🌞欢迎来到Python 的世界
🌈博客主页:卿云阁💌欢迎关注🎉点赞👍收藏⭐️留言📝
🌟本文由卿云阁原创!
📆首发时间:🌹2024年6月9日🌹
✉️希望可以和大家一起完成进阶之路!
🙏作者水平很有限,如果发现错误,请留言轰炸哦!万分感谢!
目录

文件定位
文件标识

文件路径
文件路径可以分为两种,绝对路径和相对路径,绝对路径是从根目录出发的路径。相对路径是从参考位置出发,其它文件处于什么路径。用.表示当前文件所在的目录,用..表示更上以及的父目录。同一目录下的文件,想用相对路径找到彼此的话,可以直接使用文件名。

文件操作
打开文件
f=open(file='C:/Users/Administrator/Desktop/zz.txt',mode='w',encoding='utf-8') 
追加模式
f=open(file='C:/Users/Administrator/Desktop/zz.txt',mode='a')
f.write("zz 202018085\n")
f.close() #保存并关闭关闭文件
f.close() #保存并关闭写文件

file.write(s)
f=open(file='C:/Users/Administrator/Desktop/zz.txt',mode='w') #在文件夹中复制地址时,文件夹中的地址是用 \ 来分隔不同文件夹的,而Python识别地址时只能识别用 / 分隔的地址。
f.write("我叫卿云\n") #写文件
f.write("我喜欢打乒乓球\n") #写文件
f.close() #保存并关闭
file.writelines(s)
file=open('example.txt','w',encoding='utf-8')
# 写入多行内容
lines = ["Line 1\n", "Line 2\n", "Line 3\n"]
file.writelines(lines)
读文件

f=open(file='C:/Users/Administrator/Desktop/zz.txt',mode='r')
print(f.readline())#读一行
print('-----分隔符-----')
data=f.read()
print(data)
f.close() #保存并关闭
结果
卿云 202018081
-----分隔符-----
文竹 202018082
循环文件
f = open(file='C:/Users/qingyun/Desktop/兼职⽩领学⽣空姐模特护⼠联系⽅式.txt',encoding="utf-8",mode='r')
for line in f:
line = line.split()
name,addr,height,weight,phone = line
height = int(height)
weight = int(weight)
if height > 170 and weight <= 50: # 只打印身⾼>170 and 体᯿<=50的
print(line)
f.close()
结果
['⻢纤⽻', '深圳', '173', '50', '13744234523']
['罗梦⽵', '北京', '175', '49', '18623423421']
['叶梓萱', '上海', '171', '49', '18042432324']二进制模式操作文件
上面操作的只是文本文件 ,但是如果遇到视频呀、图片呀,你直接打开的话会报错是因为,open()有个encoding参数,默认是None, 是用来告诉解释器,要操作的这个文件 是什么编码。 不填的话,就⽤解释器默认编码,即utf-8。如果你是⼀个gbk编码的文件 ,就必须指定 encoding=gbk
open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None,
closefd=True, opener=None)f = open("gbk_file",encoding="gbk")
for line in f:
print(line)但是像图片、视频,是有自己特殊的编码的,而非什么unicode\utf-8这样的文本编码 。 所以要操作这样的文件 ,你用utf-8什么的去解,自然会报错。
如何处理图片、视频文件呢?
可以用2进制模式打开文件
rb 2进制只读模式
wb 2进制创建模式,若⽂件已存在,则覆盖旧文件
ab 2进制追加模式,新数据会写到文件末尾
这样,你读出来的数据,就是bytes字节类型了,当然写进去的也必须是bytes格式了
f = open("gbk_file2","wb")
f.write("哈".encode("gbk") ) # 写⼊的⽂本要⽤字节类型练习题-全局文本检索替换
写⼀个脚本,允许⽤户按以下⽅式执⾏时,即可以对指定⽂件内容进⾏全局替换,且替换完毕后打印替换了多少处内容 。写完后的脚本调用方式:
python your_script.py old_str new_str filenameimport sys
old_str=sys.argv[1]
new_str=sys.argv[2]
filename=sys.argv[3]
#1. load into ram
f=open(filename,"r+")
data=f.read()
#2. count and replace
old_str_count=data.count(old_str)
new_data=data.replace(old_str,new_str)
#3. clear old filename
f.seek(0)
f.truncate()
#4.save new data into file
f.write(new_data)
print("成功")
print(f'''成功替换字符'{old_str}' to '{new_str}',共{old_str_count}处...''')编码方式
计算机只能存储0,1这些二进制数字,其它的文本,数字等等都必须转换成二进制进行存储。
字符编码
我们自己强行约定了⼀个表,把文字和数字对应上,这张表就相当于翻译,我们可以拿着⼀个数字来对比对应表找到相应的文字,反之亦然。

ASCII编码
用固定的8比特长度来存储每个字符

GB2312 & GBK
英文问题是解决了, 我们中文如何显示呢? 美国佬设计ASSCII码一共就适用于128个字符,其它语言可能就不够用了,于是不同国家和地区开始制定自己的编码标准,于是我们1980年设计出了GB2312编码表,长成下面的样子。⼀共存了6763个汉字。

直到现在,我们的windows电脑中文版本的编码就是GBK(对GB2312 进行扩展)。
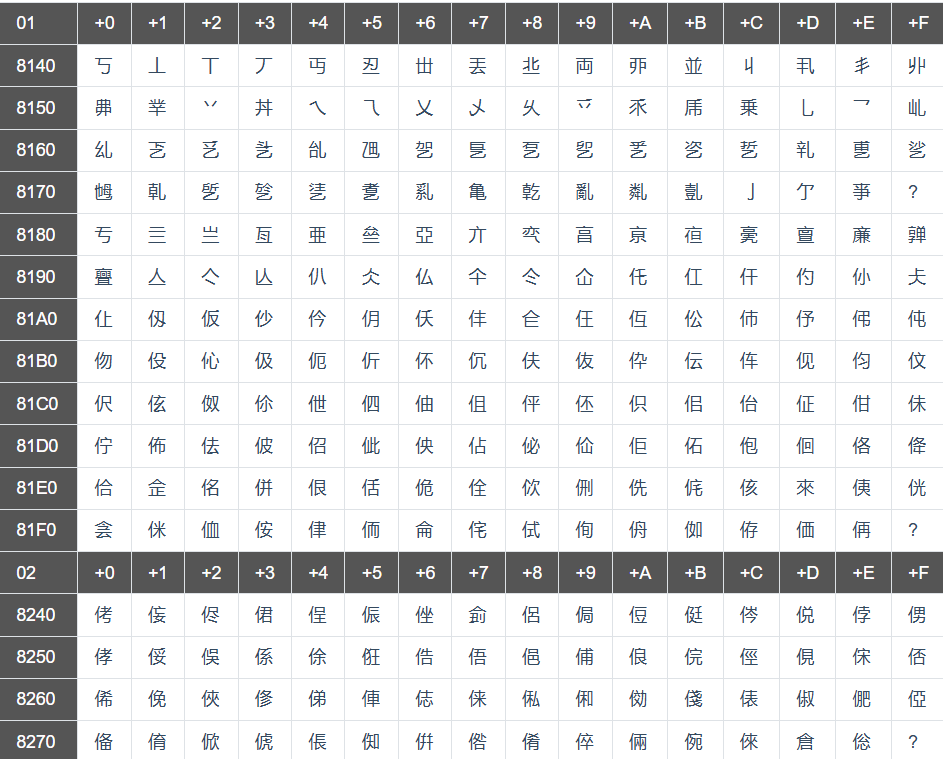
乱码问题
由于标准不统一,乱码问题也随之产生,这是因为同一个二进制的数字在不同的编码集中代表着不同的字符。因此,Unicode应运而生。Unicode把所有语言都统一到⼀套编码里,这样就不会再有乱码问题了。
Unicode和UTF-8
Unicode 2-4字节 已经收录136690个字符,并还在⼀直不断扩张中…Unicode标准也在不断发展,但最常用的是用两个字节表示一个字符(如果要用到非常偏僻的字符,就需要4个字节)。现代操作系统和大多数编程语言都直接支持Unicode。
UTF-8: 使用1、2、3、4个字节表示所有字符;优先使⽤1个字节、无法满足则使增加⼀个字节,
最多4个字节。
UTF-16: 使用2、4个字节表示所有字符;优先使用2个字节,否则使用4个字节表示。
UTF-32: 使用4个字节表示所有字符;
总结:UTF 是为unicode编码 设计 的⼀种 在存储和传输时节省空间的编码方案。
如果你要传输的文本包含大量英⽂字符,⽤UTF-8编码就能节省空间:

不同字符编码间的转换
windows系统的默认编码是GBK, 如果你把⼀段在windows系统上用gbk编码的字符发送到mac电脑 上, mac默认编码是utf-8, 那这段文字是乱码显示的。 如何实现在mac上正常显示这段 gbk文本呢?
编码与解码
1.把任意编码转换成unicode的过程叫做解码
>>> s="卿云"
>>> s="卿云"#unicode格式
>>> s.encode("utf-8") #将其编码成utf-8
b'\xe5\x8d\xbf\xe4\xba\x91'
2.把unicode转换成的任意编码过程叫做编码
>>> s
'卿云'
>>> s.encode("utf-8").decode("utf-8")#把utf-8编码的字符在转化成unicode
'卿云'
>>> s
'卿云'
>>> s.encode("utf-8") #将其编码成utf-8
b'\xe5\x8d\xbf\xe4\xba\x91
#会变成bytes字节格式,bytes字节类型是用16进制表示的,像\xe5这样两个16进制数是代表一个字节(因为一个16进制数占4位)
字节类型到底是什么
字节类型其实就是二进制数,只不过为了易于理解,常用16进制数表示。