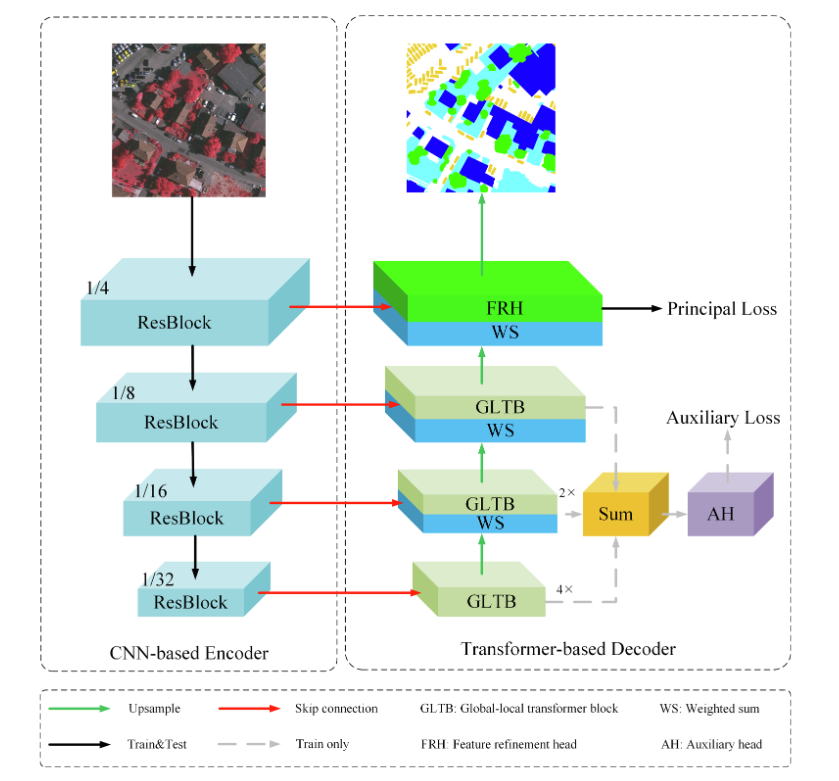
提出了一种参数高效调优方法,称为实例感知视觉提示(IVP)。该方法基于RS图像复杂的背景和高度多变的特征,自适应生成提示信息,仅更新少量参数,将预训练好的RS模型转移到不同的场景分类任务中。具体来说,我们没有调整整个模型参数,而是在输入空间中引入了一些特定于实例的提示向量。然后,考虑到RS图像的显著可变性,我们引入了一个实例级提示生成模块,通过聚合来自输入的上下文信息为每个RS图像生成特定的提示。最后,这些提示向量将校准预训练的特征来编码特定于实例的信息。
我们提出了实例感知视觉提示(instance-aware visual prompt, IVP),这是在遥感场景分类领域首次对提示进行探索。此外,由于RS图像中土地覆盖分布的复杂性,不同类别的场景可能表现出相似的特征,而同一类别内的场景也可能存在显著差异。为所有图像学习特定于任务的固定提示将导致次优性能。我们的方法自适应地为每张RS图像生成特定的提示,并仅更新几个参数,将预训练的RS模型转移到不同的场景分类任务中。
我们的总体框架如图1所示。具体来说,我们在输入空间中引入了一些特定于实例的提示向量。然后,考虑到RS图像的显著可变性,我们引入了一个实例级提示生成模块,称为Meta-Net,通过聚合来自输入的上下文信息为每个RS图像生成特定的提示。最后,这些提示向量将校准预训练的特征来编码特定于实例的信息。

IVP框架概述。在训练阶段,我们冻结骨干网的参数,并根据输入的RS图像自适应生成提示。然后将这些提示与图像和类标记(CLS)一起输入网络,以校准预训练的特征。
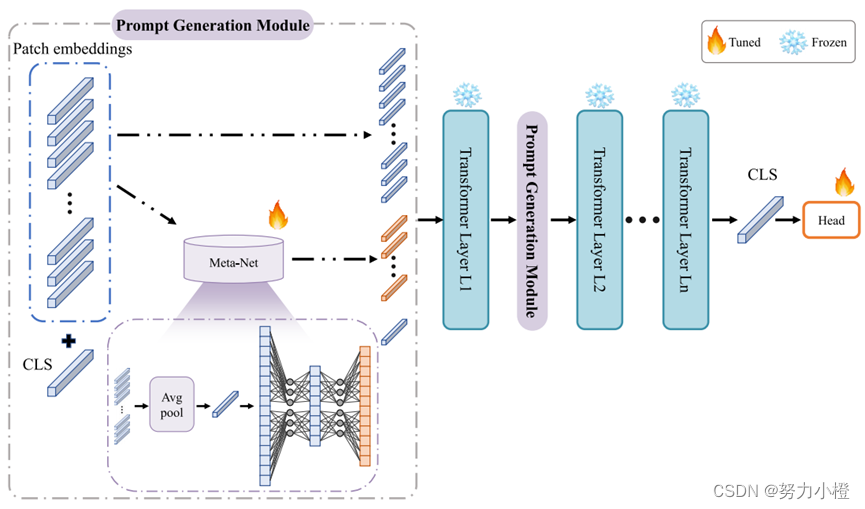
IVP的具体模型体系结构。我们首先使用Meta-Net在每个转换器编码器层生成特定于示例的提示令牌。最后,类令牌、输入上下文令牌和提示令牌作为输入连接到冻结的变压器层。在下游分类任务的训练中,只更新元网和线性头部的参数,而整个变压器编码器保持冻结状态。
图2显示了所提出模型的具体架构。给定一个预训练的ViT模型,我们在嵌入层后的输入空间中引入M个维数为d的连续嵌入,即提示符。我们首先使用特征嵌入模块将输入图像补丁嵌入到几个上下文令牌中,如(1)所示。然后,IVP使用meta网络从输入上下文令牌生成特定于示例的提示令牌。