前言
在构建高效的自然语言处理模型时,Embedding层是不可或缺的组成部分。它不仅可以帮助我们捕获词汇之间的语义关系,还能提高模型的性能。在本篇博客中,我们将详细介绍Embedding层的基本原理、使用方法以及它在深度学习框架中的实现,帮助你更好地理解和应用这一技术。
一、为什么要引入Embedding层
你是否曾经遇到过这样的问题:在处理大量文本数据时,如何有效地表示词汇或短语?传统的独热编码(One-Hot Encoding)方法存在哪些局限性?Embedding层又是如何解决这些问题的?接下来,我们将一起探讨Embedding层的工作原理及其在自然语言处理中的应用。
传统的onehot编码的局限性在于:
1.维度过高且稀疏:当词库(或特征集合)很大时,独热编码会生成一个维度极高的向量,其中大部分元素为0,只有对应特征位置的元素为1。这种高维且稀疏的表示方式不仅占用大量的存储空间,而且在后续的计算中会导致计算成本显著增加。
2.丢失了单词间的语义关系:独热编码仅根据单词在词库中的索引位置进行编码,没有考虑到单词之间的语义关系。
3.对词汇数量的敏感度:独热编码的维度与词库的大小直接相关。如果词库中的单词数量增加,那么编码的维度也会相应增加,这会导致上述的维度过高和稀疏性问题进一步加剧。
4.无法处理未知单词:如果在测试或应用阶段遇到了一个训练阶段中未曾出现过的单词(即未知单词),那么独热编码将无法为其生成一个有效的表示向量,因为该单词在词库中没有对应的索引位置。
随着语料库越来越大,在处理大规模这些文本数据或需要捕捉单词间语义关系时,one hot编码的局限性变得尤为突出。为了克服这些局限性,人们发展出了如词嵌入 等更先进的文本表示方法。
而且,在大语言模型盛行的今天,Embedding层仍然是不可或缺的一部分,它在表示文本内容、增强模型性能以及解决长文本输入问题等方面发挥着重要作用。
二、Embedding层是怎么发挥作用的?
在这里我以经典的Word2Vec为例子。简单介绍一下Word2Vec,它是一个将单词表示为向量的的词向量学习方法。有两种实现方式,分别是CBOW和Skip-Gram模型。
方便起见,这里以CBOW举例子了。他的思想是这样的:给出目标单词周围的词,预测目标单词。就比如一句话原本的语句是“我爱你”,后来把“爱”遮住,使用CBOW预测出“我”和“你”之间的单词是什么。

网络结构如图所示:(输入下面的两个方块是周围单词,映射下面的方块是低维、稠密的词向量表示,输出下面的方块表示用softmax得出的得分)
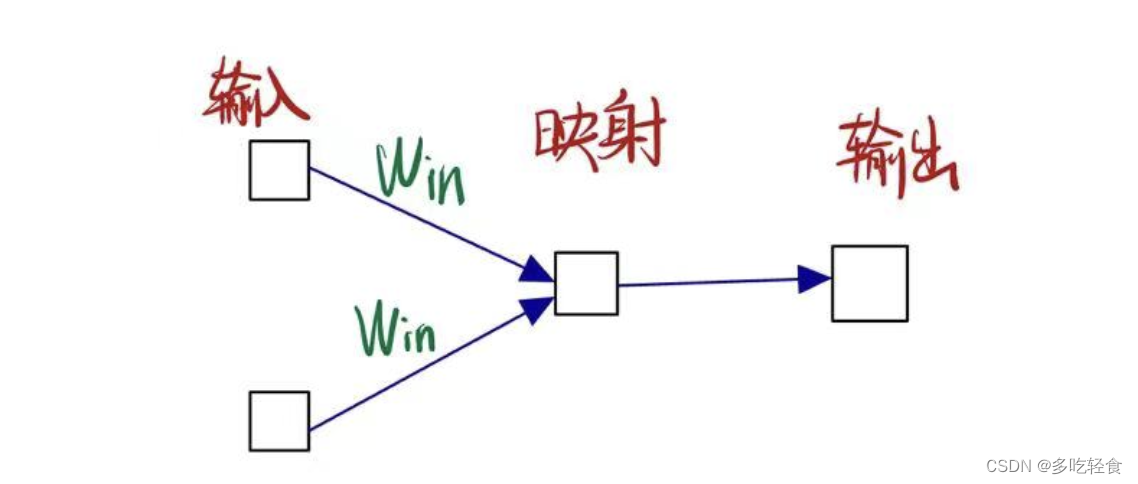
CBOW做的是输入矩阵(即周围单词的矩阵表示)与一个输入单词权重矩阵 W i n W_{in} Win(也称嵌入矩阵)做矩阵相乘。这样就把输入变成了低维稠密的单词向量的形式,然后把这个单词向量表示进行softmax输出,取概率最大的单词。
本文章是为了介绍Embedding层,简单起见,所以我们聚焦于一个其中一个周围单词和 W i n W_{in} Win矩阵乘积的情况。
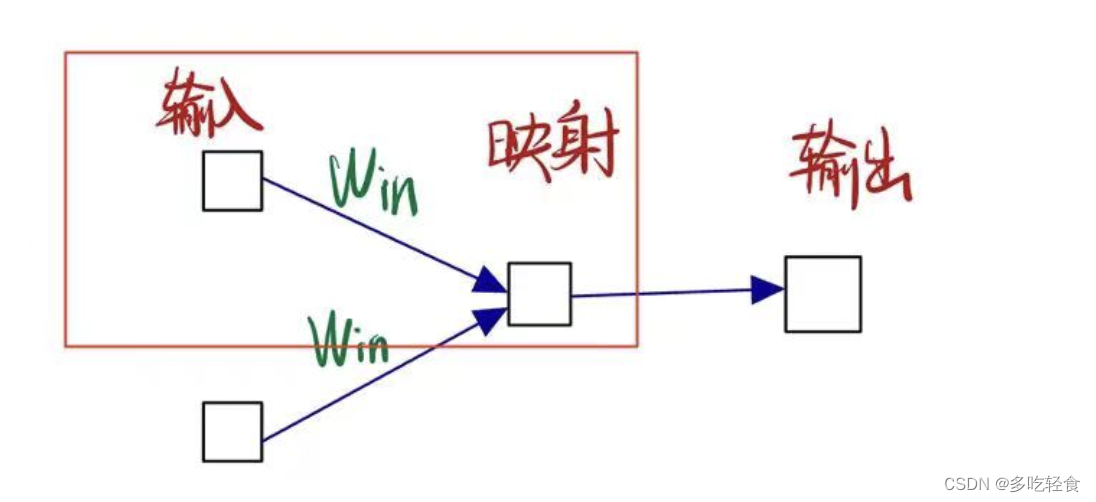
如果单词的输入矩阵用one hot向量表示。我们那么这个过程就变成了一下情况
输入单词向量形状是1 * 1000000, W i n W_{in} Win的形状是1000000 * 100,最终得到 1 * 100的低纬稠密向量。
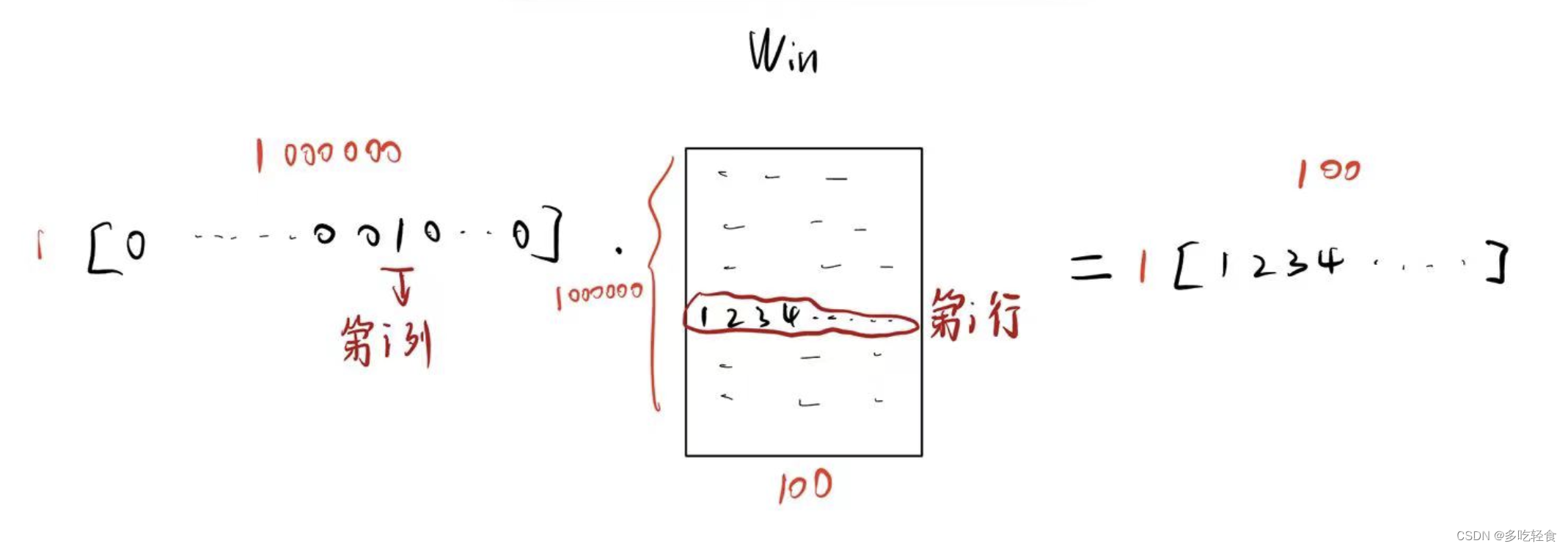
这个过程有一个问题,矩阵相乘的时间复杂度是1 * 1000000 * 100 = 100000000。这个过程需要这么大的计算量。
但是,如果仔细观察的话,我们做的知识把第i行的元素提取出来而已。
为了解决这个问题,我们引入Embedding层,做的就是把 W i n W_{in} Win的某一行提取出来。
- Embedding层的作用:一个 可以抽取单词id对应的行(向量) 的层。
- 还有一个说法也比较贴切,Embedding是一个简单的查找表。
三、感受Embedding的强大
引入Embedding层之后,这样问题就简单了。
考虑更复杂的一种情况,输入是100 * 1000000(输入100个单词,用每个单词用1000000维onehot表示)的情况,要把它压缩成100 * 100的矩阵。
原本的计算是这样的。

计算量是100 * 1000000 * 1000000=100000000000000。看数字可能感觉不够明显,翻译成中文就是10万亿。更何况语料库更加庞大的今天,可以说如果使用传统方法计算量简直是天文数字,根本不可以实现。
但是如今有了Embedding的方法,就简单多了。
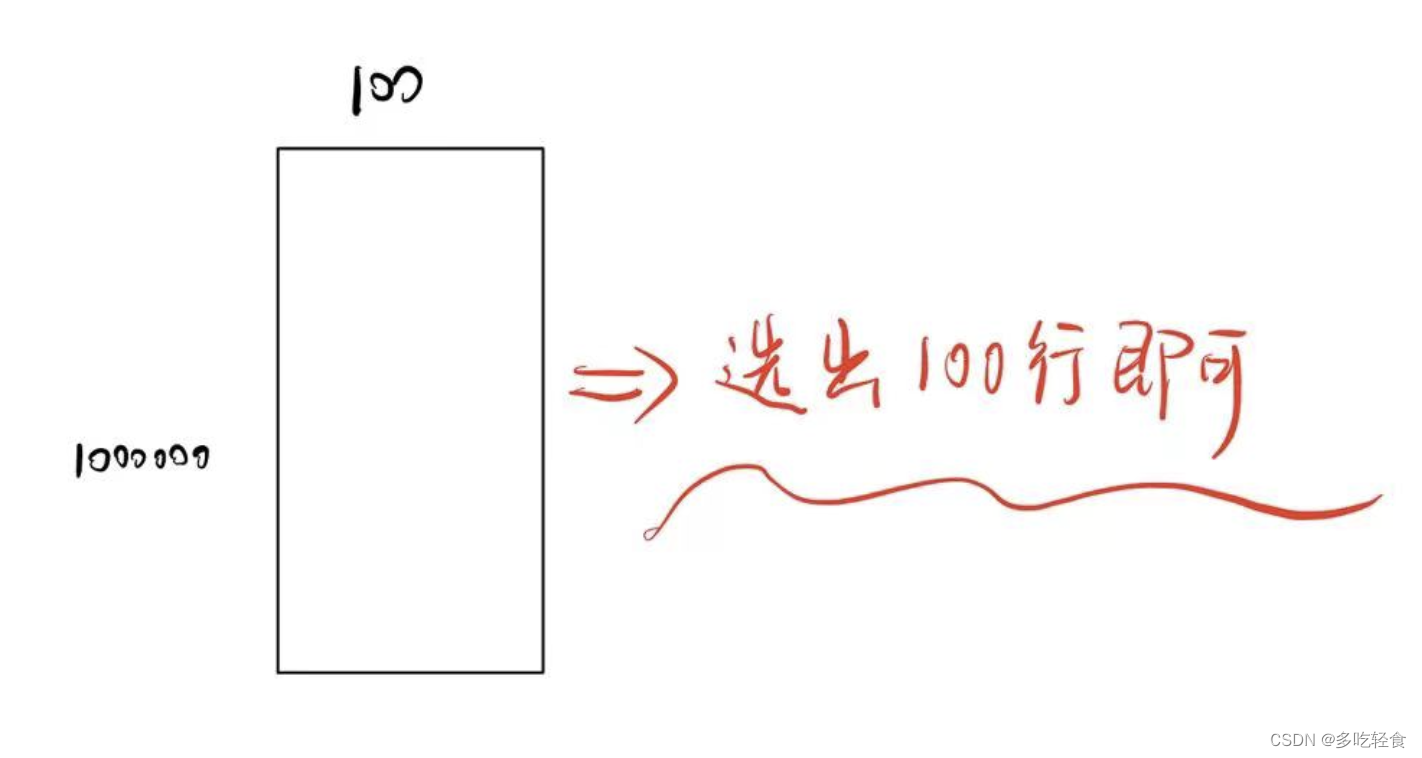
我们要做的无非就是根据单词对应的序号从 W i n W_in Win中选出100行而已。
计算量=100 * 100 = 10000。(第一个100是输入的单词数,第二个100是 W i n W_{in} Win的100的纬度)
这样就把一个上面不可能解决的问题变成了一个很简单的取数问题。
简直爽爆了!
四、为什么理解Embedding的底层原理?
现如今,深度学习的框架十分方便,只要输入文本对应的整数索引(也称为类别索引或token索引),使用nn.Embedding(input),自动就转化成了想要的token(分词或单词)的低纬稠密表示。
但是我们不能知其然不知其所以然。虽然框架很方便,实际工作中光会调用接口是远远不够的。
了解Embedding的底层原理有助于你更深入地理解模型是如何工作的,在某些情况下,你可能需要自定义Embedding层的实现,以适应特定的任务或数据,从而进一步提高模型的运行效率。
总之,尽管深度学习框架提供了方便的接口来实现Embedding层,但学习其底层原理仍然是非常重要的。这不仅可以帮助你更好地理解模型的工作原理,还可以提高你的技术能力和创新能力
总结
在本文中,我们深入探讨了Embedding层的底层实现。我们了解到Embedding层在深度学习中扮演着将离散索引映射为连续向量空间的重要角色,
通过对Embedding层底层实现的解析,我们不难发现其高效性和灵活性的关键。使用嵌入矩阵作为查找表,Embedding层能够快速地根据索引返回对应的嵌入向量,而无需进行复杂的计算。同时,嵌入向量的维度可以根据任务需求进行灵活调整,以适应不同的应用场景。
最后,我想强调的是,Embedding层只是深度学习中的一个组成部分,它的作用和价值需要与其他网络层相结合才能充分发挥。因此,在学习和使用Embedding层时,我们需要深入理解其背后的原理和实现细节,并结合具体任务和数据集进行实践和调整。






















![[数据集][目标检测]厨房积水检测数据集VOC+YOLO格式88张2类别](https://img-blog.csdnimg.cn/direct/c4e49eab8a6747f38b241b8c4423ab14.png)