『太长不看版』
Apache Kvrocks[1] 作为 Redis 的开源替代,近期支持了以下查询语法:
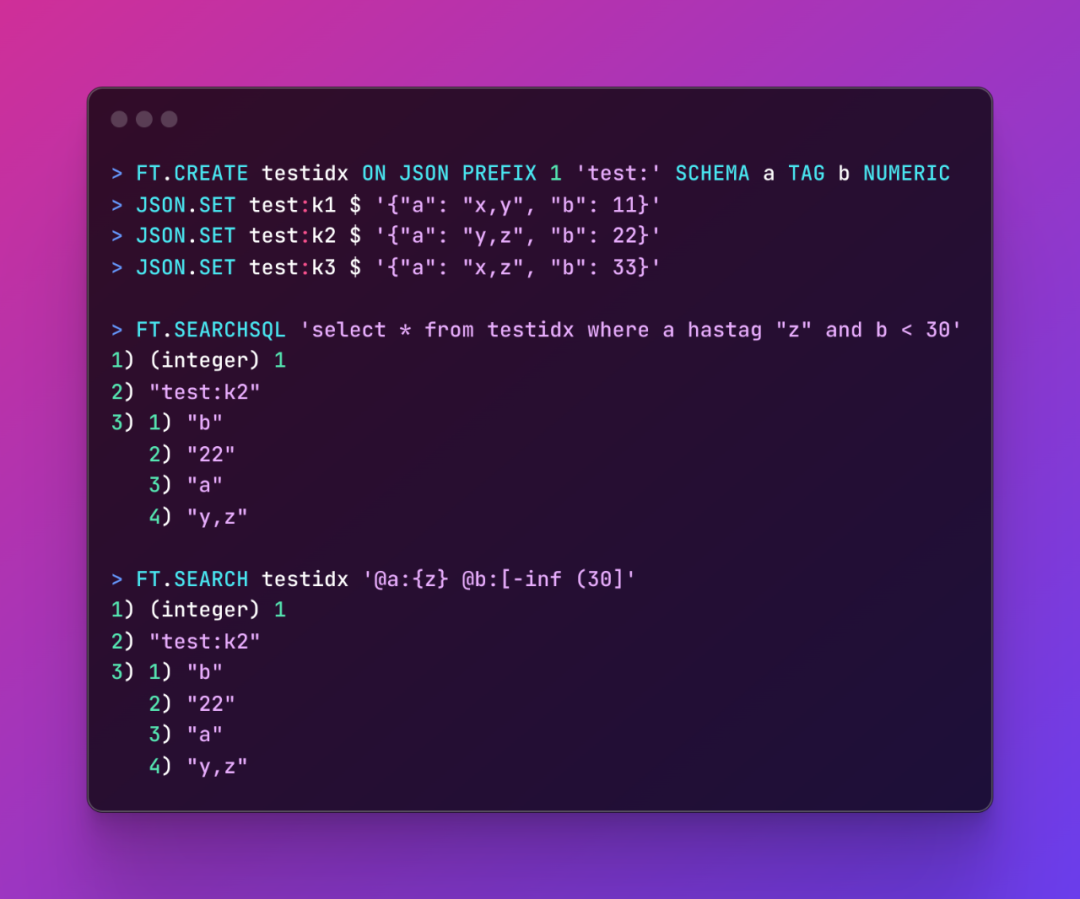
欢迎试用或跳转到文末完整示例[2]段落查看具体步骤的含义。
原文作者 twice 发表于 Apache Kvrocks 官方博客[3]。本文是取得原文作者许可的中文译文,翻译过程中间略有措辞顺序调整和演绎。
项目背景
首先介绍一下 Apache Kvrocks 项目:它是 Redis 的开源替代,构建在 RocksDB 之上。因此,就缓存场景而言,Kvrocks 跟 Redis 是有设计上的差距的,但是在数据持久化和数据存储成本方面,Kvrocks 就有设计上的优势。总的来说,Kvrocks 是一个实现了绝大部分 Redis 命令[4]的 NoSQL 数据库。
Kvrocks 支持 RESP 通信协议[5],包括 v2 和 v3 两个版本。因此,绝大部分 Redis 生态的工具都可以无缝接入到 Kvrocks 上。上面演示的例子就是从 Redis 提供的 redis-cli 命令行工具接入到 Kvrocks 后操作的。
Kvrocks 作为一个使用 C++ 从头重新实现 Redis 的开源替代,不仅支持了 Redis 最基本的命令,还支持了 Redis Stack 当中的高级功能,包括:
String
Hash
Set
Sorted Set
Stream
GEO
Lua Script
Transaction
Functions[6]
Bloom Filter[7]
JSON[8]
Redis Stack 的功能源码一直是商业协议下发布的,新版本的 Redis 也使用了其自制的专有协议发布。Kvrocks 在保证接口行为一致的前提下,完全使用 C++ 从头重新实现,不存在合规风险。本文介绍的 KQIR 更是相同用户体验下完全原创的底层实现方案,与上游实现是相互独立的。
复杂查询的需求
近二十年来,NoSQL 数据库迎来了一段蓬勃发展的黄金时期,一度盖过传统数据库的风头。这主要是因为 NoSQL 数据库性能更好,易于扩展,并且针对特定使用场景有极致的优化。例如,Redis 作为 KV 数据库的代表,MongoDB 作为文档数据库的代表,Apache HBase 作为某种表格数据库的代表,各领风骚数年。
然而,许多用户不愿意仅仅出于性能原因而放弃传统 SQL 数据库的提供基本功能,尤其是 ACID 事务、SQL 固有复杂查询能力,以及结构化数据和关系代数提供的优化和抽象。因此,一批自诩 NewSQL 的新型数据库就此诞生。其中典型包括 TiDB 和 CockroachDB 等。
如前所述,Kvrocks 大体上是一个 NoSQL 数据库。虽然 Kvrocks 算不上 NewSQL 数据库,但是它仍然努力在 NoSQL 和 NewSQL 范式之间取得平衡。在保证 NoSQL 的高性能和灵活性的前提下,Kvrocks 努力实现事务保证和支持更复杂的查询。
RediSearch?
RediSearch[9] 是一个 Redis 模块,它通过查询、辅助索引和全文搜索功能实现了对 Redis 的增强。
虽然其对应的 Redis 命令[10]以 FT. 开头(即 Full-Text 全文),但它不仅仅是全文搜索。
实际上,Redis 正快速向 SQL 数据库靠拢。RediSearch 允许用户在现有 Redis JSON 或 HASH 数据上创建结构化模式,以用于索引构建。这些模式支持各种字段类型[11],如数字、标记、地理、文本和矢量,后两者用于全文搜索和矢量搜索。不同于直接支持 SQL 查询的方案,RediSearch 提供了一种独特的查询语法[12],称为 RediSearch 查询语言。
RediSearch 在许多领域都能找到应用场景,例如利用其矢量搜索功能来支持检索增强生成(RAG)。例如,LangChain[13] 将 Redis 作为其矢量数据库之一。如果 Kvrocks 能够实现 RediSearch 的接口,那么 Kvrocks 就可以作为这些生态当中 Redis 位置的一个潜在选项。对于那些更关注成本和持久化的用户来说,Kvrocks 将成为一个非常有吸引力的选项。
SQL?
RediSearch 自定义了一套语法来进行查询。这产生了一些额外的问题。
首先,RediSearch 的模式(也称为索引,使用 FT.CREATE 创建)可以对应到 SQL 数据库中的一个表。它的查询语法在语义上也与 SQL 查询一致。考虑到这种相似性,支持 SQL 查询并不会带来太多额外工作量。那么,为什么我们不把 SQL 查询也顺带支持上呢?
其次,SQL 的使用范围非常广,为许多人所熟悉,上手更简单。理解 RediSearch 查询语法需要花费相当的时间,而适应新的 SQL 数据库通常更不费力。此外,SQL 为各种查询功能提供了强大的支持,增强了表达能力(例如 JOIN、子查询和聚合等等)。
最后,RediSearch 查询语法受到一些历史设计的影响。例如,AND 和 OR 运算符(在 RediSearch 查询中用空格和 | 运算符表示)的优先级在不同的方言版本[14]中有所不同。这些村规增加了用户的理解成本,而常用的标准 SQL 给到用户的基本假设是相对一致的。
综合考虑,我们认为在 Kvrocks 支持复杂查询时,将 SQL 作为查询语言会是一个不错的决定。
『译注』
自研查询语言很多时候都是死路一条。InfluxDB 自己搞的 Flux 脚本语言已经进入维护模式了,说白了就是死了还没埋。新版本的 InfluxDB V3 一开始只想支持 SQL 作为查询接口,后来迫于存量压力实现了 InfluxQL 的兼容,但是显然 InfluxQL 也是其官方定义下的明日黄花了。
KQIR 的设计与实现
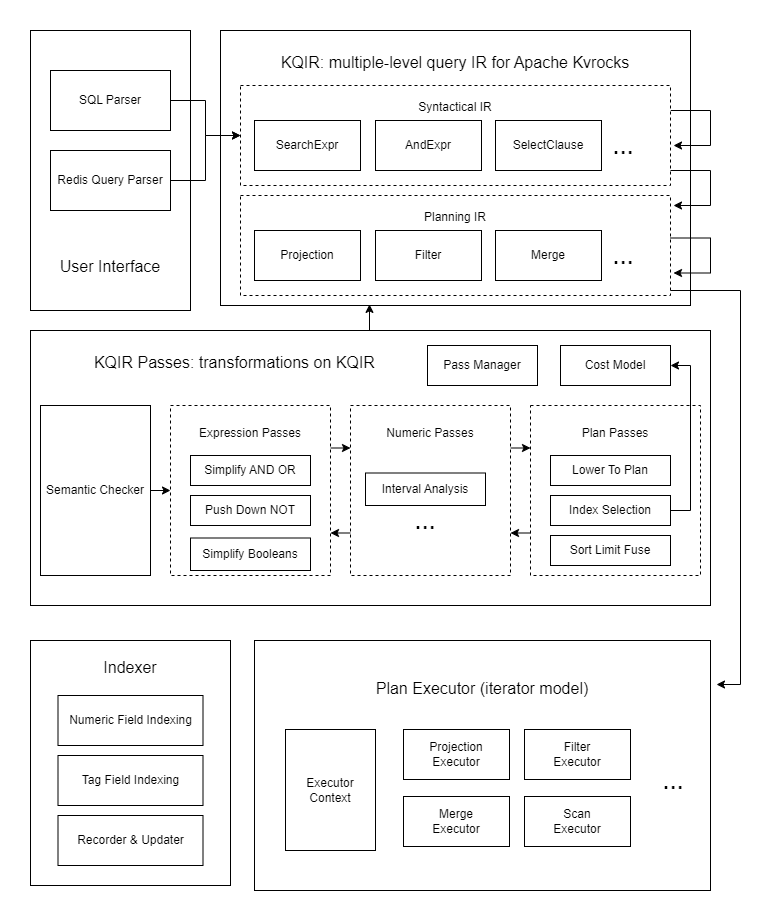
为了在 Kvrocks 系统当中支持 SQL 查询,我们需要设计一个健壮的查询引擎。它需要考虑到系统的扩展性、可维护性,以及强大的查询计划和优化能力。
Kvrocks 的方案是 KQIR 框架[15]。在 Kvrocks 的语境下,KQIR 代表着:
完整的查询引擎,包括语法解析、查询优化和算子执行,等等。
查询引擎全阶段操作的一种中间表示(IR)。
多层级的 IR
实现 KQIR 的一个主要目的是同时支持 SQL 和 RediSearch 的查询方言。为了屏蔽不同方言下用户输入的差异,我们需要设计一个统一的查询中间表示。
目前,Kvrocks 已经实现了一个支持 MySQL 语法和 RediSearch 查询语法的一个子集的语法解析器。它能够将这两者对应的抽象语法树统统转换为 KQIR 的形式。
KQIR 是一个多层级的中间表示,可以表示优化过程中不同级别的查询结构。抽象语法树首先会转换成 Syantatic IR 的形式,这是某些语法表达式的高级表示。这个形式的 IR 经过优化器处理后,会转变为 Planning IR 的形式。Planning IR 则是一种在查询引擎中表达查询执行计划的低级表示。
此外,我们将在优化之前对 IR 进行语义检查,以确保查询在语义上是正确的。这包括验证它是否不包括任何未定义的模式或字段,并使用适当的字段类型。
IR 优化器
KQIR 优化器由多个阶段(Pass)组成。这仿照了 LLVM 的概念和设计[16]。每个阶段都以某种形式的 IR 作为输入,执行相应的分析和更改,然后生成新的 IR 作为输出。
『译注』
twice 同时也是 LLVM 相关项目的活跃贡献者:
llvm/clangir[17]
llvm/llvm-project[18]
目前,优化器的过程分为三组:
表达式分析:主要优化逻辑表达式,如 AND、OR、NOT 运算符等;
数值分析:通过区间分析优化数值比较,例如消除不必要的比较,或改进比较表达式来实现查询优化;
查询计划生成:把 Syntatical IR 转换成 Planning IR 并通过选择最佳索引以及消除不必要排序来增强查询计划。
Kvrocks 的阶段管理器会控制上述阶段的运行顺序。每个阶段可能运行多次,但最终会收敛并交给执行器执行。
查询计划执行
KQIR 计划执行器是一个 Volcano 模型[19]的实现。
一旦 IR 优化器完成所有优化,计划执行器就可以拿到最终的 Planning IR 结果。然后,计划执行器会将 IR 转化为具体的执行算子,串接成为一个从源端拉取数据,经过层层转换后输出结果的流水线。
随后,Kvrocks 从最终结果的迭代器中轮询拉取数据,取得查询结果。
磁盘上的索引
不同于 Redis 在内存中存储索引数据,Kvrocks 需要在磁盘上构建索引。这意味着,对于任何字段类型,我们都需要设计编码来将索引转换为 RocksDB 上的键值对。
此外,我们需要在执行 JSON 或 HASH 命令前后分别递增地创建索引,以确保查询结果是实时的。
现状与限制
KQIR 功能目前已经合并到 unstable 分支上,支持 FT.CREATE、FT.SEARCH 和 FT.SEARCHSQL 等命令。我们鼓励用户进行测试和发布反馈。
然而,KQIR 仍处于早期开发阶段,我们无法保证兼容性,并且,许多功能仍然不完整。因此,即将发布的版本 2.9.0 将不包括 KQIR 组件。我们将在 2.10.0 版本开始发布 KQIR 功能。
字段类型支持
目前,我们只支持两种字段类型:标记(tag)和数字(numeric)。
标记字段用多个 tag 标记了每个数据记录,以便在查询中进行筛选。
数字字段保存双精度浮点范围内的数字数据,允许按特定的数值范围进行排序和过滤。
未来,我们计划扩大支持范围,将向量搜索和全文检索功能与其他字段类型一起实现。
事务保证
目前,KQIR 的事务保证非常弱,这可能会导致使用过程中出现意外问题。
Kvrocks 社群有另一个项目[20],计划通过建立结构化框架来增强 Kvrocks 的事务保证,从而在 KQIR 实现的 ACID 支持。
『译注』
上述项目也是今年开源之夏(OSPP)的一个项目。
IR 优化器的限制
目前,KQIR 在优化排序时没有使用成本模型,而是依赖一段专门的逻辑。这点会在未来的版本里以高优先级做改进。
此外,KQIR 目前没有使用基于运行时统计数据的优化。我们未来的重点将是将运行时统计信息集成到成本模型中,以实现更精确的索引选择。
与其他功能的关系
KQIR 与命名空间功能[21]集成良好。
FT.CRAETE 创建的任何索引都限制在当前命名空间中,不能在其他命名空间中访问,这与命名空间中访问其他数据的方式一致。
目前,KQIR 无法在集群模式[22]下启用。集群模式支持目前还没有计划,但是这是我们想要实现的功能。欢迎在 Kvrocks 社群当中分享你的需求场景或设计思路。
合规问题
虽然 KQIR 实现了 RediSearch 的接口,但它不包括任何来自 RediSearch 的代码。如前所述,KQIR 采用了一个全新的框架,其查询架构(包括解析、优化、执行)均独立于 RediSearch 的实现。
这点非常重要,因为 RediSearch 并不是开源软件,而是专有许可下的扩展。Kvrocks 的实现保证用户在开源协议下使用相关功能,而无需担心额外的合规风险。这也是 Apache 软件基金会品牌的一个重要保证。
这是一次冒险!
KQIR 目前仍处于早期实验阶段。我们建议用户在生产环境中使用 KQIR 功能时要慎重考虑,因为我们不保证兼容性。但是我们非常欢迎用户试用和提供反馈,这将有助于我们尽快稳定相关功能并正式发布。
未来计划
目前,twice 和 Kvrocks 的其他成员正在快速开发 KQIR 框架。所有上文提到的内容都将继续发展。如果你对这些主题感兴趣,欢迎在 GitHub 上随时了解最新进展。我们欢迎任何期望参与这些工作的开发者加入 Apache Kvrocks 社群并共同创造出有价值的软件。
作为 Apache 软件基金会旗下的开源社群,Kvrocks 社群完全由志愿者组成。我们致力于提供一个开放、包容和供应商中立的环境。
向量搜索
支持向量搜索的设计和实现目前正在进行中。相关进展非常乐观。
Kvrocks 社群的一些成员正在讨论,并提出了在 KQIR 上实现向量搜索的编码设计。
根据计划,我们将首先在磁盘上实现 HNSW 索引,然后引入向量字段类型。
Vector Search HNSW Indexing Encoding[23]
全文检索
目前,Kvrocks 社群还没有全文搜索的设计方案。
不过,我们正在探索通过 CLucene[24] 或 PISA[25] 将全文索引纳入 KQIR 的可能性。
欢迎任何有兴趣参与的开发者分享想法或建议!
SQL 功能
未来,我们计划逐步支持更多 SQL 功能,可能包括子查询、JOIN操作、聚合函数和其他功能。
Kvrocks 的 SQL 能力主要关注的仍然是事务处理,而不是分析任务。
完整示例
首先,我们需要启动一个 Kvrocks 的实例。可以运行下述命令,启动一个 Kvrocks 的 Docker 容器:
docker run -it -p 6666:6666 apache/kvrocks:nightly --log-dir stdout当然,你也可以选择克隆 unstable 分支的最新版本代码[26],并从源码构建出 Kvrocks 二进制并运行。
成功启动 Kvrocks 实例之后,我们用 redis-cli 工具连接上实例。运行一下命令:
FT.CREATE testidx ON JSON PREFIX 1 'test:' SCHEMA a TAG b NUMERIC这个命令创建了一个名为 testidx 的索引,包括一个名为 a 的 tag 字段和名为 b numeric 字段。
然后,我们可以使用 Redis JSON 命令写入一系列的数据:
JSON.SET test:k1 $ '{"a": "x,y", "b": 11}'
JSON.SET test:k2 $ '{"a": "y,z", "b": 22}'
JSON.SET test:k3 $ '{"a": "x,z", "b": 33}'写入数据也可以在 FT.CREATE 创建索引之前,执行顺序并不会影响最终效果。
最后,我们就可以用 SQL 语句来基于刚才创建的索引,在这些数据上运行查询了:
FT.SEARCHSQL 'select * from testidx where a hastag "z" and b < 30'除了使用 SQL 查询,RediSearch 语法的查询也是支持的:
FT.SEARCH testidx '@a:{z} @b:[-inf (30]'欢迎下载试用、探索和发表反馈。
参考资料
[1]
Apache Kvrocks: https://kvrocks.apache.org/
[2]完整示例: #完整示例
[3]Apache Kvrocks 官方博客: https://kvrocks.apache.org/blog/kqir-query-engine/
[4]绝大部分 Redis 命令: https://kvrocks.apache.org/docs/supported-commands/
[5]RESP 通信协议: https://redis.io/docs/latest/develop/reference/protocol-spec/
[6]Functions: https://redis.io/docs/latest/develop/interact/programmability/functions-intro/
[7]Bloom Filter: https://redis.io/docs/latest/develop/data-types/probabilistic/bloom-filter/
[8]JSON: https://redis.io/docs/latest/develop/data-types/json/
[9]RediSearch: https://github.com/RediSearch/RediSearch
[10]对应的 Redis 命令: https://redis.io/docs/latest/operate/oss_and_stack/stack-with-enterprise/search/commands/
[11]支持各种字段类型: https://redis.io/docs/latest/develop/interact/search-and-query/basic-constructs/field-and-type-options/
[12]独特的查询语法: https://redis.io/docs/latest/develop/interact/search-and-query/advanced-concepts/query_syntax/
[13]LangChain: https://www.langchain.com/
[14]不同的方言版本: https://redis.io/docs/latest/develop/interact/search-and-query/advanced-concepts/query_syntax/#basic-syntax
[15]KQIR 框架: https://github.com/apache/kvrocks/tree/unstable/src/search
[16]LLVM 的概念和设计: https://llvm.org/docs/Passes.html
[17]llvm/clangir: https://github.com/llvm/clangir/commits?author=PragmaTwice
[18]llvm/llvm-project: https://github.com/llvm/llvm-project/commits?author=PragmaTwice
[19]Volcano 模型: https://cs-people.bu.edu/mathan/reading-groups/papers-classics/volcano.pdf
[20]另一个项目: https://github.com/apache/kvrocks/issues/2331
[21]命名空间功能: https://kvrocks.apache.org/docs/namespace/
[22]集群模式: https://kvrocks.apache.org/docs/cluster
[23]Vector Search HNSW Indexing Encoding: https://github.com/apache/kvrocks/discussions/2316
[24]CLucene: https://clucene.sourceforge.net/
[25]PISA: https://github.com/pisa-engine/pisa
[26]最新版本代码: https://github.com/apache/kvrocks/?tab=readme-ov-file#build-and-run-kvrocks