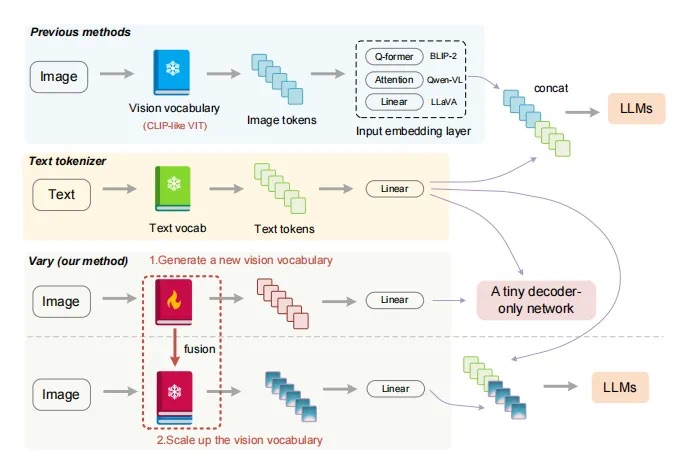
论文题目:统一感知解析:场景理解的新视角 Unified Perceptual Parsing for Scene Understanding
论文链接:http://arxiv.org/abs/1807.10221(ECCV 2018)
代码链接:https://github.com/CSAILVision/unifiedparsing
一、摘要
研究了一个新的任务,称为统一感知解析,它要求机器视觉系统从给定的图像中识别尽可能多的视觉概念。为此,开发了一个多任务框架——UPerNet,并提出了一种训练策略,以学习异构图像注释。在统一感知解析任务上评估了UPerNet框架,结果显示它能够有效地从图像中分割出广泛的概念。训练后的网络还被应用于发现自然场景中的视觉知识。
文章目录
二、创新点
1)提出了一项新的解析任务——统一感知解析,要求系统同时解析多个视觉概念。
2)提出了一种名为UPerNet的新型网络,具有层次结构,能够从多个图像数据集的异构数据中学习。
3)模型展示了能够联合推断和发现图像下的丰富视觉知识。
三、关键问题
神经网络是否能够同时解决多个视觉识别任务?这激发了该工作,引入了一个新的任务——统一感知解析(Unified Perceptual Parsing,UPP),并提出了一种新的学习方法来应对这一挑战。
问题:没有单一的图像数据集标注了所有层次的视觉信息。
解决:提出了一种框架,克服了不同数据集的异质性,学习同时检测各种视觉概念。一方面,每次迭代时,随机选择一个数据源,并仅更新相关路径上的层以从所选源推断概念,避免了针对特定概念注解的梯度噪声。另一方面,该框架利用单个网络特征的层次结构:对于具有更高语义级别的概念,如场景分类,分类器基于具有更高语义的特征图构建;对于较低层次的语义,如对象和材质分割,分类器基于所有阶段特征融合或仅低层次语义的特征图构建。还提出了一种训练方法,使网络能够仅使用图像级别的注解预测像素级的纹理标签。
四、原理
该工作建立在语义分割和多任务学习的先前研究之上。

1、Defining Unified Perceptual Parsing
定义统一感知解析任务(Unified Perceptual Parsing)为从给定图像中识别尽可能多的视觉概念。可能的视觉概念被组织成多个层次:从场景标签、物体和物体的部分,到物体的材质和纹理。这项任务的完成依赖于不同类型训练数据的可用性。由于没有单一的图像数据集对所有层次的视觉概念进行了标注,首先通过结合多个图像标注来源构建了一个图像数据集。
Datasets
为了实现对多级别视觉概念的广泛分割,利用了Broden数据集[26],这是一个包含各种视觉概念的异质数据集。Broden整合了ADE20K[2]、Pascal-Context[27]、Pascal-Part[28]、OpenSurfaces[6]和Describable Textures Dataset (DTD)[4]等密集标注的图像数据集。这些数据集包含了各种场景、物体、物体部件、材料和纹理的样本,涵盖了多种上下文。物体、物体部件和材料被像素级分割,而纹理和场景则以图像级标注。
尽管Broden数据集提供了丰富的视觉概念,但因其最初是为了解释卷积神经网络(CNN)的视觉概念与隐藏单元之间的对应关系而收集,作者发现不同类别的样本分布不平衡。(因此,对Broden数据集进行了标准化,使其更适合训练分割网络。首先,合并了不同数据集中相似的概念,如ADE20K、Pascal-Context和Pascal-Part中的物体和部件标注被统一。其次,只包含至少出现在50张图像中且在整个数据集中至少有50,000像素的物体类别,以及至少出现在20张图像中的有效部件。概念上不一致的物体和部件被手动移除。第三,手动合并OpenSurfaces中样本不足的标签,如将石头和混凝土合并为石头,透明塑料和不透明塑料合并为塑料。出现次数少于50次的标签也被过滤掉。第四,从ADE20K数据集中映射超过400个场景标签到Places数据集的365个标签[30]。)

表1展示了标准化后的Broden(称为Broden+)的一些统计信息。Broden+总共有57,095张图像,包括来自ADE20K的22,210张,Pascal-Context和Pascal-Part的10,103张,OpenSurfaces的19,142张,以及DTD的5,640张。图2展示了按所属物体分组的物体和部件的分布情况。图3展示了Broden+数据集各来源的示例。


Metrics
为了衡量模型性能,根据每个数据集的注释设置了不同的指标。对于语义分割任务,标准的评估指标包括像素精度(P.A.),它表示正确分类像素的比例,以及平均交并比(mIoU),它表示针对所有对象类别预测像素与真实像素的交并比的平均值。注意,由于图像中可能存在未标注区域,mIoU指标不会计算在未标注区域的预测。这促使人们在训练时排除背景标签。然而,这不适合部分分割等任务的评估,因为对于某些对象,带有部分注释的区域只占像素的少数。因此,在某些任务中使用包含背景区域的mIoU(mIoU-bg)。这样,训练时排除背景标签会略微提高P.A.,但会显著降低mIoU-bg的性能。
对于ADE20K、Pascal-Context和OpenSurfaces涉及的对象和材料解析任务,注释是像素级别的。ADE20K和Pascal-Context的图像完全注释,不属于预定义类别的区域被归类为未标注类别。OpenSurfaces的图像部分注解,即如果一个图像中有多个材料区域,可能不止一个区域未被标注。使用P.A.和mIoU来评估这两个任务。对于对象部分,出于上述原因使用P.A.和mIoU-bg。首先对每个部分的IoU在对象类别内求平均,然后对所有对象类别求平均。对于场景和纹理分类,作者报告最高精度。评估指标见表1。
为了在不同类别标签之间平衡样本,首先随机抽取10%的原始图像作为验证集。然后,从训练和验证集中随机选择一张图像,交换后检查像素级注释是否更均衡地分布到10%。这个过程重复进行。数据集被划分为51,617张图像用于训练,5,478张图像用于验证。在网络后部添加金字塔池化模块(PPM)[16]后,将特征馈送到FPN的自上而下的分支。右上图:使用不同语义级别的特征。场景头直接连接在PPM后的特征图上,因为图像级别的信息更适合场景分类。对象和部分头连接在FPN输出的所有层融合后的特征图上。材料头连接在FPN具有最高分辨率的特征图上。纹理头连接在ResNet[1]的Res-2块上,并在完成其他任务的整个网络训练后进行微调。下图:不同头的示意图。

2、Designing Networks for Unified Perceptual Parsing
在图4中展示了网络设计,称为UPerNet(统一感知解析网络),它基于特征金字塔网络(FPN)[31]。为了解决Zhou等人提出的深度卷积神经网络(CNN)的理论感受野足够大,但实际感受野相对较小的问题[32, 33],在将特征图输入FPN的顶部下采样分支之前,对基干网络的最后一层应用了PSPNet中的金字塔池化模块(PPM)。作者发现,PPM与FPN架构高度兼容,能够提供有效的全局先验表示。
新框架能够统一解析多级别的视觉属性。将ResNet各阶段的最后一个特征图集记为{C2, C3, C4, C5},而FPN输出的特征图集为{P2, P3, P4, P5},其中P5也是PPM之后的特征图。下采样率分别为{4, 8, 16, 32}。场景标签,即图像级别的最高级属性,由P5的全局平均池化后接线性分类器预测。值得注意的是,与基于扩张网络的框架不同,P5的下采样率相对较大,使得全局平均池化后的特征更专注于高层语义。对于对象标签,实验发现,融合所有FPN特征图比仅使用分辨率最高的特征图(P2)更好。对象部件基于与对象相同的特征图进行分割。对于材质,直观地说,如果知道某个区域属于“杯子”对象,可以合理推测它可能是由纸或塑料制成。这种上下文信息是有用的,但仍然需要局部的明显特征来决定哪个是正确的。还需注意,一个对象可能由多种材质组成。基于上述观察,在P2特征图上进行材质分割。图像级别的纹理标签基于非自然图像。直接将这些非自然图像与其他自然图像融合会损害其他任务。为了实现网络能在像素级别预测纹理标签这一目标,在C2之上添加了几层卷积层,迫使网络在每个像素处预测纹理标签。该分支的梯度不会反向传播到基干网络层,且纹理训练图像被调整为较小的尺寸(约64×64)。这些设计背后的理由是:1)纹理是最底层的感知属性,完全基于明显的特征,不需要任何高层信息。2)在处理其他任务时,预测纹理所需的本质特征被隐式学习。3)该分支的接收场需要足够小,以便在正常尺度的图像输入网络时,网络能够对不同区域预测不同的标签。在其他任务的整个网络训练完成后,仅对纹理分支进行几轮微调。
仅在对象监督下训练,该框架在相同数量的训练周期内,性能几乎与最先进的PSPNet相当,但训练时间只需其的63%。值得注意的是,除了尺度抖动,并未执行PSPNet论文中提到的深度监督或数据增强[16]。
Implementation details
每个分类器前面都配备了一个独立的卷积头。为了融合不同尺度的层,如{P2, P3, P4, P5},通过双线性插值将它们调整到P2的大小,然后将这些层进行拼接。接着,应用一个卷积层来融合来自不同层次的特征,并减少通道维度。所有额外的非分类器卷积层,包括FPN中的层,其输出通道数都设置为512。使用批归一化[34],之后应用ReLU[35]。采用与[36]相同的"poly"学习率策略,当前迭代的学习率等于初始学习率乘以(1 - iter / max_iter)的幂。初始学习率和幂分别设置为0.02和0.9。使用权重衰减0.0001和动量0.9。训练时,输入图像的短边长度随机选择{300, 375, 450, 525, 600}之一。推理时,为了公平比较,不使用多尺度测试,长度设置为450。长边的最大长度设为1200,以防止GPU内存溢出。Backbone网络的层使用在ImageNet[37]上预训练的权重进行初始化。
在每个迭代中,如果一个批次包含来自多个任务和不同来源的图像,由于每个任务的实际批次大小减小,针对特定任务的梯度可能变得嘈杂。因此,根据每个来源的规模,每次迭代随机选择一个数据源,并仅更新用于预测选定源相关概念的路径。
对于对象和材质,不在未标记区域计算损失。对于部分,将背景视为有效标签。此外,部分损失仅应用在其超对象区域。
由于物理内存限制,每个GPU上的批次仅包含2张图像。采用8个GPU之间的同步SGD训练。值得注意的是,对于分类[38]、语义分割[16]和对象检测[39]等任务,批次大小已被证明对生成准确统计至关重要。实现的批归一化能够跨多个GPU同步。训练过程中,不固定任何批归一化层。仅ADE20k(约20k张图像)的训练迭代次数为100k次。如果在更大的数据集上训练,将基于数据集中图像的数量线性增加训练迭代次数。
(Design discussion)
为了实现高分辨率的语义分割预测,膨胀卷积[14]被提出,这是一种移除卷积层步长并在每个卷积滤波器位置之间添加空洞的技术,以缓解下采样带来的副作用,同时保持感受野的扩展率。膨胀网络已经成为语义分割的主流方法。
然而,作者认为这种框架对于提出的统一感知解析任务存在重大局限。首先,近年来在图像分类和语义分割等任务上取得成功的深度卷积神经网络(如[1,40]),通常包含数十或数百层。这些深度CNN设计得非常复杂,目的是在网络的早期阶段为了获得更大的感受野和更轻的计算负担,快速增加下采样率。然而,这种设计对于统一感知解析来说并不理想,因为统一解析需要对图像中的多种视觉概念进行精细的识别和区分,而过快的下采样可能导致关键细节的丢失,影响对复杂视觉概念的解析能力。因此,作者主张需要重新考虑网络架构,以适应统一感知解析任务的需求。
例如,在总共有100个卷积层的ResNet中,Res-4和Res-5块的组合中共有78个卷积层,它们的下采样率分别为16和32。在实践中,为了在保持所有特征图的最大下采样率不超过8的情况下,使用了扩张卷积。然而,由于这两个块中的特征图被放大了4或16倍,这显著增加了计算复杂度和GPU内存占用。第二个缺点是,这种框架仅利用网络中的最深特征图。先前的研究[41]表明,网络中的特征具有层次性:**较低层倾向于捕捉局部特征,如角落或边缘/颜色的结合,而较高层则倾向于捕捉更复杂的模式,如物体的部分。**对于分割高层次概念,如物体,使用具有最高级语义的特征可能是合理的。但对于多级感知属性,特别是低级的如纹理和材质,这自然不合适。接下来,将展示UPerNet在效率和效果上的优势。
五、实验
第一节介绍对提出的框架在原始语义分割任务和统一感知解析任务(UPP任务)上的定量研究。接着,第二节将该框架应用于发掘场景理解背后的视觉常识知识。
Main results
整体架构。为了展示提出的架构在语义分割任务中的有效性,在Table 2中报告了使用ADE20K上的对象注释在不同设置下的训练结果。通常情况下,FPN展现出竞争性的性能,同时对语义分割的需求却少得多的计算资源。仅使用一次16倍下采样的特征图(P4),它达到了mIoU和P.A.的34.46/76.04,这几乎与[16]中报告的强基线相当,而且在相同的迭代次数下,训练时间大约只有1/3。当分辨率提高时,性能进一步提升。添加金字塔池化模块(PPM)后,性能提高了4.87/3.09,这表明FPN也受到不足感受野的影响。经验性地发现,融合来自FPN所有层次的特征能带来最佳性能,这与[43]中的观察结果一致。

考虑到FPN的简单性,仅通过双线性插值对特征图进行上采样,而不是耗时的反卷积,以及通过 1 × 1 1 \times 1 1×1卷积层和元素级相加融合上下路径,而无需复杂的细化模块,保证效率,因此,我们选择这种设计用于统一感知解析。
异质注释的多任务学习。分别报告了融合不同注释集的训练结果。对象解析的基线模型是在ADE20K和Pascal-Context上训练的,其mIoU和P.A.为24.72/78.03。与ADE20K的结果相比,这个结果相对较低,因为Broden+包含更多的对象类别。材料解析的基线模型是在OpenSurfaces上训练的,其mIoU和P.A.为OpenSurfaces。这归因于对象信息作为材料解析的先验的有用性。如上所述,发现直接将纹理图像与自然图像融合对其他任务有害,因为DTD中的纹理图像与自然图像之间存在显著差异。通过使用包含所有其他任务的模型在纹理图像上进行微调,可以通过选择最频繁的像素级预测作为图像级预测来获得定量的纹理分类结果,其准确率为35.10。在纹理上的性能表明,仅对纹理标签进行网络微调并不理想。然而,这是克服自然和合成数据源融合的必要步骤。
定性结果。在Figure 5中展示了UPerNet的定性结果。UPerNet能够统一复合视觉知识,并同时高效地预测分层输出。

Discovering visual knowledge in natural scenes
统一感知解析需要模型能够从给定图像中识别出尽可能多的视觉概念。如果模型成功实现这一目标,它将能够揭示现实世界中丰富的视觉知识,例如回答“客厅和卧室之间的共同点是什么?”或“杯子是由什么材料制成的?”在自然场景中发现或甚至推理视觉知识将使未来的视觉系统更好地理解其环境。
本节展示在Broden+数据集上训练的框架能够发现多级的组成视觉知识。这也是在异质数据标注上训练的网络的特殊应用。使用包含36,500张来自365个场景图像的Places-365验证集作为测试平台,因为Places数据集包含来自各种场景的图像,更接近现实世界。定义了几种层次关系,包括场景-对象关系、对象-部分关系、对象-材料关系、部分-材料关系和材料-纹理关系。请注意,只有对象-部分关系可以直接从ground-truth注解中读出,其他类型的关系只能从网络预测中提取。
Scene-object relations. 场景-对象关系。对每个场景计算出现的物体数量,除以该场景的频率。根据[44],将关系定义为由场景节点 V = V S ∪ V o V = V_{S} ∪ V_{o} V=VS∪Vo以及边 E E E构成的二分图 G = ( V , E ) G = (V, E) G=(V,E)。从 v s v_{s} vs 到 v o v_{o} vo的带权重的边表示物体 v o v_{o} vo 在场景 v s v_{s} vs 中出现的百分比概率。两个节点都来自 V s V_{s} Vs 或 V o V_{o} Vo 的情况下没有边相连。过滤掉权重低于阈值的边,并运行聚类算法以形成更好的布局。由于空间限制,仅展示几十个节点,并在图6(a)中可视化。可以清楚地看到,室内场景大多共享天花板、地板、椅子或窗户等物体,而室外场景则主要共享天空、树木、建筑物或山脉等。更有趣的是,即使在场景集中,人造和自然场景也会被分为不同的组。在布局中,还能找到出现在多个场景中的常见物体,或者找到特定场景中的物体。图6(a)的左下角和右下角图片展示了例子,可以合理地推断出架子通常出现在商店、商店和洗衣房中;而在停机坪上,通常会有树木、围栏、跑道、人,当然还有飞机。

Object(part)-material relations. 对象(部分)-材料关系。除了场景-对象关系,还能发现对象-材料关系。得益于我们的能力,我们能够通过预测每个像素的物体和材料标签,通过计算每个像素中每种材料在每个物体中所占的百分比,直接将物体与其关联的材料对齐变得简单。类似地,构建二分图并展示其可视化结果,如图6(b)的左边所示。利用这个图,可以推断出一些水槽是陶瓷的,而另一些是金属的;不同的地板有不同的材料,如木头、瓷砖或地毯。天花板和墙壁被涂漆;天空也被“涂”上了,更像是一个比喻。然而,也能看到床的大部分是织物而不是木头,这是由于床上实际物体造成的偏差。直观地说,物体部分的材料通常更单调。在图6(b)的中间部分展示了部分-材料的可视化。
Material-texture relations.材料-纹理关系。一种材料可能具有多种纹理。然而,材料的视觉描述是什么?在图6(b)的右侧展示了材料-纹理关系的可视化。值得注意的是,尽管纹理标签缺乏像素级注释,仍然能够生成一个合理的关联图。例如,地毯可以描述为绒毛状、斑驳、污渍、交叉网格和有纹理的。

表4进一步展示了UPerNet发现的一些视觉知识。对于场景-对象关系,选择在场景中出现频率至少达到30%的物体。对于对象-材料、部分-材料和材料-纹理关系,选择最多前3个候选,通过阈值过滤,并对频率进行归一化。能够发现构成每个场景的常见物体,以及每个物体或部分由何种材料构成的程度。UPerNet提取和总结的视觉知识与人类知识相一致。这个知识库提供了跨越各种概念类型丰富信息。期望这样的知识库能为未来的智能代理理解不同场景提供启示,最终理解真实世界。
六、总结
本研究探讨了统一感知解析(Unified Perceptual Parsing)任务,目标是解析图像中的视觉概念,涵盖场景类别、物体、部分、材质和纹理等多个层次。作者设计了一种多任务网络架构和处理异质标注的训练策略,并对其进行了基准测试。通过利用训练好的网络,还能够探索场景之间的视觉知识。这项工作展示了如何通过统一的框架处理复杂的视觉理解任务,为深入理解视觉世界并推动相关领域的技术发展提供了新的视角。