Transformers 核心设计Auto Classes
Transformers Auto Classes 设计:统一接口、自动检索
AutoClasses 旨在通过全局统一的接口 from_pretrained() ,实现基于名称(路径)自动检索预训练权重(模
型)、配置文件、词汇表等所有与模型相关的抽象。

灵活扩展的配置AutoConfig
transformers.AutoConfig 类实例化通常由from_pretrained(pretrained_model_name_or_path, ) 方法完成。
Transformers 根据配置中的 model_type 加载预定义配置,兜底方案是基于模型名称/路径自动推断。
自动化模型管理 AutoModel
transformers.AutoModel 类实例化通常由from_pretrained() 或 from_config() 方法完成。
换句话说,Transformers 可以从预训练模型文件或配置中完成模型加载。
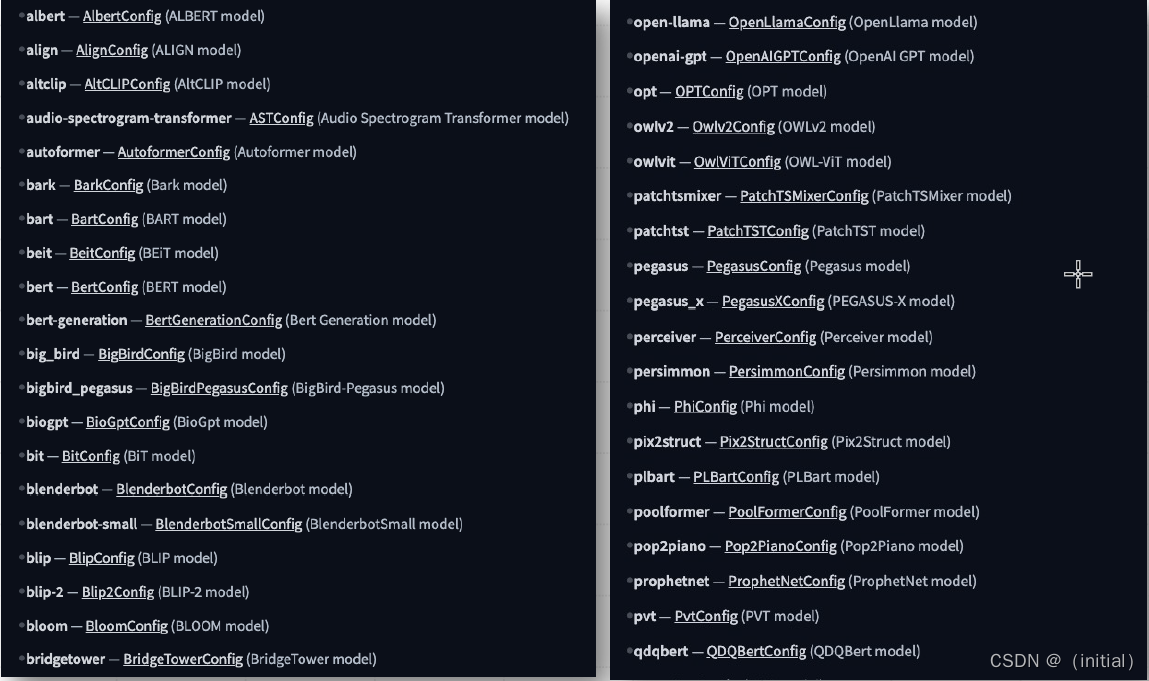
通用分词器 AutoTokenizer
transformers.AutoModel 类实例化通常由from_pretrained(pretrained_model_name_or_path) 方法完成。
Transformers 同样是优先基于 model_type 来自动匹配 Tokenizer,兜底方案是基于模型名称/路径自动推断
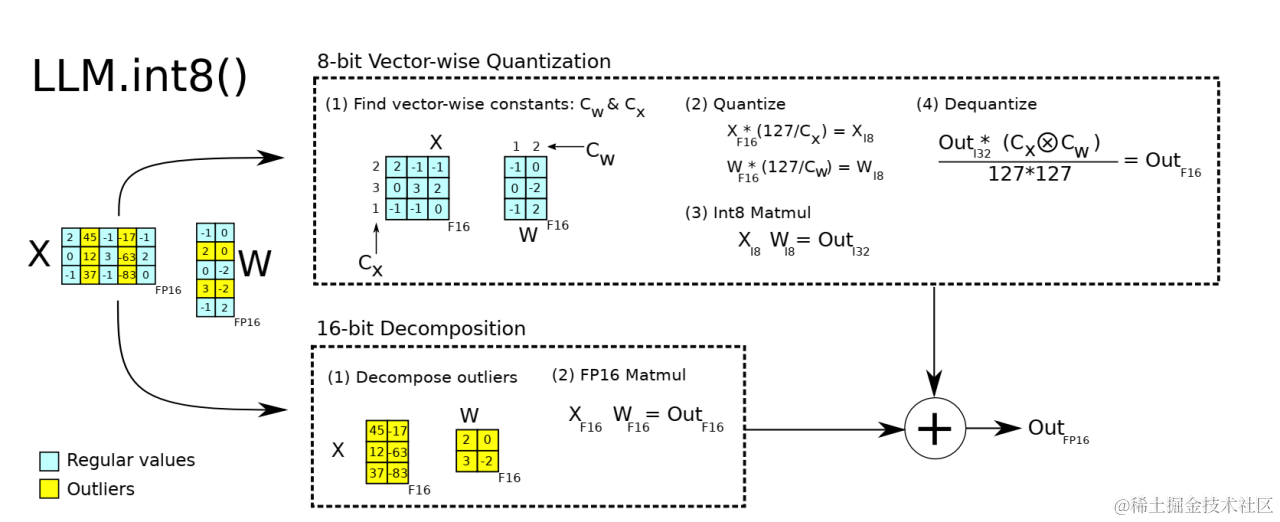
Transformers 模型量化 Quantization
模型量化技术
量化(Quantization)技术专注于用较少的信息表示数据,同时尽量不损失太多准确性。
具体来说,量化会将模型参数使用的数据类型,转换为更少位数表示,并尽可能达到相同信息的效果。
例如,假设您的模型权重原始以32位(32-bit)浮点数(Float32)存储。
- 如果将它们量化为16位(16-bit)浮点数(Float16),则可以将模型大小减半。换句话说,仅需要一半的 GPU 显存即可加载量化后的模型。
- 如果将模型量化为8位(8-bit)整数(Int8),则大约只需要四分之一的显存开销。























![[office] excel表格中双击鼠标左键有什么快捷作用- #经验分享#媒体](https://img-blog.csdnimg.cn/img_convert/78655764f92aa9382f17a7bc6a0bd7aa.jpeg)