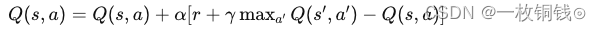Q学习算法原理与Q表的实现
Q学习算法原理与Q表的实现:强化学习的基石探索
在强化学习的广阔天地里,Q学习算法是一颗璀璨的明星,以其优雅的理论基础和实用的工程实现,为智能体赋予了学习如何在环境中采取最佳行动的能力。本文将深入剖析Q学习的原理,探讨其背后的思想,并通过Python代码实例,手把手教你如何实现Q表(Q-table),进而迈入强化学习的实践大门。
Q学习算法原理
Q学习是一种离线的强化学习算法,它无需模型,直接从环境交互中学习最优策略。其核心在于Q函数(Q(s,a)),表示在状态(s)下采取动作(a)后,预期获得的累积回报。Q学习的目标是找到这个函数的最大值,即最优策略。
Q学习的核心更新规则为贝尔曼方程的近似形式:
[Q(s_t, a_t) \leftarrow Q(s_t, a_t) + \alpha [r_{t+1} + \gamma \max_{a’}Q(s_{t+1}, a’) - Q(s_t, a_t)]]
其中,(\alpha) 是学习率,(\gamma) 是折现因子,(r_{t+1}) 是即时奖励,(s_{t+1}) 是下一状态。
Q表的实现
Q表是一种简单直接的Q函数近似方法,它将状态-动作对映射为一个表格中的值,适用于状态空间和动作空间有限的情况。
代码实现
接下来,我们将通过一个经典的“迷宫寻宝”示例,用Python实现Q学习算法,找到从起点到终点的最短路径。
import numpy as np
# 迷宫环境定义
maze = np.array([['S', ' ', ' ', ' ', ' ', ' ', ' ', ' ', ' ', 'W'],
[' ', ' ', '#', ' ', '#', ' ', '#', ' ', ' ', ' '],
[' ', '#', ' ', ' ', ' ', ' ', ' ', ' ', ' ', ' '],
[' ', '#', ' ', ' ', ' ', ' ', ' ', '#', 'E']])
shape = maze.shape
# 参数设置
actions = {'U': (-1, 0), 'D': (1, 0), 'L': (0, -1), 'R': (0, 1)}
alpha = 0.1
gamma = 0.9
epsilon = 0.1
num_episodes = 1000
# 初始化Q表
Q = np.zeros(shape + (len(actions))
# Q学习主循环
for episode in range(num_episodes):
state = np.where(maze == 'S')[::-1] # 起点
done = False
while not done:
if np.random.uniform(0, 1) < epsilon: # 探索性策略
action = np.random.choice(list(actions.keys()))
else: # 选择最优策略
action = max(actions, key=lambda x: Q[state][actions[x]]))
new_state = (np.clip(state + actions[action], 0, shape[0]-1)
reward = -1 if maze[new_state] == '#' else (10 if maze[new_state] == 'E' else 0)
Q[state][action] += alpha * (reward + gamma * np.max(Q[new_state]) - Q[state][action])
state = new_state
if maze[state] == 'E':
done = True
# 打印出Q表
print("Q表:\n", Q)
# 打印出最优路径
policy = {state: max(actions, key=lambda x: Q[state][x]) for state in np.ndindex(shape)}
path = []
state = np.where(maze == 'S')[::-1]
while state != np.where(maze == 'E')[::-1]:
path.append(state)
state = tuple(np.array(policy[state]))
path.append(np.where(maze == 'E')[::-1]))
print("最优路径:", path[::-1])
结语
通过上述代码,我们不仅理解了Q学习的基本原理,还亲手实现了Q表,见证了智能体从零开始,通过不断试错和学习,最终找到最优路径的过程。Q学习的美妙之处在于它不仅限于迷宫游戏,而是可以拓展到机器人导航、游戏AI、交易策略制定等广泛领域。希望这次实践能成为你深入探索强化学习之旅的一个精彩起点,继续挖掘更多算法的奥秘,创造无限可能。