注意,万字预警~
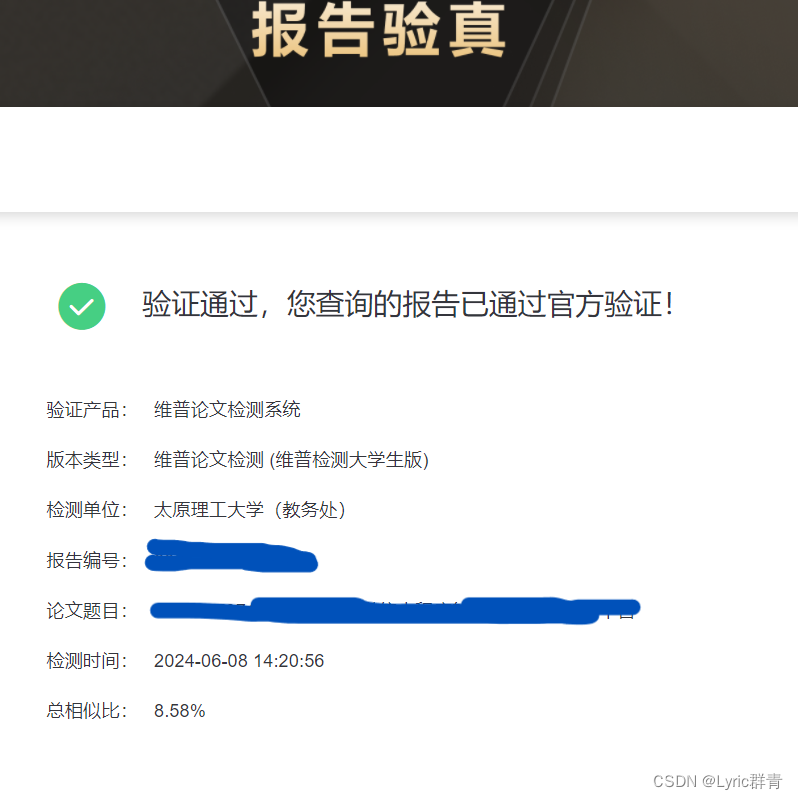
各位,6月好,又是一段很长的空窗期,一言难尽,因为博主的母校所合作的校企之一在苏州,5月31日舟车劳顿从虹桥转车(给东航“捐”了1.5k),花了一天整理材料、完成答辩,又在苏州和上海溜达了几天,3号晚上回家,又折腾了一段时间完善最终稿……一个字粗略概括一下:累。。。 (本科生2.5w+字符的论文是真逆天,唉)
毕设告一段落,接下来的几个月甚至半年,博主的更新重点主要是数据结构+算法,web全栈方面的东西会暂时放一放~本科期间博主考过唯一一次CSP,170分(第二题强行暴力霸王硬上弓,30%的用例超时www~),实在是有点菜,不过没参加过校队和培训,自学基本上很难冲破260吧,必须堆很多时间成本,9、12月的CSP,不知道能不能冲击一下350+……
这个系列主要是总结一下算法笔记上面的知识,大家可以参考~(优先更新原书的,上机指南先放一放~)

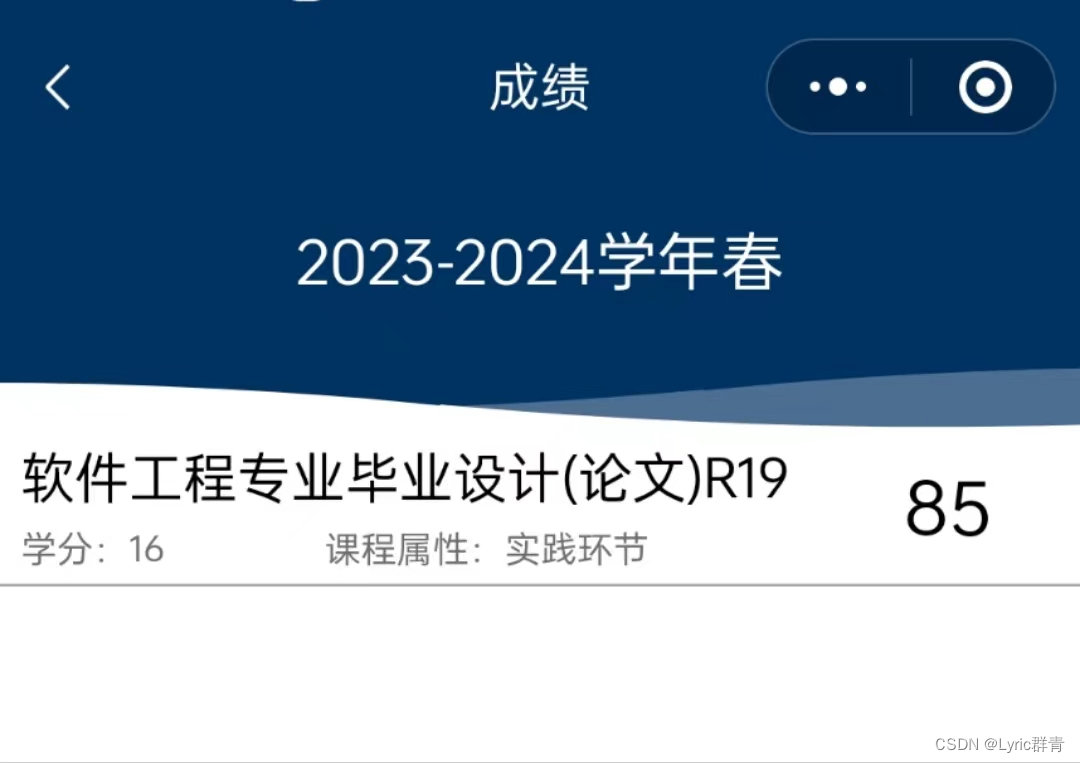
今天第一期,再复习总结一下C++ 。涵盖的内容都掌握,在末流211期末考试考85+应该是没什么问题(doge~)
一.数据类型
1.数值变量类型的取值范围
这个需要注意一下,有些【大数】类的题目,使用int型不足以解决问题,需要选择最适合的类型:
- int:最大值为2^31-1,大致范围是2*10的9次方~
- long long:2^63-1,大致是9乘10的18次方~(如果long long型赋予大于2^31-1的初值,需要在后面加上LL)
- 如果加上unsigned,即无符号类型,可以分别扩大到32次和64次
- float:2^128次,实际精度为6-7位——3.1415
- double:2^1024次,实际精度为15-16位——3.1415926536
- double和float可以进行相加等运算,一般情况下浮点型无理由选double
- C语言中字符常量统一使用ASCII编码,取值范围是0~127
- 需要牢记:0-9对应值为48-57,小写字母从a开始是97-122,大写字母从A开始是65-90
- \n为换行,\0为null空字符,\t为tab键
- 字符串常量可以通过字符数组的方式表出
- 不能把字符串常量赋值给字符变量!
- 在C++中,布尔型可以直接使用,C中需要引入头文件stdbool.h
- 非0值一律为true,0为false值;对于计算机来说,一律按1和0存储
如果将浮点型强制转换为整型,会向下取整,如下:
double a=12.34; double b=12.89; printf("%.2f %.2f\n",a,b); printf("%d %d",(int)a,(int)b); return 0;

赋值时会自动完成类型转换:
int a1; double c1,c2; a1=a; c1=a1/2; printf("%.2f",c1); return 0;

#define可以定义常量,即宏定义;但是通常使用const关键字修饰常量。
关于自增运算符,老生常谈了,有人大一开始就不能完全理顺:
- i++,先使用i,再将i+1
- ++i,先i+1,再使用
int main(int argc, char *argv[]) { int i=0,j=0; for(;i<=5;i++) printf("%d ",i); printf("\n"); for(;j<=5;++j) printf("%d",j); }但是在for循环中 ,如上,先执行的是条件判断,才会执行第三个赋值语句,异常无论是++i还是i++,结果均相同:
对于菜一点的(比如博主)经常使用暴力,遍历的范围一定要理清楚,通常使用i++。

- 对于关系运算符和逻辑运算符,返回值结果均为布尔型,真时为true,假时为false。
- 位运算符需要牢记一下,计租和2进制相关的题目经常会用到~
以-5为例:
原码:10000000 00000000 00000000 00000101 (最高位为1)
反码:11111111 11111111 11111111 11111010 (按位取反,符号位不变)
补码:11111111 11111111 11111111 11111011 (反码加1)左移运算符:
int a = -5; int b = a << 1; printf("%d\n", a); printf("%d\n", b); return 0;
简单说就是:左边丢弃,右边补0!
需要注意的是:位运算符操作的是补码,以此写出:
补码:11111111 11111111 11111111 11110110
反码:11111111 11111111 11111111 11110101(补码 -1 得到反码)
原码:10000000 00000000 00000000 00001010(按位取反得到原码)求得结果为10~
右移运算符:
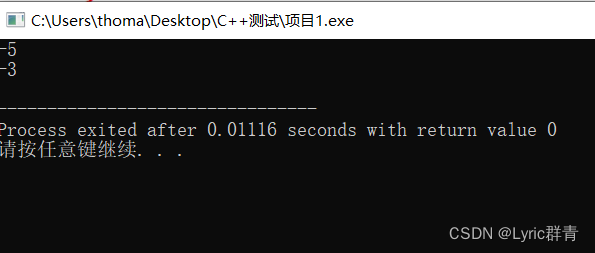
#include<stdio.h> int main() { int a = -5; int b = a >> 1; printf("%d\n", a); printf("%d\n", b); return 0; }
右移运算是将一个二进制位的操作数按指定移动的位数向右移动,移出位被丢弃,左边移出的空位一律补0,或者补符号位,这由不同的机器而定。在使用补码作为机器数的机器中,正数的符号位为 0 ,负数的符号位为 1 。
同理反推:
补码:11111111 11111111 11111111 11111101
反码:11111111 11111111 11111111 11111100(补码 -1 得到反码)
原码:10000000 00000000 00000000 00000011(按位取反得到原码)得出结果为:-3

注:不要移动负数位!
- 按位与:除了11得1其他均为0
- 按位或:除了00得1其他均为1
- 按位异或:相同为0,不同为1
- 按位取反:0变1,1变0
二.3大结构
顺序,判断,循环,此处不多赘述,说一些很容易犯错的地方~
- 对于scanf来说:long long形态和double形态的格式控制符分别为:%lld,%lf
- 除%c外,scanf其他格式符以空格、tab等空白符号为结束标志
- %c可以接收空格
- %s以换行或者空格作为结束标志
3种实用的输出格式:
- %md:不足m位的int型数值输出时在前面自动用空格填充到m位
- %0md:和前者一样,空位用0补齐
- %.mf:保留m位小数输出(四舍六入五成双!)
int a=123; int b=1234567; float c=1.31917; printf("%7d\n",a); printf("%07d\n",a); printf("%d\n",b); printf("%.2f\n",c);

- getchar和putchar用来接收单一字符,但是切记一定要保存下来,负责不能用putchar输出。如下:输入的是1234,但是2未被保存,因此不会被输出~
char c1,c2,c3; c1=getchar(); getchar(); c2=getchar(); c3=getchar(); putchar(c1); putchar(c2); putchar(c3);

常用的math函数:
- fabs:对double型取绝对值
- floor:对double向上取整
- ceil:对double向下取整
- pow(a,b):返回a的b次方,a和b都是double类型
- sqrt:返回double变量的算术平方根
- log:返回以自然对数为底的double型变量的对数(想用其他底数必须用换底公式)
- sin、cos、tan即为三角函数,参数必须是弧度制
- asin,acos,atan返回double型变量的反三角函数值
- round:将double型变量四舍五入~
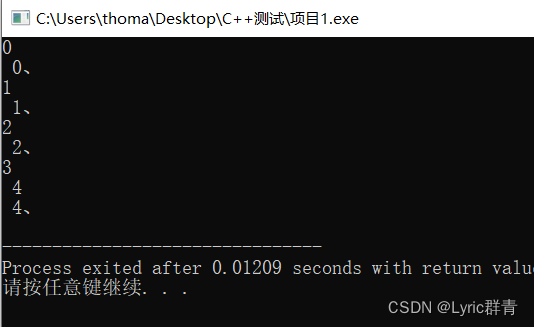
break和continue语句:
break是直接跳出循环,continue结束本次循环后面的操作~
break:触发后直接和循环体说拜拜
int i=0; for(;i<5;i++) { printf("%d\n ",i); if(i==3) break; printf("%d、\n",i); }
continue:之时不执行3后面的操作,直接进入4
for(;i<5;i++) { printf("%d\n ",i); if(i==3) continue; printf("%d、\n",i); }

三.数组
数组就是把相同数据类型的变量组合在一起而产生的数据集合,数组大小必须是整数常量,不可以是变量!
数组中没有赋予初值的部分,不一定默认为0,此处给出两种赋予初值的方式:
int a[10]={0}; int a[10]={};
递推其实没有想象中的那么高大上复杂:即根据某一下条件,可以不断让后一位的结果由前一位或前面若干位计算而来。如下,每一位都是前面的2倍,也是一个递推的例子:
int i,j; int arr[10]; arr[0]=1; for(i=0;i<10;i++) arr[i+1]=2*arr[i]; for(j=0;j<10;j++) printf("%d ",arr[j]); return 0;
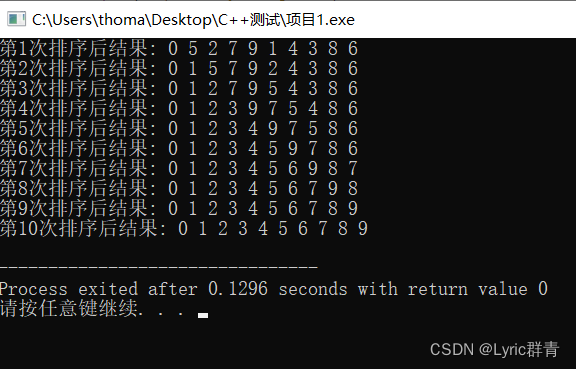
冒泡排序:最基础的排序,本质是交换,此处再复习一下:(C++版),以升序排列为例:
原数组:
int arr[10]={6,5,2,7,9,1,4,3,8,0};int a=0; //中间变量 for(int i=0;i<=9;i++) { for(int j=i+1;j<=9;j++) if(arr[i]>arr[j]) { a=arr[j]; arr[j]=arr[i]; arr[i]=a; } cout<<"第"<<(i+1)<<"次排序后结果: "; for(int k=0;k<=9;k++) cout<<arr[k]<<" "; cout<<endl; }其实不难发现,经过i回合后,前i个数已经是有序的啦,因为无论具体细节是什么,第1回合都会将最小的数冒泡到前面,以此类推~
二维数组就是对一维数组的扩展,可以理解为某种矩阵:
int arr[3][9]={0}; for(int i=0;i<=2;i++) { for(int j=0;j<=8;j++) cout<<arr[i][j]<<" "; cout<<endl; }奇怪的赋值方式,知道一下就行:
int arr[6][6]={{1,1,1},{2,2},{},{3,3,3,3,3}}; for(int i=0;i<=5;i++) { for(int j=0;j<=5;j++) cout<<arr[i][j]<<" "; cout<<endl; }

需要注意的是,如果数组大小较大(10w左右),则需要将其定义在主函数外部,否则会使程序异常退出,原因是函数内部申请的局部变量来自系统栈,太远不需要申请的空间较小,而函数外部申请的全局变量来自静态存储区,允许申请的空间较大~
memset函数:为数组赋予相同的值,包含在string.h文件中,建议用来赋值0、-1,如果是其他值建议使用fill函数!
int a[5]; memset(a,0,sizeof(a)); //3个参数:数组名,赋予的初值,sizeof(数组名~) for(int i=0;i<=4;i++) cout<<a[i]<<endl;
字符数组:很重要的存在,如果不适用string对象或者vector容器,很多题目中需要使用字符数组来处理实际情况~
需要注意的是,赋予初值是可以直接通过字符串赋予,但是,程序中任何其他地方,都不能这样做!
char string[20]="Hello world!"; for(int i=0;i<=19;i++) cout<<string[i]<<" ";
对比字符型数组的输出方式:
- scanf和printf:
通过scanf有两种方式键入字符数组,一种是%c,一种是%s,前者相当于一个一个字符接收,因此可以接收空格和换行;而%s是接收字符串,以空格或者换行结束~(此外,%s不需要加取值符即可输入完毕~)
char str1[20]; scanf("%s",str1); printf("%s",str1);一般来说,不适用所谓的%c输入,恕博主直言这样太怪了。。
- getchar和putchar:不再赘述,需要注意getchar能接收空格和换行!
char str1[5][5]; for(int i=0;i<=4;i++) { for(int j=0;j<=4;j++) { str1[i][j]=getchar(); } getchar(); //消除换行符的影响 } for(int i=0;i<=4;i++) { for(int j=0;j<=4;j++) { cout<<str1[i][j]<<" "; } cout<<endl; }如下图:空格在键入的时候没做处理,因此会当成元素输入;空格被处理后不影响~
- gets和puts:以空格和换行收尾,如果要不计空格输入,记得同样用getchar接收
后面两种博主不喜欢用,一般情况下如果使用C++的话肯定是cin+string、vector为妙,不能使用C++,就乖乖用char数组+%s的scanf吧~

string.h头文件
- strlen:可以得到字符数组中第一个\0前面的字符的个数
- strcmp:返回两个字符串按大小的比较结果,比较原则是字典序,如果前面的数组小返回负整数、反之则是正整数,如果相同则返回0(所谓字典序即第一个不相同的字符按照字典顺序比较,这里说的大小可不是字符串的长度!)
- strcpy:将第二个参数的字符串值赋予第一个
- strcat:将第二个字符串拼接在第一个后面
sscanf和sprintf:
原始的scanf和printf其实可以理解为:
scanf(screen,"%d",&n); scanf(screen,"%d",n);即在screen——屏幕上面的io操作!
不妨将screen改为某种字符串,这里以str为例:其实相当于对str专属的IO方式:
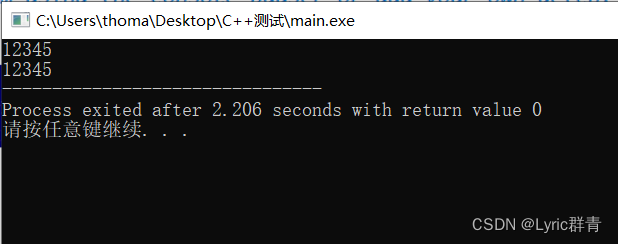
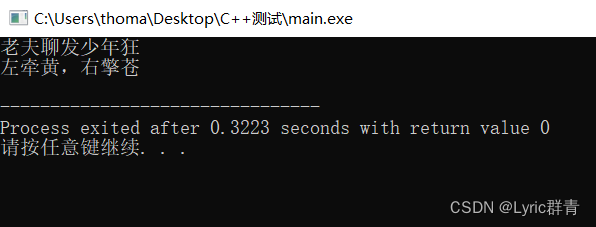
char str1[20]="老夫聊发少年狂",str2[20],str3[20]="左牵黄,右擎苍"; sscanf(str1,"%s",str2); cout<<str2<<endl; sprintf(str2,"%s",str3); cout<<str2<<endl;
看着是不是有点晕,其实很简单,这里相当于分别用str1、str2代替了与我们交互的电脑屏:
- 第一个里面str1是“电脑屏”,即将键入的数据保存到我们的变量中(str2)
- 第二个里面str2是“电脑屏”,即将输出的数据保存到我们的变量中(str2)
不需要深度钻研的操作,你可以理解为节省空间,将中间变量当电脑的io设备用~
字符数组的存储方式:
最后一位会添加“\0”作为结束标志,gets和scanf会默认添加作为结束标志,而puts和printf将其作为结束标识~
列举几种经典错误吧:
char str1[5]="12345"; char str2[5]="1234\0" char str3[5]="123\0"; char str4[5]="1234"; printf("%s\n",str3); printf("%s",str4);
- str1:报错,必须给结尾符预留空间,越界
- str2:报错,同样越界,因为\0占此处占两个字符!
- str3:正常,但是输出时将\0全部忽略,只有3位
- str4:正常,如果不主动键入\0,只需要留一位即可!
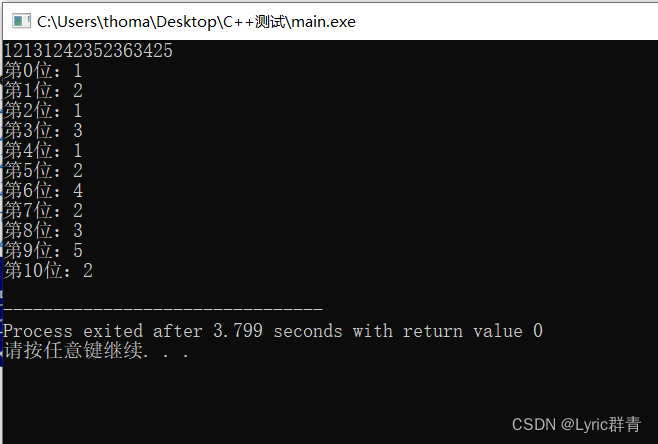
另外补充一个神奇的地方:%s的scanf即使越界,也可以自动扩充,不报错~
char str5[5]; scanf("%s",&str5); for(int i=0;i<=10;i++) cout<<"第"<<i<<"位:"<<str5[i]<<endl;


四.函数
- 全局变量: 在定义之后的所有程序段内都有效的变量(即定义在所有函数之前)
- 局部变量:定义在函数内部,只在函数内部生效,函数结束时局部变量销毁
值传递:
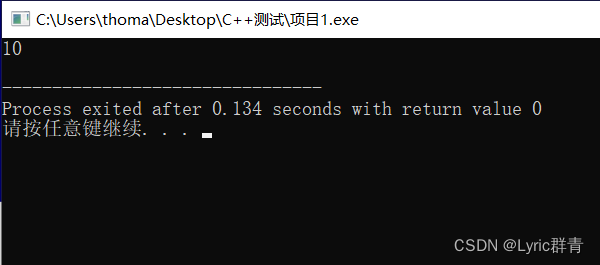
先看一段代码,如下:test函数的形参和实参相同,均为x:
void test(int x) { x=x+1; } int main(int argc, char** argv) { int x=10; test(x); cout<<x<<endl; return 0; }然而使用test函数后,x的值依旧为10。
这是因为,在test函数里面的参数x为局部变量,仅在函数内部生效,通过test(x)传进去的其实只是一个副本,也即change函数的参数x和main函数里面的x其实是作用与两个不同函数的不同变量——即便他们名字相同~
main函数:
主函数对一个程序来说只能有一个,并且无论主函数卸载哪个位置,整个程序一定是从主函数的第一个语句开始执行,然后在需要调用其他函数时才去调用。
用函数的眼光来看:main是函数名称,返回类型是int型,并在函数主体最后面返回了0,对于计算机来说,main函数返回0的意义在于告知系统程序正常终止。
数组作为函数参数:
- 数组的第一维不需要填写长度,从第二维开始再填写即可
- 数组作为参数时,在函数中对数组元素的修改等同于对原数组的修改!
- 数组不能作为返回类型出现~
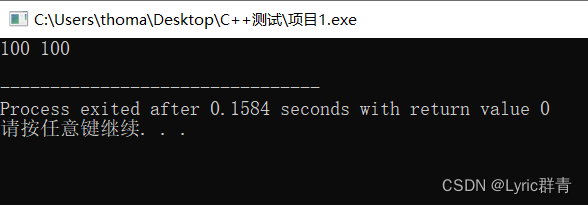
void test(int a[],int b[][5]) { a[1]=100; b[0][0]=100; } int main(int argc, char** argv) { int a[5]={0}; int b[5][5]={0}; test(a,b); cout<<a[1]<<" "<<b[0][0]<<endl; }
函数的递归调用:一个函数调用该函数自身~
(这里暂不展开)
五.指针
指针定义:
一个房间号指向一个房间,对应到计算机里面就是一个地址指向一个变量,可以通过地址来找到变量。
在C语言中中指针表示内存地址,或者称指针指向了内存地址。简单且不严谨的说法是,指针就是变量的地址~
- &可以获取变量的地址
- 指针实际上就是一个unsigned的整数~
指针变量用来存储指针——也可以理解为地址。就好比整型的1/2/3,可以把地址理解为一种常量,然后专门定义一种指针变量来存放他。
*放在数据类型之后或者变量名之前都是可以的!
- C语言程序员:int *p;
- C++程序员:int* p;
两种不同的约定俗成罢了~
语法上容易混淆的点:
- int *p1,p2;——只有p1是整型指针,而p2却是整型
- int* p1,*p2,*p3;——3者均为整型指针
- int *p1,*p2,*p3;——上述的一种美观写法
指针赋值:
int a=5; int* p1=&a;亦或是:
int a=5; int* p1; p1=&a;小白需要特别注意的是:&a的值是赋予p的,而不是所谓的*p!int* 才是变量的类型,要牢记*是类型的一部分~
通过地址获取元素:
如果说&可以获取房间的地址,星号*其实就是一把开启房间的钥匙
int a=5; int* p1; p1=&a; cout<<*p1<<endl;
- &a,p可以理解为某种地址
- a,*p即为本身的值
- 因此,int* p=&a,理解为*p=&a是不正确的——地址怎么可能和值赋值呢?
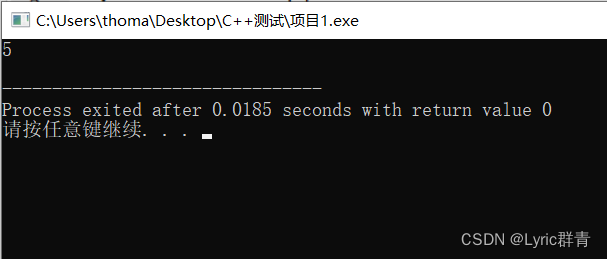
- 某个变量所在地址的房间内的东西被改变了,但这并不影响它的地址
- p存放地址,那么亦可使用*p完成赋值,如下:
int a=0; int* p=&a; *p=123; cout<<a<<" "<<*p<<endl;
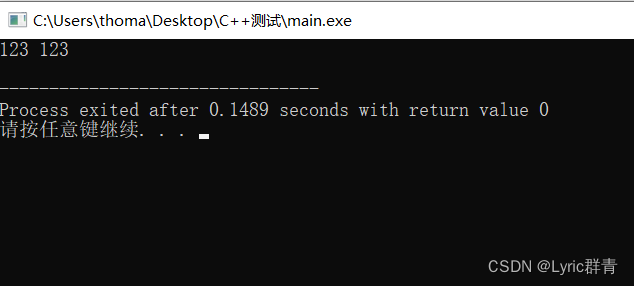
- 指针变量也可以进行加减法,对于int*型来说,p+1是指p所指的int型变量的下一个int型变量地址~
- 对于指针变量来说,把其存储的地址的类型称为基类型——即基类型必须和地址类型相同~
指针与数组:
- 首先要记清楚,C语言中,&a[0]和a都可以作为数组首地址使用~如下,二者完全相同:
int a[5]={1,2,3,4,5}; printf("%d\n",a); int* p=&a[0]; printf("%d",p);
- 划重点,因为a=&a[0],又因为指针可以进行加减,因此a+i=&a[i]!因此地址&a[i]完全可以用a+i作为其平替,因此有如下代码:
int a[10]; int i=0,j=0; for(;i<=9;i++) scanf("%d",a+i); for(;j<=9;j++) cout<<*(a+j)<<" "; //注意a+j相当于&a[j],还要加*取值!数据均正常读入:
指针变量可以完成自增操作,因此可以这样枚举数组的元素:
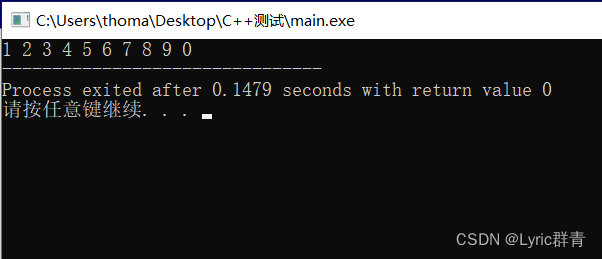
int a[10]={1,2,3,4,5,6,7,8,9,0}; for(int* p=a;p<=a+9;p++) // p即数组a的地址,自增即位移 cout<<*p<<" ";
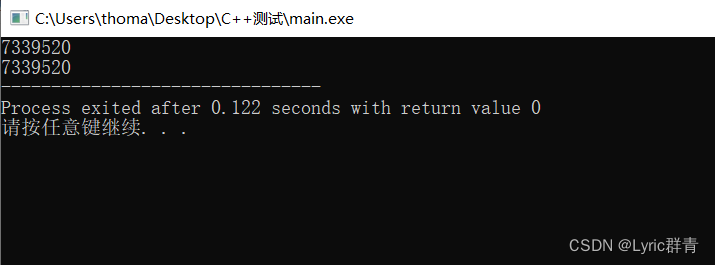
还有一个小细节要注意:
int a[3]={1,2,3}; int* p=a; //等价于&a[0] int* q=&a[2]; cout<<p<<" "<<q<<endl; cout<<(q-p)<<endl;p比q的16进制低了8点,但是q-p是2:
要明白,指针的加减是位移,因此两个指针真正的距离是8/4=2(对于int型来说~)
换句话说,p和q差了两个int!


指针变量作为函数参数:
视为将变量的地址传入函数,如果在函数中对这个地址中的元素进行修改,那么原先的数据就却是会被改变——而不是之前说的副本那种情况!
举一个很直观的例子,先看值传递:
int test(int x) { x*=2; return x; } int main(int argc, char** argv) { int x=10; cout<<test(x)<<endl; cout<<x<<endl; }即便x作为实参传入了test函数,返回值也是x的一个副本罢了——真正的x值不变:
如下,将x的地址p传入到函数中:
int test(int* x) { (*x)*=2; return *x; } int main(int argc, char** argv) { int x=10; int* p=&x; cout<<test(p)<<endl; cout<<x<<endl; }x本身的值也发生了变化!
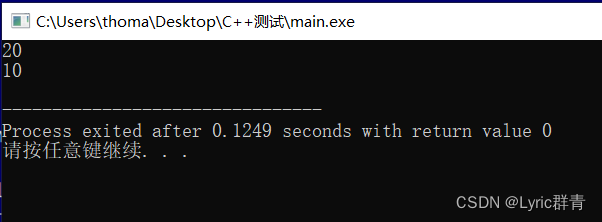
再来看一个经典的例子,交换两个值的函数:
int test(int a,int b) { int temp=0; temp=a; a=b; b=temp; return a,b; } int main(int argc, char** argv) { int x=10,y=100; test(x,y); cout<<x<<" "<<y<<endl; }无法交换,同理还是因为传入的副本,不改变变量本身的值:
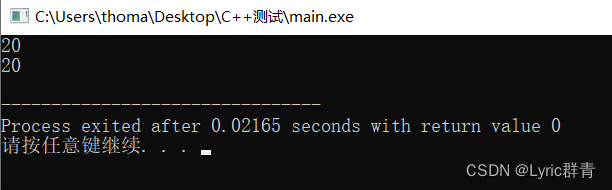
再来看 地址传递:
int test(int* a,int* b) { int temp; temp=*a; *a=*b; *b=temp; } int main(int argc, char** argv) { int x=10,y=100; int* p=&x; int* q=&y; test(p,q); cout<<x<<" "<<y<<endl; }
众所周知,指针变量存放的是地址,那么使用指针变量作为参数传进来的也是地址。只有在获取地址的情况下对元素操作,才能真正的修改变量。

引用:
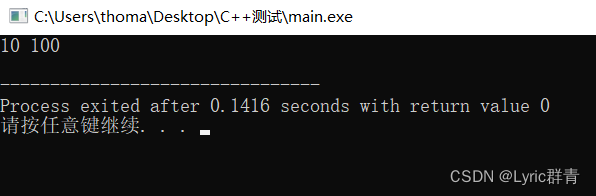
引用相当于给原来的变量起了一个别名,这样旧名字和新名字其实都是指同一个东西,且对引用变量的操作就是原变量的操作~
int test(int &x) { x+=100; } int main(int argc, char** argv) { int x=0; test(x); cout<<x<<endl; }
- &一般卸载变量名前面——一种规范
- &并不是取地址的意思!
- 不管是否使用引用,函数的参数名和实际传入的参数名可以不同
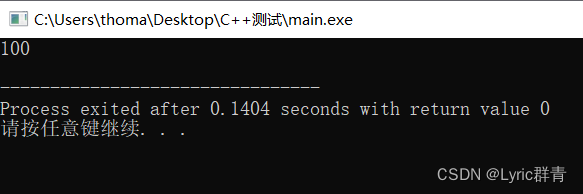
指针的引用:
int test(int* &p1,int* &p2) { int* temp=p1; p1=p2; p2=temp; } int main(int argc, char** argv) { int a=10,b=20; int* p=&a,*q=&b; test(p,q); cout<<*p<<" "<<*q<<endl; }

六.结构体
结构体可以将很多不同数据类型的变量或者数组封装在一起,以存储自定义的数据结构,方便存储一些符合数据~
需要特别注意的是:虽然结构体不能定义自己本身,但是可以定义自身类型的指针变量!
这一点在考验数据结构的伪代码中很常见!
struct node{ node n; node* next; };
struct my{
int id;
char name[20];
my* next;
}me,*p;对于普通的变量me:
me.name;对于指针变量*p:
(*p).name;针对指针变量的简单写法:
p-next;七.黑盒测试
1.单点测试
对于单点测试来说,系统会判断每组数据的输出结果是否正确,如果输出正确,那么对该组数据来说就通过了测试,并得到了这组数据的分值。
2.多点测试
与前者相对应,多点测试要求程序能一次性允许所有的数据,并要求所有输出结果都必须完成正确,才能算这题通过;而且只要有其中一组数据的输出错误,该题即为0分。
- while...EOF型:如果题目没有给定输入结束的条件,那么就会默认读取到文件末尾,对黑盒测试来说,所有输入的数据都是放在一个文件里面的,系统会让程序去读取这个文件里的输入数据,然后执行程序并输出结果
- while...break型
- while(T--)型
八.其他要点
cin与cout:
- cin的输入不指定格式,也不需要加取址运算符,直接写变量名即可~
- getline用于接收一整行
char str[100]; cin.getline(str,100); cout<<str<<endl;
事实上,cin和cout在处理大量数据的情况下表现非常糟糕,有时候题目的数据还没有完全输入完毕就已经超时,建议不要图省事,还是老老实实用scanf和printf吧~
复杂度:
- 时间复杂度,数据结构已经将理论讲的很清楚了,这里不单独叙述~
- 空间复杂度:只要不开好几个百万以上的数组就肯定够用
- 编码复杂度:编码不能过度冗余
细节:
- 上述代码段有些地方不太符合规范,最好不要在同一程序同时使用cout和printf。
- 在C++中,头文件的.h可以省略,换成头部加c
#include<string.h>——#include<cstring>