现有私募基金发行一支特殊基金产品,该基金认购人数上限不超过 30 人, 募集总金额不超过 3000W,每个投资人认购金额不定。该基金只能将募集到的钱用于投资两支股票,且要求两支股票投资金额必须相同,且每位投资人的钱只能用于投资一支股票或不投资。问如何在给定募集条件下,实现投资金额最大化。如果无法实现则返回0

解题方法
- 第1步:找到和为偶数的所有子集
- 第2步:将子集传算法计算:两子集相等
- 第3步:筛选出和值最大的结果

注意:
[1, 2, 3, 10, 5, 5], 只要求子集和为总和一半,不管哪种划分方式,都是“最优解”
a: [1, 2 10], [3, 5, 5]
b: [1, 2, 5, 5], [3, 10]
一、代码与执行结果
具体代码
1、动态规划:将列表切分成两个和值相等的子列表
import random
# 动态规划:将列表切分成两个和值相等的子列表
def can_partition(nums):
total_sum = sum(nums)
if total_sum % 2 != 0:
return False
if len(nums) == 2:
if nums[0] == nums[1]:
return ([nums[0]], [nums[1]], nums[0]*2)
else:
return False
target_sum = total_sum // 2
n = len(nums)
# ----------------------
# 初始化动态规划表 dp,其中 dp[i][j] 表示前 i 个元素中是否存在和为 j 的子集。
dp = [[False] * (target_sum + 1) for _ in range(n + 1)] # 空间: O(n * target_sum)
# 初始时,将 dp[0][0] 设为 True。
dp[0][0] = True
# 创建一个字典 index_map,用于记录每个元素在原列表中的索引。[1, 5, 11, 5] [1, 5, 5, 11]
index_map = {}
for i in range(n):
if nums[i] not in index_map:
index_map[nums[i]] = [i]
else:
index_map[nums[i]].append(i)
# 哈希表
# 使用两层循环遍历元素和目标和的可能取值,更新动态规划表 dp。
# 对于每个位置 (i, j),如果前 i-1 个元素中存在和为 j 的子集,
# 或者前 i-1 个元素中存在和为 j-nums[i-1] 的子集且第 i 个元素没有被选择,
# 则 dp[i][j] 为 True。
for i in range(1, n + 1): # O(n)
for j in range(target_sum + 1): # O(target_sum) -> O(n * target_sum)
dp[i][j] = dp[i - 1][j]
if j >= nums[i - 1]:
dp[i][j] = dp[i][j] or dp[i - 1][j - nums[i - 1]]
# 如果动态规划表中 dp[n][target_sum] 为 True,说明存在一种划分方式,将列表划分成两个和相等的子列表。
# 接下来,需要找到具体的划分方式:
if dp[n][target_sum]:
# 初始化空列表 subset1 和 subset2_indices,subset1 用于存放第一个子列表的元素,subset2_indices 用于存放第二个子列表的索引。
subset1, subset2_indices = [], []
i, j = n, target_sum
# 从动态规划表的右下角开始向左上角遍历,如果第 i 个元素没有被选择,则将其加入 subset1 中,同时更新目标和 j。
while i > 0 and j > 0:
# 如果 dp[i - 1][j] 为 True,说明第 i 个元素没有被选择,则将 i 减 1,即考虑前 i - 1 个元素。
if dp[i - 1][j]:
i -= 1
# 如果 dp[i - 1][j] 为 False,说明第 i 个元素被选择了,则将第 i 个元素加入 subset1 中,并更新目标和 j。
else:
subset1.append(nums[i - 1])
j -= nums[i - 1]
subset2_indices.append(i - 1) # 更新 subset2_indices
i -= 1
# 最终得到的 subset2_indices 中存放的是第二个子列表的索引,根据这些索引可以得到第二个子列表 subset2。
subset2_indices = set(range(n)) - set(subset2_indices)
subset2 = [nums[i] for i in subset2_indices]
return subset1, subset2, sum(subset1)*2
else:
return False
# 返回两个子列表和相加的结果的两倍,表示划分成功,否则返回 False。
# # Test
# nums = [1, 5, 11, 5]
# print(can_partition(nums)) # Output: ([11], [1, 5, 5])
# nums = [1, 5, 5, 11]
# print(can_partition(nums)) # Output: ([11], [1, 5, 5])
# nums = [1, 2, 2, 3, 4]
# print(can_partition(nums)) # Output: ([3, 2, 1], [2, 4])
2、筛选出所有符合要求的子集
# 划分子集:筛选出所有符合要求(例如和值为偶数、至少包含2个元素等)的子集,并降序排序
def subset_sums(lst):
total_sum = sum(lst)
Len = len(lst)
if (Len <= 1) or (Len > 30) or (total_sum > 3000):
return False
def calc_sum(subset):
return sum(subset)
def is_even(num):
return num % 2 == 0
def find_sublists(lst, start, end, path, result): # # 回溯,时间, O(2^n)
'''
lst:要查找子列表的原始列表
start:当前递归的起始索引
end:递归的结束索引(不包括在内)
path:当前已构建的子列表
result:包含所有符合条件的子列表的列表
'''
if len(path) >= 2 and is_even(calc_sum(path)) and (len(path) > 2 or path[0] == path[1]):
result.append(path.copy())
# 递归终止条件,当起始索引等于结束索引时,递归结束
if start == end:
return
# 遍历从start到end的索引,每次将当前索引对应的元素添加到path中
for i in range(start, end):
path.append(lst[i])
# 递归调用函数,将i+1作为新的起始索引,继续寻找子列表
find_sublists(lst, i + 1, end, path, result)
# 在递归返回后,弹出最后一个元素,以便尝试其他可能的子列表
path.pop()
def sort_and_remove_duplicates(lists): # # O(nlog(n))
# 对每个子列表进行排序,并转换为元组以便于后续去重
sorted_lists = [tuple(sorted(sublist)) for sublist in lists]
# 使用集合去除重复的子列表
unique_lists = list(set(sorted_lists))
# 按照子列表的和值从大到小排序整个列表
unique_lists.sort(key=lambda x: sum(x), reverse=True)
# 将子列表转换回列表形式并返回结果
return [list(sublist) for sublist in unique_lists]
def sort_sublists(lists):
sorted_lists = sorted(lists, key=lambda x: calc_sum(x), reverse=True)
for i in range(len(sorted_lists)):
sorted_lists[i].sort()
return sorted_lists
result = []
find_sublists(lst, 0, len(lst), [], result)
return sort_sublists(sort_and_remove_duplicates(result))
3、测试-生成模拟数据
# 生成模拟数据
def split_number(number, parts):
# 初始化每个部分为0
parts_sum = [0] * parts
remaining = number
# 循环分配数字直到只剩下最后一个部分
for i in range(parts - 1):
# 随机分配数字,确保剩余数字可以被均分
parts_sum[i] = random.randint(1, remaining - parts + i + 1)
remaining -= parts_sum[i]
# 最后一个部分取得所有剩余数字
parts_sum[-1] = remaining
return parts_sum
def generate_random_partitions():
# 随机将 Q 两次切分成不同的 M 份
# M1 和 M2 的个数分别为 1 到 10 之间,这样设置比其他方法产生的结果更加均衡,防止产生大量1
M1 = random.randint(1, 10)
M2 = random.randint(1, 10)
Q_min = max(M1, M2)
# 生成一个 30-1500 内的随机数
Q = random.randint(Q_min, 1500)
# 随机切分 Q 为 M1 份和 M2 份
part1 = split_number(Q, M1)
part2 = split_number(Q, M2)
Randnumber = 30 - M1 + M2
total_money = Q * 2
balance = 3000 - total_money
bal = random.randint(1, balance)
if Randnumber >= 1:
R = random.randint(1, Randnumber)
if R <= balance:
part_balance = split_number(bal, R)
else:
part_balance = []
else:
part_balance = []
return part1 + part2 + part_balance
4、主程序执行
if __name__ == "__main__":
# 示例数据
nums = [1, 5, 11, 5]
# nums = [1, 5, 5, 11]
# nums = [12,7,13,18]
# nums = [12,8,13,18]
# nums = [1,2,3,4,5,6]
# nums = [2,3,4,5,6]
# nums = [1,2,3,4,5]
# nums = [17,3,8]
# nums = [1,1]
# nums = [1,2]
# nums = [1, 2, 2, 3, 4]
# nums = [2, 2, 2, 2, 3]
print("示例数据-输入:", nums)
# 模拟数据
# nums = generate_random_partitions()
# print("模拟数据-输入:", nums)
numss = subset_sums(nums)
if numss:
# print("子集组合:", numss) # 子集组合,最优解只会在这些子集中产生
for nums in numss:
result = can_partition(nums)
if result:
print("输出:", result) # 和值最大的两个相等子集
break
else:
print("输出:", 0)
5、输出
示例数据-输入: [1, 5, 11, 5]
输出: ([5, 5, 1], [11], 22)
具体算法过程:
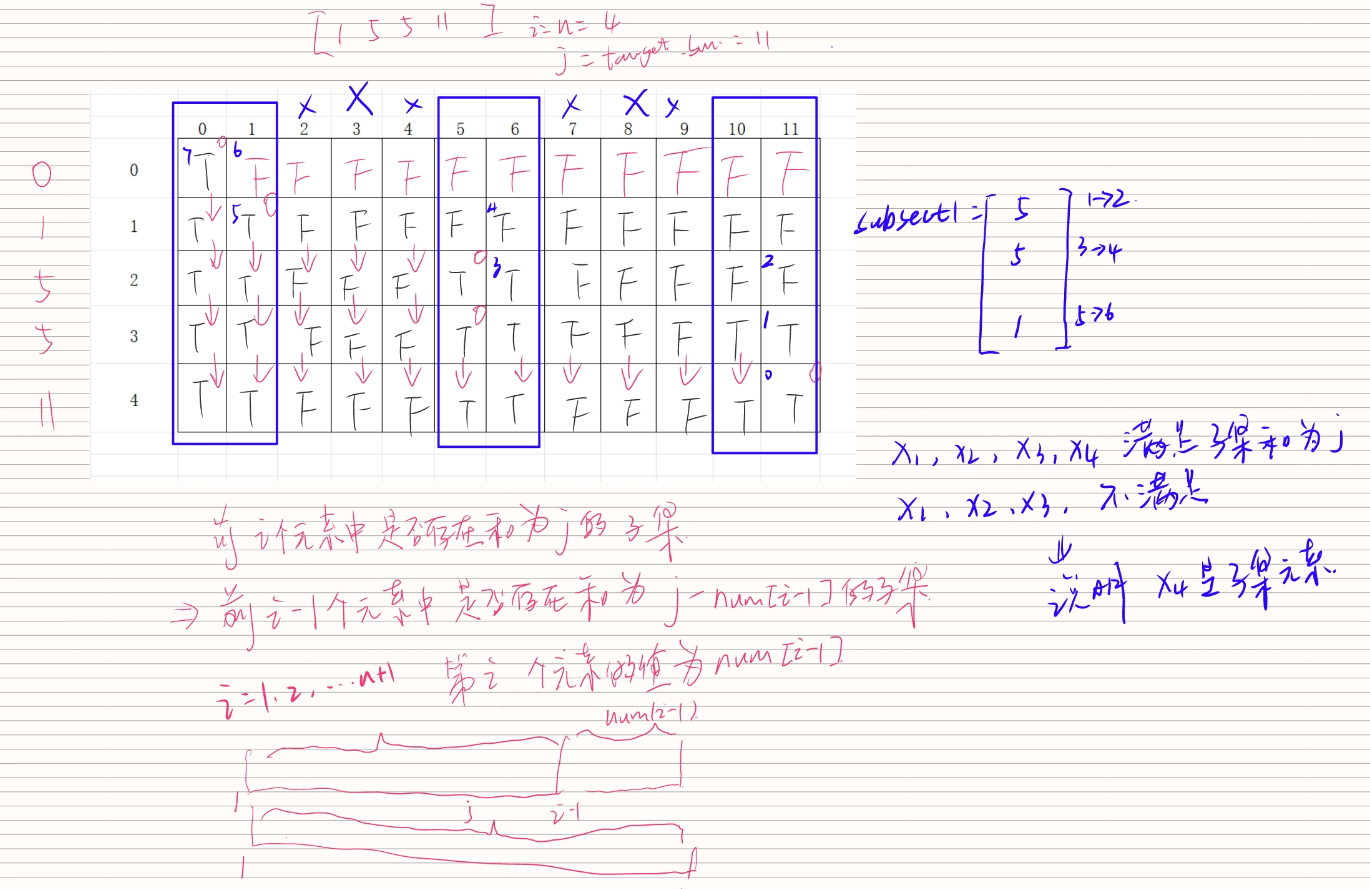
二、函数关键信息
1、can_partition(nums)函数信息
函数名称:can_partition
关键参数和含义:
nums:输入的整数列表,表示要判断是否能将其分割成两个和相等的子集。
返回值:
如果能将 nums 分割成两个和相等的子集,则返回一个元组 (subset1, subset2, sum(subset1)*2),其中 subset1 和 subset2 分别为两个和相等的子集,sum(subset1)*2 为两个子集的和的两倍。
如果不能将 nums 分割成两个和相等的子集,则返回 False。
主要变量信息:
total_sum:nums 列表所有元素的和。
target_sum:total_sum 的一半,即要达到的子集的目标和。
n:nums 列表的长度。
dp:动态规划数组,dp[i][j] 表示前 i 个元素是否能凑出和为 j 的子集。
index_map:字典,用于记录 nums 中每个元素的索引。
subset1:和相等的子集之一。
subset2_indices:和相等的另一个子集的索引。
subset2:和相等的另一个子集。2、subset_sums(lst)函数信息
函数名称:subset_sums
关键参数和含义:
lst:输入的整数列表,表示要找出其中所有符合条件的子集。
返回值:
如果找到符合条件的子集,则返回一个列表,列表中包含所有符合条件的子集,每个子集都是一个列表。
如果未找到符合条件的子集,则返回 False。
主要变量信息:
total_sum:lst 列表所有元素的和。
Len:lst 列表的长度。
result:存储符合条件的子集的列表。
calc_sum(subset):计算子集 subset 的和。
is_even(num):判断一个数是否为偶数。
find_sublists(lst, start, end, path, result):递归查找 lst 中符合条件的子集。
sort_and_remove_duplicates(lists):对子集进行排序和去重。
sort_sublists(lists):对子集列表进行排序。
三、程序设计原理
1、整体思路
第1步:对于一个列表找到和为偶数的所有子集,限制子集至少包含两个元素,若只有两个元素,要求元素值大小相等。对子集和值大小进行降序排序。
第2步:将符合要求的子集用动态规划算法进行切分,使得两子集相等,一旦找到,便终止循环,此时的结果满足和值最大
第3步:生成模拟数据,检验算法有效性。2、can_partition(nums)函数具体方法
2.1 函数思路
首先计算nums数组的总和total_sum,如果total_sum为奇数,则无法分割成等和子集,直接返回False。
然后计算target_sum为total_sum的一半,问题转化为在nums数组中找到一组元素的和等于target_sum。
使用动态规划算法,定义二维数组dp[i][j]表示在前i个元素中是否存在子集的和为j。初始化dp数组为False,表示初始状态下不存在子集的和为j。
遍历nums数组,对于每个元素nums[i],遍历可能的和值j(从target_sum到nums[i]),更新dp[i][j]为True,表示在前i个元素中存在子集的和为j。
最终如果dp[n][target_sum]为True,表示存在一组子集的和为target_sum,根据dp数组回溯找出这组子集。
2.2 回溯查找子集:
当dp[n][target_sum]为True时,从dp数组中回溯查找这组子集。从最后一个元素dp[n][target_sum]开始,如果dp[i-1][j]为True,则说明nums[i-1]不在子集中,将i减一;否则,将nums[i-1]加入subset1中,并将j减去nums[i-1],继续向前查找。
通过回溯找到subset1后,将剩余的元素构成subset2。
2.3 优化空间:
使用了index_map来记录nums数组中每个元素的索引,避免重复计算。
2.4 返回结果:
如果存在分割成等和子集的方案,则返回subset1, subset2和sum(subset1)*2;否则返回False。3、subset_sums(lst)函数具体方法
3.1、 函数思路
首先计算lst数组的总和total_sum和长度Len,如果Len小于等于1或大于30,或者total_sum大于3000,则直接返回False。
使用回溯算法,递归地寻找符合要求的子集,即和值为偶数、至少包含2个元素。
对找到的子集进行排序和去重操作。
3.2、回溯算法:
定义一个辅助函数find_sublists(lst, start, end, path, result),其中lst为输入数组,start和end表示当前搜索范围的起始和结束位置,path为当前的子集,result为存储符合要求的子集的列表。
在回溯过程中,如果当前子集的长度大于等于2且和值为偶数且长度大于2或者前两个元素相等,则将该子集加入结果中。
递归搜索下一个元素加入子集或者不加入子集的情况,直到搜索完所有元素。
3.3、排序和去重:
对于符合要求的子集列表,首先对每个子集进行排序,然后转换为元组以便于后续去重。
使用集合去除重复的子集。
最后按照子集的和值从大到小排序整个列表,并将子集转换回列表形式返回结果。
3.4、边界条件处理:
在开始时检查输入数组的长度和总和是否满足条件,如果不满足则直接返回False。
四、复杂度分析
1、can_partition(nums)函数复杂度分析
时间复杂度:程序使用了动态规划算法来解决分割等和子集问题。外层循环的时间复杂度为O(n),内层循环的时间复杂度为O(target_sum),其中n为nums数组的长度,target_sum为nums数组所有元素的和的一半。因此,总体时间复杂度为O(n * target_sum)。
空间复杂度:程序使用了一个二维数组dp来保存状态,其大小为(n+1) * (target_sum+1),因此空间复杂度为O(n * target_sum)。2、subset_sums(lst)函数复杂度分析
时间复杂度:程序使用了回溯算法来找出所有符合要求的子集,并对结果进行排序和去重。回溯算法的时间复杂度为O(2n),其中n为lst数组的长度。排序和去重操作的时间复杂度为O(nlog(n)),因此总体时间复杂度为O(2n + nlog(n))。
空间复杂度:程序使用了递归栈来存储回溯过程中的中间结果,最坏情况下的空间复杂度为O(n),其中n为lst数组的长度。3、整体复杂度
can_partition 函数的时间复杂度是O(n * target_sum),空间复杂度也是O(n * target_sum)。subset_sums 函数的时间复杂度是O(2^n + nlog(n)),空间复杂度是O(n)。
在整个代码块中,首先调用 subset_sums(nums) 函数得到子集组合 numss,这一步的时间复杂度是 subset_sums 的时间复杂度,即O(2^n + nlog(n))。
然后,对于 numss 中的每个子集,调用 can_partition(nums) 函数,这一步的时间复杂度是O(n * target_sum)。由于 numss 中可能有多个子集,所以整个过程中需要执行多次 can_partition 函数。
综上所述,整个代码块的总时间复杂度取决于两个函数中较大的那个复杂度,即O(2^n + n*log(n)),空间复杂度为O(n * target_sum)。