【pytorch】pytorch模型加载函数torch.load()
🌈 欢迎莅临我的个人主页👈这里是我深耕Python编程、机器学习和自然语言处理(NLP)领域,并乐于分享知识与经验的小天地!🎇
🎓 博主简介:
我是云天徽上,一名对技术充满热情的探索者。多年的Python编程和机器学习实践,使我深入理解了这些技术的核心原理,并能够在实际项目中灵活应用。尤其是在NLP领域,我积累了丰富的经验,能够处理各种复杂的自然语言任务。
🔧 技术专长:
我熟练掌握Python编程语言,并深入研究了机器学习和NLP的相关算法和模型。无论是文本分类、情感分析,还是实体识别、机器翻译,我都能够熟练运用相关技术,解决实际问题。此外,我还对深度学习框架如TensorFlow和PyTorch有一定的了解和应用经验。
📝 博客风采:
在博客中,我分享了自己在Python编程、机器学习和NLP领域的实践经验和心得体会。我坚信知识的力量,希望通过我的分享,能够帮助更多的人掌握这些技术,并在实际项目中发挥作用。机器学习博客专栏几乎都上过热榜第一:https://blog.csdn.net/qq_38614074/article/details/137827304,欢迎大家订阅
💡 服务项目:
除了博客分享,我还提供NLP相关的技术咨询、项目开发和个性化解决方案等服务。如果您在机器学习、NLP项目中遇到难题,或者对某个算法和模型有疑问,欢迎随时联系我,我会尽我所能为您提供帮助,个人微信(xf982831907),添加说明来意。

PyTorch是一个强大的深度学习框架,它提供了丰富的API来构建和训练神经网络。在训练完模型后,我们通常需要保存模型的权重以便将来使用或进一步微调。PyTorch中的torch.save()函数用于保存模型,而torch.load()函数用于加载模型。本文将介绍如何使用torch.load()来加载PyTorch模型,包括一些常见的问题及其解决办法。
为什么需要加载模型?
迁移学习:在迁移学习中,我们通常使用预训练的模型作为起点。

模型微调:在模型微调时,需要加载预训练的权重。
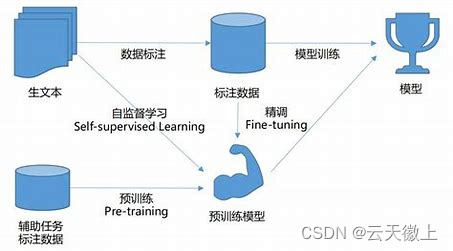
模型部署:在生产环境中,需要加载训练好的模型进行预测。
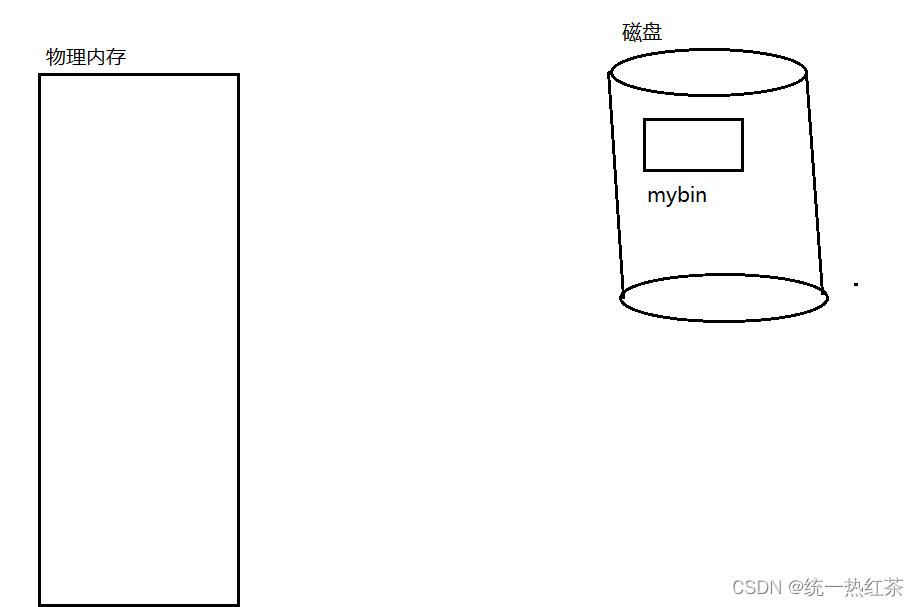
1.作用:用来加载torch.save() 保存的模型文件。
torch.load()先在CPU上加载,不会依赖于保存模型的设备。如果加载失败,可能是因为没有包含某些设备,比如你在gpu上训练保存的模型,而在cpu上加载,可能会报错,此时,需要使用map_location来将存储动态重新映射到可选设备上,比如map_location=torch.device(‘cpu’),意思是映射到cpu上,在cpu上加载模型,无论你这个模型从哪里训练保存的。
一句话:map_location适用于修改模型能在gpu上运行还是cpu上运行。如果map_location是可调用的,那么对于每个带有两个参数的序列化存储,它将被调用一次:storage和location。存储参数将是存储的初始反序列化,驻留在CPU上。每个序列化存储都有一个与之关联的位置标记,它标识保存它的设备,这个标记是传递给map_location的第二个参数。内置的位置标签是“cpu”为cpu张量和“cuda:device_id”(例如:device_id)。“cuda:2”)表示cuda张力。map_location应该返回None或一个存储。如果map_location返回一个存储,它将被用作最终的反序列化对象,已经移动到正确的设备。否则,torch.load()将退回到默认行为,就好像没有指定map_location一样。
如果map_location是一个torch.device对象或一个包含设备标签的字符串,它表示所有张量应该被加载的位置。
如何使用torch.load()
使用方式
torch.load(f, map_location=None, pickle_module=<module 'pickle' from '/opt/conda/lib/python3.6/pickle.py'>, **pickle_load_args)
输入参数:
f :一个类文件的对象(必须实现read(),:meth ’ readline ',:meth ’ tell '和:meth ’ seek '),或者一个字符串或os。包含文件名的类路径对象
map_location : -指定如何重新映射存储位置的函数、torch.device、字符串或dict
pickle_module :—用于解pickle元数据和对象的模块(必须匹配用于序列化文件的pickle_module)【没用过】
pickle_load_args : -(仅适用于Python 3)传递给pickle_module.load()和pickle_module. unpickpickler()的可选关键字参数,例如errors=…【没用过】
输出:
基本用法
import torch
# 假设model是我们训练好的模型
model = ...
model_path = 'path/to/model.pth'
# 保存模型
torch.save(model.state_dict(), model_path)
# 加载模型
model.load_state_dict(torch.load(model_path))
加载模型时的常见问题
- 设备不匹配:加载的模型权重可能与当前设备不匹配。
- 版本不兼容:PyTorch版本不一致可能导致模型加载失败。
- 模型定义不匹配:加载的权重与当前模型定义不匹配。
解决办法
方法一:确保设备一致性
使用torch.load()时,可以指定设备。
# 指定设备为GPU
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model.load_state_dict(torch.load(model_path, map_location=device))
方法二:检查PyTorch版本
确保运行环境中的PyTorch版本与保存模型时使用的版本一致。
# 检查PyTorch版本
python -c "import torch; print(torch.__version__)"
方法三:处理模型定义不匹配
确保加载权重的模型定义与保存时的模型定义完全一致。
方法四:使用try-except捕获异常
使用try-except块来捕获加载过程中可能出现的异常。
try:
model.load_state_dict(torch.load(model_path))
except KeyError as e:
print(f"KeyError: {e}")
# 可能需要调整模型定义或检查权重文件
方法五:使用预训练模型
对于某些任务,可以直接加载PyTorch提供的预训练模型。
import torchvision.models as models
# 加载预训练的ResNet模型
resnet = models.resnet50(pretrained=True)
方法六:保存和加载整个模型
除了保存和加载模型权重外,也可以保存整个模型。
# 保存整个模型
torch.save(model, model_path)
# 加载整个模型
model = torch.load(model_path)
方法七:使用torch.jit保存和加载模型
对于需要序列化或在不同平台间传输的模型,可以使用torch.jit.
import torch.jit
# 将模型转换为脚本
scripted_model = torch.jit.script(model)
# 保存脚本模型
torch.jit.save(scripted_model, model_path)
# 加载脚本模型
loaded_model = torch.jit.load(model_path)
结论
torch.load()是PyTorch中加载模型的关键函数。正确使用这个函数,可以有效地加载训练好的模型权重或整个模型。在加载模型时,需要注意设备一致性、PyTorch版本兼容性、模型定义匹配等问题。希望本文能帮助你在PyTorch项目中成功加载模型。