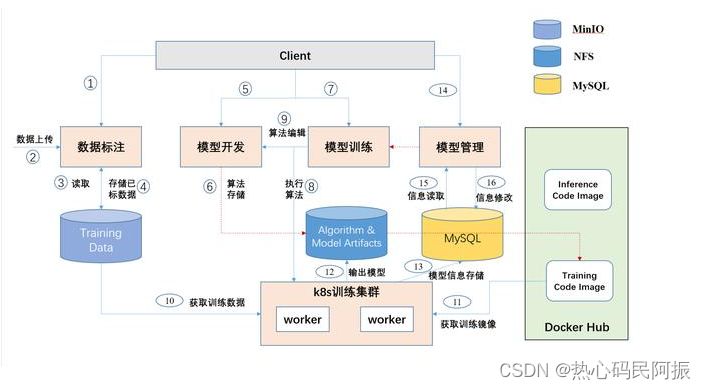
目录
8.1.2 前馈神经网络(Feed-Forward Neural Network, FFN)
1. 模型概述
定义
- Gemini是谷歌DeepMind开发的一款多模态大模型,具有处理文本、图像、音频和视频等多种数据类型的能力。
特点
- 采用了Transformer解码器(Decode Only)作为基础架构,针对神经网络结构和目标进行了优化,提升了大规模预训练时训练和推理的稳定性。
- 支持长达32k的上下文长度,采用了高效的注意机制,如多查询注意力(Multi-query Attention)。
2. 模型基础与架构
模型架构
- Gemini基于Transformer解码器(Decode Only)构建,这是一个常用于处理序列数据的神经网络架构。
- Gemini采用了类似于GPT的Decoder-only模式,即只包含解码器部分,用于预测下一个token。
模型尺寸
- Gemini系列包括Ultra、Pro和Nano三种尺寸,分别针对不同复杂度的任务和应用场景。
- Gemini Ultra:最强大的模型,适用于各种高度复杂的任务,包括推理和多模式任务。
- Gemini Pro:适用于处理多个任务的模型,性价比高,具有良好的延展性。
- Gemini Nano:小型模型,支持在本地部署,提供了最佳的小型语言模型,用于处理终端上设备的特定任务。
3. 多模态处理能力
输入处理
- Gemini支持文本、图像、音频和视频的交错序列作为输入。
- 输入序列中使用不同颜色的标记来表示不同的模态数据。
数据处理
- 所有模态的数据首先被转换成tokens。
- 对于图像和视频等平面数据,通过特定的方式(如将图像划分为32x32的tokens)将其转化为一维线性输入。
训练过程
- Gemini遵循next token prediction的模式进行训练,预测下一个token,从而统一了不同模态在预训练阶段的处理方式。
4. 技术细节与优化
预训练
- Gemini的预训练在训练算法、数据集和基础设施方面进行了创新。
- 采用了Transformer解码器,并针对神经网络结构和目标进行了优化,提升了大规模预训练时训练和推理的稳定性。
上下文长度
- 经过训练以支持32k的上下文长度,这在处理长文本或复杂任务时非常有用。
注意机制
- 采用了高效的注意机制,如多查询注意力(Multi-query Attention),以提高模型在处理复杂任务时的效率。
5. 安全性与编程能力
安全性评估
- Gemini拥有全面的安全性评估,确保在处理敏感数据或执行关键任务时能够保持高度安全性。
编程能力
- Gemini可以理解并生成主流编程语言(如Python、Java、C++)的高质量代码,这对于自动化编程和代码生成等任务非常有用。
6. 模型发布与应用
发布时间
- Gemini于2023年12月6日由谷歌DeepMind发布。
应用方向
- 谷歌计划逐步将Gemini整合到其搜索、广告、Chrome等其他服务中,以提供更丰富、更智能的用户体验。
7. 性能评估
- Gemini在多模态方面表现出色,在新的MMMU基准测试中获得了较高的SOTA分数。
8. 数学基础
8.1.2 前馈神经网络(Feed-Forward Neural Network, FFN)
8.2 多模态处理
8.3 模型优化与特点
大模型Gemini的数学原理主要基于Transformer架构,特别是其解码器部分,并结合了多模态处理技术和特定的优化方法。
8.1 Transformer解码器基础
8.1.1 自注意力机制(Self-Attention)
- 输入嵌入:首先将输入序列(文本、图像、音频等模态的嵌入)转换为嵌入向量。
- 查询(Query)、键(Key)和值(Value):
- 对于每个位置,计算其对应的查询、键和值向量,通常通过线性变换(权重矩阵乘法)得到。
- 注意力分数:
- 对于每个查询,计算其与所有键的点积,并除以键的维度的平方根(例如(\sqrt{d_k}))进行缩放。
- 数学公式:(Attention\ Scores = \frac{Query \cdot Key}{\sqrt{d_k}})
- 注意力权重:
- 将注意力分数输入softmax函数进行归一化,得到注意力权重。
- 数学公式:(Attention\ Weights = softmax(Attention\ Scores))
- 加权和:
- 将注意力权重与对应的值向量相乘,然后求和,得到自注意力的输出。
- 数学公式:(Output = \sum_{i} Attention\ Weights_i \cdot Value_i)
- 在自注意力层之后,通常包含一个或多个前馈神经网络层。
- 数学公式:(FFN(x) = \text{ReLU}(xW_1 + b_1)W_2 + b_2)
- 其中,(x) 是输入,(W_1) 和 (W_2) 是权重矩阵,(b_1) 和 (b_2) 是偏置项,ReLU是激活函数。
- 模态嵌入:
- 对于文本、图像、音频等不同模态的数据,Gemini使用特定的嵌入方法将其转换为统一的嵌入向量。
- 例如,对于图像数据,可以使用CNN(卷积神经网络)提取特征,并将其转换为嵌入向量。
- 模态融合:
- 将不同模态的嵌入向量进行融合,以得到一个统一的表示。
- 这可以通过简单的拼接、加权和或更复杂的注意力机制来实现。
- 上下文长度:Gemini支持高达32k的上下文长度,这使得模型能够处理更长的序列和更复杂的任务。
- 高效的注意力机制:如多查询注意力(Multi-query Attention),提高了模型在处理复杂任务时的效率。
- 模型规模:Gemini提供了Ultra、Pro和Nano三种不同规模的模型,以满足不同计算能力和应用场景的需求。
- 预训练与微调:Gemini在大量多模态数据集上进行预训练,并在特定任务上进行微调,以实现更好的性能