目标
近期,我开始了尝试使用Stable Diffusion进行文生图和。为此,我也尝试了多种在线服务,如WHEE。虽然在线平台能够提供不错的生成效果,但是生成的图片太多的话最终还是需要收费的。
因此我想尝试在本地部署SD模型进行图像生成。目前我手上性能最强的主机只有UM790 Pro迷你主机了。可是它搭载了AMD的核显iGPU(AMD Radeon™ 780M),虽然它的性能接近GTX1650,但是部署SD模型肯定没有英伟达的GPU方便,并且还不支持ROCm。
在此记录一下我使用UM790 Pro本地部署SD模型的流程,希望能帮到大家。如有问题,还请批评指正。
准备条件
- UM790 pro迷你主机(搭载780M核显)
- 核显需要支持DirectML,否则只能使用CPU
环境准备
- 安装conda环境
conda的安装这里就不赘述了,可以直接参考百度。安装完成之后,我们需要创建python3.10的环境。网上参考资料说directml好像最高支持到3.10(不保真)。
我这里安装的版本为3.10.13,之后的操作建议都在这个conda环境中进行。conda create -n sd_directml python=3.10.13 conda activate sd_directml - 安装pyenv
由于之后使用的SD项目安装时会自动创建pyenv环境,因此如果没有安装pyenv的话还需要进行安装。windows环境下安装pyenv的教程如下,在此就不进行赘述了。
python多环境管理工具——pyenv-win安装与使用教程
安装完成后在工程目录下进入和退出pyenv环境可使用如下命令venv\Scripts\activate#进入 venv\Scripts\deactivate.bat#退出
安装stable-diffusion-webui-directml
首先将其项目克隆下来
git clone https://github.com/lshqqytiger/stable-diffusion-webui-directml.git
cd stable-diffusion-webui-directml
git submodule init
git submodule update
之后我们执行脚本进行安装
webui.bat --skip-torch-cuda-test --precision full --no-half
在安装的时候会安装onnxruntime这是我们使用iGPU进行模型推理的关键。但是安装的并不是directml版本,因此在脚本执行结束后,我们需要退出脚本并进入到工程目录下面的pyenv环境中手动安装onnxruntime-directml,具体命令如下
venv\Scripts\activate
pip uninstall onnxruntime
pip install onnxruntime-directml
#venv\Scripts\deactivate.bat
之后可以执行python命令查看当前onnxruntime支持的excutionprovider
import onnxruntime as ort
# 获取当前系统上可用的所有执行提供者
providers = ort.get_available_providers()
print("Available Execution Providers:")
for provider in providers:
print(provider)
不出意外的话会看到dmlexcutionprovider,说明我们可以使用directml调用iGPU运行SD模型了。
项目配置
重新运行命令
webui.bat --skip-torch-cuda-test --precision full --no-half
在打开的web界面中找到Settings->ONNX Runtime,并按下图进行配置
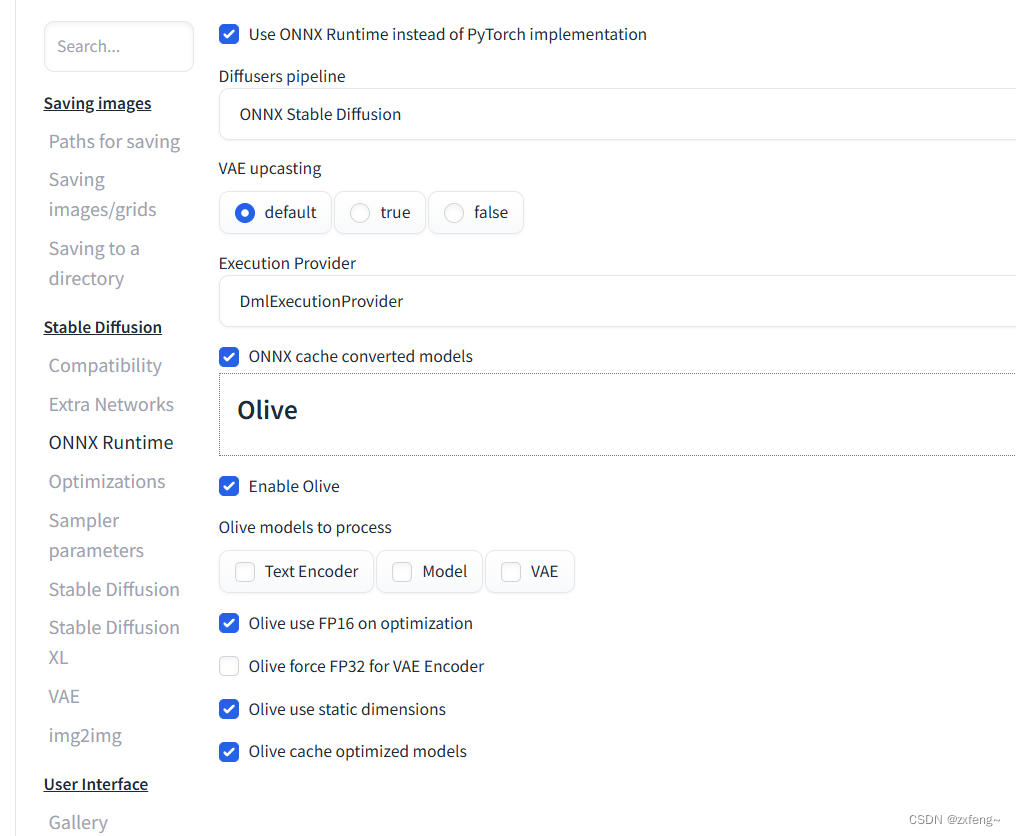
其中的”Use ONNX Runtime instead of Pytorch implementation“就是选择是否使用ONNXRuntime的,勾选后就能调用iGPU,取消勾选就是使用的CPU。
文生图测试
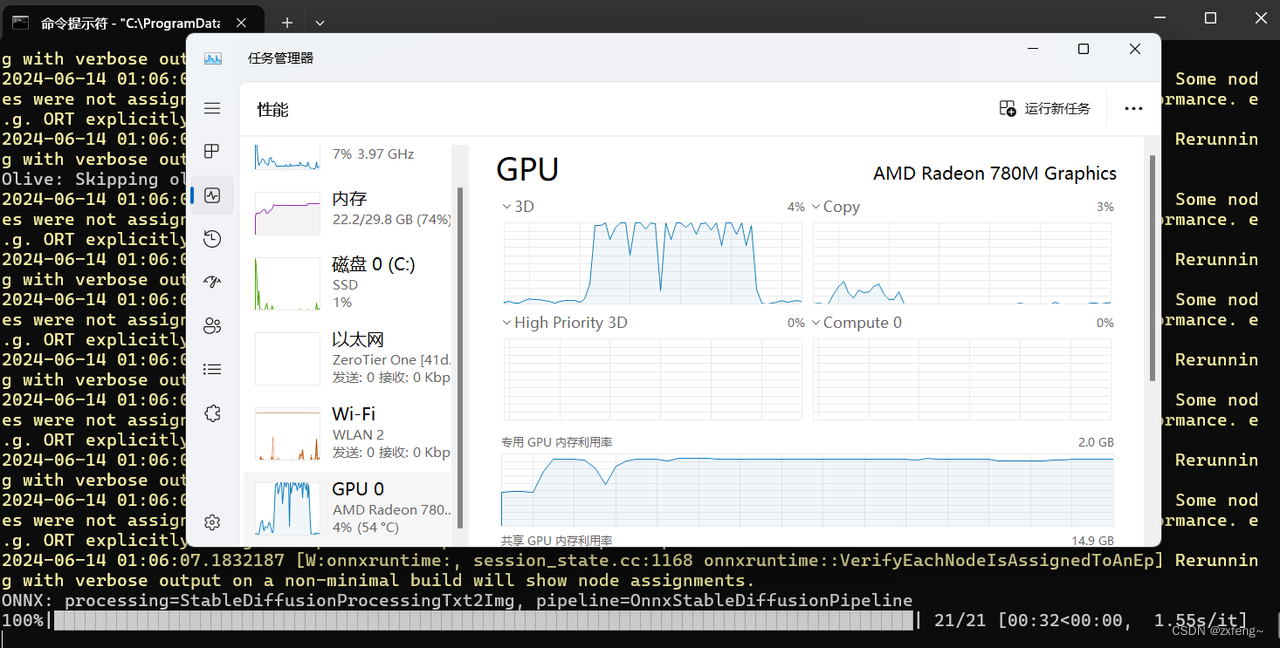
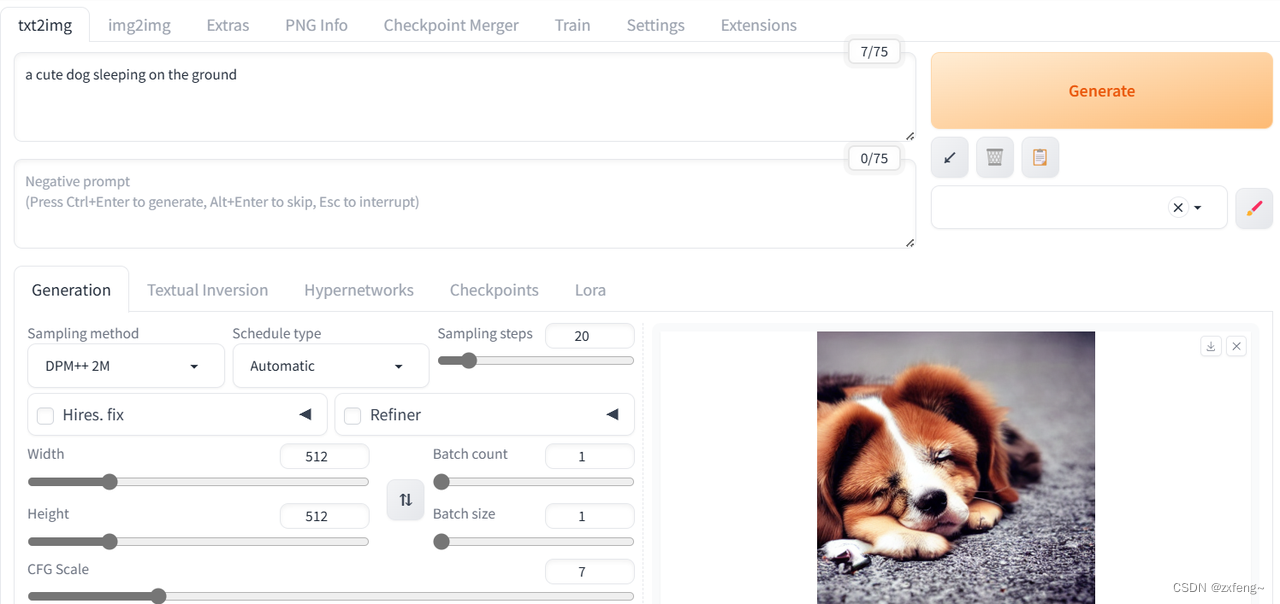
以上简单生成了一个小狗睡觉的图片,可以发现效果还可以。在实际测试中,发现采样20步使用CPU推理时需要1分半钟,使用GPU时只需要半分钟,速度有了明显的提升。
除此最基本的使用之外,还支持微调模型的使用,可以参考
【Stable Diffusion】微调模型详细教程 - embedding, hypernetwork, LoRA