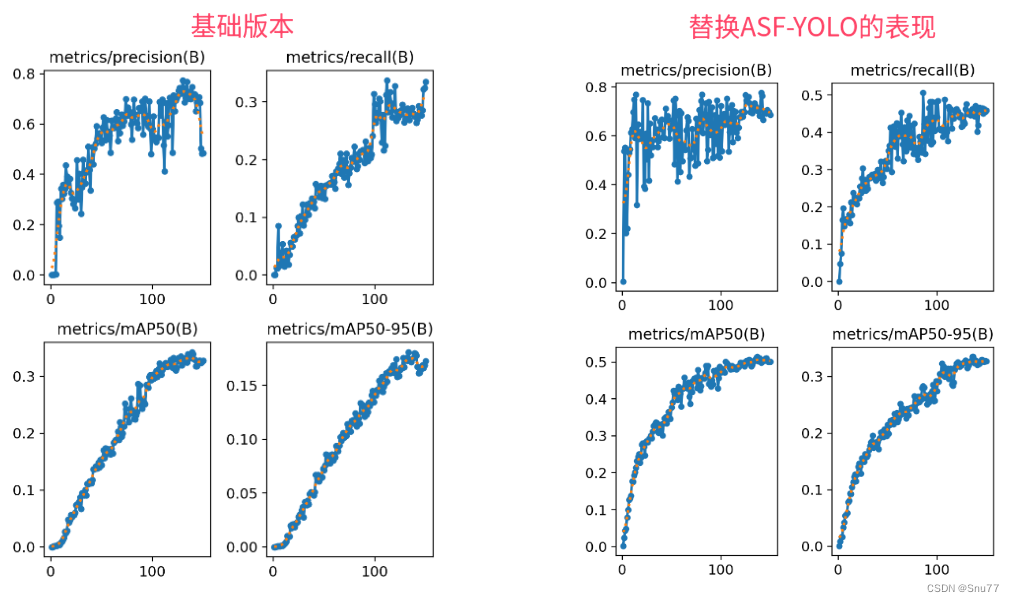
1.BiFPN介绍

摘要:模型效率在计算机视觉中变得越来越重要。 在本文中,我们系统地研究了用于目标检测的神经网络架构设计选择,并提出了几个提高效率的关键优化。 首先,我们提出了一种加权双向特征金字塔网络(BiFPN),它可以轻松快速地进行多尺度特征融合; 其次,我们提出了一种复合缩放方法,可以同时统一缩放所有主干网络、特征网络和框/类预测网络的分辨率、深度和宽度。 基于这些优化和更好的主干,我们开发了一个新的目标检测器系列,称为EfficientDet,它在各种资源限制下始终实现比现有技术更高的效率。 特别是,通过单模型和单尺度,我们的EfficientDet-D7 在 COCO 测试开发上实现了最先进的 55.1AP,具有77M参数和410B FLOPs1,比以前的检测器小4至9倍,使用的FLOP数减少13至42倍。
官方论文地址:https://arxiv.org/pdf/1911.09070
官方代码地址:https://github.com/google/automl/tree/
简单介绍: 本文给大家带来的改进机制是BiFPN双向特征金字塔网络,是一种特征融合层的结构,改进YOLOv10模型中的Neck部分,它的主要思想是通过多层级的特征金字塔和双向信息传递来提高精度。
BiFPN模块结构图:

2.核心代码
import torch.nn as nn
import torch
class swish(nn.Module):
def forward(self, x):
return x * torch.sigmoid(x)
class BiFPN(nn.Module):
def __init__(self, length):
super().__init__()
self.weight = nn.Parameter(torch.ones(length, dtype=torch.float32), requires_grad=True)
self.swish = swish()
self.epsilon = 0.0001
def forward(self, x):
weights = self.weight / (torch.sum(self.swish(self.weight), dim=0) + self.epsilon)
weighted_feature_maps = [weights[i] * x[i] for i in range(len(x))]
stacked_feature_maps = torch.stack(weighted_feature_maps, dim=0)
result = torch.sum(stacked_feature_maps, dim=0)
return result3.YOLOv10中添加BiFPN方式
3.1 在ultralytics/nn下新建Extramodule

3.2 在Extramodule里创建BiFPN


在BiFPN.py文件里添加给出的BiFPN代码
添加完BiFPN代码后,在ultralytics/nn/Extramodule/__init__.py文件中引用

3.3 在task.py里引用
在ultralytics/nn/tasks.py文件里引用Extramodule

在task.py找到parse_model(ctrl+f可以直接搜索parse_model位置)
添加如下代码:

给出代码:
elif m in {BiFPN}:
length = len([ch[x] for x in f])
args = [length]4.新建一个yolov10nBiFPN.yaml文件
新建一个yolov10nBiFPN.yaml文件后,在Neck部分添加了BiFPN模块。
给出yolov10nBiFPN.yaml代码
# Parameters
nc: 2 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024]
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, SCDown, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, SCDown, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
- [-1, 1, PSA, [1024]] # 10
# YOLOv8.0n head
head:
- [4, 1, Conv, [256]] # 11-P3/8
- [6, 1, Conv, [256]] # 12-P4/16
- [9, 1, Conv, [256]] # 13-P5/32
- [-1, 1, nn.Upsample, [None, 2, 'nearest']] # 14 P5->P4
- [[-1, 12], 1, BiFPN, []] # 15
- [-1, 3, C2f, [256]] # 16-P4/16
- [-1, 1, nn.Upsample, [None, 2, 'nearest']] # 17 P4->P3
- [[-1, 11], 1, BiFPN, []] # 18
- [-1, 3, C2f, [256]] # 19-P3/8
- [1, 1, Conv, [256, 3, 2]] # 20 P2->P3
- [[-1, 11, 19], 1, BiFPN, []] # 21
- [-1, 3, C2f, [256]] # 22-P3/8
- [-1, 1, Conv, [256, 3, 2]] # 23 P3->P4
- [[-1, 12, 16], 1, BiFPN, []] # 24
- [-1, 3, C2f, [512]] # 25-P4/16
- [-1, 1, SCDown, [256, 3, 2]] # 26 P4->P5
- [[-1, 13], 1, BiFPN, []] # 27
- [-1, 3, C2fCIB, [1024]] # 28-P5/32
- [[22, 25, 28], 1, v10Detect, [nc]] # Detect(P3, P4, P5)大家根据自己的数据集实际情况,修改nc大小。
5.模型训练
模型结构打印,成功运行 :

6.本文总结
到此本文的正式分享内容就结束了,在这里给大家推荐我的YOLOv10改进有效涨点专栏,后期我会根据各种最新的前沿顶会进行论文复现,也会对一些老的改进机制进行补充,如果大家觉得本文帮助到你了,订阅本专栏,关注后续更多的更新~