \hat{p}(c|4) = \frac{1}{1 + \exp(1 \cdot 0.5 - 1)} = \frac{1}{1 + \exp(-0.5)} \approx 0.622 p^(c∣4)=1+exp(1⋅0.5−1)1=1+exp(−0.5)1≈0.622 - 样本5: s ( 5 ) = 0.0 s(5) = 0.0 s(5)=0.0
p ^ ( c ∣ 5 ) = 1 1 + exp ( 1 ⋅ 0.0 − 1 ) = 1 1 + exp ( − 1 ) ≈ 0.731 \hat{p}(c|5) = \frac{1}{1 + \exp(1 \cdot 0.0 - 1)} = \frac{1}{1 + \exp(-1)} \approx 0.731 p^(c∣5)=1+exp(1⋅0.0−1)1=1+exp(−1)1≈0.731
- 样本1: s ( 1 ) = 2.5 s(1) = 2.5 s(1)=2.5
结果:
- 样本1的校准后后验概率为0.182。
- 样本2的校准后后验概率为0.378。
- 样本3的校准后后验概率为0.5。
- 样本4的校准后后验概率为0.622。
- 样本5的校准后后验概率为0.731。
通过Sigmoid函数映射,我们将分类器的评分成功地转换为后验概率。
方法三:邻近对违反者(Pair-Adjacent Violators, PAV)
例题描述:
假设我们有一个分类器对一组样本进行了评分,并希望将这些评分校准为后验概率。评分和真实标签如下表所示:
| 样本 | 评分 | 标签 |
|---|---|---|
| 1 | 0.8 | 1 |
| 2 | 0.7 | 0 |
| 3 | 0.6 | 1 |
| 4 | 0.5 | 1 |
| 5 | 0.4 | 0 |
步骤:
排序评分:
- 样本按评分从高到低排序:样本1、样本2、样本3、样本4、样本5。
校准步骤:
- 初始化后验概率:假设初始后验概率与评分成比例,依次为0.8、0.7、0.6、0.5、0.4。
第一遍遍历:
- 样本1和2:标签不同,无需调整。
- 样本2和3:标签不同,无需调整。
- 样本3和4:标签相同,平均后验概率为0.55。
- 样本4和5:标签不同,无需调整。
第二遍遍历:
- 样本3和4:已调整,无需再调整。
结果:
- 样本1的校准后后验概率为0.8。
- 样本2的校准后后验概率为0.7。
- 样本3的校准后后验概率为0.55。
- 样本4的校准后后验概率为0.55。
- 样本5的校准后后验概率为0.4。
通过PAV算法,我们将分类器的评分成功地转换为后验概率。
这些例题展示了三种常见输出校准方法的具体应用,帮助理解和掌握这些方法的基本操作步骤和效果。
排序学习 (Learning to Rank)
1. 点对点方法 (Pointwise Approach)
概述:
点对点方法将要排序的项目单独处理,通常将其视为回归、分类或有序回归问题。它学习一个函数,该函数为每个项目分配一个绝对分数或类别,然后根据这些分数进行排序。
示例:
假设有一个包含文档及其相关性的集合,点对点方法将为每个文档分配一个分数,并根据分数进行排序。
主要步骤:
- 为每个项目分配一个分数。
- 根据分数对项目进行排序。
- 通过最小化绝对分数的误差来优化排名函数。
2. 对对方法 (Pairwise Approach)
概述:
对对方法将项目成对处理,学习一个函数来确定哪个项目在一对项目中排名更高。它的目标是减少成对比较中的误分类数量。
数据转换:
- 将原始数据集转换为成对的数据集。
- 对于每个项目对((d_i, d_j)),我们生成一个新样本 ((x_i - x_j, y_i > y_j)),其中 (x_i) 和 (x_j) 是项目的特征向量,(y_i) 和 (y_j) 是项目的标签或相关性得分。
模型训练:
- 使用二元分类算法(如逻辑回归、SVM等)来训练模型,学习函数 (f(x_i - x_j)),预测哪个项目在一对项目中排名更高。
预测与排序:
- 对于新数据,使用训练好的模型对所有可能的项目对进行比较,生成一个相对排序。
例题
假设我们有一个信息检索系统,我们希望对一组文档进行排序,以响应用户查询。我们有以下数据:
- 特征向量:每个文档的特征,如包含查询词的数量、文档长度、页面排名等。
- 目标变量:每个文档的相关性得分(例如,通过用户点击或人工评分得到)。
数据集
| 文档 | 查询词数量 | 文档长度 | 页面排名 | 相关性得分 |
|---|---|---|---|---|
| 文档1 | 5 | 200 | 0.9 | 3 |
| 文档2 | 3 | 150 | 0.8 | 2 |
| 文档3 | 7 | 300 | 0.7 | 4 |
| 文档4 | 2 | 100 | 0.6 | 1 |
数据转换
我们将数据转换为成对的数据集。对于每一对文档((d_i, d_j)),我们生成一个新样本 ((x_i - x_j, y_i > y_j))。例如:
- 对于文档1和文档2,生成新样本 ((x_1 - x_2, y_1 > y_2)),即 (({5-3, 200-150, 0.9-0.8}, 3 > 2))。
- 对于文档1和文档3,生成新样本 ((x_1 - x_3, y_1 < y_3)),即 (({5-7, 200-300, 0.9-0.7}, 3 < 4))。
通过这种方式,我们可以生成以下成对数据集:
| 差值特征向量 | 标签 |
|---|---|
| {2, 50, 0.1} | 1(正) |
| {-2, -100, 0.2} | -1(负) |
| {3, 100, 0.3} | -1(负) |
| {1, 50, 0.2} | 1(正) |
| {4, 150, 0.3} | 1(正) |
| {5, 200, 0.4} | 1(正) |
模型训练
我们使用一个二元分类算法(例如逻辑回归)来训练模型,学习函数 (f(x_i - x_j))。这个函数的目标是预测每对项目中的标签(1 或 -1),即哪个项目排名更高。
预测与排序
对于新文档集,我们使用训练好的模型对所有可能的文档对进行比较。例如,假设我们有新的文档集:
| 文档 | 查询词数量 | 文档长度 | 页面排名 |
|---|---|---|---|
| 新文档1 | 6 | 250 | 0.85 |
| 新文档2 | 4 | 200 | 0.75 |
| 新文档3 | 8 | 300 | 0.9 |
我们生成成对数据集并使用模型进行预测:
- ((x_1 - x_2) = {6-4, 250-200, 0.85-0.75} = {2, 50, 0.1})
- ((x_1 - x_3) = {6-8, 250-300, 0.85-0.9} = {-2, -50, -0.05})
- ((x_2 - x_3) = {4-8, 200-300, 0.75-0.9} = {-4, -100, -0.15})
使用模型预测每对的标签:
- (f({2, 50, 0.1})) 预测为 1(新文档1 排名高于 新文档2)
- (f({-2, -50, -0.05})) 预测为 -1(新文档1 排名低于 新文档3)
- (f({-4, -100, -0.15})) 预测为 -1(新文档2 排名低于 新文档3)
最终排序为:
- 新文档3
- 新文档1
- 新文档2
3. 列表方法 (Listwise Approach)
概述:
列表方法直接对整个项目列表进行处理,通常尝试直接优化特定任务的评估指标(例如标准折扣累积增益,NDCG)。
示例:
在信息检索中,列表方法可能会优化搜索结果的NDCG,以确保高相关性的文档出现在结果列表的顶部。
主要步骤:
- 将每个列表作为一个实例进行处理。
- 学习一个函数来优化整个列表的排序质量。
- 通过优化适当的评估指标来调整排名函数。
标准折扣累积增益 (NDCG)
折扣累积增益 (DCG):
- 定义:折扣累积增益 (DCG) 是衡量排名质量的一种指标。
- 计算方式:使用文档在搜索引擎结果集中的分级相关性来衡量文档的效用或增益,基于文档在结果列表中的位置进行折扣。
- 累积方式:从结果列表顶部开始累积增益,每个结果的增益随着位置的降低而折扣。高度相关的文档在结果列表中出现得越早,其效用就越大。
标准化折扣累积增益 (NDCG):
- 问题:由于搜索结果列表长度不同,无法通过DCG一致比较搜索引擎的性能。
- 解决方法:通过标准化DCG来解决这个问题,即对每个位置的累积增益进行标准化,使得不同查询的结果具有可比性,这就是标准化DCG (NDCG)。
DCG的定义和计算:
- 公式:[ G(y’, y) = \sum_{i=1}^r D(\pi(y’)_i) y_i ]
- 说明:其中 ( D ) 是一个递减函数,( \pi(y’)_i ) 是 ( y’_i ) 在排序向量中的位置(排名最高的实例在 ( \pi(y’) ) 中有最高的值)。
- 解释:DCG通过考虑每个文档的位置和其相关性得分来计算增益,位置越靠后的文档,其增益越小。
NDCG的定义和计算:
- 公式:[ \Delta(y’, y) = 1 - \frac{G(y’, y)}{G(y, y)} ]
例题
基本公式
首先,DCG 的计算公式如下:
[ G(y’, y) = \sum_{i=1}^r D(\pi(y’)_i) y_i ]
其中:
- ( y’ ) 表示预测的相关性得分向量。
- ( y ) 表示实际的相关性得分向量。
- ( \pi(y’)_i ) 是 ( y’_i ) 在排序向量中的位置(排名最高的实例在 ( \pi(y’) ) 中有最高的值)。
- ( D ) 是一个递减函数,通常是 ( D(\pi(y’)_i) = \frac{1}{\log_2(\pi(y’)_i + 1)} )。
示例数据
数据表格如下:
| ( y’ ) | sorted ( y’ ) | ( \pi(y’) ) | ( D(\pi(y’)) ) | ( y ) | ( D(\pi(y)) ) | ( \pi(y) ) | sorted ( y ) |
|---|---|---|---|---|---|---|---|
| 2 | -1 | 4 | 1 | 5 | 1 | 4 | -2 |
| 1 | 0.5 | 3 | 0 | -2 | 0 | 1 | 1 |
| 6 | 1 | 5 | 2 | 6 | 2 | 5 | 3 |
| -1 | 2 | 1 | 0 | 1 | 0 | 2 | 5 |
| 0.5 | 6 | 2 | 0 | 3 | 0 | 3 | 6 |
计算步骤
排序预测相关性得分 ( y’ ):
- 对 ( y’ ) 进行排序,得到 sorted ( y’ )。
- 记录每个 ( y’ ) 的排序位置 ( \pi(y’) )。
计算折扣因子 ( D(\pi(y’)) ):
- 根据 ( \pi(y’) ) 计算折扣因子 ( D(\pi(y’)) ),通常是 ( \frac{1}{\log_2(\pi(y’)_i + 1)} )。
计算实际相关性得分 ( y ):
- 对实际相关性得分 ( y ) 进行排序,得到 sorted ( y )。
- 记录每个 ( y ) 的排序位置 ( \pi(y) )。
计算 DCG 和 IDCG:
- DCG:使用公式 ( G(y’, y) = \sum_{i=1}^r D(\pi(y’)_i) y_i ) 计算预测排序的折扣累积增益。
- IDCG:使用相同公式计算理想排序的折扣累积增益。
计算示例
计算 DCG:
- 使用公式 ( G(y’, y) = \sum_{i=1}^r D(\pi(y’)_i) y_i ),
- 具体计算:
- 第一个元素:( D(\pi(y’)_1) \times y_1 = 1 \times 5 = 5 )
- 第二个元素:( D(\pi(y’)_2) \times y_2 = 0 \times -2 = 0 )
- 第三个元素:( D(\pi(y’)_3) \times y_3 = 2 \times 6 = 12 )
- 第四个元素:( D(\pi(y’)_4) \times y_4 = 0 \times 1 = 0 )
- 第五个元素:( D(\pi(y’)_5) \times y_5 = 0 \times 3 = 0 )
- 总和:DCG = 5 + 0 + 12 + 0 + 0 = 17
计算 IDCG:
- 使用公式 ( G(y, y) = \sum_{i=1}^r D(\pi(y)_i) y_i ) 计算理想排序的折扣累积增益,
- 具体计算:
- 第一个元素:( D(\pi(y)_1) \times y_1 = 1 \times 5 = 5 )
- 第二个元素:( D(\pi(y)_2) \times y_2 = 0 \times -2 = 0 )
- 第三个元素:( D(\pi(y)_3) \times y_3 = 2 \times 6 = 12 )
- 总和:IDCG = 5 + 0 + 12 = 17
计算 NDCG:
- 使用公式 ( \Delta(y’, y) = 1 - \frac{G(y’, y)}{G(y, y)} ) 计算标准化折扣累积增益。
- 具体计算:
- NDCG = 1 - ( \frac{17}{17} = 0 )
双部排序 (Bipartite Ranking)
二部排序:具体讲解
我们将深入分析二部排序的概念及其实现方法,并重点讨论相关的评分函数和评估指标。
排序评分
首先,学习一个评分函数 f : X → R f: \mathcal{X} \rightarrow \mathbb{R} f:X→R,该函数根据偏好对对象进行排序。这里的偏好指的是一个对象比另一个对象更优越或相关的程度。
在这个过程中,评分函数 f f f 的错误率与成对逆序偏好的数量成正比。这意味着如果对象 x i x_i xi 的评分 f ( x i ) f(x_i) f(xi) 应该高于对象 x j x_j xj 的评分 f ( x j ) f(x_j) f(xj),但实际情况相反,则会产生一个错误。
下图展示了这一点:
- 圆圈代表对象,黑色和白色分别表示不同的类别。
- 排序过程中,所有对象根据评分函数 f ( x ) f(x) f(x) 的值排列在一条线上。
- 排序错误指示为评分错误的地方。
经验排序风险
经验排序风险 L ^ r n k ( f ) \hat{L}_{rnk}(f) L^rnk(f) 是用于评估评分函数 f f f 的一个重要指标。定义如下:
L ^ r n k ( f ) = 1 n + n − ∑ i : y i = 1 ∑ j : y j = − 1 ( I [ f ( x i ) < f ( x j ) ] + 1 2 I [ f ( x i ) = f ( x j ) ] ) \hat{L}_{rnk}(f) = \frac{1}{n_+ n_-} \sum_{i:y_i=1} \sum_{j:y_j=-1} \left( \mathbb{I}[f(x_i) < f(x_j)] + \frac{1}{2} \mathbb{I}[f(x_i) = f(x_j)] \right) L^rnk(f)=n+n−1i:yi=1∑j:yj=−1∑(I[f(xi)<f(xj)]+21I[f(xi)=f(xj)])
其中, n + n_+ n+ 是正类样本的数量, n − n_- n− 是负类样本的数量, I [ ⋅ ] \mathbb{I}[\cdot] I[⋅] 是指示函数,用于判断条件是否成立。
这个公式的含义是:
- 对每一个正类样本 x i x_i xi 和每一个负类样本 x j x_j xj,检查评分函数 f f f 是否正确地将正类样本 x i x_i xi 的评分排在负类样本 x j x_j xj 之前。
- 如果 f ( x i ) < f ( x j ) f(x_i) < f(x_j) f(xi)<f(xj),则记一个错误。
- 如果 f ( x i ) = f ( x j ) f(x_i) = f(x_j) f(xi)=f(xj),则记半个错误。
ROC 曲线下面积 (AUC)
ROC 曲线下面积(AUC)是另一个重要的评估指标,用于评估排序模型的性能。定义如下:
A U C ( f ) = 1 − L ^ r n k ( f ) AUC(f) = 1 - \hat{L}_{rnk}(f) AUC(f)=1−L^rnk(f)
这意味着 AUC 与经验排序风险呈反比关系,AUC 值越高,排序模型的性能越好。
二部排序到成对二分类
二部排序到成对二分类的标准方法:详细讲解及例题
1. 标准方法概述
将二部排序简化为成对二分类
我们有一个数据集 ( x 1 , y 1 ) , ( x 2 , y 2 ) , … , ( x n , y n ) (\mathbf{x}_1, y_1), (\mathbf{x}_2, y_2), \ldots, (\mathbf{x}_n, y_n) (x1,y1),(x2,y2),…,(xn,yn),其中每个 ( x i , y i ) (\mathbf{x}_i, y_i) (xi,yi) 属于 X × Y \mathcal{X} \times \mathcal{Y} X×Y。我们要将这个问题转换成一个成对二分类问题。
给定:
- 数据集 ( x 1 , y 1 ) , ( x 2 , y 2 ) , … , ( x n , y n ) (\mathbf{x}_1, y_1), (\mathbf{x}_2, y_2), \ldots, (\mathbf{x}_n, y_n) (x1,y1),(x2,y2),…,(xn,yn),其中每个 ( x i , y i ) ∈ X × Y (\mathbf{x}_i, y_i) \in \mathcal{X} \times \mathcal{Y} (xi,yi)∈X×Y
- 实值预测函数类 F \mathcal{F} F, f : X → R f: \mathcal{X} \rightarrow \mathbb{R} f:X→R
定义:
- 新的数据集 { ( x ~ k , y ~ k ) } k = 1 K \{(\tilde{\mathbf{x}}_k, \tilde{y}_k)\}_{k=1}^K {(x~k,y~k)}k=1K,其中 K = n + n − K = n_+ n_- K=n+n−
- 新的函数类 F ~ \tilde{\mathcal{F}} F~, f : X × X → R f: \mathcal{X} \times \mathcal{X} \rightarrow \mathbb{R} f:X×X→R
2. 数据转换
将每对标签为 y i = + 1 y_i = +1 yi=+1 和 y j = − 1 y_j = -1 yj=−1 的实例 ( x i , x j ) (\mathbf{x}_i, \mathbf{x}_j) (xi,xj) 转换为一个学习样本 ( x ~ k , y ~ k ) (\tilde{\mathbf{x}}_k, \tilde{y}_k) (x~k,y~k),使得:
x ~ k = ( x i , x j ) , y ~ k = + 1 \tilde{\mathbf{x}}_k = (\mathbf{x}_i, \mathbf{x}_j), \tilde{y}_k = +1 x~k=(xi,xj),y~k=+1
3. 函数转换
对于任何 f ∈ F f \in \mathcal{F} f∈F,定义 f ~ ∈ F ~ \tilde{f} \in \tilde{\mathcal{F}} f~∈F~ 为:
f ~ ( x ~ k ) = f ( x i ) − f ( x j ) , 其中 x ~ k = ( x i , x j ) \tilde{f}(\tilde{\mathbf{x}}_k) = f(\mathbf{x}_i) - f(\mathbf{x}_j), \quad \text{其中} \tilde{\mathbf{x}}_k = (\mathbf{x}_i, \mathbf{x}_j) f~(x~k)=f(xi)−f(xj),其中x~k=(xi,xj)
4. 经验风险等式
很容易看到,对于任何 f f f, f f f 的经验排序风险等于 f ~ \tilde{f} f~ 的经验 0/1 风险:
ℓ 0 / 1 ( y ~ , f ~ ( x ~ ) ) = I [ y ~ f ~ ( x ~ ) < 0 ] + 1 2 I [ f ~ ( x ~ ) = 0 ] \ell_{0/1}(\tilde{y}, \tilde{f}(\tilde{\mathbf{x}})) = \mathbb{I}[\tilde{y} \tilde{f}(\tilde{\mathbf{x}}) < 0] + \frac{1}{2} \mathbb{I}[\tilde{f}(\tilde{\mathbf{x}}) = 0] ℓ0/1(y~,f~(x~))=I[y~f~(x~)<0]+21I[f~(x~)=0]
这可以表示为:
ℓ 0 / 1 ( y ~ , f ~ ( x ~ ) ) = I [ f ( x i ) < f ( x j ) ] + 1 2 I [ f ( x i ) = f ( x j ) ] \ell_{0/1}(\tilde{y}, \tilde{f}(\tilde{\mathbf{x}})) = \mathbb{I}[f(\mathbf{x}_i) < f(\mathbf{x}_j)] + \frac{1}{2} \mathbb{I}[f(\mathbf{x}_i) = f(\mathbf{x}_j)] ℓ0/1(y~,f~(x~))=I[f(xi)<f(xj)]+21I[f(xi)=f(xj)]
对所有正负样本对求和,即得到排序风险。
例题
我们通过一个具体例子来演示如何将二部排序问题转换为成对二分类问题。
数据集:
假设我们有以下数据集:
x 1 1 + 1 x 2 2 − 1 x 3 3 + 1 x 4 4 − 1 \begin{array}{ccc} \mathbf{x}_1 & 1 & +1 \\ \mathbf{x}_2 & 2 & -1 \\ \mathbf{x}_3 & 3 & +1 \\ \mathbf{x}_4 & 4 & -1 \\ \end{array} x1x2x3x41234+1−1+1−1
其中 x i \mathbf{x}_i xi 表示实例,第二列表示特征值,第三列表示标签。
步骤 1:数据转换
我们将所有正负样本对进行转换。这里我们有 2 个正样本 ( x 1 , x 3 ) (\mathbf{x}_1, \mathbf{x}_3) (x1,x3) 和 2 个负样本 ( x 2 , x 4 ) (\mathbf{x}_2, \mathbf{x}_4) (x2,x4)。因此,转换后的数据集为:
x ~ 1 ( x 1 , x 2 ) ( 1 , 2 ) + 1 x ~ 2 ( x 1 , x 4 ) ( 1 , 4 ) + 1 x ~ 3 ( x 3 , x 2 ) ( 3 , 2 ) + 1 x ~ 4 ( x 3 , x 4 ) ( 3 , 4 ) + 1 \begin{array}{cccc} \tilde{\mathbf{x}}_1 & (\mathbf{x}_1, \mathbf{x}_2) & (1, 2) & +1 \\ \tilde{\mathbf{x}}_2 & (\mathbf{x}_1, \mathbf{x}_4) & (1, 4) & +1 \\ \tilde{\mathbf{x}}_3 & (\mathbf{x}_3, \mathbf{x}_2) & (3, 2) & +1 \\ \tilde{\mathbf{x}}_4 & (\mathbf{x}_3, \mathbf{x}_4) & (3, 4) & +1 \\ \end{array} x~1x~2x~3x~4(x1,x2)(x1,x4)(x3,x2)(x3,x4)(1,2)(1,4)(3,2)(3,4)+1+1+1+1
步骤 2:函数转换
定义一个函数 f f f,假设 f ( x i ) = x i f(\mathbf{x}_i) = \mathbf{x}_i f(xi)=xi 的特征值。
对于每个 x ~ k \tilde{\mathbf{x}}_k x~k,计算 f ~ \tilde{f} f~:
f ~ ( x ~ 1 ) = f ( x 1 ) − f ( x 2 ) = 1 − 2 = − 1 \tilde{f}(\tilde{\mathbf{x}}_1) = f(\mathbf{x}_1) - f(\mathbf{x}_2) = 1 - 2 = -1 f~(x~1)=f(x1)−f(x2)=1−2=−1 f ~ ( x ~ 2 ) = f ( x 1 ) − f ( x 4 ) = 1 − 4 = − 3 \tilde{f}(\tilde{\mathbf{x}}_2) = f(\mathbf{x}_1) - f(\mathbf{x}_4) = 1 - 4 = -3 f~(x~2)=f(x1)−f(x4)=1−4=−3 f ~ ( x ~ 3 ) = f ( x 3 ) − f ( x 2 ) = 3 − 2 = 1 \tilde{f}(\tilde{\mathbf{x}}_3) = f(\mathbf{x}_3) - f(\mathbf{x}_2) = 3 - 2 = 1 f~(x~3)=f(x3)−f(x2)=3−2=1 f ~ ( x ~ 4 ) = f ( x 3 ) − f ( x 4 ) = 3 − 4 = − 1 \tilde{f}(\tilde{\mathbf{x}}_4) = f(\mathbf{x}_3) - f(\mathbf{x}_4) = 3 - 4 = -1 f~(x~4)=f(x3)−f(x4)=3−4=−1
步骤 3:经验风险
计算经验 0/1 风险:
ℓ 0 / 1 ( y ~ 1 , f ~ ( x ~ 1 ) ) = I [ − 1 < 0 ] = 0 \ell_{0/1}(\tilde{y}_1, \tilde{f}(\tilde{\mathbf{x}}_1)) = \mathbb{I}[-1 < 0] = 0 ℓ0/1(y~1,f~(x~1))=I[−1<0]=0
ℓ 0 / 1 ( y ~ 2 , f ~ ( x ~ 2 ) ) = I [ − 3 < 0 ] = 0 \ell_{0/1}(\tilde{y}_2, \tilde{f}(\tilde{\mathbf{x}}_2)) = \mathbb{I}[-3 < 0] = 0 ℓ0/1(y~2,f~(x~2))=I[−3<0]=0
ℓ 0 / 1 ( y ~ 3 , f ~ ( x ~ 3 ) ) = I [ 1 < 0 ] = 1 \ell_{0/1}(\tilde{y}_3, \tilde{f}(\tilde{\mathbf{x}}_3)) = \mathbb{I}[1 < 0] = 1 ℓ0/1(y~3,f~(x~3))=I[1<0]=1
ℓ 0 / 1 ( y ~ 4 , f ~ ( x ~ 4 ) ) = I [ − 1 < 0 ] = 0 \ell_{0/1}(\tilde{y}_4, \tilde{f}(\tilde{\mathbf{x}}_4)) = \mathbb{I}[-1 < 0] = 0 ℓ0/1(y~4,f~(x~4))=I[−1<0]=0
总经验排序风险:
L ^ r n k ( f ) = 1 4 ∑ k = 1 4 ℓ 0 / 1 ( y ~ k , f ~ ( x ~ k ) ) = 1 4 ( 0 + 0 + 1 + 0 ) = 1 4 \hat{L}_{rnk}(f) = \frac{1}{4} \sum_{k=1}^4 \ell_{0/1}(\tilde{y}_k, \tilde{f}(\tilde{\mathbf{x}}_k)) = \frac{1}{4} (0 + 0 + 1 + 0) = \frac{1}{4} L^rnk(f)=41k=1∑4ℓ0/1(y~k,f~(x~k))=41(0+0+1+0)=41
结论
通过上述步骤,我们成功将二部排序问题转换为成对二分类问题,并计算了经验排序风险。这种方法能够利用现有的二分类算法来解决排序问题,是一种有效的技巧。