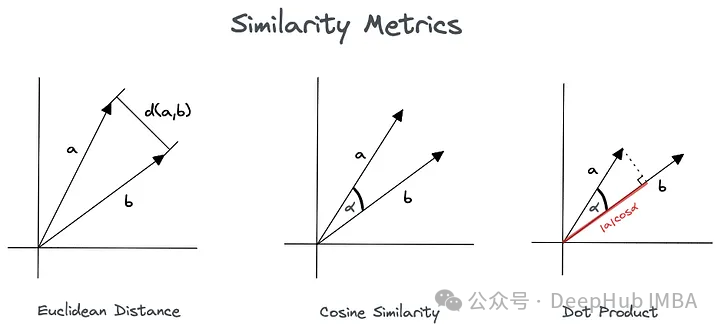
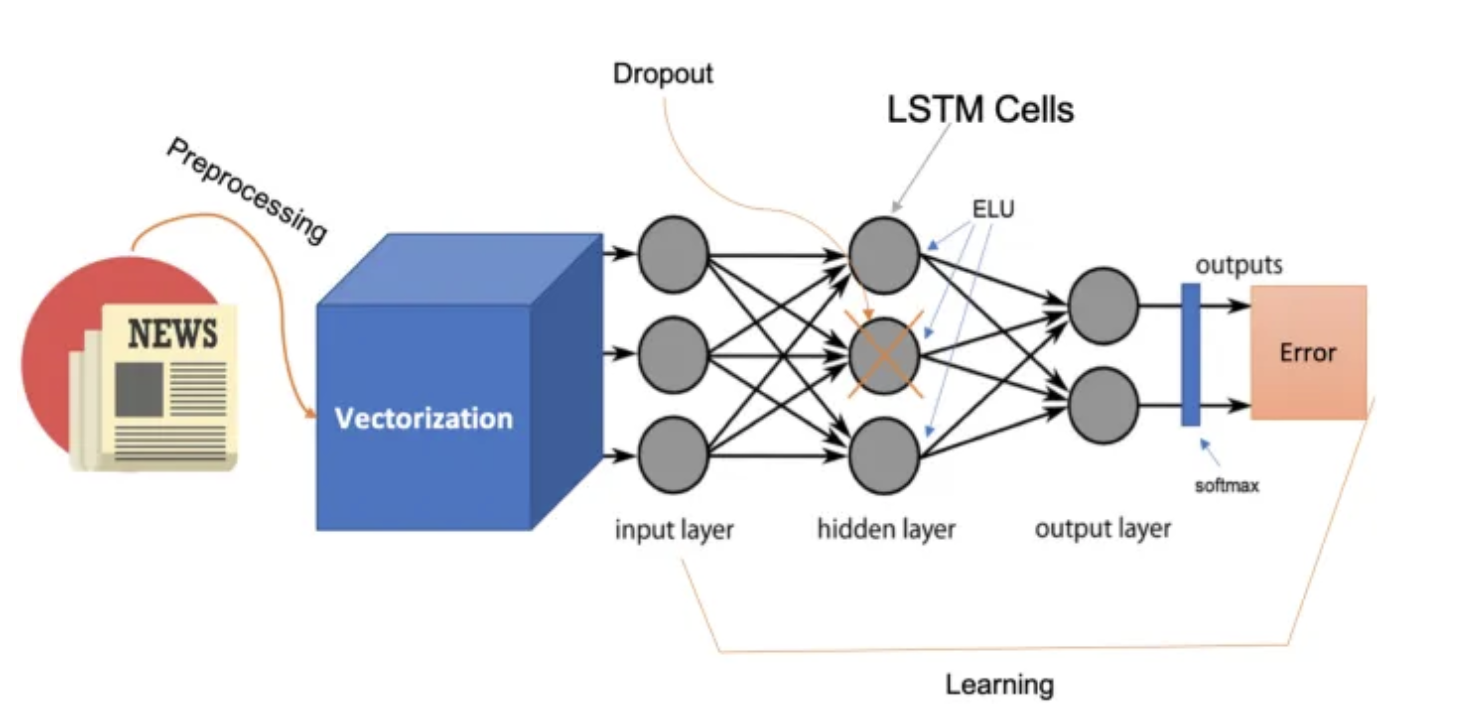
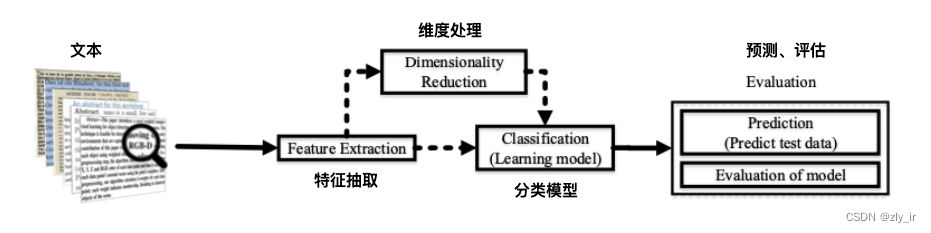
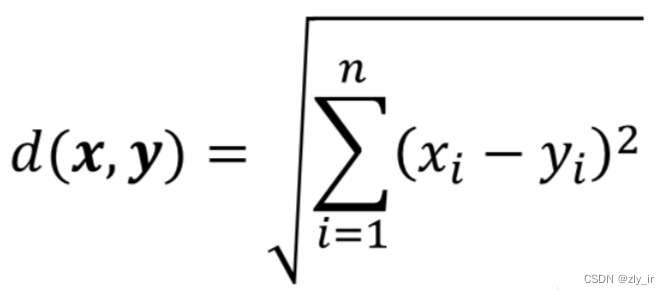在自然语言处理(NLP)中,嵌入层(Embedding Layer)是一个特殊的层,通常用于深度学习模型的第一层,它的作用是将离散的文本数据(如单词或短语)转换为连续的向量表示。每个单词或短语被映射到固定大小的密集向量中。嵌入层基本上是一个查找表,模型通过查找表中对应的单词索引来获取单词的向量表示。
嵌入层的关键点包括:
词汇表映射:嵌入层有一个预定义大小的词汇表,每个词都与一个唯一的索引相关联。输入文本中的词汇将被转换为这些索引。
维度降低:原始文本数据通常是高维的(例如,使用独热编码的单词),而嵌入层将这些高维的表示转换为低维、密集和连续的向量。这些向量通常更小、更易于模型处理,并能捕捉单词之间的语义关系。
参数学习:嵌入层的权重(即词向量)通常在模型训练过程中学习得到,尽管也可以使用预训练的词向量(如GloVe或Word2Vec)进行初始化。这些向量随着模型的训练不断调整,以更好地表示词汇之间的关系。
改善效率和表达力:使用嵌入层不仅可以减少模型的计算负担(相比于直接使用独热编码的高维表示),还可以增强模型对词汇的理解,包括语义相似性和词汇间的关系。
应用场景:
嵌入层广泛应用于各种NLP任务中,如文本分类、情感分析、机器翻译、问答系统等。通过使用嵌入层,模型能够更有效地处理自然语言,并捕捉词汇的深层语义特征。
总之,嵌入层是NLP中的一种基础技术,通过将单词转换为向量,使得文本数据能够被深度学习模型更有效地处理。这些向量不仅减少了数据的维度,还能在一定程度上捕捉和表示单词之间复杂的关系和语义。
要使用预训练的BERT模型将文本序列转化为词向量表示,
首先,确保你已经安装了transformers和torch这两个库。如果没有,可以使用pip install transformers torch来安装它们。
以下是一个简单的代码示例,展示了如何使用BERT模型来获取文本序列的词向量表示:
- 导入所需的库。
- 加载预训练的BERT模型和对应的分词器。
- 使用分词器处理文本,将文本转化为模型所需的格式。
- 将处理后的文本输入到BERT模型中,获取词向量表示。
from transformers import BertTokenizer, BertModel import torch # 1. 初始化分词器和模型 tokenizer = BertTokenizer.from_pretrained('bert-base-uncased') model = BertModel.from_pretrained('bert-base-uncased') # 2. 要处理的文本 text = "Here is some text to encode" # 3. 使用分词器预处理文本 encoded_input = tokenizer(text, return_tensors='pt') # 4. 获取词向量表示 with torch.no_grad(): output = model(**encoded_input) # 词向量表示存储在`output`中,可以根据需要进行进一步处理 word_embeddings = output.last_hidden_state print(word_embeddings)在这个例子中,
word_embeddings将包含输入文本序列的词向量表示。每个词在BERT模型中被映射为一个向量,这些向量可以用于各种下游任务,例如文本分类、情感分析等。注意:BERT模型对输入文本长度有限制,通常为512个词汇单元。因此,对于长文本,可能需要进行适当的截断或分段处理。