一、研究背景与意义
汇率是指两个国家之间的货币兑换比率,而且在国家与国家的经济交流有着举足轻重的作用。随着经济全球化的不断深入,在整个全球经济体中,汇率还是一个评估国家与国家之间的经济状况和发展水平的一个风向标。汇率的变动会对一个国家的对外贸易频繁度、外汇储备以及对于国内的物价水平都会产生一定的影响。故针对于汇率的变动,应该采取相应的措施及政策。....
二、国内外研究现状及总结
随着我国经济的不断发展进步,人民币在国际上的地位逐渐提升,出现了大批学者对于汇率的研究,其研究的角度有许多,其中具有代表性的有:研究影响汇率波动的因素、关于汇率政策与制度的研究以及通过建立适当的模型来进行汇率波动的研究和预测,个人看来,其中最为主流的角度还是建立相应的模型来进行研究。.....
三、研究对象
本文的研究对象是2009年至2020年的中美的月度汇率数据,数据来源于雅虎财经网,其中包括每月开盘、收盘价,每月最高价最低价以及涨跌幅度。为了分析清晰,本文选择了每月收盘价为主要序列数据。
首先将所获取得到的数据进行清洗、缺失值处理等预处理操作。然后将处理好的数据进行分析,然后选择适当的模型进行预测,最后得出相应的结论。
四、主要研究内容和方法
本文主要是以时间序列分析为主要基础,针对特定时间段内的中美汇率波动来分析建模以及预测后期的汇率走势,重点介绍本论文研究主要运用的ARIMA模型以及ARCH、GARCH模型的理论,然后针对数据来进行实证分析,做出相应的预测。....
五、模型知识概述
略
六、实证分析
本文选取了2009年1月至2020年1月的中美汇率月度数据,其中数据包括每月的开盘价(open),收盘价(close),每月中最高点、最低点数据以及汇率变动比率等等,为了研究的更好进行,本文选择的是每月的收盘价为主要数据来进行分析及操作。
pop<-read.table("D:/网页下载/USD_CNY历史数据.csv",sep=",",header = T)
pop
pirce<-pop$close
HL<-ts(pirce,frequency = 12,start = 2009)
plot(HL,main = "汇率变动",xlab = "年份",ylab="汇率变动量")
#白噪声检验
for(i in 1:2) print(Box.test(HL,type = "Ljung-Box",lag=6*i))
随后,对于本文的时序数据进行描述性统计,其具体结果如下表:
表 时序数据描述性统计
Min |
1st Qu |
Median |
Mean |
3rd Qu |
Max |
6.054 |
6.284 |
6.584 |
6.562 |
6.827 |
7.154 |
其次,进行纯随机性检验,只有当序列为非白噪声序列,才能进行后续操作,否则是无意义的。
表 纯随机性检验
Box-Ljung test |
||
Data: 2009年1月-2020年1月 |
||
X-squared = 664.74 |
df=6 |
P_value<2.2e-16 |
X-squared = 1029.8 |
Df=12 |
P_value<2.2e-16 |

从图分析,中美的月度汇率的时间序列图形在2009年-2020波动起伏较大,可见受许多政治、经济等因素的影响,单从时序图可以判断,该序列是属于非平稳序列
为了保证其科学性,下一步需要做关于该序列的ADF单根检验。
表 中美汇率的ADF检验
Augmented Dickey-Fuller Test |
||
Alternative : stationary |
||
Type 1:no drift no trend |
||
Lag: |
ADF |
P_value |
0 |
-0.454 |
0.513 |
1 |
-0.396 |
0.530 |
2 |
-0.384 |
0.533 |
3 |
-0.372 |
0.537 |
4 |
0.378 |
0.535 |
Type 2: with drift no trend |
||
0 |
-1.49 |
0.526 |
1 |
-1.95 |
0.347 |
2 |
-1.93 |
0.356 |
3 |
-2.08 |
0.296 |
4 |
-1.93 |
0.354 |
Type 2: with drift with trend |
||
0 |
-1.71 |
0.696 |
1 |
-2.16 |
0.504 |
2 |
-2.15 |
0.510 |
3 |
-2.29 |
0.452 |
4 |
-2.19 |
0.493 |
从上表可以看出,其P值大于0.05的显著性水平,故在0.05的显著性水平下,接受其原假设,即表明该序列为非平稳序列。
从上表3.3可以看出,其P值大于0.05的显著性水平,故在0.05的显著性水平下,接受其原假设,即表明该序列为非平稳序列。
#打印出关于季节性趋势的图表
dc<-decompose(HL)
season<-dc$figure
plot(season,type = "b",xaxt="n",xlab = "Month",ylab = "Season Effect")

由于本文数据为汇率数据,该类型数据通常具有集聚效应,故在序列为平稳序列基础上,查看其差分之后差分图。
#差分和画出差分图
diff(HL)
plot(diff(HL))
win.graph(width=3.25,height=2.5,pointsize=8)
tsdisplay(diff(HL))
dc<-decompose(diff(HL))
plot(dc)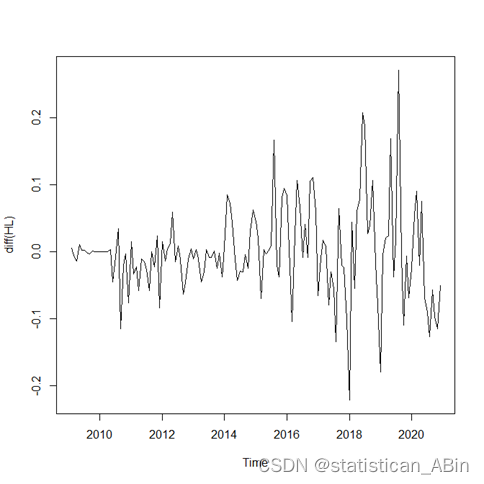
模型选择
#ARIMA(1,1,)
model=Arima(HL,order=c(1,1,0))
summary(model)#aic = -2588.36Training set error measures: |
|||||||||||
Series: 中美汇率 |
|||||||||||
ARIMA(0,1,1) |
|||||||||||
Coefficients: |
|||||||||||
ma1 |
|||||||||||
0.3127 |
|||||||||||
s.e. |
0.0811 |
||||||||||
Sigma^2=0.004074: |
Log likelihood =191.02 |
||||||||||
AIC=-378.04 |
AICc=-377.95 |
BIC=-372.11 |
|||||||||
ME |
RMASE |
MAE |
MPE |
MAPE |
MASE |
ACF1 |
|||||
Training set |
-0.0016 |
0.0634 |
0.0447 |
-0.0260 |
-0.6762 |
0.2001 |
0.0067 |
||||
无论是AIC准则还是BIC准则,模型都定位一个模型,即ARIMA(0,1,1)。并且也可从表中得出模型的各个评判指标。最终模型的表达式应为:

接下来进行残差分析
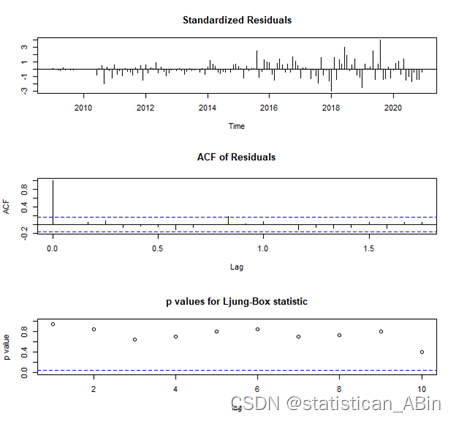
接下来GARCH检验及预测看是否存在ARCH效应。
ARCH LM-test ; null hypothesis: no ARCH effects |
||
Data: model$residual |
||
Chi-squared=2.9169 |
df=1 |
P_value=0.08766 |
Chi-squared=3.0018 |
df=2 |
P_value=0.0229 |
Chi-squared=9.0705 |
df=3 |
P_value=0.02837 |
Chi-squared=10.198 |
df=4 |
P_value=0.03722 |
Chi-squared=12.263 |
df=5 |
P_value=0.03136 |
进一步,运用所得到的模型进行预测,本文由于是月度数据,所以为了保证预测的准确性,将预测阶数定为5阶,其最终预测结果如下图和表。
###模型预测
model=Arima((HL),order=c(0,1,1),include.mean = T,transform.pars=T)
model
#预测未来5期,99.5%置信区间
forecast<-forecast(model,h=5,levels=c(95.5))
forecast
##可视化预测图
plot(forecast)
七、结论与展望
本文通过分析2009年1月至2020年1月的中美汇率,首先通过差分,将序列变为平稳序列,再通过季节因素提取,提取出其他因素,然后进行ARCH检验(本文是LM检验),最后建立模型ARCH(1,1)和ARIMA(0,1,1)进行分析和预测,最终预测结果表现为中美汇率的整体趋势是往下波动。但是随着时间周期的变成,预测误差变得越来越大,这可能是传统预测模型的缺陷所在.....
创作不易,希望大家多多点赞收藏和评论!