关于LLM何时使用RAG的问题,原本是阅读了关于ADAPT-LLM模型的那篇论文,被问到与SELF-RAG有何区别。所以,大概看了一下SELF-RAG这篇论文,确实很像,这些基于LLM针对下游任务的模型架构和方法,本来就很像。不过,对比起来,SELF-RAG还是更像前面介绍的SteerLM。进一步觉得SELF-RAG这种方法具有通用性,所以又详细阅读了一下,并重新总结了SELF-RAG的完整方法。
论文链接:https://ar5iv.labs.arxiv.org/html/2310.11511

摘要
尽管大型语言模型(LLMs)具有显著的能力,但它们仍然会产生包含事实错误的响应,这些错误仅依赖于它们所包含的参数知识。检索增强生成(RAG)是一种通过检索相关知识来增强LLMs输入的方法,这在知识密集型任务中减少了知识错误。然而,RAG方法会不加选择地检索和整合检索到的段落,无论检索是否必要或段落是否相关,这可能会减少LLMs的多功能性或导致生成质量低下。为了解决这些问题,文章介绍了一种新的框架——自反思检索增强生成(Self-Rag:Self-Reflective Retrieval-Augmented Generation),通过按需检索和自我反思提高了LLMs生成的质量,包括事实准确性,同时不损害其多功能性。
方法简述
Self-Rag框架训练流程涉及两个模型,一个是评价模型(Critic Model),一个是生成模型(Generator Model)。大概方法是,借助GPT-4形成数据集,训练评价模型;然后通过评价模型,生成新的数据集,再来训练生成模型。如何,是不是与SteerLM的流程非常相似。
整个训练步骤:
- 初始化评价模型(Critic Model):评价模型使用预训练的语言模型进行初始化。初始模型可以是任何预训练的LM,文章使用与生成模型LM相同的模型(即Llama 2-7B)来初始化。
- 数据采样:从原始训练数据中随机采样实例,形成用于训练评价模型的数据集。
- 生成反思Token(Reflection Tokens):手动为每个段落注释反思Token成本高昂,文章使用GPT-4(或其他高级语言模型)生成反思Token,这些Token用于评估是否需要检索、检索到的文档的相关性和生成文本的质量。
- 训练评价模型:将生成的反思Token与原始训练数据一起,训练评价模型,使其能够预测给定输入和输出的适当反思Token。
- 创建生成模型的训练数据:使用评价模型来评估每个生成的段落是否需要检索,如果需要,就检索相关的文档。然后,评价模型评估检索到的文档的相关性(
IsRel),支持度(IsSup),以及整体效用(IsUse)。 - 生成模型的训练:将上述步骤中收集到的数据,包括原始输入、输出和预测的反思Token,用于训练生成模型。生成模型被训练为能够预测下一个词,包括正常的生成文本和反思Token。
- 训练细节:训练时,可能会对检索到的文本块进行掩码处理,并且在损失计算时不包括这些文本块。此外,原始词汇表会通过添加反思Token进行扩展。
通过这些步骤,生成模型能够学习如何根据需要检索文档,并生成包含反思Token的文本,这些反思Token可以在推理阶段用于评估和改进生成文本的质量。
Self-Rag使用特殊的反思Token(Reflection Tokens)来生成和反思检索到的段落以及自身的生成内容。反思token在推理阶段使LLM可控,使其能够根据不同任务需求调整行为。具体来说,Self-Rag通过以下步骤工作:
- 确定是否需要通过检索来增强生成。
- 如果需要,输出一个检索token,按需调用检索器模型。
- 并行处理多个检索到的段落,评估它们的相关性,并生成相应的任务输出。
- 生成评价token来评价自身的输出,并选择最佳输出。
最近,吴恩达提到:“大型语言模型 (LLM) 的低成本token生成和智能体工作流为在合成数据上训练LLM开辟了有趣的新可能性。在LLM直接生成的响应上进行预训练是没有帮助的。但是,如果使用LLM实现的智能体工作流产生的输出质量高于LLM直接生成的输出质量,那么对该输出进行训练就很可能变得有用。”Self-Rag的方法也可以看做一种依靠智能体技术生成合成数据的案例!
反思Token(Reflection Tokens)的定义
文章的重要创新之处,是引入了反思Token(Reflection Tokens),所以先看看这个特殊的Token是如何定义的。

如上表所示,反思Token表明了检索的需求或评估输出的相关性、支持性或完整性。相比之下,常见的 RAG 方法不分青红皂白地检索段落,而不能确保引用来源的对输出的支持性。Self-Rag中使用的四种反思Token。每种类型使用几个token来表示其输出值。第一行是检索Token,下面三行是三种评价Token,粗体文本表示最理想的评价token。x、y、d分别表示输入的问题、输出的响应和检索的相关段落。下面是反思Token的具体定义。
检索需求(Retrieval-on-demand):
Retrieve: 给定输入和前一步生成的内容(如果适用),语言模型(LM)确定继续生成是否需要事实基础支撑。
No 表示检索是不必要的,因为序列不需要事实基础支撑,或者可能不会通过知识检索得到增强。
Yes 表示检索是必要的。
Continue to use evidence 表示模型可以继续使用之前检索到的段落。例如,一个段落可能包含丰富的事实信息,因此Self-Rag会基于该段落生成多个段落。
相关性(Relevance):
IsRel: 检索到的知识 d 可能并不总是与查询 x 相关。这个Token表明检索是否提供了有用的信息(Relevant)或者没有(Irrelevant)。
支持度(Support):
IsSup: 归因(Attribution)表示是否输出 y 完全由特定证据 d 支持。
这个方面根据证据支持的程度,评价输出信息的相关性,分为三个等级:Fully supported(完全支持)、Partially supported(部分支持)和No support / Contradictory(无支持/相反)。
有用性(Usefulness):
IsUse: 定义为响应 y 是否是查询 x 的有帮助和信息丰富的答案,无论它实际上是否真实。
对于有用性,使用五级评估(1是最低,5是最高)。
方法介绍
尽管最新的大型语言模型(LLMs)在模型和数据规模上有所增加,但它们在事实错误方面仍然存在挑战。检索增强生成(RAG)方法通过向LLMs的输入中增加检索到的相关段落,减少了知识密集型任务中的事实错误。然而,这些方法可能会阻碍LLMs的多功能性,或者引入不必要的或离题的段落,导致生成质量低下,因为它们无论检索的事实基础是否有帮助,都会不加选择地检索段落。此外,输出并不能保证与检索到的相关段落一致,因为模型没有明确地被训练去利用和遵循提供段落中的事实。
自反思检索增强生成(Self-Rag:Self-Reflective Retrieval-Augmented Generation),通过按需检索和自我反思,提高LLM生成质量,包括其事实准确性,而不会损害其多功能性。通过以端到端的方式训练任意的语言模型,让它学会在给定任务输入时反思自己的生成过程,通过生成任务输出和间歇性的特殊token(即反思token)。反思token被归类为检索和评价token,以分别指示检索需求和其生成质量。

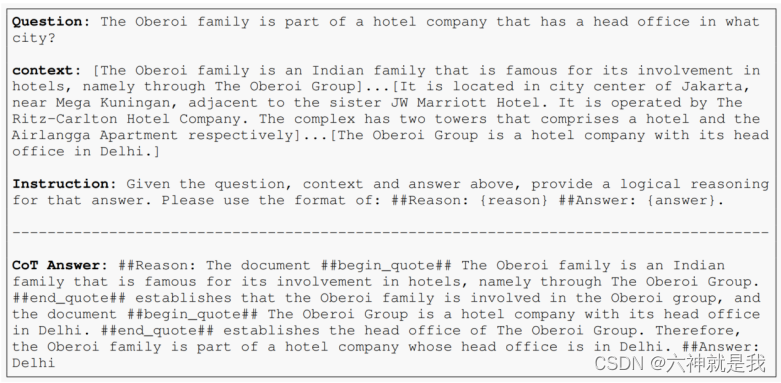
上图的左上侧是传统的RAG方式。图下侧通过左右两种情况对比,显示在某些情况下,不必要的检索会导致生成质量低下。
图的右上侧显示Self-Rag的流程,给定一个输入提示和上下文生成内容,Self-Rag首先确定是否需要通过检索段落来增强持续生成的内容。如果需要检索,它将输出一个检索token,按需调用检索器模型(步骤1)。随后,Self-Rag同时处理多个检索到的段落,评估它们的相关性,然后生成相应的任务输出(步骤2)。然后生成评价token来评估自身的输出,并在事实准确性和整体质量方面选择最佳输出(步骤3)。从图中看出,检索到的段落𝑑1被选中,因为𝑑2不提供直接证据(显示为不相关)、𝑑3虽然相关但是输出仅部分支持,而𝑑1完全支持。
这个过程与传统的RAG不同(图1左侧),后者在生成过程中始终检索固定数量的文档,无论是否需要检索(例如,底部图例示例不需要事实知识),并且从不重新审视生成质量。此外,Self-Rag为每个段落提供了相关性评估,以及自我评估输出是否由段落支持,从而更容易进行事实验证。
Self-Rag通过将反思token统一为模型词汇表中的下一个token预测,训练任意的语言模型生成带有反思token的文本。
生成模型LM是在一个多样化的文本集合上训练,这些文本与反思token和检索到的段落交错在一起。反思token受强化学习中的奖励模型启发,通过已经训练良好的评价模型离线插入到原始语料库。这种离线方式,减少了训练开销。
评价模型基于通过提示专有语言模型(GPT-4)收集的输入、输出和相应的反思token数据集进行监督学习。之前的研究使用控制token来启动和引导文本生成,这里训练的语言模型使用评价token在每个生成段之后评估自身的预测,作为生成输出的一个组成部分。
方法的算法表达
形式上,给定输入x,训练模型ℳ顺序生成由多个段落组成的文本输出y,其中y=[y1,…,yT],yt表示第t个段落的一系列Token。在实验中,将一个句子当作一个段落,但这个框架适用于任何段落单位(即子句)。yt中的生成token包括原始词汇表中的文本以及反思token。

推理概览:算法1展示了Self-Rag推理的流程。对于每个x和前面的已经生成的y,模型解码一个检索token以评估检索的效用。如果不需要检索,模型像标准LM一样预测下一个输出段落。如果需要检索,模型生成:一个评价token IsRel来评估检索段落的相关性,下一个响应段落,以及一个评价token IsSup来评估响应段落中的信息是否由段落支持。最后,一个新的评价token IsUse评估响应的整体效用。
生成每个段后,Self-Rag 并行处理多个段落,并使用自己生成的反思token对生成的任务输出实施相关控制。
训练概览:Self-Rag通过将反思token统一为模型词汇表中的下一个token预测,使任意LM能够生成带有反思token的文本。具体来说,在包含反思token的精选语料库上训练生成模型ℳ,使用标准的LM目标,使ℳ能够自己在推理时生成反思token,而无需依赖评价模型。
Self-Rag训练
具体看两个模型的监督数据收集和训练,即评价模型ℂ和生成模型ℳ。
1)训练评价模型
评价模型的数据收集
手动为每个段落注释反思token成本高昂。像GPT-4这样的最先进LLM可以有效地用于生成此类反馈。通过提示GPT-4生成反思token,然后将其知识提炼到内部ℂ中,创建监督数据。
对于每组反思token,从原始训练数据中随机采样实例:{Xsample,Ysample}∼{X,Y}。由于不同的反思token组有自己的定义和输入,需要使用不同的指令提示。这里,以检索为例,用类型特定的指令提示GPT-4(“给定一个指令,判断是否查找一些来自网络的外部文档有助于生成更好的响应。”),然后给定一些示例I,原始任务输入x和输出y,以预测适当的反思token作为文本:p(r|I,x,y)。
手动评估显示,GPT-4反思token预测与人类评估高度一致。为每种类型收集了4k-20k的监督训练数据,并将它们结合起来形成训练数据。
评价模型学习
在收集到训练数据Dcritic之后,使用预训练的LM初始化,并使用标准的有条件的语言建模目标对其进行训练,最大化概率见公式:

初始模型可以是任何预训练的LM,使用与生成模型LM相同的模型(即Llama 2-7B)来初始化ℂ。
2)训练生成模型
生成模型的数据收集
给定输入输出对(x,y),使用检索和评价模型增强原始输出y,创建精确模拟Self-Rag推理过程的监督数据。对于每个段落yt∈y,运行评价模型ℂ评估是否需要额外的段落来增强生成。
如果需要检索,检索特殊Token Retrieve=YES被添加,并且ℛ检索K个最高段落,D。对于每个段落,ℂ进一步评估该段落是否相关,并预测IsRel。
如果一个段落相关,ℂ进一步评估该段落是否支持模型生成,并预测IsSup。评价Token IsRel和IsSup被添加到检索到的段落或生成之后。
在输出的末尾y,ℂ预测整体效用Token IsUse,并且带有反思token和原始输入对的增强输出被添加到数据集Dgen中。下图是训练数据示例。

生成模型学习
Self-Rag 通过将反射token统一为模型词汇表中的下一个token预测,使LM能够生成带有反思token的文本。具体来说,在包含检索到的段落和由评价模型预测的反思token的语料库上训练生成模型 ℳ。通过在带有反思token的精选语料库Dgen上训练,训练生成模型ℳ的预测下一个token的训练目标:

与ℂ训练目标不同,ℳ学习预测目标输出以及反思token。在训练期间,损失计算时遮蔽检索到的文本块,并将原始词汇表扩展为包含反思token的集合。
训练数据
最后看一下训练数据和提示是如何样子。简单截取片段,作为示例,详细的可以参见原文。
训练数据示例:

用于GPT-4生成反思token的提示,只选一种情况,仅有输入情况下的生成检索Token的提示(其他的提示包括给定输入、历史输出和检索段落的检索Token、以及生成评价Token的各种不同的提示):