⚠申明: 未经许可,禁止以任何形式转载,若要引用,请标注链接地址。 全文共计11261字,阅读大概需要20分钟
🌈更多学习内容, 欢迎👏关注👀【文末】我的个人微信公众号:不懂开发的程序猿
⏰个人网站:https://jerry-jy.co/❗❗❗知识付费,🈲止白嫖,有需要请后台私信或【文末】个人微信公众号联系我
人工智能数学与代码实现--聚类分析
人工智能数学与代码实现–聚类分析
实验背景
聚类分析是一类将数据所对应的研究对象进行分类的统计方法。这一类方法的共同特点是,事先不知道类别的个数与结构;进行分析的数据是表明对象之间的相似性或相异性的数据,将这些数据看成对对象“距离”远近的一种度量,将距离近的对象归入一类,不同类对象之间的距离较远。系统聚类是将每个样品分成若干类的方法,其基本思想是:先将各个样品各看成一类,然后规定类与类之间的距离,选择距离最小的一对合并成新的一类,计算新类与其他类之间的距离,再将距离最近的两类合并,这样每次减少一类,直至所有的样品合为一类为止。K-means算法是很典型的基于距离的聚类算法,采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大。该算法认为簇是由距离靠近的对象组成的,因此把得到紧凑且独立的簇作为最终目标。本实验主要运用系统聚类中的最短距离法、最长距离法、类平均法和动态聚类中的K均值聚类法的理论对一些实例的应用。
实验描述
本次实验有两个数据:
basketball.csv包含三列数据,分别为256名篮球运动员的赛季场均得分(PPG)、场均篮板(RPG)和场均助攻(ARG)
数据路径为:/root/experiment/data/ basketball.csv
对该数据进行求相似系数和K均值聚类。
iris.csv 包含五列数据,分别为花萼长度(Sepal_Length),花萼宽度(Sepal_Width),花瓣长度(Petal_Length),花瓣宽度(Petal_Width),种类(Species)。
数据路径为:/root/experiment/data/ iris.csv
对该数据进行K均值聚类。
实验环境
Oracle Linux 7.4
Python 3
实验目的
基于Python实现求距离和相似系数
基于Python实现系统聚类
基于Python实现K均值(K-Means)聚类
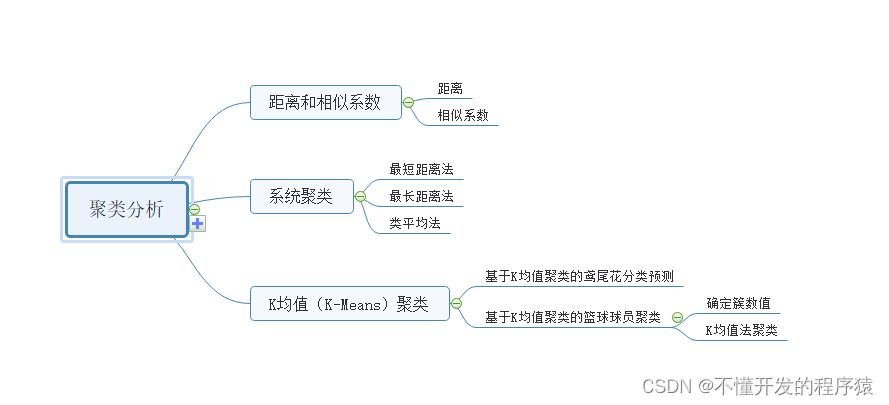
知识点
距离和相似系数
系统聚类
K均值(K-Means)聚类
实验分析
任务实施过程
一、打开Jupyter,并新建python工程
1.桌面空白处右键,点击Konsole打开一个终端
2.切换至/experiment/jupyter目录
cd experiment/jupyter
3.启动Jupyter,root用户下运行需加–allow-root
jupyter notebook --ip=127.0.0.1 --allow-root

4.依次点击右上角的 New,Python 3新建python工程
5.点击Untitled,在弹出框中修改标题名,点击Rename确认
二、距离和相似系数
1. 距离

import numpy as np
from scipy import spatial
data = np.array([[1,2,5,9,13]])
# 计算n维空间中观测值之间的距离
# pdist(X, metric='euclidean', *args, **kwargs)
# X表示需要计算距离的数据;metric表示计算距离的方法,'cityblock'表示绝对值距离。
dist1 = spatial.distance.pdist(data.T,'cityblock')
print('距离矩阵为:\n', dist1)

2. 相似系数
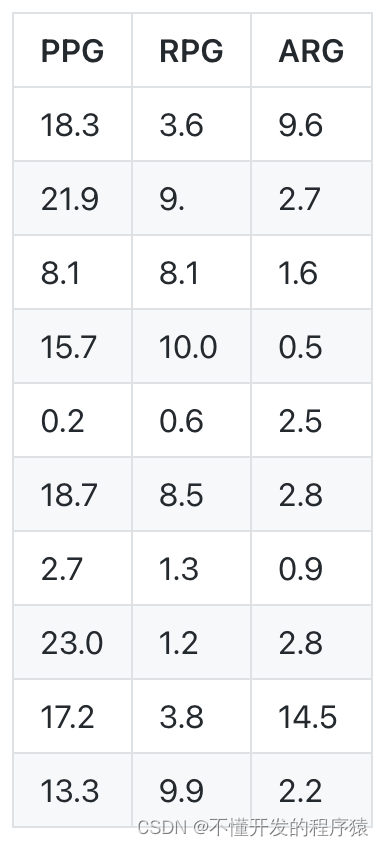
某篮球联赛共计256名篮球运动员,下表展示了他们的赛季场均得分(PPG)、场均篮板(RPG)和场均助攻(ARG)的前10条记录,整体数据保存在basketball.csv文件中(不含表头),试采用夹角余弦度量每个球员之间的相似度。
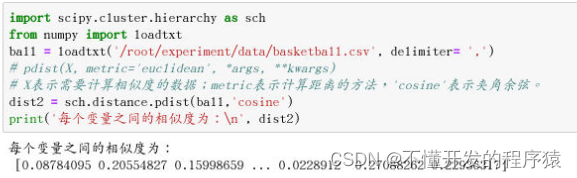
import scipy.cluster.hierarchy as sch
from numpy import loadtxt
ball = loadtxt('/root/experiment/data/basketball.csv', delimiter= ',')
# pdist(X, metric='euclidean', *args, **kwargs)
# X表示需要计算相似度的数据;metric表示计算距离的方法,'cosine'表示夹角余弦。
dist2 = sch.distance.pdist(ball,'cosine')
print('每个变量之间的相似度为:\n', dist2)
三、系统聚类
1991年辽宁等5省城镇居民月均消费数据(单位:元/人)如下表
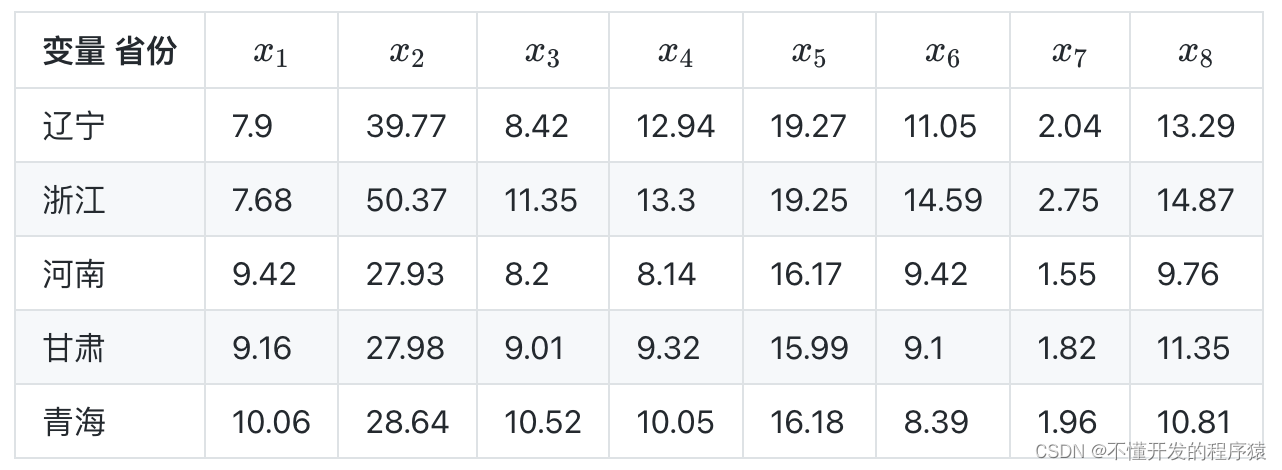
其中, x 1 x_1 x1:人均粮食支出,
x 2 x_2 x2 :人均衣着商品支出,
x 3 x_3 x3 :人均副食支出
x 4 x_4 x4:人均日用品支出,
x 5 x_5 x5 :人均烟、酒、茶支出,
x 6 x_6 x6 :人均燃料支出
x 7 x_7 x7 :人均其他副食支出,
x 8 x_8 x8 :人均非商品支出
分别采用不同的系统聚类方法对5个省份进行聚类
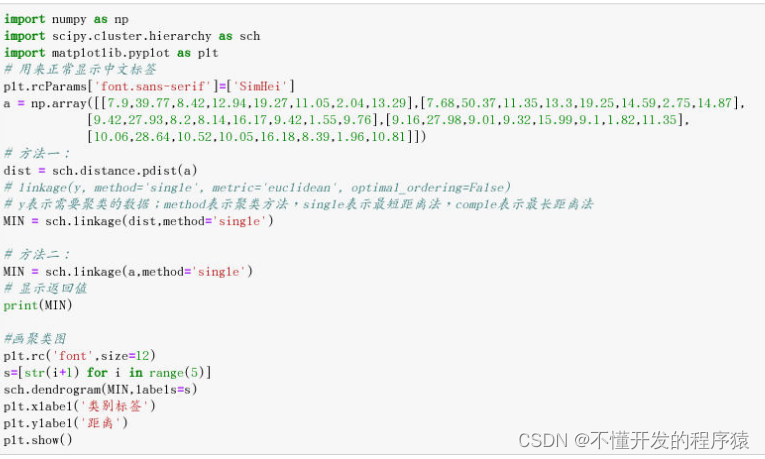
1. 最短距离法

import numpy as np
import scipy.cluster.hierarchy as sch
import matplotlib.pyplot as plt
# 用来正常显示中文标签
plt.rcParams['font.sans-serif']=['SimHei']
a = np.array([[7.9,39.77,8.42,12.94,19.27,11.05,2.04,13.29],[7.68,50.37,11.35,13.3,19.25,14.59,2.75,14.87],
[9.42,27.93,8.2,8.14,16.17,9.42,1.55,9.76],[9.16,27.98,9.01,9.32,15.99,9.1,1.82,11.35],
[10.06,28.64,10.52,10.05,16.18,8.39,1.96,10.81]])
# 方法一:
dist = sch.distance.pdist(a)
# linkage(y, method='single', metric='euclidean', optimal_ordering=False)
# y表示需要聚类的数据;method表示聚类方法,single表示最短距离法,comple表示最长距离法
MIN = sch.linkage(dist,method='single')
# 方法二:
MIN = sch.linkage(a,method='single')
# 显示返回值
print(MIN)
#画聚类图
plt.rc('font',size=12)
s=[str(i+1) for i in range(5)]
sch.dendrogram(MIN,labels=s)
plt.xlabel('类别标签')
plt.ylabel('距离')
plt.show()
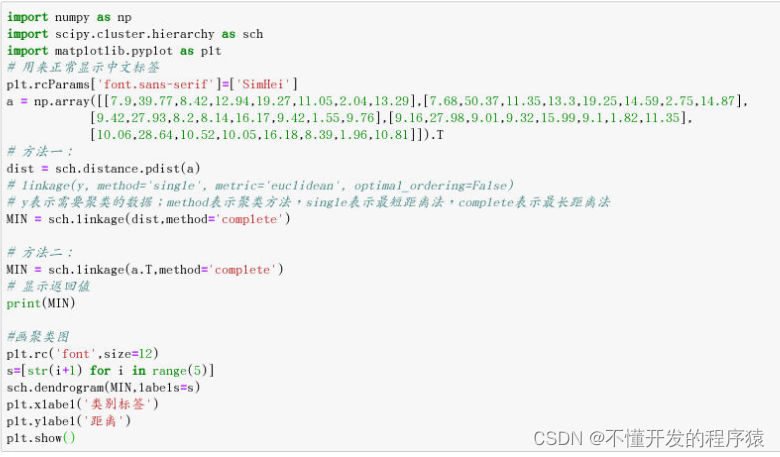
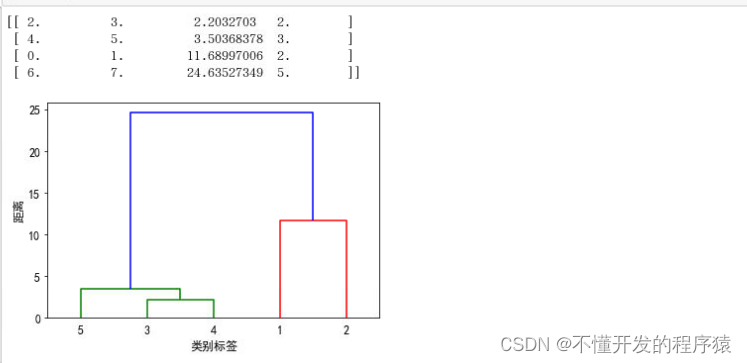
2. 最长距离法

import numpy as np
import scipy.cluster.hierarchy as sch
import matplotlib.pyplot as plt
# 用来正常显示中文标签
plt.rcParams['font.sans-serif']=['SimHei']
a = np.array([[7.9,39.77,8.42,12.94,19.27,11.05,2.04,13.29],[7.68,50.37,11.35,13.3,19.25,14.59,2.75,14.87],
[9.42,27.93,8.2,8.14,16.17,9.42,1.55,9.76],[9.16,27.98,9.01,9.32,15.99,9.1,1.82,11.35],
[10.06,28.64,10.52,10.05,16.18,8.39,1.96,10.81]])
# 方法一:
dist = sch.distance.pdist(a)
# linkage(y, method='single', metric='euclidean', optimal_ordering=False)
# y表示需要聚类的数据;method表示聚类方法,single表示最短距离法,complete表示最长距离法
MIN = sch.linkage(dist,method='complete')
# 方法二:
MIN = sch.linkage(a,method='complete')
# 显示返回值
print(MIN)
#画聚类图
plt.rc('font',size=12)
s=[str(i+1) for i in range(5)]
sch.dendrogram(MIN,labels=s)
plt.xlabel('类别标签')
plt.ylabel('距离')
plt.show()
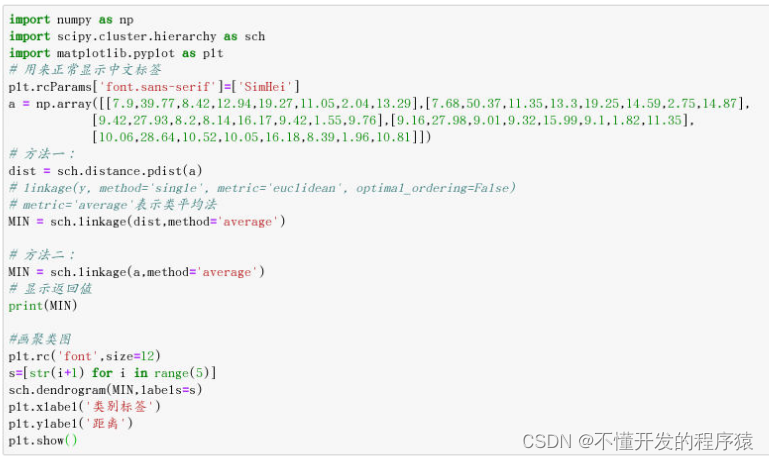
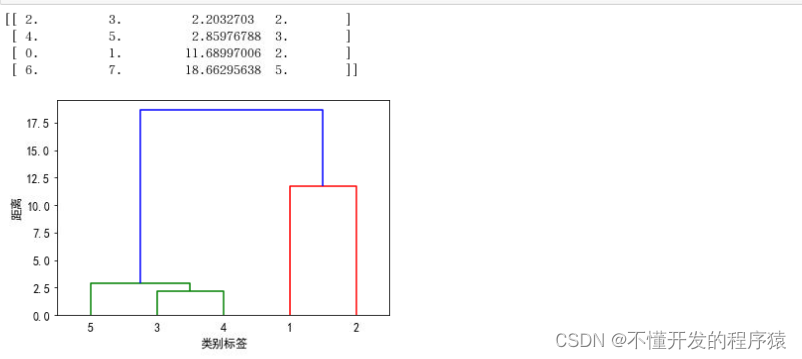
3. 类平均法

import numpy as np
import scipy.cluster.hierarchy as sch
import matplotlib.pyplot as plt
# 用来正常显示中文标签
plt.rcParams['font.sans-serif']=['SimHei']
a = np.array([[7.9,39.77,8.42,12.94,19.27,11.05,2.04,13.29],[7.68,50.37,11.35,13.3,19.25,14.59,2.75,14.87],
[9.42,27.93,8.2,8.14,16.17,9.42,1.55,9.76],[9.16,27.98,9.01,9.32,15.99,9.1,1.82,11.35],
[10.06,28.64,10.52,10.05,16.18,8.39,1.96,10.81]])
# 方法一:
dist = sch.distance.pdist(a)
# linkage(y, method='single', metric='euclidean', optimal_ordering=False)
# metric='average'表示类平均法
MIN = sch.linkage(dist,method='average')
# 方法二:
MIN = sch.linkage(a,method='average')
# 显示返回值
print(MIN)
#画聚类图
plt.rc('font',size=12)
s=[str(i+1) for i in range(5)]
sch.dendrogram(MIN,labels=s)
plt.xlabel('类别标签')
plt.ylabel('距离')
plt.show()
四、K均值(K-Means)聚类
1. 基于K均值聚类的鸢尾花分类预测
Iris也称鸢尾花卉数据集,是一类多重变量分析的数据集。数据集包含150个数据,分为3类,每类50个数据,每个数据包含4个属性。根据iris.csv数据中花萼长度,花萼宽度,花瓣长度,花瓣宽度4个属性预测鸢尾花卉属于(Setosa,Versicolour,Virginica)三个种类中的哪一类。
解析 数据集的前四个变量它们之间没有量纲上的差异,故无须对其做标准化处理,最后一个变量为鸢尾花所属的种类。
方法一:使用scipy库求解
import pandas as pd
import matplotlib.pylab as plt
import scipy.cluster.vq as vq
iris = pd.read_csv("/root/experiment/data/iris.csv")
# iloc通过行号索引
a = iris.iloc[:,:-1]
# 方法一
# kmeans2(data, k, iter=10, ...)
# data表示需要进行聚类的数据,k表示聚类的个数;iter表示迭代次数
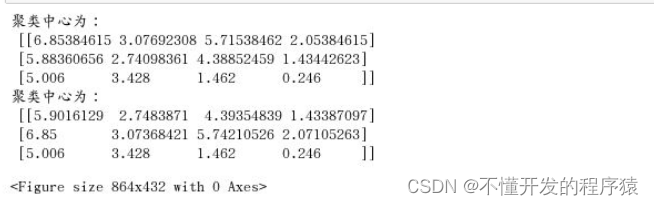
kmeans_cent1 = vq.kmeans2(a, 3)
print('聚类中心为:\n', kmeans_cent1[0])
# 方法二
# kmeans(obs, k_or_guess, iter=20, ...)
# obs表示需要进行聚类的数据,k_or_guess表示聚类的个数;iter表示迭代次数
kmeans_cent2 = vq.kmeans(a, 3)
print('聚类中心为:\n', kmeans_cent2[0])
# 画图
# 设置图片大小
plt.figure(figsize=(12, 6))
# 画出数据和聚类中心的散点图
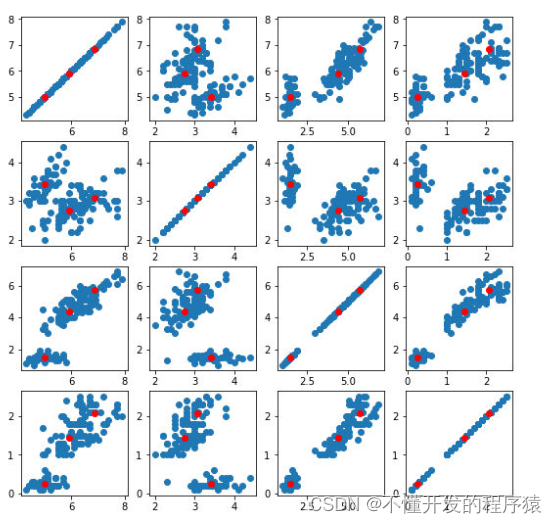
p = plt.figure(figsize=(9,9))
for i in range(4):
for j in range(4):
ax = p.add_subplot(4,4,i*4+1+j)
plt.scatter(a.iloc[:, j], a.iloc[:, i])
plt.scatter(kmeans_cent2[0][:, j], kmeans_cent2[0][:, i], c='r')
plt.show()

方法二:使用sklearn库求解
import numpy as np; import pandas as pd
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
a = pd.read_csv("/root/experiment/data/iris.csv")
# iloc通过行号索引
b = a.iloc[:,:-1]
# 构建模型并求解模型
# KMeans(n_clusters=8,init='k-means++', ...)
# n_clusters表示聚类的个数,init表示初始簇中心的获取方法
md = KMeans(3)
md.fit(b)
# 获取聚类标签
labels=md.labels_
# 获取聚类中心
centers=md.cluster_centers_
# 数据框b添加一个列变量cluster 数据为聚类标签
b['cluster']=labels
# cluster中各类频数统计
c=b.cluster.value_counts()
# 画图
# 设置图片大小
plt.figure(figsize=(12, 6))
# 用来正常显示中文标签
plt.rc('font',family='SimHei')
# 设置字体大小
plt.rc('font',size=12)
# 对比建模后的3类与原始3类的差异,绘制花瓣长度与宽度的散点图
# markersize设置点的大小;plt.legend()loc设置图例位置,可以填入字符串或者数字
plt.subplot(121)
str1=['^r','.k','*b']
for i in range(len(centers)):
plt.plot(b['Petal_Length'][labels==i],b['Petal_Width']
[labels==i], str1[i],markersize=3,label=str(i))
plt.legend(loc=2)
plt.xlabel("(a)KMeans聚类结果")
plt.subplot(122)
str2=['setosa','versicolour','virginica']
ind=np.hstack([np.zeros(50),np.ones(50),2*np.ones(50)])
for i in range(3):
plt.plot(b['Petal_Length'][ind==i],b['Petal_Width'][ind==i],
str1[i],markersize=3,label=str2[i])
plt.legend(loc=2)
plt.xlabel("(b)原数据的类别")
plt.show()
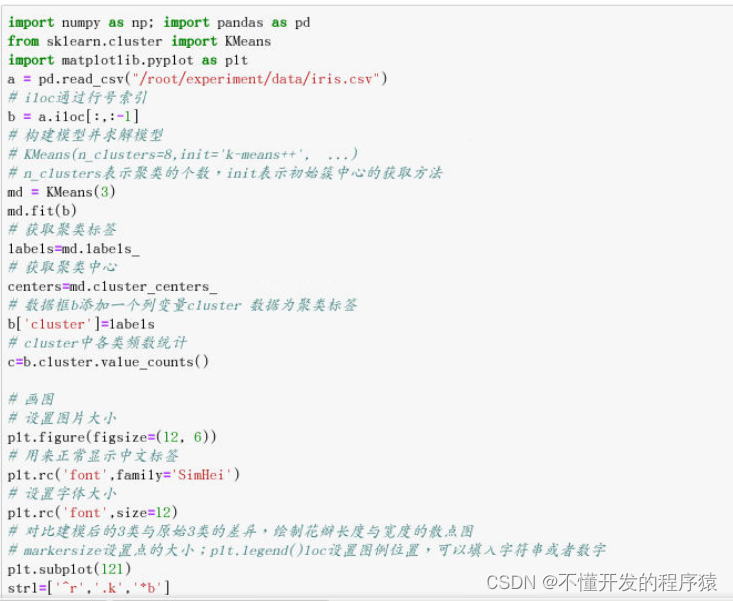

以上为原始数据的散点图,与聚类图对比,标记为0的与原始数据吻合,1和2存在一些错误分割,但还是比较一致
2. 基于K均值聚类的篮球球员聚类
某篮球联赛共计256名篮球运动员,basketball.csv文件包含他们的赛季场均得分(PPG)、场均篮板(RPG)和场均助攻(ARG)数据。试采用K均值聚类法对球员进行聚类。聚类簇数k由轮廓系数法确定
(1)确定簇数值
import numpy as np; import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn import metrics
ball=np.loadtxt('/root/experiment/data/basketball.csv', delimiter= ',')
S=[]; K=10
# 轮廓系数法接受的聚类簇数必须大于等于2
for k in range(2,K+1):
md = KMeans(k)
md.fit(ball)
labels = md.labels_
# 计算轮廓系数
# silhouette_score(X, labels, metric='euclidean',...)
# X表示需要计算的数据;labels表示数据标签;metric表距离的计算方法,默认为欧式距离法
S.append(metrics.silhouette_score(ball,labels,metric='euclidean'))
# 画图
plt.rc('font',size=12)
# 用来正常显示中文标签
plt.rc('font',family='SimHei')
plt.plot(range(2,K+1), S, 'b*-')
plt.xlabel('簇的个数')
plt.ylabel('轮廓系数')
plt.show()

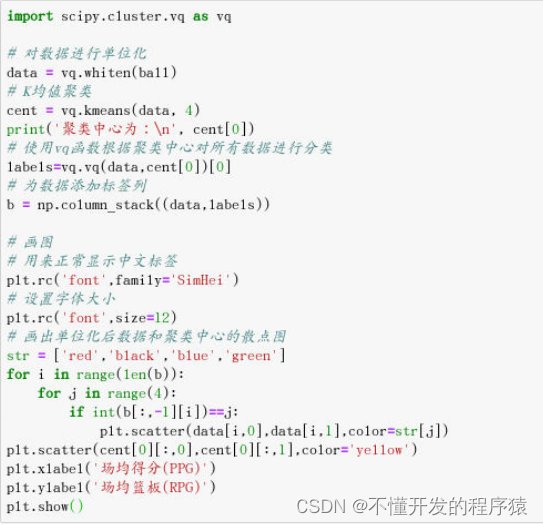
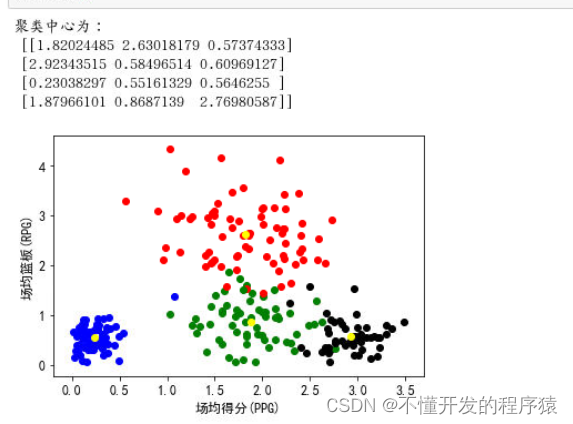
(2)K均值法聚类(需要对数据进行单位化)
方法一:使用scipy库求解
import scipy.cluster.vq as vq
# 对数据进行单位化
data = vq.whiten(ball)
# K均值聚类
cent = vq.kmeans(data, 4)
print('聚类中心为:\n', cent[0])
# 使用vq函数根据聚类中心对所有数据进行分类
labels=vq.vq(data,cent[0])[0]
# 为数据添加标签列
b = np.column_stack((data,labels))
# 画图
# 用来正常显示中文标签
plt.rc('font',family='SimHei')
# 设置字体大小
plt.rc('font',size=12)
# 画出单位化后数据和聚类中心的散点图
str = ['red','black','blue','green']
for i in range(len(b)):
for j in range(4):
if int(b[:,-1][i])==j:
plt.scatter(data[i,0],data[i,1],color=str[j])
plt.scatter(cent[0][:,0],cent[0][:,1],color='yellow')
plt.xlabel('场均得分(PPG)')
plt.ylabel('场均篮板(RPG)')
plt.show()
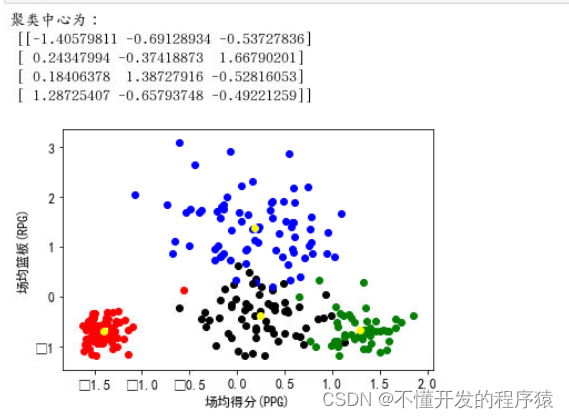
方法二:使用sklearn库求解
from sklearn.cluster import KMeans
from sklearn.preprocessing import scale
# 对数据进行单位化
a = scale(ball)
# 构建模型
md = KMeans(4)
md.fit(a)
# 获取聚类标签
labels=md.labels_
# 获取聚类中心
centers=md.cluster_centers_
print('聚类中心为:\n',centers)
# 为数据添加标签列
b = np.column_stack((a,labels))
# 画图
# 用来正常显示中文标签
plt.rc('font',family='SimHei')
# 设置字体大小
plt.rc('font',size=12)
# 画出单位化后数据和聚类中心的散点图
str = ['red','black','blue','green']
for i in range(len(b)):
for j in range(4):
if int(b[:,-1][i])==j:
plt.scatter(a[i,0],a[i,1],color=str[j])
plt.scatter(centers[:,0],centers[:,1],color='yellow')
plt.xlabel('场均得分(PPG)')
plt.ylabel('场均篮板(RPG)')
plt.show()

实验总结
本实验主要通过使用Python的SciPy、sklearn工具库,实现了基于距离和相似系数、系统聚类、K均值聚类原理的应用以及Python实现。
–end–
说明
本实验(项目)/论文若有需要,请后台私信或【文末】个人微信公众号联系我