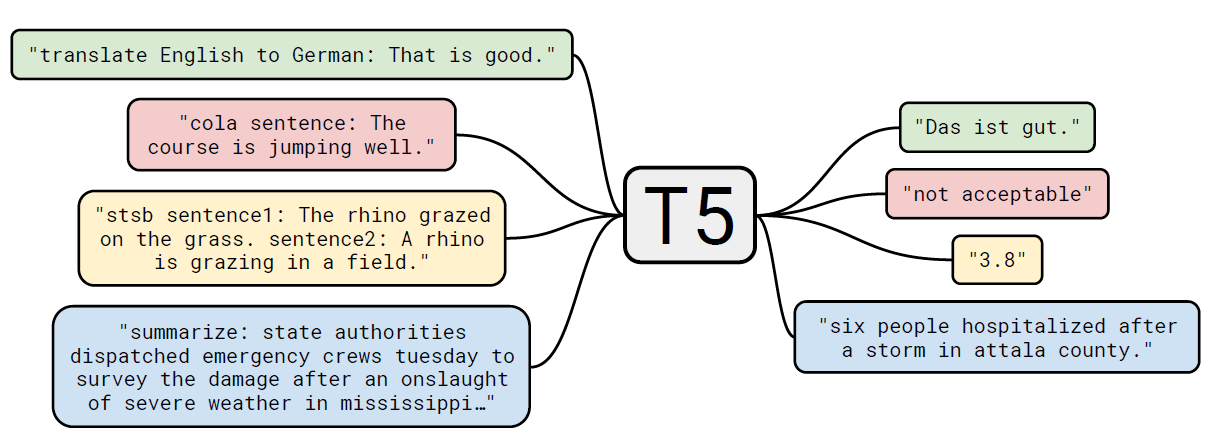
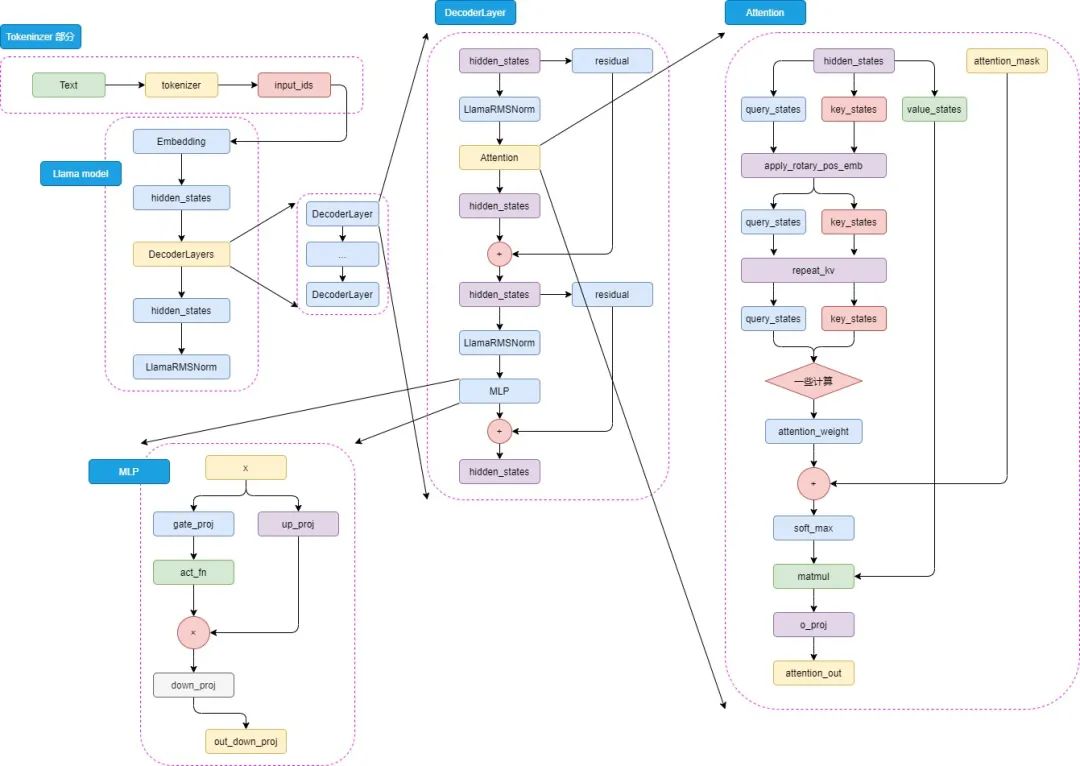
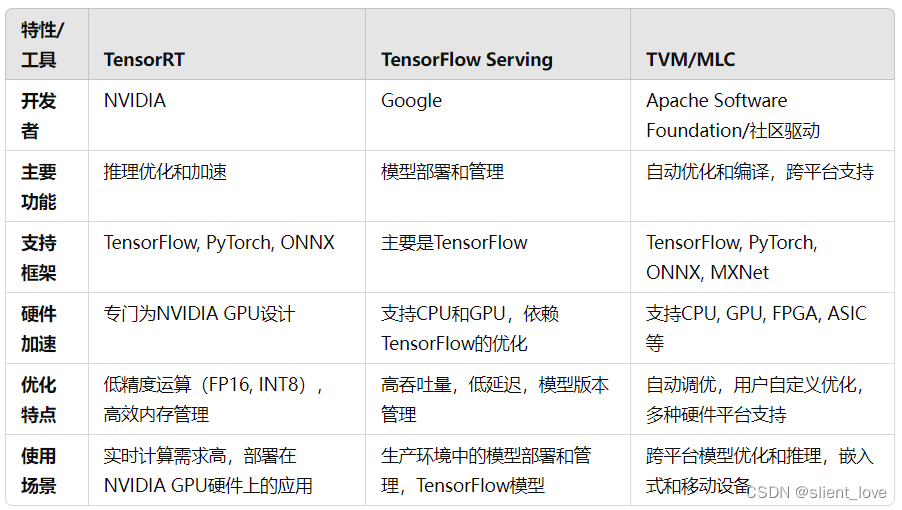
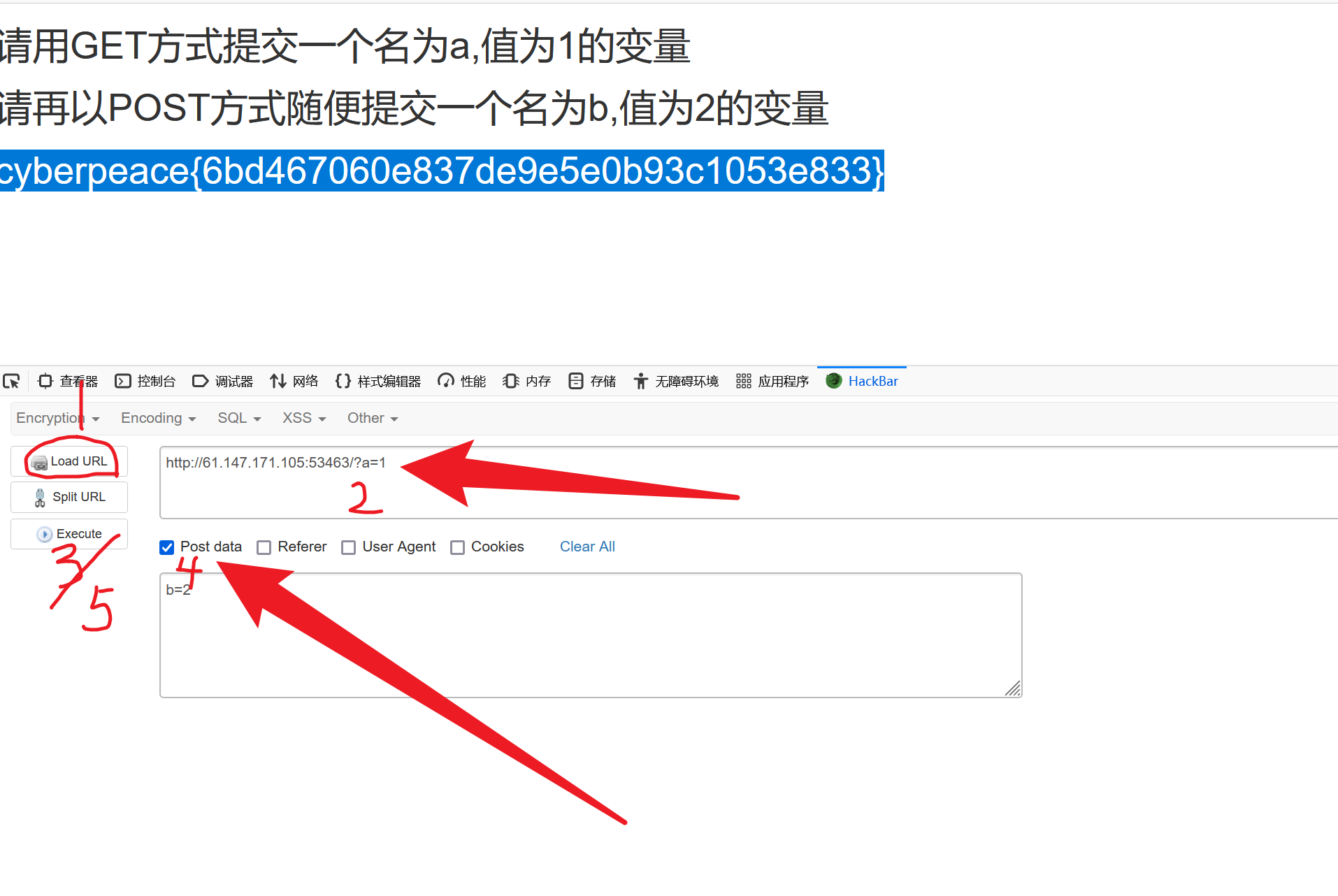
大模型推理时model.generate的源码
文件路径:anaconda3/envs/环境名/lib/python3.10/site-packages/transformers/generation/utils.py
def generate(
self,
inputs: Optional[torch.Tensor] = None,
generation_config: Optional[GenerationConfig] = None,
logits_processor: Optional[LogitsProcessorList] = None,
stopping_criteria: Optional[StoppingCriteriaList] = None,
prefix_allowed_tokens_fn: Optional[Callable[[int, torch.Tensor], List[int]]] = None,
synced_gpus: Optional[bool] = None,
assistant_model: Optional["PreTrainedModel"] = None,
streamer: Optional["BaseStreamer"] = None,
negative_prompt_ids: Optional[torch.Tensor] = None,
negative_prompt_attention_mask: Optional[torch.Tensor] = None,
**kwargs,
) -> Union[GenerateOutput, torch.LongTensor]:
r"""
Generates sequences of token ids for models with a language modeling head.
<Tip warning={true}>
Most generation-controlling parameters are set in `generation_config` which, if not passed, will be set to the
model's default generation configuration. You can override any `generation_config` by passing the corresponding
parameters to generate(), e.g. `.generate(inputs, num_beams=4, do_sample=True)`.
For an overview of generation strategies and code examples, check out the [following
guide](../generation_strategies).
</Tip>
Parameters:
inputs (`torch.Tensor` of varying shape depending on the modality, *optional*):
The sequence used as a prompt for the generation or as model inputs to the encoder. If `None` the
method initializes it with `bos_token_id` and a batch size of 1. For decoder-only models `inputs`
should be in the format of `input_ids`. For encoder-decoder models *inputs* can represent any of
`input_ids`, `input_values`, `input_features`, or `pixel_values`.
generation_config ([`~generation.GenerationConfig`], *optional*):
The generation configuration to be used as base parametrization for the generation call. `**kwargs`
passed to generate matching the attributes of `generation_config` will override them. If
`generation_config` is not provided, the default will be used, which has the following loading
priority: 1) from the `generation_config.json` model file, if it exists; 2) from the model
configuration. Please note that unspecified parameters will inherit [`~generation.GenerationConfig`]'s
default values, whose documentation should be checked to parameterize generation.
logits_processor (`LogitsProcessorList`, *optional*):
Custom logits processors that complement the default logits processors built from arguments and
generation config. If a logit processor is passed that is already created with the arguments or a
generation config an error is thrown. This feature is intended for advanced users.
stopping_criteria (`StoppingCriteriaList`, *optional*):
Custom stopping criteria that complements the default stopping criteria built from arguments and a
generation config. If a stopping criteria is passed that is already created with the arguments or a
generation config an error is thrown. If your stopping criteria depends on the `scores` input, make
sure you pass `return_dict_in_generate=True, output_scores=True` to `generate`. This feature is
intended for advanced users.
prefix_allowed_tokens_fn (`Callable[[int, torch.Tensor], List[int]]`, *optional*):
If provided, this function constraints the beam search to allowed tokens only at each step. If not
provided no constraint is applied. This function takes 2 arguments: the batch ID `batch_id` and
`input_ids`. It has to return a list with the allowed tokens for the next generation step conditioned
on the batch ID `batch_id` and the previously generated tokens `inputs_ids`. This argument is useful
for constrained generation conditioned on the prefix, as described in [Autoregressive Entity
Retrieval](https://arxiv.org/abs/2010.00904).
synced_gpus (`bool`, *optional*):
Whether to continue running the while loop until max_length. Unless overridden this flag will be set to
`True` under DeepSpeed ZeRO Stage 3 multiple GPUs environment to avoid hanging if one GPU finished
generating before other GPUs. Otherwise it'll be set to `False`.
assistant_model (`PreTrainedModel`, *optional*):
An assistant model that can be used to accelerate generation. The assistant model must have the exact
same tokenizer. The acceleration is achieved when forecasting candidate tokens with the assistent model
is much faster than running generation with the model you're calling generate from. As such, the
assistant model should be much smaller.
streamer (`BaseStreamer`, *optional*):
Streamer object that will be used to stream the generated sequences. Generated tokens are passed
through `streamer.put(token_ids)` and the streamer is responsible for any further processing.
negative_prompt_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
The negative prompt needed for some processors such as CFG. The batch size must match the input batch
size. This is an experimental feature, subject to breaking API changes in future versions.
negative_prompt_attention_mask (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
Attention_mask for `negative_prompt_ids`.
kwargs (`Dict[str, Any]`, *optional*):
Ad hoc parametrization of `generation_config` and/or additional model-specific kwargs that will be
forwarded to the `forward` function of the model. If the model is an encoder-decoder model, encoder
specific kwargs should not be prefixed and decoder specific kwargs should be prefixed with *decoder_*.
Return:
[`~utils.ModelOutput`] or `torch.LongTensor`: A [`~utils.ModelOutput`] (if `return_dict_in_generate=True`
or when `config.return_dict_in_generate=True`) or a `torch.LongTensor`.
If the model is *not* an encoder-decoder model (`model.config.is_encoder_decoder=False`), the possible
[`~utils.ModelOutput`] types are:
- [`~generation.GenerateDecoderOnlyOutput`],
- [`~generation.GenerateBeamDecoderOnlyOutput`]
If the model is an encoder-decoder model (`model.config.is_encoder_decoder=True`), the possible
[`~utils.ModelOutput`] types are:
- [`~generation.GenerateEncoderDecoderOutput`],
- [`~generation.GenerateBeamEncoderDecoderOutput`]
"""
# 1. Handle `generation_config` and kwargs that might update it, and validate the `.generate()` call
self._validate_model_class()
tokenizer = kwargs.pop("tokenizer", None) # Pull this out first, we only use it for stopping criteria
generation_config, model_kwargs = self._prepare_generation_config(generation_config, **kwargs)
self._validate_model_kwargs(model_kwargs.copy())
# 2. Set generation parameters if not already defined
if synced_gpus is None:
if is_deepspeed_zero3_enabled() and dist.get_world_size() > 1:
synced_gpus = True
else:
synced_gpus = False
logits_processor = logits_processor if logits_processor is not None else LogitsProcessorList()
stopping_criteria = stopping_criteria if stopping_criteria is not None else StoppingCriteriaList()
accepts_attention_mask = "attention_mask" in set(inspect.signature(self.forward).parameters.keys())
requires_attention_mask = "encoder_outputs" not in model_kwargs
kwargs_has_attention_mask = model_kwargs.get("attention_mask", None) is not None
# 3. Define model inputs
inputs_tensor, model_input_name, model_kwargs = self._prepare_model_inputs(
inputs, generation_config.bos_token_id, model_kwargs
)
batch_size = inputs_tensor.shape[0]
device = inputs_tensor.device
self._prepare_special_tokens(generation_config, kwargs_has_attention_mask, device=device)
# decoder-only models must use left-padding for batched generation.
if not self.config.is_encoder_decoder and not is_torchdynamo_compiling():
# If `input_ids` was given, check if the last id in any sequence is `pad_token_id`
# Note: If using, `inputs_embeds` this check does not work, because we want to be more hands-off.
if (
generation_config.pad_token_id is not None
and batch_size > 1
and len(inputs_tensor.shape) == 2
and torch.sum(inputs_tensor[:, -1] == generation_config.pad_token_id) > 0
):
logger.warning(
"A decoder-only architecture is being used, but right-padding was detected! For correct "
"generation results, please set `padding_side='left'` when initializing the tokenizer."
)
# 4. Define other model kwargs
# decoder-only models with inputs_embeds forwarding must use caching (otherwise we can't detect whether we are
# generating the first new token or not, and we only want to use the embeddings for the first new token)
if not self.config.is_encoder_decoder and model_input_name == "inputs_embeds":
model_kwargs["use_cache"] = True
else:
model_kwargs["use_cache"] = generation_config.use_cache
if not kwargs_has_attention_mask and requires_attention_mask and accepts_attention_mask:
model_kwargs["attention_mask"] = self._prepare_attention_mask_for_generation(
inputs_tensor, generation_config.pad_token_id, generation_config.eos_token_id
)
if self.config.is_encoder_decoder and "encoder_outputs" not in model_kwargs:
# if model is encoder decoder encoder_outputs are created and added to `model_kwargs`
model_kwargs = self._prepare_encoder_decoder_kwargs_for_generation(
inputs_tensor, model_kwargs, model_input_name, generation_config
)
# 5. Prepare `input_ids` which will be used for auto-regressive generation
if self.config.is_encoder_decoder:
input_ids, model_kwargs = self._prepare_decoder_input_ids_for_generation(
batch_size=batch_size,
model_input_name=model_input_name,
model_kwargs=model_kwargs,
decoder_start_token_id=generation_config.decoder_start_token_id,
device=inputs_tensor.device,
)
else:
input_ids = inputs_tensor if model_input_name == "input_ids" else model_kwargs.pop("input_ids")
if streamer is not None:
streamer.put(input_ids.cpu())
# 6. Prepare `max_length` depending on other stopping criteria.
input_ids_length = input_ids.shape[-1]
has_default_max_length = kwargs.get("max_length") is None and generation_config.max_length is not None
has_default_min_length = kwargs.get("min_length") is None and generation_config.min_length is not None
generation_config = self._prepare_generated_length(
generation_config=generation_config,
has_default_max_length=has_default_max_length,
has_default_min_length=has_default_min_length,
model_input_name=model_input_name,
inputs_tensor=inputs_tensor,
input_ids_length=input_ids_length,
)
if generation_config.cache_implementation is not None and model_kwargs.get("past_key_values") is not None:
raise ValueError(
"Passing both `cache_implementation` (used to initialize certain caches) and `past_key_values` (a "
"Cache object) is unsupported. Please use only one of the two."
)
elif generation_config.cache_implementation in NEED_SETUP_CACHE_CLASSES_MAPPING:
if not self._supports_cache_class:
raise ValueError(
"This model does not support the `cache_implementation` argument. Please check the following "
"issue: https://github.com/huggingface/transformers/issues/28981."
)
if generation_config.cache_implementation == "static":
if not self._supports_static_cache:
raise ValueError(
"This model does not support `cache_implementation='static'`. Please check the following "
"issue: https://github.com/huggingface/transformers/issues/28981"
)
model_kwargs["past_key_values"] = self._get_static_cache(batch_size, generation_config.max_length)
self._validate_generated_length(generation_config, input_ids_length, has_default_max_length)
# 7. determine generation mode
generation_mode = generation_config.get_generation_mode(assistant_model)
if streamer is not None and (generation_config.num_beams > 1):
raise ValueError(
"`streamer` cannot be used with beam search (yet!). Make sure that `num_beams` is set to 1."
)
if self.device.type != input_ids.device.type:
warnings.warn(
"You are calling .generate() with the `input_ids` being on a device type different"
f" than your model's device. `input_ids` is on {input_ids.device.type}, whereas the model"
f" is on {self.device.type}. You may experience unexpected behaviors or slower generation."
" Please make sure that you have put `input_ids` to the"
f" correct device by calling for example input_ids = input_ids.to('{self.device.type}') before"
" running `.generate()`.",
UserWarning,
)
# 8. prepare distribution pre_processing samplers
prepared_logits_processor = self._get_logits_processor(
generation_config=generation_config,
input_ids_seq_length=input_ids_length,
encoder_input_ids=inputs_tensor,
prefix_allowed_tokens_fn=prefix_allowed_tokens_fn,
logits_processor=logits_processor,
device=inputs_tensor.device,
model_kwargs=model_kwargs,
negative_prompt_ids=negative_prompt_ids,
negative_prompt_attention_mask=negative_prompt_attention_mask,
)
# 9. prepare stopping criteria
prepared_stopping_criteria = self._get_stopping_criteria(
generation_config=generation_config, stopping_criteria=stopping_criteria, tokenizer=tokenizer, **kwargs
)
# 10. go into different generation modes
if generation_mode == GenerationMode.ASSISTED_GENERATION:
if generation_config.num_return_sequences > 1:
raise ValueError(
"num_return_sequences has to be 1 when doing assisted generate, "
f"but is {generation_config.num_return_sequences}."
)
if batch_size > 1:
raise ValueError("assisted generate is only supported for batch_size = 1")
if not model_kwargs["use_cache"]:
raise ValueError("assisted generate requires `use_cache=True`")
if generation_config.cache_implementation == "static":
raise ValueError("assisted generate is not supported with `static_cache`")
# 11. Get the candidate generator, given the parameterization
candidate_generator = self._get_candidate_generator(
generation_config=generation_config,
input_ids=input_ids,
inputs_tensor=inputs_tensor,
assistant_model=assistant_model,
logits_processor=logits_processor,
model_kwargs=model_kwargs,
)
# 12. prepare logits warper (if `do_sample` is `True`)
prepared_logits_warper = (
self._get_logits_warper(generation_config) if generation_config.do_sample else None
)
# 13. run assisted generate
result = self._assisted_decoding(
input_ids,
candidate_generator=candidate_generator,
logits_processor=prepared_logits_processor,
logits_warper=prepared_logits_warper,
stopping_criteria=prepared_stopping_criteria,
generation_config=generation_config,
synced_gpus=synced_gpus,
streamer=streamer,
**model_kwargs,
)
elif generation_mode == GenerationMode.CONTRASTIVE_SEARCH:
if not model_kwargs["use_cache"]:
raise ValueError("Contrastive search requires `use_cache=True`")
result = self._contrastive_search(
input_ids,
logits_processor=prepared_logits_processor,
stopping_criteria=prepared_stopping_criteria,
generation_config=generation_config,
synced_gpus=synced_gpus,
streamer=streamer,
**model_kwargs,
)
elif generation_mode in (GenerationMode.SAMPLE, GenerationMode.GREEDY_SEARCH):
# 11. prepare logits warper
prepared_logits_warper = (
self._get_logits_warper(generation_config) if generation_config.do_sample else None
)
# 12. expand input_ids with `num_return_sequences` additional sequences per batch
input_ids, model_kwargs = self._expand_inputs_for_generation(
input_ids=input_ids,
expand_size=generation_config.num_return_sequences,
is_encoder_decoder=self.config.is_encoder_decoder,
**model_kwargs,
)
# 13. run sample (it degenerates to greedy search when `generation_config.do_sample=False`)
result = self._sample(
input_ids,
logits_processor=prepared_logits_processor,
logits_warper=prepared_logits_warper,
stopping_criteria=prepared_stopping_criteria,
generation_config=generation_config,
synced_gpus=synced_gpus,
streamer=streamer,
**model_kwargs,
)
elif generation_mode in (GenerationMode.BEAM_SAMPLE, GenerationMode.BEAM_SEARCH):
# 11. prepare logits warper
prepared_logits_warper = (
self._get_logits_warper(generation_config) if generation_config.do_sample else None
)
# 12. prepare beam search scorer
beam_scorer = BeamSearchScorer(
batch_size=batch_size,
num_beams=generation_config.num_beams,
device=inputs_tensor.device,
length_penalty=generation_config.length_penalty,
do_early_stopping=generation_config.early_stopping,
num_beam_hyps_to_keep=generation_config.num_return_sequences,
max_length=generation_config.max_length,
)
# 13. interleave input_ids with `num_beams` additional sequences per batch
input_ids, model_kwargs = self._expand_inputs_for_generation(
input_ids=input_ids,
expand_size=generation_config.num_beams,
is_encoder_decoder=self.config.is_encoder_decoder,
**model_kwargs,
)
# 14. run beam sample
result = self._beam_search(
input_ids,
beam_scorer,
logits_processor=prepared_logits_processor,
logits_warper=prepared_logits_warper,
stopping_criteria=prepared_stopping_criteria,
generation_config=generation_config,
synced_gpus=synced_gpus,
**model_kwargs,
)
elif generation_mode == GenerationMode.GROUP_BEAM_SEARCH:
# 11. prepare beam search scorer
beam_scorer = BeamSearchScorer(
batch_size=batch_size,
num_beams=generation_config.num_beams,
device=inputs_tensor.device,
length_penalty=generation_config.length_penalty,
do_early_stopping=generation_config.early_stopping,
num_beam_hyps_to_keep=generation_config.num_return_sequences,
num_beam_groups=generation_config.num_beam_groups,
max_length=generation_config.max_length,
)
# 12. interleave input_ids with `num_beams` additional sequences per batch
input_ids, model_kwargs = self._expand_inputs_for_generation(
input_ids=input_ids,
expand_size=generation_config.num_beams,
is_encoder_decoder=self.config.is_encoder_decoder,
**model_kwargs,
)
# 13. run beam search
result = self._group_beam_search(
input_ids,
beam_scorer,
logits_processor=prepared_logits_processor,
stopping_criteria=prepared_stopping_criteria,
generation_config=generation_config,
synced_gpus=synced_gpus,
**model_kwargs,
)
elif generation_mode == GenerationMode.CONSTRAINED_BEAM_SEARCH:
final_constraints = []
if generation_config.constraints is not None:
final_constraints = generation_config.constraints
if generation_config.force_words_ids is not None:
def typeerror():
raise ValueError(
"`force_words_ids` has to either be a `List[List[List[int]]]` or `List[List[int]]` "
f"of positive integers, but is {generation_config.force_words_ids}."
)
if (
not isinstance(generation_config.force_words_ids, list)
or len(generation_config.force_words_ids) == 0
):
typeerror()
for word_ids in generation_config.force_words_ids:
if isinstance(word_ids[0], list):
if not isinstance(word_ids, list) or len(word_ids) == 0:
typeerror()
if any(not isinstance(token_ids, list) for token_ids in word_ids):
typeerror()
if any(
any((not isinstance(token_id, int) or token_id < 0) for token_id in token_ids)
for token_ids in word_ids
):
typeerror()
constraint = DisjunctiveConstraint(word_ids)
else:
if not isinstance(word_ids, list) or len(word_ids) == 0:
typeerror()
if any((not isinstance(token_id, int) or token_id < 0) for token_id in word_ids):
typeerror()
constraint = PhrasalConstraint(word_ids)
final_constraints.append(constraint)
# 11. prepare beam search scorer
constrained_beam_scorer = ConstrainedBeamSearchScorer(
constraints=final_constraints,
batch_size=batch_size,
num_beams=generation_config.num_beams,
device=inputs_tensor.device,
length_penalty=generation_config.length_penalty,
do_early_stopping=generation_config.early_stopping,
num_beam_hyps_to_keep=generation_config.num_return_sequences,
max_length=generation_config.max_length,
)
# 12. interleave input_ids with `num_beams` additional sequences per batch
input_ids, model_kwargs = self._expand_inputs_for_generation(
input_ids=input_ids,
expand_size=generation_config.num_beams,
is_encoder_decoder=self.config.is_encoder_decoder,
**model_kwargs,
)
# 13. run beam search
result = self._constrained_beam_search(
input_ids,
constrained_beam_scorer=constrained_beam_scorer,
logits_processor=prepared_logits_processor,
stopping_criteria=prepared_stopping_criteria,
generation_config=generation_config,
synced_gpus=synced_gpus,
**model_kwargs,
)
return result