开始使用 TensorFlow
借助 TensorFlow,轻松创建可在任何环境中运行的机器学习模型。 通过交互式代码示例,了解如何使用直观的 API。
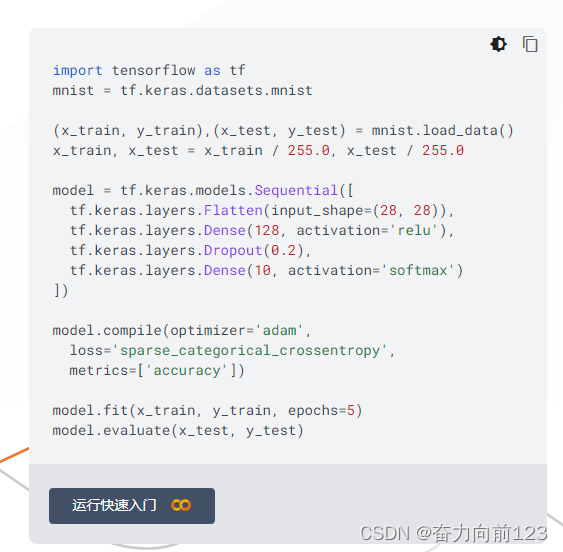
import tensorflow as tf
mnist = tf.keras.datasets.mnist
(x_train, y_train),(x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.fit(x_train, y_train, epochs=5)
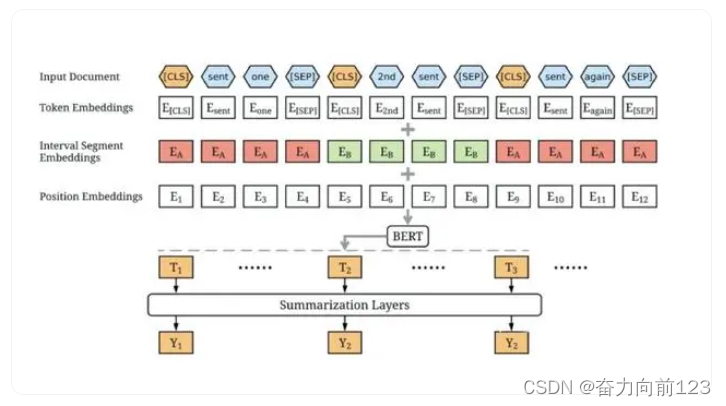
model.evaluate(x_test, y_test)上面代码是一个使用TensorFlow和Keras库训练MNIST手写数字识别模型的示例。这个代码展示了如何加载MNIST数据集、预处理数据、构建模型、编译模型、训练模型以及评估模型在测试集上的性能。
这里是代码的逐行解释:
- 导入TensorFlow:
import tensorflow as tf |
这行代码导入了TensorFlow库,并给它一个别名tf,这样在代码中就可以使用tf来引用TensorFlow的功能。
- 加载MNIST数据集:
mnist = tf.keras.datasets.mnist |
|
(x_train, y_train),(x_test, y_test) = mnist.load_data() |
这里首先通过tf.keras.datasets.mnist获取了MNIST数据集的引用,然后使用load_data()方法加载了数据集。这个方法返回两个元组,分别包含训练集和测试集的特征(图像)和标签(数字)。
- 数据预处理:
x_train, x_test = x_train / 255.0, x_test / 255.0 |
由于MNIST图像的数据类型是uint8,其值域为0-255。为了使得模型更容易训练,通常将这些值归一化到0-1之间。这里通过简单的除法操作实现了归一化。
- 构建模型:
model = tf.keras.models.Sequential([ |
|
tf.keras.layers.Flatten(input_shape=(28, 28)), |
|
tf.keras.layers.Dense(128, activation='relu'), |
|
tf.keras.layers.Dropout(0.2), |
|
tf.keras.layers.Dense(10, activation='softmax') |
|
]) |
这里使用Keras的Sequential模型API定义了一个简单的神经网络。模型首先使用Flatten层将输入的28x28图像展平为一维向量,然后是一个包含128个神经元和ReLU激活函数的Dense(全连接)层,接着是一个丢弃率为0.2的Dropout层用于防止过拟合,最后是一个包含10个神经元和softmax激活函数的输出层,用于多分类任务。
- 编译模型:
model.compile(optimizer='adam', |
|
loss='sparse_categorical_crossentropy', |
|
metrics=['accuracy']) |
这行代码配置了模型训练所需的优化器、损失函数和评估指标。这里使用了Adam优化器、sparse categorical crossentropy损失函数以及准确率作为评估指标。
- 训练模型:
model.fit(x_train, y_train, epochs=5) |
这行代码启动了模型的训练过程。模型将在训练集(x_train, y_train)上进行训练,并运行5个epoch(即遍历整个训练集5次)。
- 评估模型:
model.evaluate(x_test, y_test) |
最后,这行代码在测试集(x_test, y_test)上评估了模型的性能。它会返回测试集上的损失值和准确率。