⚠申明: 未经许可,禁止以任何形式转载,若要引用,请标注链接地址。 全文共计6023字,阅读大概需要10分钟
🌈更多学习内容, 欢迎👏关注👀【文末】我的个人微信公众号:不懂开发的程序猿
⏰个人网站:https://jerry-jy.co/❗❗❗知识付费,🈲止白嫖,有需要请后台私信或【文末】个人微信公众号联系我
基于PyTorch实现MNIST手写字识别
基于PyTorch实现MNIST手写字识别
任务需求
MNIST数据库是一个手写数字图像的数据库,它提供了60000的训练集和10000的测试集。它的每个图像是被规范处理过的,是一张被放在中间部位的28x28的黑白图像。
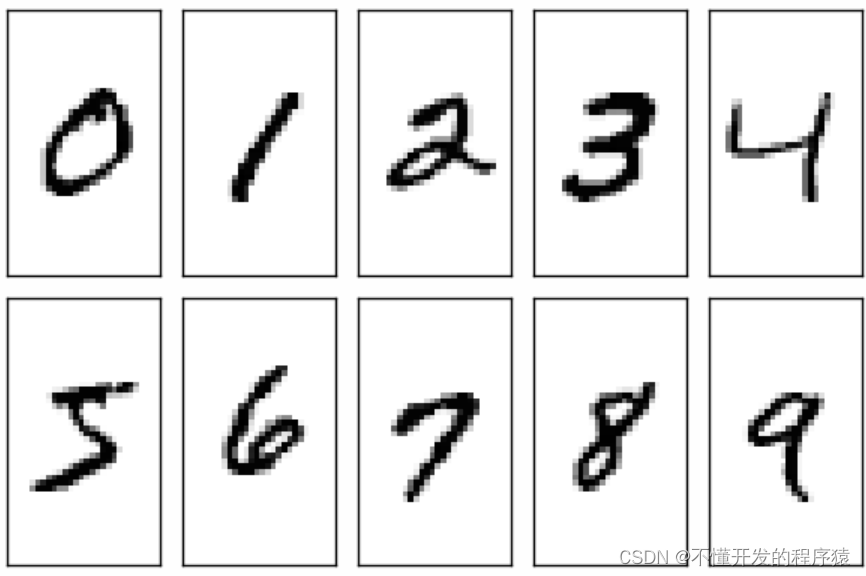
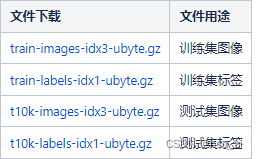
总共4个文件:
train-images-idx3-ubyte: 训练图像数据集
train-labels-idx1-ubyte: 训练图像标记数据集
t10k-images-idx3-ubyte: 测试图像数据集
t10k-labels-idx1-ubyte: 测试图像标记数据集
图像都被转成二进制放到了文件里面,每一个文件头部几个字节都记录着这些图像的信息,然后才是储存的图像信息。
使用Pytorch构建一个简单的神经网络,并对MNIST数据集进行了训练和测试,使用测试集来验证训练出的模型对手写数字的识别准确率。
任务目标
掌握Pytorch加载数据集并归一化处理方法
掌握使用Pytorch构建神经网络
任务分析

任务分解
本任务共设定3个子任务,分4大步骤完成。
第1步:准备python环境,创建python工程
第2步:加载MNIST数据并归一化
第3步:定义一个神经网络并定义损失函数和优化函数
第4步:训练网络并使用测试集来验证模型识别准确率
任务环境
Oracle Linux 7.4
Python3
任务实施过程
1.打开Jupyter,并新建python工程
1.桌面空白处右键,点击Konsole打开一个终端
2.切换至/experiment/jupyter目录
cd experiment/jupyter
3.启动Jupyter,root用户下运行需加–allow-root
jupyter notebook --ip=127.0.0.1 --allow-root
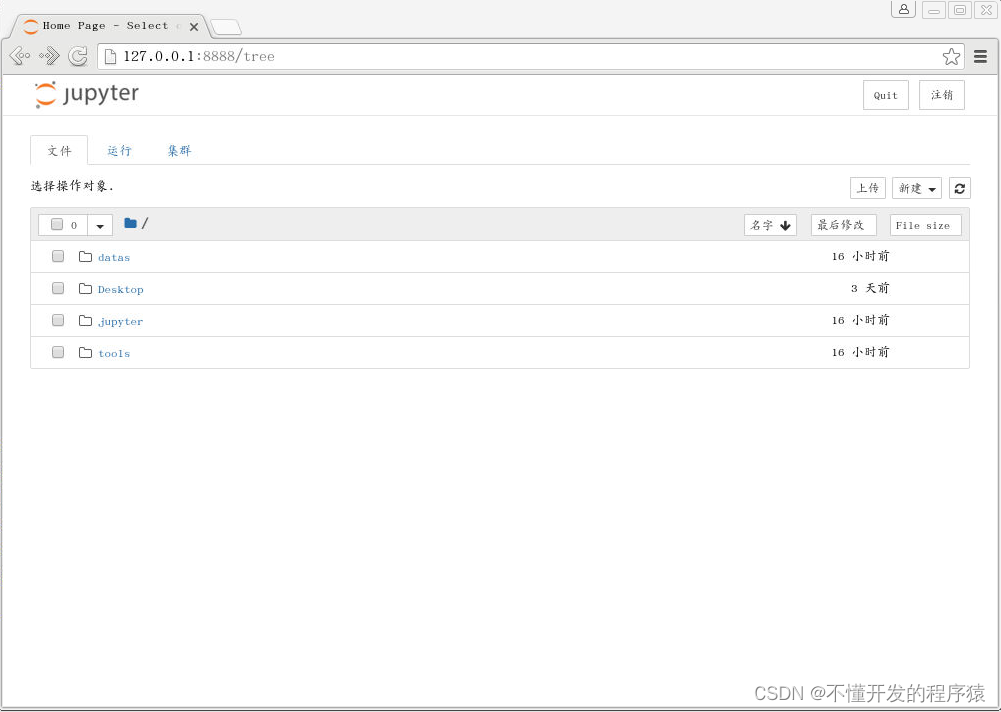
4.依次点击右上角的 New,Python 3新建python工程
5.点击Untitled,在弹出框中修改标题名,点击Rename确认
2.加载MNIST
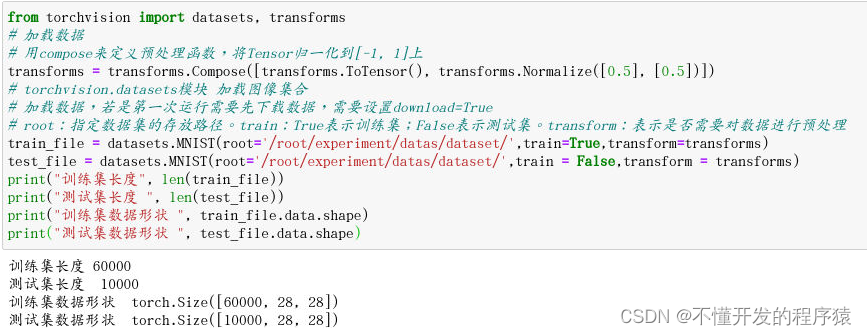
(1)加载MNIST数据,如果第一次执行需要下载数据集,这里数据集已经在对应路径下,不需要下载。
from torchvision import datasets, transforms
# 加载数据
# 用compose来定义预处理函数,将Tensor归一化到[-1, 1]上
transforms = transforms.Compose([transforms.ToTensor(), transforms.Normalize([0.5], [0.5])])
# torchvision.datasets模块 加载图像集合
# 加载数据,若是第一次运行需要先下载数据,需要设置download=True
# root:指定数据集的存放路径。train:True表示训练集;False表示测试集。transform:表示是否需要对数据进行预处理
train_file = datasets.MNIST(root='/root/experiment/datas/dataset/',train=True,transform=transforms)
test_file = datasets.MNIST(root='/root/experiment/datas/dataset/',train = False,transform = transforms)
print("训练集长度", len(train_file))
print("测试集长度 ", len(test_file))
print("训练集数据形状 ", train_file.data.shape)
print("测试集数据形状 ", test_file.data.shape)
(2)对数据集进行批处理
数据集里面很多个数据,不能一次喂入,所以需要分成一小块一小块喂入搭建好的网络。
pytorch中DataLoader可以将数据分成预定义大小的批次。
from torch.utils.data import DataLoader # 导入数据装载器
# dataloader则是加载dataset,并设置其batch_size(单次训练时送入的样本数目),
# shuffle=True表示打乱样本顺序
train_loader = DataLoader(dataset = train_file, batch_size = 100, shuffle = True)
test_loader = DataLoader(dataset = test_file, batch_size= 100, shuffle = True)

(3)训练数据可视化
import torch
# 训练数据可视化
torch.manual_seed(1) # 设置随机种子
import matplotlib.pyplot as plt
# 用来正常显示中文标签
plt.rc('font',family="SimHei")
examples = enumerate(train_loader)
# data里含有图像数据(data,tensor类型)和标签(labels,tensor类型)
batch_idx,(data,labels) = next(examples)
fig = plt.figure(figsize=(5,5)) # 设置画布大小
for i in range(9):
plt.subplot(3,3,i+1)
plt.tight_layout() # 设子图间距
# 用plt.imshow()可以将digits数据集中images可视化
# cmap='gray'显示灰度图;interpolation = ‘none’不执行插值
plt.imshow(data[i][0],cmap='gray',interpolation='none')
plt.title("训练图片:{}".format(labels[i])) # 设置子图标题,标题中显示正确标签
plt.xticks([]) # 不显示x轴
plt.yticks([]) # 不显示y轴


3.构建神经网络
torch.nn是专门为神经网络设计的模块化接口。可以用来定义和运行神经网络。
nn.Module是nn中十分重要的类,包含网络各层的定义及forward方法。
激活函数是用来加入非线性因素的,提高神经网络对模型的表达能力,解决线性模型所不能解决的问题。
(1)构建神经网络模型
from torch import nn
# 搭建神经网络
# 定义一个名为Net的网络模型, 输入为28*28维, 输出为10维
class Net(nn.Module):
def __init__(self, input_num, hidden_num, output_num):
# nn.Module的子类函数必须在构造函数中执行父类的构造函数
super(Net, self).__init__()
self.fc1 = nn.Linear(input_num, hidden_num) # 完成从输入层到隐藏层的线性变换
self.relu = nn.ReLU() # 非线性激活函数
self.fc2 = nn.Linear(hidden_num, output_num) # 完成从隐藏层到输出层的线性变换
def forward(self,x):
x = self.fc1(x)
x = self.relu(x)
x = self.fc2(x)
return x

(2)参数初始化, 产生训练模型对象以及定义损失函数和优化函数
import torch.optim as optim
# 参数初始化
epoches = 5
input_num = 784
hidden_num = 500
output_num = 10
# 产生训练模型对象以及定义损失函数和优化函数
model = Net(input_num, hidden_num, output_num)
criterion = nn.CrossEntropyLoss() # 使用交叉熵作为损失函数
optimizer = optim.Adam(model.parameters()) # 构建优化函数,放入模型参数

4.训练网络并计算测试集准确率
(1)训练网络
# 开始循环训练
Loss_list=[]
# 一个epoch可以认为是一次训练循环
for epoch in range(epoches):
for i, data in enumerate(train_loader):
# 获取每张图片的 数据(data)矩
(images, labels) = data
images = images.reshape(-1, 28*28) # 列数定为28*28,自动计算行数
output = model(images) # 1、前向求出预测值
# criterion()计算损失,传入的参数: 输出值(预测值), 实际值(标签) 需要labels中的数据是long类型
loss = criterion(output, labels.long()) # 2、求出损失函数
optimizer.zero_grad() # 3.1梯度始化为零
loss.backward() # 3.2反向传播,计算当前梯度
optimizer.step() # 4根据梯度更新网络参数
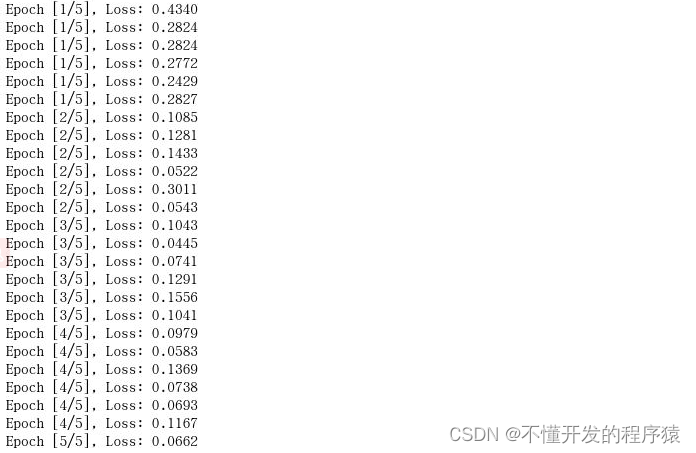
# 打印每个循环中,每100个样本的loss值,i表示样本的编号。loss.item 将一个张量转换成浮点数
if (i+1) % 100 == 0:
print('Epoch [{}/{}], Loss: {:.4f}'.format(epoch + 1, epoches, loss.item()))
Loss_list.append(loss.item())

(2)计算测试集准确率
# 开始测试
# 强制之后的内容不进行计算图构建
with torch.no_grad():
correct = 0 # 用来计算测试数据预测正确总数
total = 0 # 用来计算测试数据总数
for images, labels in test_loader:
images = images.reshape(-1, 28*28) # 列数定为28*28,自动计算行数
output = model(images) # 经过模型,求出预测值
_, predicted = torch.max(output, dim=1)# 返回预测值在给定维度上每行的最大值和位置索引
total += labels.size(0) # 此处的size()类似numpy的shape: np.shape(train_images)[0]
correct += (predicted == labels).sum().item() # 计算预测标签正确的个数
print("测试数据共 {} 个,预测正确率为: {}%".format(total, 100 * correct/total))

–end–
说明
本实验(项目)/论文若有需要,请后台私信或【文末】个人微信公众号联系我

























![[next.js]移动端调试vconsole](https://img-blog.csdnimg.cn/direct/ee7714ef43924b7296641e920f0bed5e.png)