文章目录
前言
最近,我们的一个只有三台DataNode节点的HDFS集群发生写故障。从客户端的异常来看,这个问题的发生与块分配有关。
我们知道,HDFS客户端在写文件的时候,NameNode会为文件的文件款分配Host,客户端收到块的分配结果以后,会往对应的DataNode上写文件。当DataNode将块信息汇报给NameNode以后,对应的块到达最终Finalized状态。因此,写文件过程中的块分配异常至少存在两种可能情况,一种情况是NameNode无法为节点选择足够的3副本的存储块,也由可能是分配了块但是DataNode出于某种原因迟迟没有汇报给给NameNode。
本文记录了这次事故发生以后的排查过程,以及后续所采取的相关措施。同时,为了梳理事故发生的过程,让事故发生过程中的各个细节能够完全相互自洽,我们进行了代码层面的原因分析和事故定位,将事故发生的代码缩小到一个方法的范围内,从而针对性的添加日志,这样如果事故再次发生,能够捕获根本原因,采取正确措施。
总之,在技术层面,我们总结出,如果NameNode为一个块分配机器失败(即集群中没有找到足够的DataNode存放这个Block的Replica),那么所有可选的DataNode被放弃只有以下可能:
- 机器问题
- 节点处于特殊的状态: 这个节点是否是inService的状态。所有与DECOMISSION和MAINTENANCE相关的状态都不是inService状态。这种状态一般是手动触发的。
- 节点长时间没有心跳:如果需要避开stale节点并且当前节点已经处于stale状态(超过了指定时间还没有收到心跳),那么会被认为是bad node而不再考虑。比如,长时间不断的FGC会导致心跳延迟。
- 节点连接负载过大:那么这个DataNode的xceiverCount超过了最大允许的负载,那么会被认为是bad node而不再考虑。
- 机架上为这个Block已经分配的机器过多: 如果使用这个节点,会导致这个节点所在的机架上为这个Block分配的总的副本数已经超过我们所计算的、最大允许的单机架的节点数,那么这个节点会被放弃
- 机器的存储问题
- 这个机器上没有一个合适的StorageType来存放文件,或者,尽管有,但是对应StorageType的所有存储总量,除去预留的(已调度但是还未汇报),已无法存放这个副本
同时,对于事故的处理,我认识到,很多第一次发生的线上事故会由于现场的缺乏,监控的缺失,日志级别过高等原因,我们无法从已有的信息中得知事故发生的根本原因,但是经过仔细的调查,包括日志分析,代码对照,我们一定可以做以下几种事:
- 存疑的参数,我们可以进行优化调整,尽量避免事故再次发生;
- 详细的阅读代码,结合有限的日志,将事故发生的原因定位在一个极小的范围内;
- 添加缺失的Dashboard:有些Dashboard所依赖的metrics还需要我们修改代码手动加上;
- 通过添加日志、详细规划出事故再发生时的操作步骤(现场保存,日志备份,临时打开DEBUG)等,保证在事故第二次发生的时候,准确捕捉现场,获取根本原因,从而从根本上解决问题。
事故分析:
我们首先看到的是用户端的报错日志:
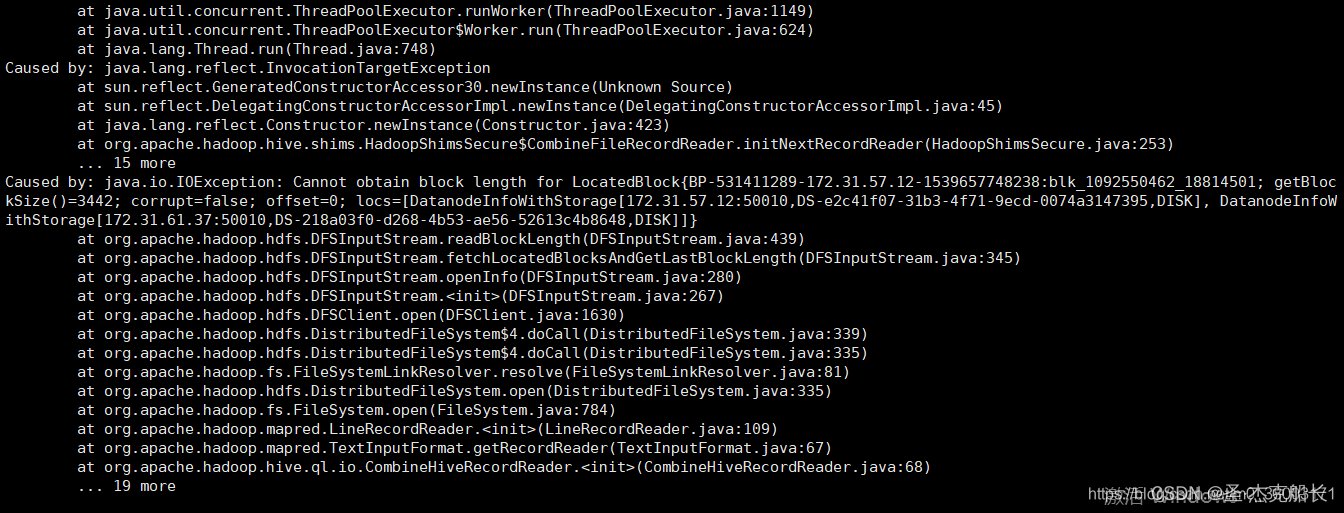
|-> StorageIOError from StorageIOFileWriter: HdfsCliError from StorageIO: Shell command error from HdfsCli!: Command 'hadoop fs -put -f /tmp/2024/05/27/02/01/partition-4-part-0.parquet_rSM /tlb2/aa-1min-output-preprod/tmp/2024/05/27/02/01/partition-4-part-0.parquet' failed with exit code: 1 24/05/27 02:03:53 WARN hdfs.DFSClient: DataStreamer Exception org.apache.hadoop.ipc.RemoteException(java.io.IOException): File /aa-1min-output-preprod/tmp/2024/05/27/02/01/partition-4-part-0.parquet._COPYING_ could only be replicated to 0 nodes instead of minReplication (=1). There are 3 datanode(s) running and no node(s) are excluded in this operation. at org.apache.hadoop.hdfs.server.blockmanagement.BlockManager.chooseTarget4NewBlock(BlockManager.java:1720) at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.getAdditionalBlock(FSNamesystem.java:3389) at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.addBlock(NameNodeRpcServer.java:683) at org.apache.hadoop.hdfs.server.namenode.AuthorizationProviderProxyClientProtocol.addBlock(AuthorizationProviderProxyClientProtocol.java:214) at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.addBlock(ClientNamenodeProtocolServerSideTranslatorPB.java:495) at org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtocolProtos.java) at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:617)从上面的日志,我们基本上可以确定,在用户写文件的过程中,无法为Block选定足够的三副本:
在NameNode这一端,我们首先看到的日志报错是这样的:
2024-05-26 23:49:39,990 WARN org.apache.hadoop.ipc.Server: Requested data length 86697796 is longer than maximum configured RPC length 67108864. RPC came from 10.8.4.105 2024-05-26 23:49:39,990 INFO org.apache.hadoop.ipc.Server: Socket Reader #1 for port 8022: readAndProcess from client 10.8.4.105 threw exception [java.io.IOException: Requested data length 86697796 is longer than maximum configured RPC length 67108864. RPC came from 10.8.4.105] java.io.IOException: Requested data length 86697796 is longer than maximum configured RPC length 67108864. RPC came from 10.8.4.105 at org.apache.hadoop.ipc.Server$Connection.checkDataLength(Server.java:1601) at org.apache.hadoop.ipc.Server$Connection.readAndProcess(Server.java:1663) at org.apache.hadoop.ipc.Server$Listener.doRead(Server.java:887) at org.apache.hadoop.ipc.Server$Listener$Reader.doRunLoop(Server.java:751) at org.apache.hadoop.ipc.Server$Listener$Reader.run(Server.java:722)- 然后我们看DataNode端日志,发现了与NameNode端相互对应的报错日志:
2024-05-27 02:54:04,611 WARN org.apache.hadoop.hdfs.server.datanode.DataNode: IOException in offerService java.io.EOFException: End of File Exception between local host is: "rccp103-2a.iad5.prod.conviva.com/10.8.2.105"; destination host is: "rccp104-5d.iad5.prod.conviva.com":8022; : java.io.EOFException; For more details see: http://wiki.apache.org/hadoop/EOFException at sun.reflect.GeneratedConstructorAccessor24.newInstance(Unknown Source) at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45) at java.lang.reflect.Constructor.newInstance(Constructor.java:423) at org.apache.hadoop.net.NetUtils.wrapWithMessage(NetUtils.java:791) at org.apache.hadoop.net.NetUtils.wrapException(NetUtils.java:764) at org.apache.hadoop.ipc.Client.call(Client.java:1508) at org.apache.hadoop.ipc.Client.call(Client.java:1441) at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:230) at com.sun.proxy.$Proxy20.blockReport(Unknown Source) at org.apache.hadoop.hdfs.protocolPB.DatanodeProtocolClientSideTranslatorPB.blockReport(DatanodeProtocolClientSideTranslatorPB.java:204) at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.blockReport(BPServiceActor.java:323) at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.offerService(BPServiceActor.java:561) at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.run(BPServiceActor.java:695) at java.lang.Thread.run(Thread.java:748) Caused by: java.io.EOFException at java.io.DataInputStream.readInt(DataInputStream.java:392) at org.apache.hadoop.ipc.Client$Connection.receiveRpcResponse(Client.java:1113) at org.apache.hadoop.ipc.Client$Connection.run(Client.java:1006)从日志分析来看,不经过特别仔细的分析,似乎就是我们客户端写文件失败的根本原因:块汇报失败。我们简单看了一下代码,对这个问题的解决方案很简单,增大NameNode端允许的最大RPC,同时,由于我们后来发现DataNode端对大的RPC请求有对应的切分策略,因此,我们需要降低这个触发切分的阈值。
- 增大NameNode端最大允许的RPC大小,当前的最大值为64MB,日志中看到实际汇报的大小超过了80MB,因此这个RPC BlockReport被拒绝。因此我们调整为128MB:
在NameNode的ipc.Server启动的时候就设置了这个最大允许的阈值,通过ipc.maximum.data.length配置,默认64M:protected Server(String bindAddress, int port, Class<? extends Writable> rpcRequestClass, int handlerCount, int numReaders, int queueSizePerHandler, Configuration conf, String serverName, SecretManager<? extends TokenIdentifier> secretManager, String portRangeConfig) .... this.maxDataLength = conf.getInt(CommonConfigurationKeys.IPC_MAXIMUM_DATA_LENGTH, CommonConfigurationKeys.IPC_MAXIMUM_DATA_LENGTH_DEFAULT); - 同时,在DataNode端,我们发现在进行blockReport的时候其实会进行切分,因此,我们打算降低最大允许的块汇报数量,默认值是100K,我们降低为20K:
List<DatanodeCommand> blockReport(long fullBrLeaseId) throws IOException { StorageBlockReport reports[] = new StorageBlockReport[perVolumeBlockLists.size()]; for(Map.Entry<DatanodeStorage, BlockListAsLongs> kvPair : perVolumeBlockLists.entrySet()) { BlockListAsLongs blockList = kvPair.getValue(); reports[i++] = new StorageBlockReport(kvPair.getKey(), blockList); totalBlockCount += blockList.getNumberOfBlocks(); } try { if (totalBlockCount < dnConf.blockReportSplitThreshold) { // Below split threshold, send all reports in a single message. DatanodeCommand cmd = bpNamenode.blockReport( bpRegistration, bpos.getBlockPoolId(), reports, new BlockReportContext(1, 0, reportId, fullBrLeaseId, true)); ... } else { // Send one block report per message. for (int r = 0; r < reports.length; r++) { StorageBlockReport singleReport[] = { reports[r] }; DatanodeCommand cmd = bpNamenode.blockReport( bpRegistration, bpos.getBlockPoolId(), singleReport, new BlockReportContext(reports.length, r, reportId, fullBrLeaseId, true)); ...... } } success = true; } finally { ...... } scheduler.scheduleNextBlockReport(); return cmds.size() == 0 ? null : cmds; }
可以看到,这个切分并不是我们直观所理解的,即如果BlockReport的总数量大于这个threshold,那么就分批次进行report,每次最多threshold个block进行report。其实,其切分方式为:
创建一个 StorageBlockReport reports[] 数组,数组中的每一个元素代表了一个Volume的所有需要Report的Block;
统计这个DataNode的所有Storage的所有Block的数量,即reports[]中的数据总量:
- 如果总量小于Threshold,那么不用进行切分,一次性将reports中存放的所有volume的数据全部发送给远程的NameNode
- 如果总量大于Threashold,那么会进行切分,但是不是均匀切分,只是每一个Storage单独进行BlockReport。
所以,用户由于副本没有分配到Location而写入失败,而HDFS服务器端的确有持续的块汇报失败,这个块汇报失败看起来似乎会让NameNode认为块没有写成功,因此二者似乎是互为因果关系,我们基本认为通过上述参数调整,就可以解决写入失败问题。
但是在用户汇报问题的时候,我们通过简单的写入操作,发现写入成功,即副本选择没问题,副本往DataNode写入没问题,DataNode将副本汇报给NameNode也没问题。
在NamNode端,我们看到的对应写失败的直接INFO日志是这样的:
2024-05-27 01:58:38,472 WARN org.apache.hadoop.hdfs.server.blockmanagement.BlockPlacementPolicy: Failed to place enough replicas, still in need of 3 to reach 3 (unavailableStorages=[], storagePolicy=BlockStoragePolicy{HOT:7, storageTypes=[DISK], creationFallbacks=[], replicationFallbacks=[ARCHIVE]}, newBlock=true) For more information, please enable DEBUG log level on org.apache.hadoop.hdfs.server.blockmanagement.BlockPlacementPolicy and org.apache.hadoop.net.NetworkTopology 2024-05-27 01:58:38,472 WARN org.apache.hadoop.hdfs.protocol.BlockStoragePolicy: Failed to place enough replicas: expected size is 3 but only 0 storage types can be selected (replication=3, selected=[], unavailable=[DISK], removed=[DISK, DISK, DISK], policy=BlockStoragePolicy{HOT:7, storageTypes=[DISK], creationFallbacks=[], replicationFallbacks=[ARCHIVE]}) 2024-05-27 01:58:38,472 WARN org.apache.hadoop.hdfs.server.blockmanagement.BlockPlacementPolicy: Failed to place enough replicas, still in need of 3 to reach 3 (unavailableStorages=[DISK], storagePolicy=BlockStoragePolicy{HOT:7, storageTypes=[DISK], creationFallbacks=[], replicationFallbacks=[ARCHIVE]}, newBlock=true) All required storage types are unavailable: unavailableStorages=[DISK], storagePolicy=BlockStoragePolicy{HOT:7, storageTypes=[DISK], creationFallbacks=[], replicationFallbacks=[ARCHIVE]} 2024-05-27 01:58:38,472 WARN org.apache.hadoop.security.UserGroupInformation: PriviledgedActionException as:tlb2 (auth:SIMPLE) cause:java.io.IOException: File /tlb2/aa-1min-output-preprod/tmp/2024/05/27/01/57/partition-205-part-0.parquet._COPYING_ could only be replicated to 0 nodes instead of minReplication (=1). There are 3 datanode(s) running and no node(s) are excluded in this operation. 2024-05-27 01:58:38,472 INFO org.apache.hadoop.ipc.Server: IPC Server handler 27 on 8020, call org.apache.hadoop.hdfs.protocol.ClientProtocol.addBlock from 10.9.6.116:52208 Call#5 Retry#0 java.io.IOException: File /tlb2/aa-1min-output-preprod/tmp/2024/05/27/01/57/partition-205-part-0.parquet._COPYING_ could only be replicated to 0 nodes instead of minReplication (=1). There are 3 datanode(s) running and no node(s) are excluded in this operation. at org.apache.hadoop.hdfs.server.blockmanagement.BlockManager.chooseTarget4NewBlock(BlockManager.java:1720) at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.getAdditionalBlock(FSNamesystem.java:3389) at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.addBlock(NameNodeRpcServer.java:683) at org.apache.hadoop.hdfs.server.namenode.AuthorizationProviderProxyClientProtocol.addBlock(AuthorizationProviderProxyClientProtocol.java:214) at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.addBlock(ClientNamenodeProtocolServerSideTranslatorPB.java:495) at org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtocolProtos.java) at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:617) at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:1073) at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2217) at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2213) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:422) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1917) at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2211)我们从日志基本可以看到,客户端调用了ClientNamenodeProtocol的addBlock()接口,这个接口会触发NameNode端选择指定副本数量的DataNode用来存放这个Block的Replica,由于在集群中没有选出任何有效机器,因此报错。
基于机器选择对应的堆栈如下所示,我们在下文源码解析部分会详细解析这个选择过程:
at org.apache.hadoop.hdfs.server.blockmanagement.BlockPlacementPolicyDefault.chooseRandom(BlockPlacementPolicyDefault.java:745) at org.apache.hadoop.hdfs.server.blockmanagement.BlockPlacementPolicyDefault.chooseRandom(BlockPlacementPolicyDefault.java:666) at org.apache.hadoop.hdfs.server.blockmanagement.BlockPlacementPolicyDefault.chooseLocalRack(BlockPlacementPolicyDefault.java:573) at org.apache.hadoop.hdfs.server.blockmanagement.BlockPlacementPolicyDefault.chooseLocalStorage(BlockPlacementPolicyDefault.java:533) at org.apache.hadoop.hdfs.server.blockmanagement.BlockPlacementPolicyDefault.chooseTargetInOrder(BlockPlacementPolicyDefault.java:437) at org.apache.hadoop.hdfs.server.blockmanagement.BlockPlacementPolicyDefault.chooseTarget(BlockPlacementPolicyDefault.java:368) at org.apache.hadoop.hdfs.server.blockmanagement.BlockPlacementPolicyDefault.chooseTarget(BlockPlacementPolicyDefault.java:243) at org.apache.hadoop.hdfs.server.blockmanagement.BlockPlacementPolicyDefault.chooseTarget(BlockPlacementPolicyDefault.java:115) at org.apache.hadoop.hdfs.server.blockmanagement.BlockPlacementPolicyDefault.chooseTarget(BlockPlacementPolicyDefault.java:131) at org.apache.hadoop.hdfs.server.blockmanagement.BlockManager.chooseTarget4NewBlock(BlockManager.java:1716) at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.getAdditionalBlock(FSNamesystem.java:3389) at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.addBlock(NameNodeRpcServer.java:683)
其实这时候,如果对HDFS的底层实现有了解,已经会发现一些逻辑上的悖论了:
- 其实块汇报失败导致的问题是块无法汇报,但是客户端的报错其实是无法为块分配到足够的副本。所以,尽管系统存在块汇报的问题,但是这个问题并不是客户端写失败的直接原因,二者无直接因果关系。如果是FBR失败导致问题,那么这个问题应该可以重现,但是我们自行写入文件是成功的。
- 我们后面通过分析代码发现,这里服务端异常所打印的块汇报,是FBR(Full Block Report),而FBR的失败完全不会影响IBR(Incremental Block Report),即不仅块分配不会受影响,块写完以后的IBR也不会受到持续的FBR失败的影响。
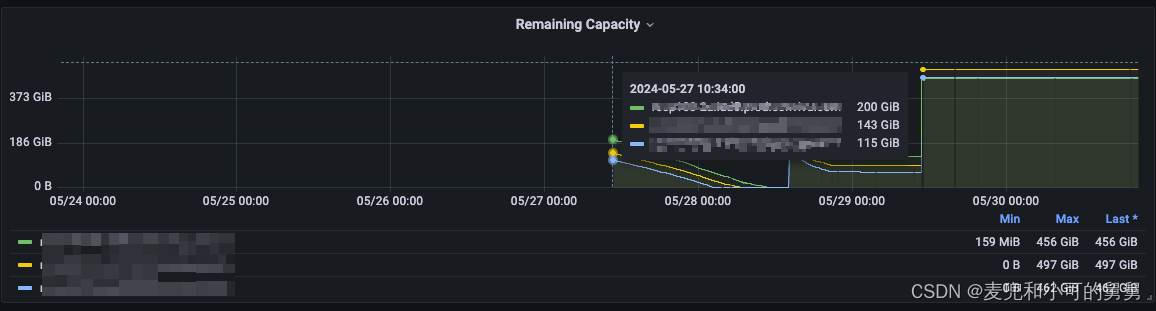
但是我们由于通过基础判断,认为用户端写失败是由FBR问题导致。我们在用户反馈问题以后,为这个集群构建了详细的Dashboard,但是遗憾的是,事故发生的时候的集群状况我们无法获知。但是我们从Dashboard中关于DataNode剩余容量可以看到,这个集群的DataNode容量后来有几次几乎快要耗尽,我们从后来的代码分析可以看到,DataNode容量耗尽会让NameNode不再选择该DataNode放置副本,如果所有DataNode都有同样问题,那么副本放置失败。
无奈之下,用户将业务逻辑先行迁移到其他HDFS集群。同时,在进行参数调整以后,我们滚动重启了集群。重启以后,FBR失败问题解决,测试写,未见异常(写恢复和FBR问题解决并无关系,可能只是集群有了剩余容量)。在对用户的数据进行了适当清理以后,用户业务迁移回当前集群,未见问题。
在本次事故中,由于监控缺乏,日志缺乏,我们无法确定当时失败的根本原因,但是经过代码分析,增加监控,梳理事故再发生的处理流程,我们已经可以确信在类似事故再次发生的时候准确定位原因从而解决问题。
代码解析
BlockReport的调度和时机
在这里,我们最终确认,FBR和IBR的汇报不会相互干扰,即使FBR失败,IBR也会正常进行。用户新写入的文件是通过IBR汇报的。
DataNode启动的时候,会为每一个NameService(注意不是NameNode)创建一个对应的BPOfferService,在BPOfferService中,会为这个NameService的每一个NameNode创建一个对应的BPServiceActor,每一个BPServiceActor就是一个独立线程,用来向对应的Active/Standby NameNode进行BlockReport
// NameNode启动或者有新的NameService加入进来的时候,会调用这个方法以创建对应的NameService的ActorService
private void doRefreshNamenodes(
Map<String, Map<String, InetSocketAddress>> addrMap) throws IOException {
....
// 对于每一个NameService,创建一个BPOfferService
for (String nsToAdd : toAdd) {
ArrayList<InetSocketAddress> addrs =
Lists.newArrayList(addrMap.get(nsToAdd).values());
BPOfferService bpos = createBPOS(addrs);
bpByNameserviceId.put(nsToAdd, bpos);
offerServices.add(bpos);
}
}
/**
* 为这个NameService创建一个BPOfferService
*/
protected BPOfferService createBPOS(List<InetSocketAddress> nnAddrs) {
return new BPOfferService(nnAddrs, dn);
}
/**
* 为这个NameService的每一个NameNode创建一个BPServiceActor
* @param nnAddrs
* @param dn
*/
BPOfferService(List<InetSocketAddress> nnAddrs, DataNode dn) {
......
for (InetSocketAddress addr : nnAddrs) {
this.bpServices.add(new BPServiceActor(addr, this));
}
}
在一个BPServiceActor启动以后,就会不断循环进行IBR、FBR和心跳的调度。调度的运行代码在BPServiceActor的offerService()方法中:
private void offerService() throws Exception {
long fullBlockReportLeaseId = 0;
while (shouldRun()) {
try {
final long startTime = scheduler.monotonicNow();
// heartbeat间隔是3s
final boolean sendHeartbeat = scheduler.isHeartbeatDue(startTime);
HeartbeatResponse resp = null;
if (sendHeartbeat) {
boolean requestBlockReportLease = (fullBlockReportLeaseId == 0) &&
scheduler.isBlockReportDue(startTime);
if (!dn.areHeartbeatsDisabledForTests()) {
resp = sendHeartBeat(requestBlockReportLease);
// 获取NameNode所grant的FBR的lease id
fullBlockReportLeaseId = resp.getFullBlockReportLeaseId();
.....
}
}
if (ibrManager.sendImmediately() || sendHeartbeat) {
ibrManager.sendIBRs(bpNamenode, bpRegistration,
bpos.getBlockPoolId(), dn.getMetrics()); // 发送IBR请求
}
List<DatanodeCommand> cmds = null;
boolean forceFullBr =
scheduler.forceFullBlockReport.getAndSet(false);
// 如果 fullBlockReportLeaseId 不等于0,或者虽然等于0,但是forceFullBr为true
if ((fullBlockReportLeaseId != 0) || forceFullBr) {
cmds = blockReport(fullBlockReportLeaseId); // 进行 FBR
fullBlockReportLeaseId = 0; // 做完一次fbr以后,block report lease重置为0,下次再进行fbr的时候,需要重新向NameNode申请
}
processCommand(cmds == null ? null : cmds.toArray(new DatanodeCommand[cmds.size()]));
// sleep,直到下一次ibr的时间时机到来,或者readyToSend = true,或者中途被直接强行唤醒
ibrManager.waitTillNextIBR(scheduler.getHeartbeatWaitTime());
} catch(RemoteException re) {
......
} // while (shouldRun())
} // offerService
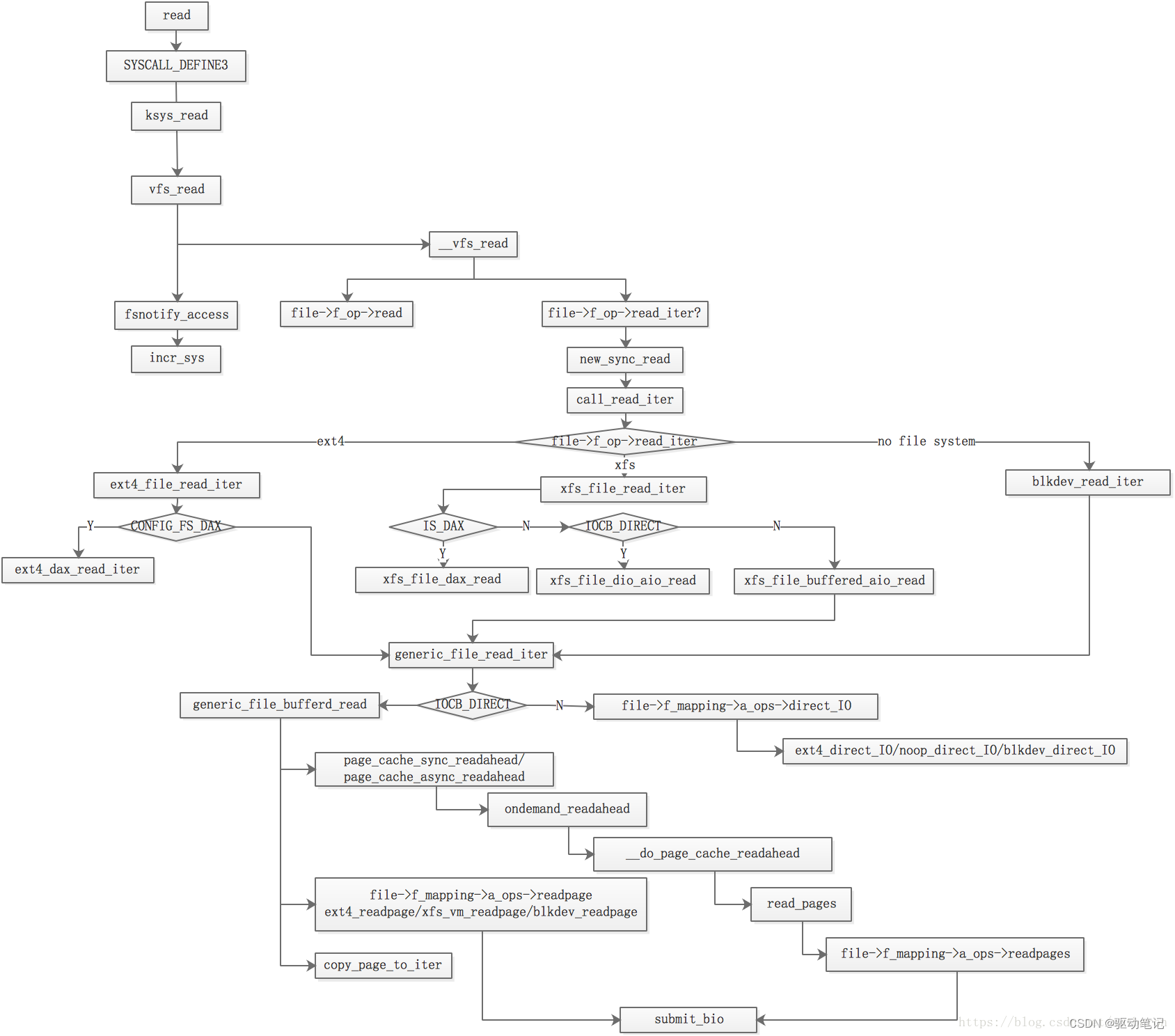
具体调度流程如下图所示:
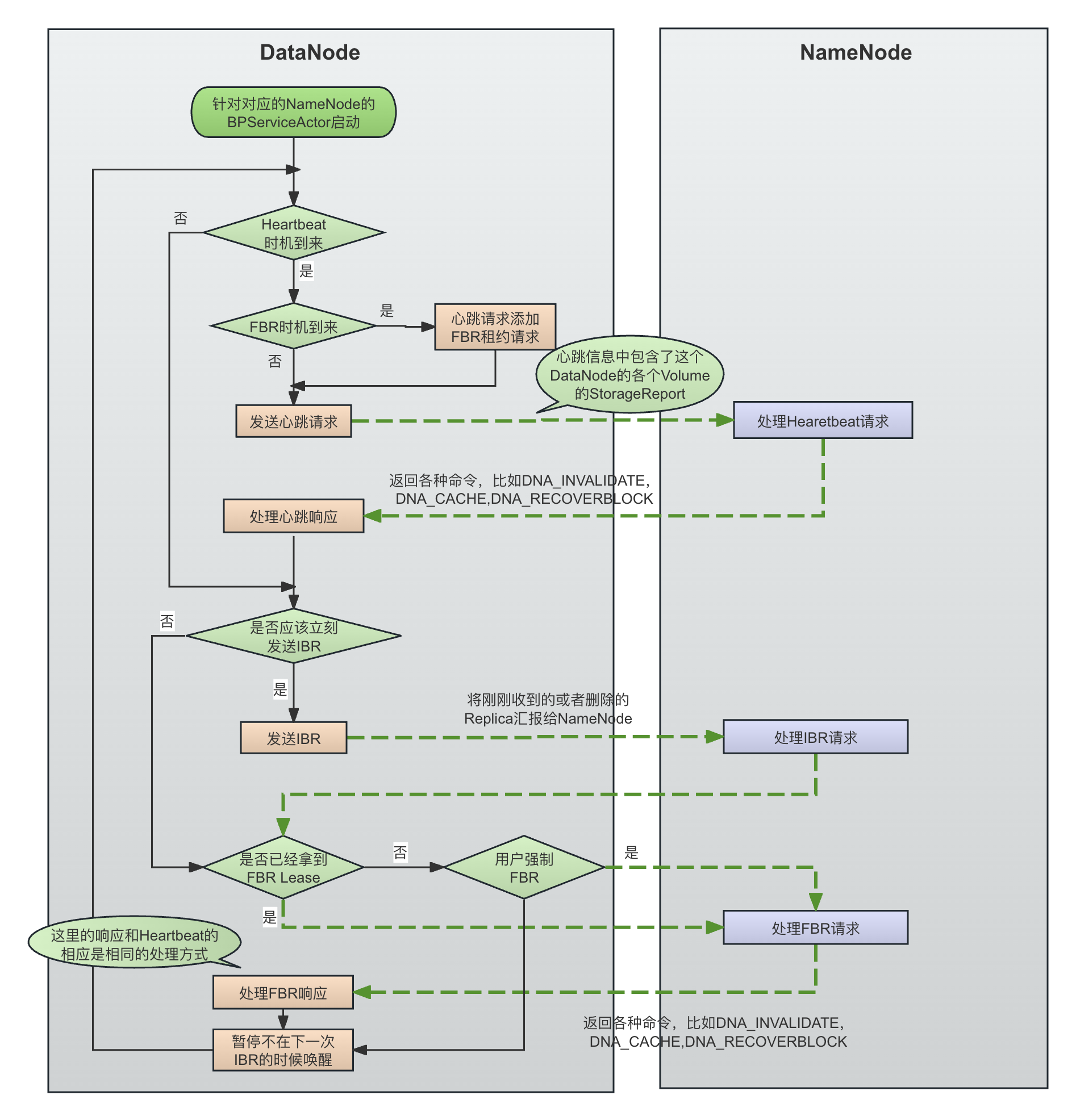
看到这里,我们就会疑问,客户端在写文件的时候,当一个Replica在DataNode写入完毕,Client肯定希望这个Block立刻汇报给NameNode,而不是还需要等待一个调度时机的到来才能在NameNode端确认写成功。这是通过关键的waitTillNextIBR()实现的,下面会讲到,waitTillNextIBR()并不是进行简单的定时等待:
-------------------------------- IncrementalBlockReportManager.java -----------------------------------------------
synchronized void waitTillNextIBR(long waitTime) {
if (waitTime > 0 && !sendImmediately()) {
wait(ibrInterval > 0 && ibrInterval < waitTime? ibrInterval: waitTime);
}
}
boolean sendImmediately() {
return readyToSend && monotonicNow() - ibrInterval >= lastIBR;
}
可以看到
- waitTillNextIBR()会首先通过sendImmediately()判断是否需要立刻发送IBR,如果是立刻发送,那么无需等待
- 如果不需要立刻发送,那么会通过
wait()(不是sleep())进行等待,等待的时长是传入到sleepInterval和ibrInterval的较小值。同时,方法waitTillNextIBR() 是拿到waitTillNextIB()是持有IncrementalBlockReportManager()的对象锁然后进行wait(),显然,这个wait()是可以通过notify()被中断的,比如,一个Block写成完成,这是需要立刻汇报给NameNode的,而不能等待waitTillNextIBR()完全根据时间去退出wait(),否则,客户端的写入操作将会存在空等。
waitTillNextIBR()被唤醒是通过triggerIBR()进行的。注意,triggerIBR()并不是在其调用者的线程进行blockReport,只是通过干预BPServiceActor的等待,来达到提前或者立刻进行IBR的目的:-------------------------------- IncrementalBlockReportManager.java ----------------------------------------------- synchronized void triggerIBR(boolean force) { readyToSend = true; if (force) { lastIBR = monotonicNow() - ibrInterval; } if (sendImmediately()) { notifyAll(); // 唤醒所有在当前的IncrementalBlockReportManager对象锁上等待的线程 } }
我们从triggerIBR()的调用堆栈以看到立刻trigger发生的情况:

- DataNode这一端已经完全收到了一个Replica,即Replica的状态是BlockStatus.RECEIVED_BLOCK。但是,从调用堆栈可以看到,
- 一个Block的删除(
BlockStatus.DELETED_BLOCK)不会设置readyToSend = true,即删除操作不会影响调度,因为一个Block的删除操作是异步的。 - 一个Block正在写入的时候(
BlockStatus.RECEIVING_BLOCK),仅仅会设置readyToSend = true,但是不会通过triggerIBR()进行强行的唤醒操作。仅仅设置readyToSend = true的作用是,在BPServiceActor.offerService()执行到最后会执行ibrManager.waitTillNextIBR()方法进行等待,而如果此时readyToSend = true,就不会等待,而是直接开始下一轮的循环处理逻辑。但是仅仅设置readyToSend = true显然不会立刻中断已经处于wait()中的waitTillNextIBR()方法:-------------------------------- IncrementalBlockReportManager.java ----------------------------------------------- synchronized void notifyNamenodeBlock(ReceivedDeletedBlockInfo rdbi, DatanodeStorage storage, boolean isOnTransientStorage) { addRDBI(rdbi, storage); // 将这个Block信息添加到需要进行IBR的block的list中 final BlockStatus status = rdbi.getStatus(); if (status == BlockStatus.RECEIVING_BLOCK) { // the report will be sent out in the next heartbeat. readyToSend = true; // 这个report会在下一次report的时候汇报上去 } else if (status == BlockStatus.RECEIVED_BLOCK) { // the report is sent right away. triggerIBR(isOnTransientStorage); // 这个report会立刻发送 } }
- HDFS管理员手动触发了Block Report
----------------------------------------- DFSAdmin.java ---------------------------------------------- public int triggerBlockReport(String[] argv) throws IOException { ....... dnProxy.triggerBlockReport( new BlockReportOptions.Factory(). setIncremental(incremental). build()); } - DataNode端的ReconfigurationThread检测到了配置文件中关于
dfs.datanode.data.dir的配置的变化,因此触发IBR:@Override --------------------------------------------------- DataNode.java ----------------------------------------------------- public void reconfigurePropertyImpl(String property, String newVal) throws ReconfigurationException { if (property.equals(DFS_DATANODE_DATA_DIR_KEY)) { // 管理员修改了`dfs.datanode.data.dir` IOException rootException = null; ...... triggerBlockReport( new BlockReportOptions.Factory().setIncremental(false).build()); } } .....
所以,总的说来,block report的调用只会在BPServiceActor中进行,外界触发IBR的各种情况,都只能通过变量或者多线程的通知,来让BPServiceActor提前或者立刻进行IBR,而不会在其自己的线程中自行进行IBR。基本情况分为三种:
- 不进行任何干预,那么BPServiceActor在每次心跳完成以后会正常进行指定时间的等待。比如,一个block的删除操作导致的IBR
- 只设置readyToSend=true,那么BPServiceActor在完成一轮汇报以后,会立刻进行下一轮新的汇报,而不会等待指定的时间间隔。但是,如果BPServiceActor已经处于两轮调度之间的wait(),这个wait不会被实时唤醒。比如,一个Block正在被写入,这时候,没有紧急到立刻需要汇报,但是最好尽快汇报,一定需要在下次汇报。
- 设置readyToSend=true,并通过triggerIBR()唤醒在IncrementalBlockReportManager对象锁上等待的BPServiceActor,这时候如果BPServiceActor已经处于两轮调度之间的wait(),这个wait()会立刻结束然后进入下一轮调度,比如,一个Block已经完全收到,需要立刻汇报给NameNode。
哪些Block会进行FBR或者IBR
FBR(Full Block Report)是DataNode的全部block的状态汇报,而IBR(IBR)是粒度要小很多、频率默认是3s一次增量汇报,即只汇报两次汇报之间发生的新的Block事件,比如,在两次IBR间隔之间新增的Replica、在两次IBR之间新删除的Replica。
IBR所选定的Block
上面说过,每一个BPOfferService对应了一个NameServicie,同时还会维护一个BlockServiceActor数组,其中每一个BlockServiceActor对应一个NameNode(无论是Active还是Standby),而每一个BPServiceActor会维护一个独立的IncrementalBlockReportManager对象,专门负责跟IBR相关的信息,最重要的就是pendingIBRs。
所有需要进行IBR的Block存放在IncrementalBlockReportManager的实例变量pendingIBRs中,这个是Map,记录了这个DataNode的每一个Storage 到 其需要进行IBR的Block的映射关系:
private final Map<DatanodeStorage, PerStorageIBR> pendingIBRs
= Maps.newHashMap();
往pendingIBRs中添加replica信息是方法addRDBI()负责的,从调用堆栈,可以看到往pendingIBRs添加待汇报的replica的信息的调用:
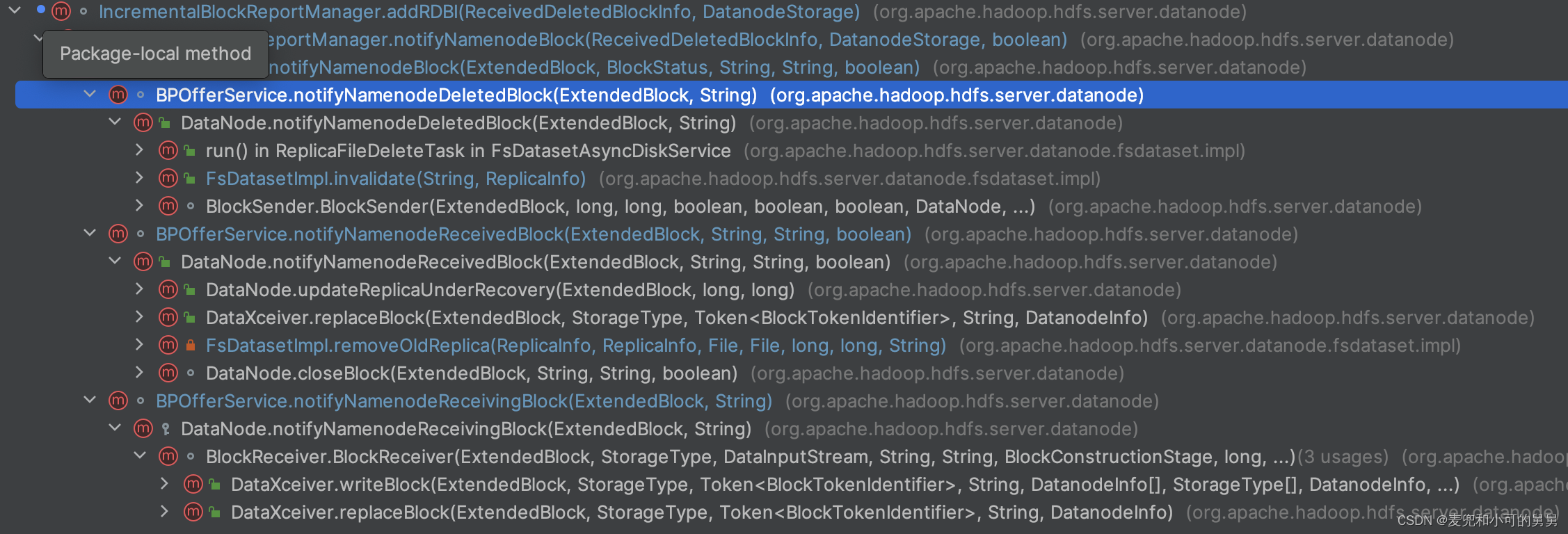
void notifyNamenodeReceivedBlock(ExtendedBlock block, String delHint,
String storageUuid, boolean isOnTransientStorage) {
notifyNamenodeBlock(block, BlockStatus.RECEIVED_BLOCK, delHint,
storageUuid, isOnTransientStorage);
}
void notifyNamenodeReceivingBlock(ExtendedBlock block, String storageUuid) {
notifyNamenodeBlock(block, BlockStatus.RECEIVING_BLOCK, null, storageUuid,
false);
}
void notifyNamenodeDeletedBlock(ExtendedBlock block, String storageUuid) {
notifyNamenodeBlock(block, BlockStatus.DELETED_BLOCK, null, storageUuid,
false);
}
RDBI是ReceivedDeletedBlockInfo的简称,即待汇报的每一个Replica会被封装成ReceivedDeletedBlockInfo对象:
---------------------------------- BPOfferService ----------------------------------
private void notifyNamenodeBlock(ExtendedBlock block, BlockStatus status,
String delHint, String storageUuid, boolean isOnTransientStorage) {
final ReceivedDeletedBlockInfo info = new ReceivedDeletedBlockInfo(
block.getLocalBlock(), status, delHint);
final DatanodeStorage storage = dn.getFSDataset().getStorage(storageUuid);
for (BPServiceActor actor : bpServices) { // 准备发送给所有的NameNode,包括standby NN
actor.getIbrManager().notifyNamenodeBlock(info, storage,
isOnTransientStorage);
}
}
可以看到,BPOfferService.notifyNamenodeBlock()会将这个RDBI添加到当前的BPOfferService的所有BPServiceActor的IncrementalBlockReportManager对象的pendingIBRs中。
ReceivedDeletedBlockInfo类如下所示,其封装了待处理的block信息以及处理的类型BlockStatus,显然,NameNode会根据这个BlockStatus信息,对这个Block进行对应操作。
public class ReceivedDeletedBlockInfo {
Block block;
BlockStatus status;
String delHints;
public static enum BlockStatus {
RECEIVING_BLOCK(1),
RECEIVED_BLOCK(2),
DELETED_BLOCK(3);
上面讲到了RDBI的pendingBlock的生成过程。那么,在IBR进行的时候,是如何操作的呢?比如,最直接的问题,IBR如果做到只汇报两次IBR之间新增或者新删除的Replica?答案是,在每次将pendingIBRs中的待回报信息拷贝出来以后,即清空对应的Storage的结果,避免下次重复汇报:
----------------------------------------- IncrementalBlockReportManager ----------------------------------
private synchronized StorageReceivedDeletedBlocks[] generateIBRs() {
final List<StorageReceivedDeletedBlocks> reports
= new ArrayList<>(pendingIBRs.size());
for (Map.Entry<DatanodeStorage, PerStorageIBR> entry
: pendingIBRs.entrySet()) {
final PerStorageIBR perStorage = entry.getValue();
// 清空这个storage刚刚新增的Replica,removeAll()会返回所删掉的这个Storage的Replica
final ReceivedDeletedBlockInfo[] rdbi = perStorage.removeAll();
if (rdbi != null) {
// 将刚刚删除的Storage的replica结果放入待汇报数组中,待会儿进行汇报
reports.add(new StorageReceivedDeletedBlocks(entry.getKey(), rdbi));
}
}
readyToSend = false;
return reports.toArray(new StorageReceivedDeletedBlocks[reports.size()]);
}
可以看到,generateIBRs()会遍历pendingIBRs中的每一个Storage,取出这个Storage对应的Block信息放入待汇报数组reports 中,然后清空pendingIBRs中这个Storage的replica信息,避免重复汇报。
FBR所选定的Block
从blockReport()方法中可以看到,它会取出所有Volume的需要进行FBR的block:
Map<DatanodeStorage, BlockListAsLongs> perVolumeBlockLists =
dn.getFSDataset().getBlockReports(bpos.getBlockPoolId());
从下面的代码可以看到收集需要进行blockReport的block的过程,就是从volumeMap中取出对应的pool 的 所有replica,然后根据replica的状态,将对应的replica放到待汇报的列表中:
public Map<DatanodeStorage, BlockListAsLongs> getBlockReports(String bpid) {
Map<DatanodeStorage, BlockListAsLongs> blockReportsMap =
new HashMap<DatanodeStorage, BlockListAsLongs>();
Map<String, BlockListAsLongs.Builder> builders =
new HashMap<String, BlockListAsLongs.Builder>();
List<FsVolumeImpl> curVolumes = null;
synchronized(this) {
curVolumes = volumes.getVolumes();
for (FsVolumeSpi v : curVolumes) {
builders.put(v.getStorageID(),BlockListAsLongs.builder(maxDataLength));
}
for (ReplicaInfo b : volumeMap.replicas(bpid)) {
.....
switch(b.getState()) {
case FINALIZED:
case RBW:
case RWR:
builders.get(b.getVolume().getStorageID()).add(b);
break;
case RUR:
ReplicaUnderRecovery rur = (ReplicaUnderRecovery)b;
builders.get(rur.getVolume().getStorageID())
.add(rur.getOriginalReplica());
break;
....
}
}
}
// blockReportMap的key是这个Volume,value是对应的blocks
for (FsVolumeImpl v : curVolumes) {
blockReportsMap.put(v.toDatanodeStorage(),
builders.get(v.getStorageID()).build());
}
return blockReportsMap;
}
可以看到,blockReport针对的Replica的状态是以下状态:
- FINALIZED: 即已经完成写入、不再进行修改的Replica。比如,正常写入到最终Replica目录的replica。在DataNode中,一个Finalized的Replica在DataNode端对应了一个FinalizedReplica对象。
- RBW(Replica Being Writen):这个Replica正在被写入,即Replica还在被客户端写入,一个正在构造中的状态。有一个RBW状态的Replica在DataNode端对应了一个ReplicaBeingWritten对象。
- RWR(Replica Waiting to be Recovered):这个Replica正在等待被修复。在DataNode启动的时候,所有的处于RBW状态下的Replica都会变成RWR状态,一个RWR状态的Replica在DataNode端对应了一个ReplicaWaitingToBeRecovered对象。
- RUR(Replica Under Recovery): 这个Replica正在被修复。NameNode会向DataNode发送DNA_RECOVERBLOCK消息,其中携带了需要进行修复的Block的信息,DataNode收到对应信息以后,会基于这些待修复的Replica构造对应的ReplicaUnderRecovery对象,一个ReplicaUnderRecovery对象代表了一个RUR状态的Replica,这些ReplicaUnderRecovery对象会被交付给对应的BlockRecoveryWorker进行修复。
所以,可以看到,在一个DataNode启动的时候(或者一次FBR的调度时机到来的时候),无论是已经完全完成的(FINALIZED)的Replica,还是正在写入的Replica(RBW)、或者是需要进行修复的Replica(RWR/RUR),都会统一汇报给NameNode。这是为什么,我们的HDFS在发生以上事故的时候,我们任务如果不进行参数调整的简单Cluster重启无法解决问题的原因。
块放置策略详解之在上层寻找机器
通过这里的代码我们会了解到:
- NameNode为Block选定机器的基本策略
- 哪些原因会导致一个DataNode无法被选作Replica的放置节点
- 当一个DataNode因为其中一种原因无法被选择Replica的放置节点的时候,怎样获取具体原因
为文件添加块的基本流程
当客户端在写入数据的过程中需要一个新的 Block以存放后续的数据的时候,会通过addBlock()接口申请一个新的Block,NameNode经过块放置策略选择合适的Block,将Block信息返回给客户端,客户端随后直接联系对于的DataNode进行写入操作。
FSNamesystem管理了整个集群的块的元数据信息,这些元数据信息会通过FSEditLog在每次操作发生的时候sync到磁盘。与之相比, FSDirectory则维护了FS文件系统的树状层次结构,其中的INodeDirectory和INodeFile代表了这个文件系统中的目录和文件节点信息,节点信息中还存放了这个文件对应的块信息,这些信息全部在内存中。
因此在我们对文件进行读写操作的时候,FSNamesystem处理管理块信息,也会通过FSDirectory去维护文件系统的层次信息,并且由FSNameService负责信息的持久化。
下图显示了FSNameservice在收到一个addBlock()请求的基本过程,我们可以从中清晰看到起操作的基本流程,包括通过FSDirectory对文件目录结构信息的维护、块的分配、文件和块的绑定、块信息的持久化等等操作,也能看到上锁的基本流程:
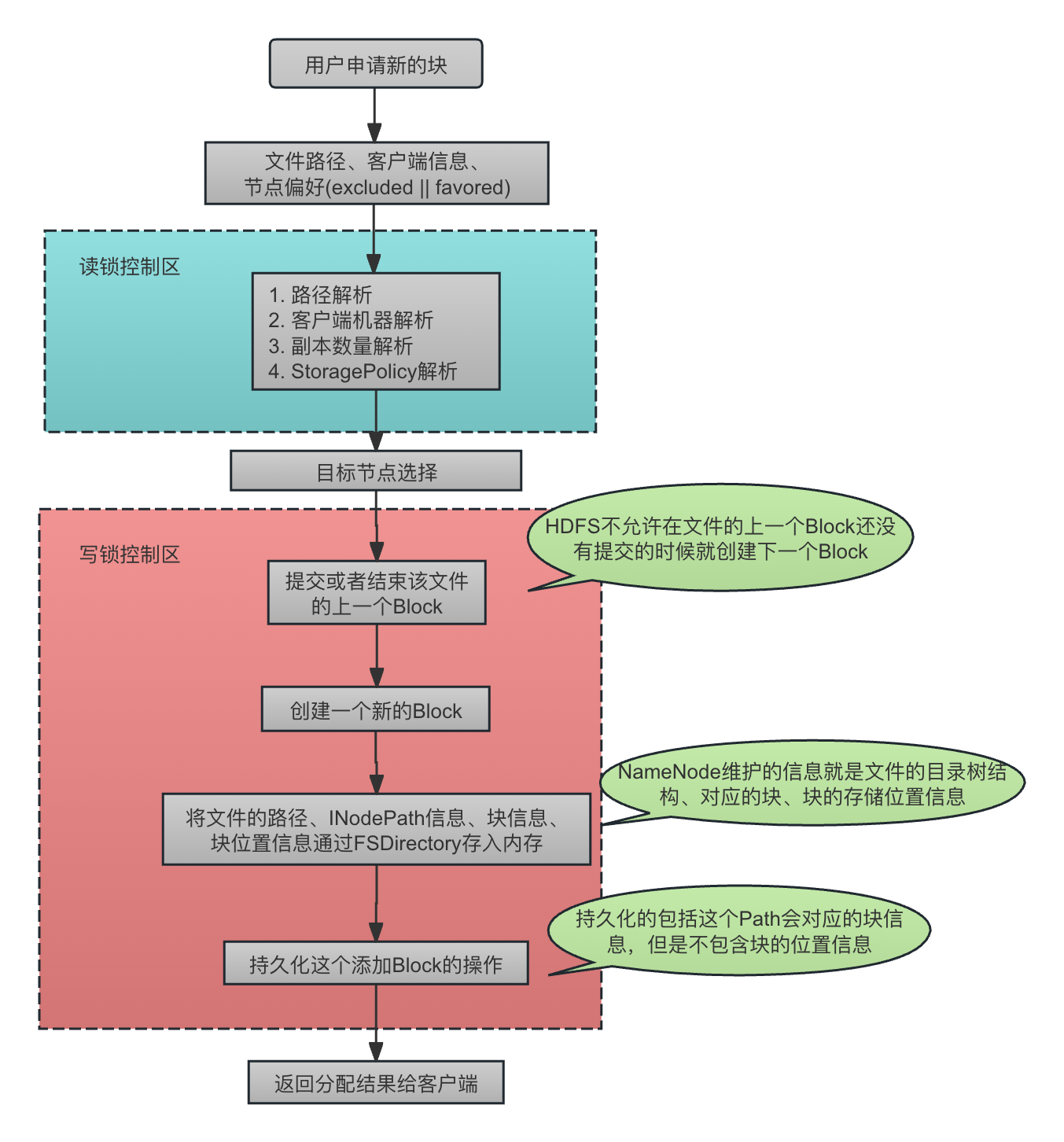
本文的关注点在“目标节点选择”这一步,可以看到,选择目标节点的时候,还没有进行新的块的分配。
注意,FSImage中会存放文件的目录结构信息,块信息,但是块信息中不会包含块的位置信息,块的位置信息依赖于DataNode的汇报。我们看AddBlockOp的writeFields()方法可以看到,在为一个文件添加一个Block的操作进行持久化的时候,会先写入文件的路径,然后通过FSImageSerialization.writeCompactBlockArray()写入这个文件的新的块的信息,包含blockid,大小(numBytes),以及生成时间(generationStamp),不会写入位置信息(尽管在持久化的时候这个Block已经是一个LocatedBlock了):
---------------------------------- FSEditLogOp.java ------------------------------------------- static class AddBlockOp extends FSEditLogOp public void writeFields(DataOutputStream out) throws IOException { FSImageSerialization.writeString(path, out); int size = penultimateBlock != null ? 2 : 1; Block[] blocks = new Block[size]; if (penultimateBlock != null) { blocks[0] = penultimateBlock; } blocks[size - 1] = lastBlock; FSImageSerialization.writeCompactBlockArray(blocks, out); // clientId and callId writeRpcIds(rpcClientId, rpcCallId, out); } }public static void writeCompactBlockArray( Block[] blocks, DataOutputStream out) throws IOException { WritableUtils.writeVInt(out, blocks.length); Block prev = null; for (Block b : blocks) { long szDelta = b.getNumBytes() - (prev != null ? prev.getNumBytes() : 0); long gsDelta = b.getGenerationStamp() - (prev != null ? prev.getGenerationStamp() : 0); out.writeLong(b.getBlockId()); // 写入块id WritableUtils.writeVLong(out, szDelta);// 写入块大小 WritableUtils.writeVLong(out, gsDelta);// 写入块时间戳 prev = b; } }
块放置策略:选择机器
NameNode端块的管理是使用BlockManager的,除了管理块和host之间的映射关系,还负责块放置策略。
在BlockManager启动的时候,会构造对应的BlockPlacementPolicy实现,默认实现是BlockPlacementPolicyDefault:
public BlockManager(final Namesystem namesystem, final FSClusterStats stats,
final Configuration conf) throws IOException {
......
blockplacement = BlockPlacementPolicy.getInstance(
conf, stats, datanodeManager.getNetworkTopology(),
datanodeManager.getHost2DatanodeMap());
从BlockPlacementPolicyDefault中可以看到,其进行块放置的决策的时候,依赖集群的一些统计信息,集群的网络拓扑信息,DataNode节点的心跳以及是否是stale节点等等。总的说来,BlockPlacementPolicyDefault的基本策略为:
- 如果写操作发生在某个数据节点上,第一个副本会放置在本地机器上。如果不是,则随机选择一个数据节点
- 第二个副本会放置在不同机架上的另一个数据节点上
- 第三个副本会放置在与第二个副本在同一机架但不同节点上的另一个数据节点上
--------------------------------- BlockPlacementPolicyDefault ------------------------------------
public class BlockPlacementPolicyDefault extends BlockPlacementPolicy {
protected boolean considerLoad; // 在选择 DataNode 的时候是否考虑负载
private boolean preferLocalNode; // 是否倾向于分配Client本地的DataNode
protected NetworkTopology clusterMap; // 用来获取cluster map的工具类
protected Host2NodesMap host2datanodeMap; // 从hostname到DataNodeInfo的映射信息
private FSClusterStats stats; // 集群的统计信息
protected long heartbeatInterval; // DataNode心跳的时间间隔,主要用在为一个Block选择一个Replica进行删除的时候用到
private long staleInterval; // 认定一个DataNode是stale的心跳间隔,心跳间隔大于该值则认定DataNode为stale,如果需要避免将块分配到stale node,就会不往这个节点上分配
BlockManager在chooseTarget4NewNode()方法中,获取对应文件的BlockStoragePolicy,然后调用对应的BlockPlacementPolicy.chooseTarget()进行DataNode节点选择:
---------------------------------------- BlockManager --------------------------------------------
public DatanodeStorageInfo[] chooseTarget4NewBlock(final String src,
final int numOfReplicas, final Node client,
final Set<Node> excludedNodes,
final long blocksize,
final List<String> favoredNodes,
final byte storagePolicyID,
final EnumSet<AddBlockFlag> flags) throws IOException {
List<DatanodeDescriptor> favoredDatanodeDescriptors =
getDatanodeDescriptors(favoredNodes);
final BlockStoragePolicy storagePolicy = storagePolicySuite.getPolicy(storagePolicyID);
final DatanodeStorageInfo[] targets = blockplacement.chooseTarget(src,
numOfReplicas, client, excludedNodes, blocksize,
favoredDatanodeDescriptors, storagePolicy, flags);
BlockPlacementPolicy抽象类中的chooseTarget()方法定义如下。从方法参数我们可以看到,有大量的引用类型参数,用来存放调用过程中的中间结果即中间状态的一些信息。
public abstract DatanodeStorageInfo[] chooseTarget(String srcPath,
int numOfReplicas,
Node writer,
List<DatanodeStorageInfo> chosen,
boolean returnChosenNodes,
Set<Node> excludedNodes,
long blocksize,
BlockStoragePolicy storagePolicy,
EnumSet<AddBlockFlag> flags);
其方法的基本参数为:
- srcPath: 文件的路径
- numOfReplicas: 所需要的额外的Replica的数量。在逐步寻找到对应的节点的过程中,numOfReplicas逐渐减小,即,该参数代表的是当前依然需要的replica的数量
- writer: 客户端节点。如果这个客户端不在集群中,那么该参数为空
- chosen: 当前已经选择出来的节点,即,参数中携带了调用过程中的中间结果
- returnChosenNodes:是否将已传入的已经选择的节点chosen中的节点也一起放到结果中返回。正常的为Block分配节点的时候,没有选择任何节点,这个参数是空的。但是,有一种情况,比如我们在已经已经进行了节点分配的节点添加新的DataNode进来的时候,这个参数为True。详情请参考BlockManager.chooseTarget4AdditionalDatanode()方法,这里不赘述。
- excludedNodes:排除的节点。在选择节点的过程中,通过该参数存放需要排除的节点,包括客户端本山要求的需要排除的节点,以及在选择节点过程中已经被选中的节点也需要加入进来放置该节点被重复选择。
- blocksize: 块大小
- storagePolicy: 存储策略,比如,需要什么类型的storage,以及这种类型的storage不存在的时候的退化选择
- AddBlockFlag: 客户端传入的、为块进行分配节点时候的一些标记信息,用来对块的节点选择进行一些提示。目前就支持NO_LOCAL_WRITE,即不要将块分配在客户端所在的DataNode上。
具体代码如下所示:
private DatanodeStorageInfo[] chooseTarget(int numOfReplicas,
Node writer,
List<DatanodeStorageInfo> chosenStorage,
boolean returnChosenNodes,
Set<Node> excludedNodes,
long blocksize,
final BlockStoragePolicy storagePolicy,
EnumSet<AddBlockFlag> addBlockFlags) {
if (numOfReplicas == 0 || clusterMap.getNumOfLeaves()==0) {
return DatanodeStorageInfo.EMPTY_ARRAY;
}
if (excludedNodes == null) {
excludedNodes = new HashSet<Node>();
}
int[] result = getMaxNodesPerRack(chosenStorage.size(), numOfReplicas);
numOfReplicas = result[0];
int maxNodesPerRack = result[1];
// 将选中的节点或者客户端要求的excludedNode添加到excludedNodes参数中,节点选择过程中不再考虑它们
for (DatanodeStorageInfo storage : chosenStorage) {
// add localMachine and related nodes to excludedNodes
addToExcludedNodes(storage.getDatanodeDescriptor(), excludedNodes);
}
List<DatanodeStorageInfo> results = null;
Node localNode = null;
boolean avoidStaleNodes = (stats != null
&& stats.isAvoidingStaleDataNodesForWrite());
boolean avoidLocalNode = (addBlockFlags != null
&& addBlockFlags.contains(AddBlockFlag.NO_LOCAL_WRITE)
&& writer != null
&& !excludedNodes.contains(writer));
// Attempt to exclude local node if the client suggests so. If no enough
// nodes can be obtained, it falls back to the default block placement
// policy.
if (avoidLocalNode) {
results = new ArrayList<>(chosenStorage);
Set<Node> excludedNodeCopy = new HashSet<>(excludedNodes);
excludedNodeCopy.add(writer); // 将客户端节点添加到排除节点中
localNode = chooseTarget(numOfReplicas, writer,
excludedNodeCopy, blocksize, maxNodesPerRack, results,
avoidStaleNodes, storagePolicy,
EnumSet.noneOf(StorageType.class), results.isEmpty());
if (results.size() < numOfReplicas) { // 并没有找到期望数量的副本,那么清空结果,下面会有fallback的策略
// not enough nodes; discard results and fall back
results = null;
}
}
// 如果avoidLocalNode=true但是没有成功找到numOfReplicas个节点,或者并不需要avoidLocalNode,那么就退化到不适用avoidLocalNode的方式
if (results == null) {
results = new ArrayList<>(chosenStorage);
localNode = chooseTarget(numOfReplicas, writer,
excludedNodes, blocksize, maxNodesPerRack, results,
avoidStaleNodes, storagePolicy,
EnumSet.noneOf(StorageType.class), results.isEmpty());
}
if (!returnChosenNodes) {
results.removeAll(chosenStorage);
}
// 对选中的节点进行排序,封装成一个可形成Pipeline的有序的节点
return getPipeline(
(writer != null && writer instanceof DatanodeDescriptor) ? writer
: localNode,
results.toArray(new DatanodeStorageInfo[results.size()]));
}
该方法的基本逻辑为:
- 首先根据当前集群的规模和这个Block的副本数量,确定平均到每个机架最大允许放置的该Block的副本数量
int[] result = getMaxNodesPerRack(chosenStorage.size(), numOfReplicas); numOfReplicas = result[0]; int maxNodesPerRack = result[1]; - 将已选择的节点加入到排除节点数组中,这些节点不会选作候选节点
for (DatanodeStorageInfo storage : chosenStorage) { // add localMachine and related nodes to excludedNodes addToExcludedNodes(storage.getDatanodeDescriptor(), excludedNodes); } - 确定当前集群的状态确定当前是否应该避免选择Stale节点(陈旧数据节点)作为数据写入的候选节点
boolean avoidStaleNodes = (stats != null && stats.isAvoidingStaleDataNodesForWrite()); - 根据客户端的指示确定当前是否应该避免选择与客户端在同一台机器上的节点作为数据写入的候选节点
boolean avoidLocalNode = (addBlockFlags != null && addBlockFlags.contains(AddBlockFlag.NO_LOCAL_WRITE) && writer != null && !excludedNodes.contains(writer)); - 如果需要排除客户端节点,那么就将客户端节点加入到排除节点列表,然后基于排除节点、是否选择Stale节点的信息,调用chooseTarget()的重载方法,进行节点选择
if (avoidLocalNode) { results = new ArrayList<>(chosenStorage); Set<Node> excludedNodeCopy = new HashSet<>(excludedNodes); excludedNodeCopy.add(writer); // 将客户端节点添加到排除节点中 localNode = chooseTarget(numOfReplicas, writer, excludedNodeCopy, blocksize, maxNodesPerRack, results, avoidStaleNodes, storagePolicy, EnumSet.noneOf(StorageType.class), results.isEmpty()); - 如果在将客户端作为排除节点的情况下失败,那么就进行退化选择,不将客户端放入排除节点,再次尝试选择
if (results == null) { results = new ArrayList<>(chosenStorage); localNode = chooseTarget(numOfReplicas, writer, excludedNodes, blocksize, maxNodesPerRack, results, avoidStaleNodes, storagePolicy, EnumSet.noneOf(StorageType.class), results.isEmpty()); } - 将节点进行排序,组装为一个Pipeline(其实就是节点排序以后的结果),返回给客户端
// 对选中的节点进行排序,封装成一个可形成Pipeline的有序的节点 return getPipeline( (writer != null && writer instanceof DatanodeDescriptor) ? writer : localNode, results.toArray(new DatanodeStorageInfo[results.size()]));
private Node chooseTarget(int numOfReplicas,
Node writer,
final Set<Node> excludedNodes,
final long blocksize,
final int maxNodesPerRack,
final List<DatanodeStorageInfo> results, //
final boolean avoidStaleNodes,
final BlockStoragePolicy storagePolicy,
final EnumSet<StorageType> unavailableStorages,
final boolean newBlock) {
if (numOfReplicas == 0 || clusterMap.getNumOfLeaves()==0) {
return (writer instanceof DatanodeDescriptor) ? writer : null;
}
final int numOfResults = results.size(); // = 0
final int totalReplicasExpected = numOfReplicas + numOfResults; // numOfReplicas = 3
if ((writer == null || !(writer instanceof DatanodeDescriptor)) && !newBlock) {
writer = results.get(0).getDatanodeDescriptor();
}
// Keep a copy of original excludedNodes
final Set<Node> oldExcludedNodes = new HashSet<Node>(excludedNodes);
// choose storage types; use fallbacks for unavailable storages
final List<StorageType> requiredStorageTypes = storagePolicy
.chooseStorageTypes((short) totalReplicasExpected,
DatanodeStorageInfo.toStorageTypes(results), // 当前已经选定的StorageType
unavailableStorages, newBlock); // 已经确定不可用的StorageType
final EnumMap<StorageType, Integer> storageTypes =
getRequiredStorageTypes(requiredStorageTypes);
try {
writer = chooseTargetInOrder(numOfReplicas, writer, excludedNodes, blocksize,
maxNodesPerRack, results, avoidStaleNodes, newBlock, storageTypes);
} catch (NotEnoughReplicasException e) {
...
if (avoidStaleNodes) {
// Retry chooseTarget again, this time not avoiding stale nodes.
// excludedNodes contains the initial excludedNodes and nodes that were
// not chosen because they were stale, decommissioned, etc.
// We need to additionally exclude the nodes that were added to the
// result list in the successful calls to choose*() above.
for (DatanodeStorageInfo resultStorage : results) {
addToExcludedNodes(resultStorage.getDatanodeDescriptor(), oldExcludedNodes);
}
// Set numOfReplicas, since it can get out of sync with the result list
// if the NotEnoughReplicasException was thrown in chooseRandom().
numOfReplicas = totalReplicasExpected - results.size();
// 递归调用当前方法
return chooseTarget(numOfReplicas, writer, oldExcludedNodes, blocksize,
maxNodesPerRack, results, false, storagePolicy, unavailableStorages,
newBlock);
}
boolean retry = false;
// simply add all the remaining types into unavailableStorages and give
// another try. No best effort is guaranteed here.
for (StorageType type : storageTypes.keySet()) {
if (!unavailableStorages.contains(type)) {
unavailableStorages.add(type); // 重试的时候,将刚刚requried storage type放入到unavailableStorages中
retry = true;
}
}
if (retry) { // 重试
for (DatanodeStorageInfo resultStorage : results) {
addToExcludedNodes(resultStorage.getDatanodeDescriptor(),
oldExcludedNodes);
}
numOfReplicas = totalReplicasExpected - results.size();
// 递归调用当前方法
return chooseTarget(numOfReplicas, writer, oldExcludedNodes, blocksize,
maxNodesPerRack, results, false, storagePolicy, unavailableStorages,
newBlock);
}
}
return writer;
}
- 确定当前的writer。如果是Block的第一个Replica,显然writer是客户端。如果不是Block的第一个Replica,显然writer就是就是第一个DataNode
if ((writer == null || !(writer instanceof DatanodeDescriptor)) && !newBlock) { writer = results.get(0).getDatanodeDescriptor(); } - 选定需要的StorageType。这里返回的是一个StorageType数组,数组中的每一个元素代表的是每个还没有分配到节点的Replica所要求的StorageType,为这些Replica分配DataNode必须保证这个DataNode上含有满足要求的StorageType:
final List<StorageType> requiredStorageTypes = storagePolicy .chooseStorageTypes((short) totalReplicasExpected, DatanodeStorageInfo.toStorageTypes(results), // 当前已经选定的StorageType unavailableStorages, newBlock); // 已经确定不可用的StorageType - 根据目前的StorageType的要求(storagteTypes),副本总数numOfReplicas,已经选择的结果results,已经不用考虑的节点excludeNodes,每个Rack上的最大副本数(maxNodesPerRack),是否是第一个Replica(newBlock),按顺序选择合适的Storage来放置副本
writer = chooseTargetInOrder(numOfReplicas, writer, excludedNodes, blocksize, maxNodesPerRack, results, avoidStaleNodes, newBlock, storageTypes); - 如果chooseTargetInOrder()依然失败(失败的意思并不意味着没有为任何一个副本找到Storage,而是指没有为剩下的所有副本找到Storage),并且刚刚是avoidStaleNodes的,这时候将进行退化处理,不再忽略staleNodes节点进行尝试,因此递归调用chooseTarget()方法进行重试。显然,如果刚刚的chooseTargetInOrder()找到了部分新的节点,这部分新找到的节点会添加到excludedNodes中去,避免递归的时候再选择到这些节点
- 如果依然失败,那么就将刚刚的副本的StorageTypes添加到unavailableStorage中去,然后重试。下文将StorageType会讲到,这里的重试的含义是,由于刚刚使用的StorageType添加到了unavailableStorage了,重试的时候会进行fallback,即根据其StoragePolicy进行存储策略的降级,基于降级进行重试,即递归调用chooseTargetInOrder()
- 如果依然失败,则整个选择过程宣告失败。
为每个副本逐个寻找机器
所以,一个Block的副本的按序选择是发生在方法chooseTargetInOrder()中。chooseTargetInOrder()的上层调用者负责制定对应的选择策略(允许的StorageType,Execluded Node等)并负责进行重试,而chooseTargetInOrder()就是按照定下来的策略进行Storage的选择,chooseTargetInOrder()的失败,意味着以当前策略没有选择到足够的副本(注意,不是一个合适的Storage都没有选择出)。
chooseTargetInOrder()清晰地反映出BlockPlacementPolicyDefault的典型选择结果,即在一个三副本的情况下,第一个副本会在一个机架上(尽可能和writer在同一个Host或者一个机架),剩下两个副本共同存在于另外一个机架中。
其选择的基本逻辑如下图所示:
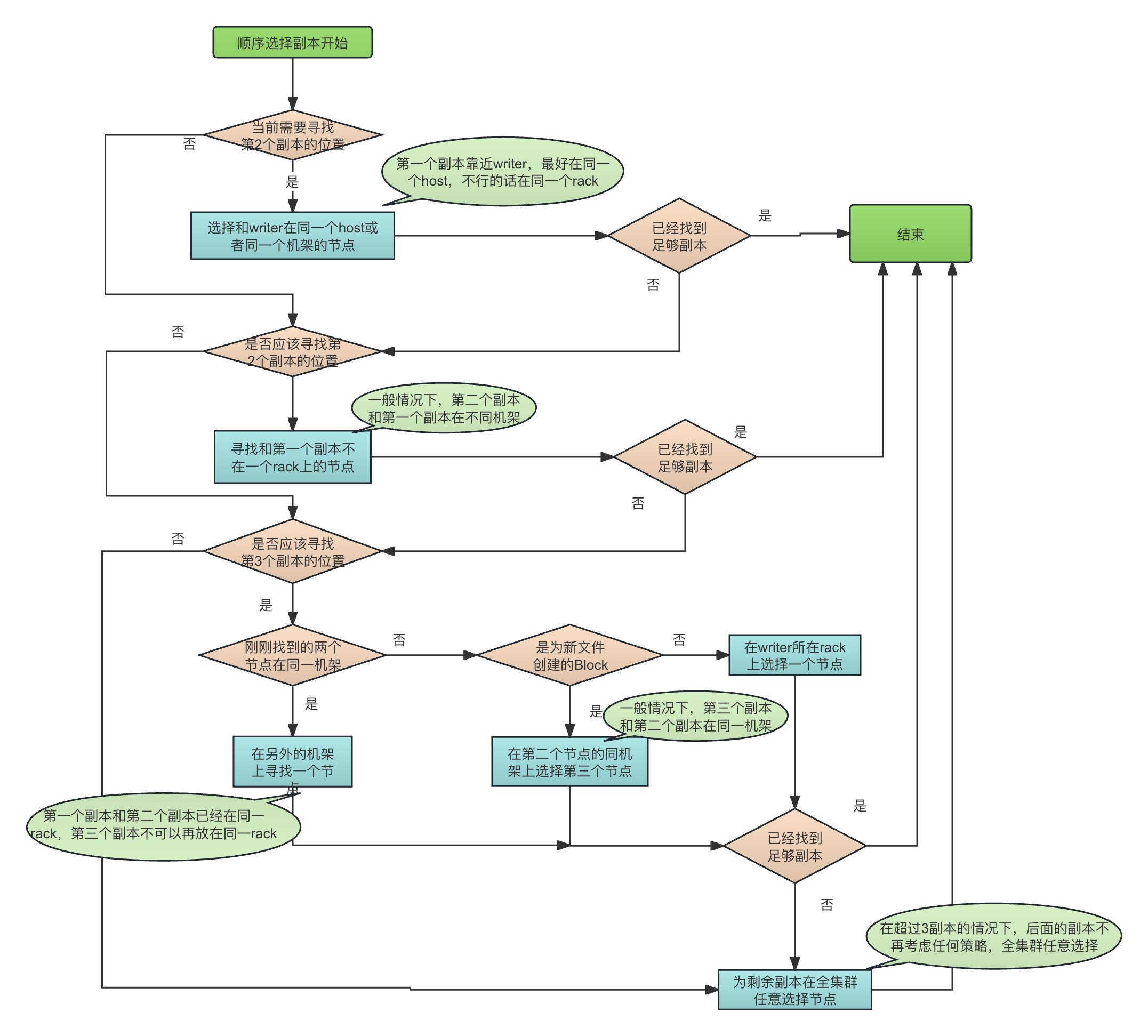
chooseTargetInOrder() 代码如下所示
protected Node chooseTargetInOrder(int numOfReplicas,
Node writer,
final Set<Node> excludedNodes,
final long blocksize,
final int maxNodesPerRack,
final List<DatanodeStorageInfo> results,
final boolean avoidStaleNodes,
final boolean newBlock,
EnumMap<StorageType, Integer> storageTypes)
throws NotEnoughReplicasException {
final int numOfResults = results.size();
if (numOfResults == 0) { // 还没有找到第一个节点,那么就寻找和local在一起的本地节点
writer = chooseLocalStorage(writer, excludedNodes, blocksize,
maxNodesPerRack, results, avoidStaleNodes, storageTypes, true)
.getDatanodeDescriptor();
if (--numOfReplicas == 0) { // numOfReplicas= 0说明副本满足要求了
return writer;
}
}
// 运行到这里,说明numOfResults!=0,dn0中存放着刚刚找到的节点
final DatanodeDescriptor dn0 = results.get(0).getDatanodeDescriptor();
if (numOfResults <= 1) { // 已经找到的节点数量 为 1,那么再选择一个远程节点,这里的远程节点指的是和刚刚选择的节点不在同一个rack上的节点
chooseRemoteRack(1, dn0, excludedNodes, blocksize, maxNodesPerRack,
results, avoidStaleNodes, storageTypes);
if (--numOfReplicas == 0) { // 找到了全部节点
return writer;
}
}
if (numOfResults <= 2) { // 已经找到的节点总数量为2, 当前正在选择第三个节点
final DatanodeDescriptor dn1 = results.get(1).getDatanodeDescriptor();
if (clusterMap.isOnSameRack(dn0, dn1)) { // 刚刚找到的两个副本在同一个机架上
chooseRemoteRack(1, dn0, excludedNodes, blocksize, maxNodesPerRack,
results, avoidStaleNodes, storageTypes); // 为第三个副本寻找一个远程机架
} else if (newBlock){ // 如果刚刚找到的两个节点不在同一个rack上(这是正常情况),并且是一个新的block的replica,那么选择一个和dn1在一起的rack
chooseLocalRack(dn1, excludedNodes, blocksize, maxNodesPerRack,
results, avoidStaleNodes, storageTypes);
} else { // 如果刚刚找到的两个节点不在同一个rack上(这是正常情况),并且不是一个新的block的replica,那么选择一个和writer在一起的rack
chooseLocalRack(writer, excludedNodes, blocksize, maxNodesPerRack,
results, avoidStaleNodes, storageTypes);
}
if (--numOfReplicas == 0) {
return writer;
}
}
// 还是不够,那么就在集群中随机选择
chooseRandom(numOfReplicas, NodeBase.ROOT, excludedNodes, blocksize,
maxNodesPerRack, results, avoidStaleNodes, storageTypes);
return writer;
}
其基本步骤为:
如果当前还没有选择出任何一个副本,那么就开始为这个Block选择第一个副本,通过方法chooseLocalStorage(),尽量为这个副本选择和writer在同一个机器上,或者如果不在一台机器,至少选择在同一个机架上。
final int numOfResults = results.size(); if (numOfResults == 0) { // 还没有找到第一个节点,那么就寻找和local在一起的本地节点 writer = chooseLocalStorage(writer, excludedNodes, blocksize, maxNodesPerRack, results, avoidStaleNodes, storageTypes, true) .getDatanodeDescriptor();对于第二个副本,则尽量选择和第一个副本所在的节点不在同一个机架上的节点(即远程机架的节点):
final DatanodeDescriptor dn0 = results.get(0).getDatanodeDescriptor(); if (numOfResults <= 1) { // 已经找到的节点数量 为 1,那么再选择一个远程节点,这里的远程节点指的是和刚刚选择的节点不在同一个rack上的节点 chooseRemoteRack(1, dn0, excludedNodes, blocksize, maxNodesPerRack, results, avoidStaleNodes, storageTypes);对于第三个副本,则分为三种情况:
- 如果前两个副本在同一机架,那么,无条件选择和它们不同的另一个机架,从而避免所有副本都在同一机架:
if (clusterMap.isOnSameRack(dn0, dn1)) { // 刚刚找到的两个副本在同一个机架上 chooseRemoteRack(1, dn0, excludedNodes, blocksize, maxNodesPerRack, results, avoidStaleNodes, storageTypes); // 为第三个副本寻找一个远程机架 - 如果前两个副本在不同机架,并且当前是为一个新的Block创建副本,那么,会选择和第二个副本同一个机架上的机器
else if (newBlock){ chooseLocalRack(dn1, excludedNodes, blocksize, maxNodesPerRack, results, avoidStaleNodes, storageTypes); - 如果前两个副本在不同机架,并且当前不是为一个新的Block创建副本,那么,会选择和writer在同一个机架上的机器存放第三个副本。
注意。这里的writer并不一定指的是写数据的客户端。上面讲过isNewBlock参数标记的就是这是否是在为一个新的Block进行副本放置,如果是一个新的Block,那么writer显然是写数据的客户端,此时的isNewBlock = true,除此之外,当前的副本分配还可能发生在比如一个副本的丢失以后的扩充、增加了Replication Factor以后的副本复制、集群rebalance等场景,这时候的writer其实是一台DataNode,此时的isNewBlock = false。chooseLocalRack(writer, excludedNodes, blocksize, maxNodesPerRack, results, avoidStaleNodes, storageTypes);
- 如果前两个副本在同一机架,那么,无条件选择和它们不同的另一个机架,从而避免所有副本都在同一机架:
如果还没有为所有副本找到机器,则在整个集群中随机寻找了
// 还是不够,那么就在集群中随机选择 chooseRandom(numOfReplicas, NodeBase.ROOT, excludedNodes, blocksize, maxNodesPerRack, results, avoidStaleNodes, storageTypes);
在指定范围内随机寻找
从chooseTargetInOrder()方法的讲解可以看到,在一定的存储策略StoragePolicy、排除节点(excludedNodes)、是否需要避免stale节点、(avoidStaleNodes)、当前已经寻找到的结果(results),我们还需要在整个集群拓扑层面约束寻找范围。比如,上面讲到的:
- 第一个副本需要尽量和writer在同一台机器上,这里叫做本地机器,local host,对应的方法为chooseLocalStorage()。这里chooseLocalStorage在无法分配到本地节点的情况下,默认允许fallback到同一机架。
- 如果第一个和第二个副本在同一个机架上,那么第三个副本不可以和它们在同一个机架上,这里叫做远程机架,remote rack,对应的方法为chooseRemoteRack();
- 如果第一个和第二个副本不再同一个机架上,并且当前是在创建一个新的Block,那么这个Block的第三个Replica需要尽量和第二个副本在同一个机架上,这里叫做本地机架,local rack,对应的方法为chooseLocalRack();
所以,local host, remote rack, local rack都是从集群拓扑范围内对副本位置的选定进行进行限制。
一个DataNode、Rack、DataCenter在集群拓扑上都表示为一个接口Node的实现,整个集群的网络拓扑形成的是一个树状结构。对于一个节点:
- networkLocation: 一个节点的网络位置是这个节点所在的位置,比如,对于一个DataNode,其网络位置就是其所在的rack的网络位置
- parent: 父节点的位置,比如,一个DataNode的父亲节点就是该DataNode所在的rack节点
- level: 这个节点所在的层级,整个集群的层级为0级,每往下一层层级加1。
DataNode作为一个集群节点,其对应的Node接口的实现是DatanodeInfo。这里不再赘述。
所以,无论是chooseLocalStorage(),还是chooseRemoteRack()和chooseLocalRack(),都只是scope的不同,最后都是在指定的scope内随机选择合适的Storage,这是通过方法chooseRandom()来实现的。该方法输入对应的scope,以及StoragePolicy、当前的结果(results)、总副本数(numOfReplicas)、需要排除的节点(excludedNodes),输出位选定的满足条件的DatanodeStorageInfo:
protected DatanodeStorageInfo chooseRandom(int numOfReplicas,
String scope,
Set<Node> excludedNodes,
long blocksize,
int maxNodesPerRack,
List<DatanodeStorageInfo> results,
boolean avoidStaleNodes,
EnumMap<StorageType, Integer> storageTypes)
throws NotEnoughReplicasException {
StringBuilder builder = null;
boolean badTarget = false;
DatanodeStorageInfo firstChosen = null;
while (numOfReplicas > 0) {
// 选节点。在excludedNodes以外,集群中随机挑选一个节点。这时候如果选不出来一个节点,
// 说明excludedNodes已经包含了集群中的所有节点,没有必要尝试了。退出while循环,就可以堆栈报错了
DatanodeDescriptor chosenNode = chooseDataNode(scope, excludedNodes);
if (chosenNode == null) {
break;
}
DatanodeStorageInfo storage = null;
if (isGoodDatanode(chosenNode, maxNodesPerRack, considerLoad,
results, avoidStaleNodes)) {
for (Iterator<Map.Entry<StorageType, Integer>> iter = storageTypes
.entrySet().iterator(); iter.hasNext();) {
Map.Entry<StorageType, Integer> entry = iter.next();
// 在节点中选择Storage Type.
// 由于异常中抛出来的是no good storage to place the block,因此这里肯定调用了
storage = chooseStorage4Block(
chosenNode, blocksize, results, entry.getKey());
if (storage != null) { // 只有当Storage不为空,才会将chosenNode加入到excludedNodes中
numOfReplicas--;
if (firstChosen == null) {
firstChosen = storage;
}
// add node (subclasses may also add related nodes) to excludedNode
addToExcludedNodes(chosenNode, excludedNodes); // 一旦选中,不再考虑
int num = entry.getValue();
if (num == 1) {
iter.remove();
} else {
entry.setValue(num - 1);
}
break;
}
}
// If no candidate storage was found on this DN then set badTarget.
badTarget = (storage == null);
}
}
// while循环退出但是numOfReplicas>0,整个选择过程就可以宣告失败了
if (numOfReplicas>0) {
String detail = enableDebugLogging;
// 整个选择过程宣告失败,可以抛出异常了
throw new NotEnoughReplicasException(detail);
}
判断一个节点是否为合适节点的方法是isGoodDatanode(),其代码非常简单,这里不再贴出。其基本的判断标准如下:
这个节点是否是inService的状态。所有与DECOMISSION和MAINTENANCE相关的状态都不是inService状态:
public boolean isInService() { return getAdminState() == AdminStates.NORMAL; } public enum AdminStates { NORMAL("In Service"), DECOMMISSION_INPROGRESS("Decommission In Progress"), DECOMMISSIONED("Decommissioned"), ENTERING_MAINTENANCE("Entering Maintenance"), IN_MAINTENANCE("In Maintenance");如果需要避开stale节点并且当前节点已经处于stale状态(超过了指定时间还没有收到心跳),那么会被认为是bad node而不再考虑
if (avoidStaleNodes) { if (node.isStale(this.staleInterval)) { logNodeIsNotChosen(node, "the node is stale "); return false; } }如果需要考虑负载,那么这个DataNode的xceiverCount超过了最大允许的负载,那么会被认为是bad node而不再考虑。熟悉DataNode的都知道,xceiver就是DataNode的写数据的streaming 连接,必须将xceiver和DataNode的普通的RPC连接以及基于Http的连接区别开,他们是DataNode所打开的三种不同连接。
if (considerLoad) { final double maxLoad = 2.0 * stats.getInServiceXceiverAverage(); final int nodeLoad = node.getXceiverCount(); if (nodeLoad > maxLoad) { return false; } }如果一旦使用这个节点,那么这个节点所在的机架上为这个Block分配的总的副本数已经超过我们所计算的、最大允许的单机架的节点数,也会认为是bad node而不再考虑
String rackname = node.getNetworkLocation(); int counter=1; for(DatanodeStorageInfo resultStorage : results) { if (rackname.equals( resultStorage.getDatanodeDescriptor().getNetworkLocation())) { counter++; } } if (counter > maxTargetPerRack) { return false; }
如果一个节点是健康节点,那么就进入了在这个节点上选择合适的Storage的过程,即遍历该节点的所有Storage,并调用chooseStorage4Block()选择一块适合存放该Replica:
public DatanodeStorageInfo chooseStorage4Block(StorageType t,
long blockSize) {
final long requiredSize =
blockSize * HdfsConstants.MIN_BLOCKS_FOR_WRITE;
final long scheduledSize = blockSize * getBlocksScheduled(t);
long remaining = 0;
DatanodeStorageInfo storage = null;
for (DatanodeStorageInfo s : getStorageInfos()) { // 一个DataNode可能有多个相同type且状态都正常的Storage
if (s.getState() == State.NORMAL && s.getStorageType() == t) {
if (storage == null) {
storage = s;
}
long r = s.getRemaining(); // 这个volume的磁盘剩余空间
if (r >= requiredSize) { // 如果剩余空间大于 requiredSize
remaining += r; // 统计多个volume的总体的remaining
}
}
}
// 返回null的原因,可能是没有对应type的storage,或者对应type的storage不是NORMAL状态,或者,
// 有对应type的storage,且状态为normal,但是,无法满足requiredSize的需要
if (requiredSize > remaining - scheduledSize) {
return null;
}
return storage;
}
chooseStorage4Block() 方法接受两个参数,分别是存储类型 StorageType和块大小 blockSize,判断是否有满足要求的StorageType。
- 该方法首先会获取已经调度到这个StorageType上的总的数据量大小。这一部分大小当前还未真正写入到DataNode的Storage,但是已经或者准备调度到对应的DataNode了,因此必须预留:
final long scheduledSize = blockSize * getBlocksScheduled(t); - 遍历这个DataNode,找到第一个StorageType满足要求的Storage,如果后面的判断说明这个DataNode的确可以存放这个Replica,那么这个Storage将被返回:
for (DatanodeStorageInfo s : getStorageInfos()) { // 一个DataNode可能有多个相同type且状态都正常的Storage if (s.getState() == State.NORMAL && s.getStorageType() == t) { if (storage == null) { storage = s; } - 统计这个DataNode上的所有满足要求的StorageType的总的大小
long r = s.getRemaining(); // 这个volume的磁盘剩余空间 if (r >= requiredSize) { // 如果剩余空间大于 requiredSize remaining += r; // 统计多个volume的总体的remaining } - 如果指定的StorageType的所有Storage的大小之和,出去已经调度却还没有真正占用的部分,依然可以存放该Replica,那么说明这个DataNode是可以满足这个StorageType的Replica的存放的,否则,这个DataNode的Storage是无法满足要求的:
if (requiredSize > remaining - scheduledSize) { return null; } return storage;
这里必须注意,chooseStorage4Block() 返回了一个对应的DataNodeStorageInfo,看起来仿佛是在NameNode端就已经为这个Replica的放置上精确到了Storage的层面,这个Replica将会写到这个选定的DataNodeStorageInfo对应的某个盘上。但是,后来仔细查看代码,发现:chooseStorage4Block()在返回一个DataNodeStorageInfo的时候,只是告知客户端这个DataNode可以存放指定StorageType的这个Replica。当客户端获取了分配结果,就可以确定自己的Block的这个Replica是可以放置到对应的DataNode上的,但是并不要求这个Replica一定要放到DataNodeStorageInfo对应的Volume上。然后客户端与DataNode通信,通信的时候只是携带了自己要求的StorageType,DataNode会通过自己的Storage选择方法,从众多可以满足对应的StorageType要求的Storage中选择一个来放置即可。
简单看一下DataNode写数据时候的Volume选择
在 DataNode端,Volume的管理发生在类FsDatasetImpl中。
DataNode端会创建对应的DataXCeiverServer负责监听客户端的各种块相关请求,这些请求定义在枚举类型datatransfer.Op中。这些请求会被放入队列中,由多个DataXceiver不断从队列中取出请求进行处理。
如果是一个Op.WRITE_BLOCK请求,DataXceiver会创建一个BlockReceiver对象负责进行处理:当收到一个Op.WRITE_BLOCK的请求时,请求中携带了这个块的StorageType要求:
--------------------------------------------- DataXceiver.java ---------------------------------------------------
public void writeBlock(final ExtendedBlock block,
final StorageType storageType,
final Token<BlockTokenIdentifier> blockToken,
final String clientname,
final DatanodeInfo[] targets,
final StorageType[] targetStorageTypes,
final DatanodeInfo srcDataNode,
final BlockConstructionStage stage,
构造BlockReceiver对象的时候,会根据当前写入的Block的BlockConstructionStage,确定对应行为。比如
- 当前的WRITE_BLOCK可能来自一个块的复制请求(比如一个Block的非首个副本,这几个副本是由DataNode通过pipeline的方式传递过来的),或者来自一个副本的移动请求(比如,Balancer)。这时候,
- 当前的WRITE_BLOCK也有可能是来自于一个新的块的创建(客户端的写行为),这时候会的写,可能是创建一个新的Replica(PIPELINE_SETUP_CREATE),或者是往一个已经固定的Replica中添加数据(PIPELINE_SETUP_APPEND),或者是一个Recover(PIPELINE_SETUP_STREAMING_RECOVERY)的过程等等。
我们以典型的创建第一个副本的请求为例,查看其大致过程
- 收到Op.WRITE_BLOCK请求以后,在构造对于的BlockReceiver的时候,会创建好对应的Rbw文件,即这个Replica的临时写入文件,这是通过方法createRbw()来创建的,Rbw指的是Replica Being Written的简称:
switch (stage) {
case PIPELINE_SETUP_CREATE:
replicaHandler = datanode.data.createRbw(storageType, block, allowLazyPersist);
datanode.notifyNamenodeReceivingBlock(
block, replicaHandler.getReplica().getStorageUuid());
break;
createRbw() 的主要责任就是根据StorageType选定一个Storage,然后创建对应的副本路径:
@Override // FsDatasetSpi
public synchronized ReplicaHandler createRbw(
StorageType storageType, ExtendedBlock b, boolean allowLazyPersist)
throws IOException {
.....
ref = volumes.getNextVolume(storageType, b.getNumBytes()); // 选定对应的Volume
FsVolumeImpl v = (FsVolumeImpl) ref.getVolume();
....
f = v.createRbwFile(b.getBlockPoolId(), b.getLocalBlock()); // 在对应的Volume上创建这个副本的文件
创建对应副本的Rbw文件的时候,肯定是先写入到临时文件,这里的rbwDir是在DataNode为每一个StoragePool单独创建的一个临时目录:
---------------------------------- FsVolumeImpl -----------------------------------
File createRbwFile(String bpid, Block b) throws IOException {
//每一个BlockPoolSlice代表了对应的BlockPool在当前DataNode上的这一部分数据
return getBlockPoolSlice(bpid).createRbwFile(b);
....
}
------------------------------- BlockPoolSlice ------------------------------------
File createRbwFile(Block b) throws IOException {
File f = new File(rbwDir, b.getBlockName());
return DatanodeUtil.createTmpFile(b, f);
}
- 当副本写入完毕,即进入FINALYZED状态,就会移动到其最终目录,这是通过FsDatasetImpl.finalizeBlock()方法实现的:
public void finalizeBlock(ExtendedBlock b, boolean fsyncDir)
throws IOException {
......
// 这个方法也是synchronized
finalizedReplicaInfo = finalizeReplica(b.getBlockPoolId(), replicaInfo);
}
finalizeReplica最终会通过addBlock()创建对应的Replica的最终目标文件,并将刚刚创建的临时文件移动到最终文件:
File addBlock(Block b, File f) throws IOException {
File blockDir = DatanodeUtil.idToBlockDir(finalizedDir, b.getBlockId());
File blockFile = FsDatasetImpl.moveBlockFiles(b, f, blockDir);
idToBlockDir是从ReplicaID到计算出文件路径的算法,其实就是从BlockID中进行移位操作构成子路径,形成这个Replica的最终路径:
public static File idToBlockDir(File root, long blockId) {
int d1 = (int)((blockId >> 16) & 0xff);
int d2 = (int)((blockId >> 8) & 0xff);
String path = DataStorage.BLOCK_SUBDIR_PREFIX + d1 + SEP +
DataStorage.BLOCK_SUBDIR_PREFIX + d2;
return new File(root, path);
}
可以看到,当一个Replica的BlockID确定了,那么其最终写入的目录是确定的。
单个同一个Block在每个机架上的最大副本数量
在多rack的环境下,将一个Block的不同副本放在不同的rack上,可以容忍rack级别的失效带来文件的读写失效。因此,计算单个rack的一个Block在单个rack的最大副本数的基本原则为:
- 这个最大副本数不宜过小:比如,最小为2。比如,即使我们集群是一个部署在上百个rack上,replication factor = 3,也最好不要将三个副本放在三个完全不同的rack上。因为多个rack同时失效的概率很低,因此,只需要分布在两个rack上,从而减少块在写的过程中的cross-rack的流量,提高写的吞吐。
- 这个最大副本数不宜过小不宜过大,这样有利于提升系统的可用性,让一个block的多个副本尽量跨rack
单个Block在每个机架上的最大副本数的计算是由方法getMaxNodesPerRack()负责的,参数和返回值如下所示:
/**
* @param numOfChosen 已经选择的节点数量
* @param numOfReplicas 需要额外分配的节点数量
* @return 一个整数数组,包含以下信息:
* 索引 0: 允许分配的节点数量(除了已经选择的节点之外)。
* 索引 1: 每个机架允许分配的最大节点数。这与已选择的节点数无关,因为它是根据目标副本数量计算的
*/
private int[] getMaxNodesPerRack(int numOfChosen, int numOfReplicas) {
int clusterSize = clusterMap.getNumOfLeaves(); // 获取集群的总的节点数
int totalNumOfReplicas = numOfChosen + numOfReplicas;
if (totalNumOfReplicas > clusterSize) {
numOfReplicas -= (totalNumOfReplicas-clusterSize); // 减去多出的部分获取需要额外分配的replica数量
totalNumOfReplicas = clusterSize;
}
// 获取集群的机架数量
int numOfRacks = clusterMap.getNumOfRacks();
if (numOfRacks == 1 || totalNumOfReplicas <= 1) { // 如果机架数量为1,或者replication factor 为 1
return new int[] {numOfReplicas, totalNumOfReplicas};
}
int maxNodesPerRack = (totalNumOfReplicas-1)/numOfRacks + 1 + 1;
if (maxNodesPerRack == totalNumOfReplicas) {
maxNodesPerRack--;
}
return new int[] {numOfReplicas, maxNodesPerRack};
}
从代码可以看到
- 由于当前的集群规模可能在所有机器都承担一个副本的情况下依然无法满足副本要求,因此,根据当前集群的规模,重新计算了额外需要的副本数为numOfReplicas,总的副本数为totalNumOfReplicas
if (totalNumOfReplicas > clusterSize) { numOfReplicas -= (totalNumOfReplicas-clusterSize); // 减去多出的部分获取需要额外分配的replica数量 totalNumOfReplicas = clusterSize; } - 当集群只有一个机架,或者这个Block的总副本数为1的时候,单个机架允许分配的最大副本数就是总的副本数totalNumOfReplicas
if (numOfRacks == 1 || totalNumOfReplicas <= 1) { return new int[] {numOfReplicas, totalNumOfReplicas}; } - 正常的一个多机架、多副本的情况,一个Block在单个机架的最大副本数计算方式如下:
对于这个公式的理解为:int maxNodesPerRack = (totalNumOfReplicas-1)/numOfRacks + 2;- 首先,保证了在多机架、多副本的情况下,一个Block在单个机架的最大副本数不小于2,即保证了最大副本数的下限
- 同时,假设将副本完全均分在每一个机架上,那么有两种情况,刚好完全均分(10个副本均分在5个机架上),或者有一部分的机架上的副本数比另一部分机架的副本数(10个副本均分在3个机架)多1。无论那种情况,机架上最多的副本数为 (totalNumOfReplicas-1)/numOfRacks + 1,再加1进行适当松弛,其结果为(totalNumOfReplicas-1)/numOfRacks + 2
假设集群机架数量为3,在Block的副本数变化的情况下,(尽量)完全均匀分布时机架上的最大副本数,以及(totalNumOfReplicas-1)/numOfRacks+1的结果以及最后获得的maxNodesPerRack的结果如下表所示:
| 副本数 | 完全均分时机架上的最大副本数 | (totalNumOfReplicas-1)/numOfRacks + 1 | maxNodesPerRack |
|---|---|---|---|
| 1 | 1 | 1 | 2 |
| 2 | 1 | 1 | 2 |
| 3 | 1 | 1 | 2 |
| 4 | 2 | 2 | 3 |
| 5 | 2 | 2 | 3 |
| 6 | 2 | 2 | 3 |
| 7 | 3 | 3 | 4 |
StoragePolicy和StorageType简介
HDFS的StoragePolicy代表了一个HDFS文件对存储介质的选择和倾向,根据选择存储介质的不同策略,一个StoragePolicy需要表达出下面三种信息:
- 创建一个新的Block的时候,所倾向于将副本存放到的存储介质
- 创建一个新的Block的时候,如果所倾向的存储介质不够,应该退而求其次的存储介质
- 在进行副本的复制的时候,如果所倾向的存储介质不够,应该退而求其次的存储介质
存储介质(Storage Media)在HDFS中由StorageType表达:
public enum StorageType {
// sorted by the speed of the storage types, from fast to slow
RAM_DISK(true),
SSD(false),
DISK(false),
ARCHIVE(false);
private final boolean isTransient;
public static final StorageType DEFAULT = DISK; // 默认的存储介质是Disk
一个StoragePolicy除了ID和名字,还包含上面所讲的三种情况下的存储介质:
public class BlockStoragePolicy {
public static final Logger LOG = LoggerFactory.getLogger(BlockStoragePolicy
.class);
/** A 4-bit policy ID */
private final byte id;
/** Policy name */
private final String name;
// 创建一个新的Block的时候,所倾向于将副本存放到的存储介质
private final StorageType[] storageTypes;
// 创建一个新的Block的时候,如果所倾向的存储介质不够,应该退而求其次的存储介质
private final StorageType[] creationFallbacks;
// 在进行副本的复制的时候,如果所倾向的存储介质不够,应该退而求其次的存储介质
private final StorageType[] replicationFallbacks;
HDFS通过预定义的方式定义了几种不同的StoragePolicy。在通过HDFS的客户端写文件的时候,用户可以指定StoragePolicy,但是显然必须在预定义的StoragePolicy范围内。这些预定义的StoragePolicy都定义在BlockStoragePolicySuite中,如下所示:
------------------------------------ BlockStoragePolicySuite.java ----------------------------------------
public static BlockStoragePolicySuite createDefaultSuite() {
final BlockStoragePolicy[] policies =
new BlockStoragePolicy[1 << ID_BIT_LENGTH];
........
final byte allssdId = HdfsConstants.ALLSSD_STORAGE_POLICY_ID;
policies[allssdId] = new BlockStoragePolicy(allssdId,
HdfsConstants.ALLSSD_STORAGE_POLICY_NAME,
new StorageType[]{StorageType.SSD}, // 所有的副本都是SSD
new StorageType[]{StorageType.DISK},
new StorageType[]{StorageType.DISK});
....
final byte hotId = HdfsConstants.Hot;
policies[hotId] = new BlockStoragePolicy(hotId,
HdfsConstants.HOT_STORAGE_POLICY_NAME,
new StorageType[]{StorageType.DISK}, // 所有的副本都是Disk
StorageType.EMPTY_ARRAY,
new StorageType[]{StorageType.ARCHIVE});
.......
return new BlockStoragePolicySuite(hotId, policies); // 默认的StoragePolicy是hotId
}
我们以上面的默认的StoragePolicy HOT_STORAGE_POLICY_ID(即用户没有显式指定任何StoragePolicy的时候所使用的默认的StoragePolicy)为例解释其含义:
final byte hotId = HdfsConstants.HOT_STORAGE_POLICY_ID;
policies[hotId] = new BlockStoragePolicy(hotId,
HdfsConstants.HOT_STORAGE_POLICY_NAME,
new StorageType[]{StorageType.DISK}, // 创建新的Block的时候,所有的副本都是Disk
StorageType.EMPTY_ARRAY, // 没有fallback的类型,即创建新的副本的时候,如果Disk不够,则无法选择足够的Storage
new StorageType[]{StorageType.ARCHIVE}); // ARCHIVE的类型,即副本复制的时候,如果Disk不够,则选择Archive类型的StorageType
这个默认的StoragePolicy的含义是:
- storageTypes = {DISK},其含义为,创建一个新的Block的时候,所有的Replica都放在DISK上
- creationFallbacks = {},其含义为,如果DISK不够用,那么创建一个新的Block的时候(首个Replica),没有提供Fallback的StorageType方案,因此会造成无法选择足够的Storage
- replicationFallbacks = {ARCHIVE},其含义为,如果DISK不够用,那么其副本(非首个Replica)可以使用ARCHIVE的StorageType
下面的列表显示了HDFS支持的不同的StoragePolicy的storageTypes, createFallbacks以及replicationFallbacks:
| Policy ID | Policy Name | Block Placement (n replicas) | Fallback storages for creation | Fallback storages for replication |
|---|---|---|---|---|
| 15 | Lazy_Persist | RAM_DISK: 1, DISK: n-1 | DISK | DISK |
| 12 | All_SSD | SSD: n | DISK | DISK |
| 10 | One_SSD | SSD: 1, DISK: n-1 | SSD, DISK | SSD, DISK |
| 7 | Hot (default) | DISK: n | ARCHIVE | |
| 5 | Warm | DISK: 1, ARCHIVE: n-1 | ARCHIVE, DISK | ARCHIVE, DISK |
| 2 | Cold | ARCHIVE: n | ||
| 1 | Provided | PROVIDED: 1, DISK: n-1 | PROVIDED, DISK | PROVIDED, DISK |
StoragePolicy在整个读写流程中的使用过程为:
- 客户端写文件的时候,设置自己的StoragePolicy,默认是Hot;
- NameNode在为该文件的Block的副本确定位置的时候,会按照文件的StoragePolicy的要求选择Replica,因为此时NameNode端通过DataNode的汇报,是有其所有的DataNodeStorageInfo的信息的;
- 客户端拿到了NameNode的副本的放置结果,同对应的DataNode通信,也会携带这个StoragePolicy的要求。DataNode端的BlockReceiver在处理这个写请求的时候,会按照这个StoragePolicy的要求进行Volume的选择;
在为Block选择副本过程中考虑StoragePolicy
BlockStoragePolicy的chooseStorageTypes()方法根据当前Block的总副本数,已经选择的Replica的StorageType,以及不可用的StorageType、以及是否为新创建一个Block的场景,选择合适的存储类型列表:
public List<StorageType> chooseStorageTypes(final short replication, // 总副本数,即replication factor
final Iterable<StorageType> chosen, // 已经选择的节点的StorageType
final EnumSet<StorageType> unavailables, // 不可用的StorageType
final boolean isNewBlock) { // 当前的使用场景是否为创建一个新的Block
final List<StorageType> excess = new LinkedList<StorageType>();
final List<StorageType> storageTypes = chooseStorageTypes(
replication, chosen, excess); // storageTypes中存放了还需要哪些存储类型,excess中存放了已选择的存储类型中不在全部存储类型中的那一部分
final int expectedSize = storageTypes.size() - excess.size(); // 还需要的存储类型的数量,减去已选择但是不存在的那一部分
final List<StorageType> removed = new LinkedList<StorageType>();
//从后往前遍历每一个StorageType, 如果unavailables中包含这个StorageType,就计算对应的fallback StorageType,
for(int i = storageTypes.size() - 1; i >= 0; i--) {
// replace/remove unavailable storage types.
final StorageType t = storageTypes.get(i);
if (unavailables.contains(t)) { // 选定的这个StorageType不可用,因此需要fallback
// 是否为创建新的Block,选择对应的creationFallback,和ReplicationFallback
final StorageType fallback = isNewBlock?
getCreationFallback(unavailables)
: getReplicationFallback(unavailables);
if (fallback == null) { // 没有fallback的storage type
removed.add(storageTypes.remove(i)); // 从storageTypes中删除掉这个不可用并且没有找到fallback的StorageType
} else {
storageTypes.set(i, fallback); // 找到了fallback方法,则设置到位置i上
}
}
}
// 在fallback以后的storageType中删掉excess中的部分,因为fallback以后确定的storage type如果在excess中存在,
// 就说明这个StorageType在已经选择的StorageType中已经有了,因此是不需要的
// remove excess storage types after fallback replacement.
diff(storageTypes, excess, null);
return storageTypes;
}
private List<StorageType> chooseStorageTypes(final short replication,
final Iterable<StorageType> chosen, final List<StorageType> excess) {
// 基于当前的这个StoragePolcy,为这个Block的每一个副本确认StorageType,因此types的大小肯定等于replication即副本数
final List<StorageType> types = chooseStorageTypes(replication);
// 计算完成以后,chosen 中在types中存在的就删掉,在types不存在的就放入excess中
diff(types, chosen, excess);
return types; // 根据副本所需要的全部存储类型和已选择的存储类型,计算出还需要的存储类型。这个数量肯定是和还额外需要的副本数一致的
}
private static void diff(List<StorageType> t, Iterable<StorageType> c,
List<StorageType> e) {
for(StorageType storagetype : c) {
final int i = t.indexOf(storagetype);
if (i >= 0) {// 如果已选择的存储类型在全部的存储类型中已经存在,那么就从全部的存储类型中去掉
t.remove(i);
} else if (e != null) { // 如果已选择的存储类型在全部的存储类型中不存在,那么就添加到execess中
e.add(storagetype);
}
}
}
方法chooseStorageTypes()的基本步骤为:
选择需要的存储类型
final List<StorageType> excess = new LinkedList<StorageType>(); final List<StorageType> storageTypes = chooseStorageTypes(replication, chosen, excess);调用重载的chooseStorageTypes() 方法,获取所需的存储类型列表 storageTypes 和多余的存储类型列表 excess。storageTypes中存放的是为还未分配的副本所决定的存储类型,excess中存放的是目前chosen()中的存储类型不在对应的StorageType中的存储类型
计算预期的存储类型数量
final int expectedSize = storageTypes.size() - excess.size();计算还需要的存储类型数量,减去已经存在但多余的存储类型。
如果当前确定的StorageType在unavailables中,则意味着这个StorageType不需要考虑了,必须Fallback:
final List<StorageType> removed = new LinkedList<StorageType>(); for(int i = storageTypes.size() - 1; i >= 0; i--) { final StorageType t = storageTypes.get(i); if (unavailables.contains(t)) { // 选定的这个StorageType不可用,因此需要fallback final StorageType fallback = isNewBlock? getCreationFallback(unavailables) : getReplicationFallback(unavailables); if (fallback == null) { removed.add(storageTypes.remove(i)); } else { storageTypes.set(i, fallback); } } }- 从后往前遍历 storageTypes,检查是否包含不可用的存储类型。
- 如果不可用,根据是否为新块的场景(这个Block的第一个Replica),选择相应的 fallback 存储类型(getCreationFallback 或 getReplicationFallback)。
- 如果没有 fallback 存储类型,则从 storageTypes 中移除该类型;否则,替换为 fallback 类型。
经过这一轮计算,得到了经过fallback以后的StorageType需求
移除多余的存储类型
diff(storageTypes, excess, null);在经过 fallback 处理后,从 storageTypes 中删除掉 excess 中存在的部分,因为这些类型在 chosen 中已经有了,不需要重复。
返回经过fallback以后的StorageType。chooseTargets()方法会根据这个选定以后的StorageType尝试为Replica进行位置分配。
基本示例:
当前,我们在为replication factor = 5的一个文件的一个Block分配副本,这个文件使用的StoragePolicy是All_SSD,因此默认全部Replica使用SSD,SSD不够用的情况下,不论是新创建的Block的第一个Replica还是后面的Replica,可以使用DISK。
- 预期正常情况下,5个Replica全部分配到SSD上,因此他们的StorageType是{SSD,SSD,SSD,SSD,SSD},还没有unavailableStorageType。
- 经过一轮选择,我们只为第一个Replica找到了一个可用的SSD(参数中的chosen),就再也找不到合适的SSD为剩下的Replica分配了;
- 因此目前还有四个Replica有待分配Storage,他们的StorageType目前是{SSD,SSD,SSD,SSD},由于我们目前已经找不到多余的SSD了,因此重试前将SSD这种类型的StorageType添加到unavailableStorages中。
- 重试的时候,当前的需求是为4个副本寻找SSD的StorageType,目前的状态是,已经成功为一个副本选择了StorageType为SSD(chosen)的存储,由于unavailableStorages中是{SSD},已经包含了SSD, 因此不能再使用All_SSD原生的StorageType SSD了,原先的{SSD,SSD,SSD,SSD}需要进行fallback。由于不是创建Block的第一个replica(isNewBlock=false),因此使用replicationFallback(
{DISK}),剩余四个Replica的StorageType确定为{DISK, DISK, DISK, DISK},然后基于这个新的storageTypes,基于chooseTargets()寻找Storage - 这时候也基于DISK的StorageType,为两个副本找到了Storage,还剩下两个副本没有找到合适的Storage。这时候,就将DISK加入到unavailableStorages中,即,目前unavailableStorages是{SSD, DISK},准备继续再重试。
- 根据All_SSD这个StoragePolicy,这两个副本的原始的StorageType需求依然是{SSD, SSD}。由于unavailableStorages中已经包含了SSD,因此不能再使用SSD了,尝试Fallback并依然使用replicationFallback中的{DISK}。由于此时的{DISK}也已经在unavailableStorages中了,故已经无法再选择出任何可用的StorageTypes了。副本选择不足,结束。
将选中的节点进行排序组合为一个Pipeline
由于HDFS在多副本的情况下的写入是以流水线的方式写入的,如下所示。因此,有必要根据节点距离的远近进行排序,确保位置上最近的节点在写流水线上也是相邻的,提高写入效率:
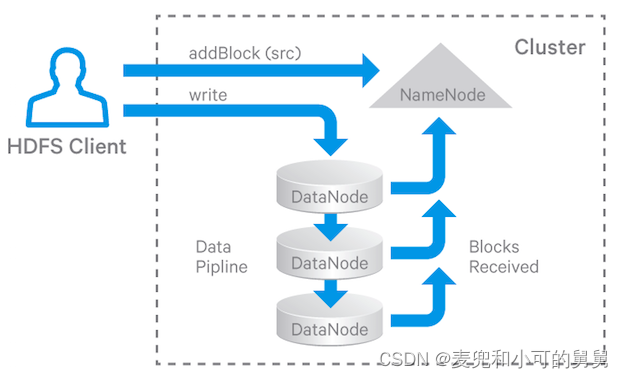
方法 getPipeline() 就是用来形成一个节点的流水线(pipeline)。具体来说,它根据从写入节点(writer)到存储节点(storages)的最短路径形成一个节点序列。这个过程类似于解决旅行商问题(TSP),即寻找经过所有节点的最短路径,代码比较简单,如下所示:
private DatanodeStorageInfo[] getPipeline(Node writer,
DatanodeStorageInfo[] storages) {
if (storages.length == 0) {
return storages;
}
synchronized(clusterMap) {
int index=0;
// 如果没有写入这信息,或者writer根本不是集群中的节点,那么就将第一个节点作为客户端节点
if (writer == null || !clusterMap.contains(writer)) {
writer = storages[0].getDatanodeDescriptor();
}
// 遍历所有的选中节点,依次进行排序
for(; index < storages.length; index++) {
DatanodeStorageInfo shortestStorage = storages[index];
int shortestDistance = clusterMap.getDistance(writer,
shortestStorage.getDatanodeDescriptor());
int shortestIndex = index;
//
for(int i = index + 1; i < storages.length; i++) {
int currentDistance = clusterMap.getDistance(writer,
storages[i].getDatanodeDescriptor());
if (shortestDistance>currentDistance) { // 当前节点的距离比index位置的节点的距离更小
shortestDistance = currentDistance; // 保存当前的最小距离
shortestStorage = storages[i]; // 保存最小距离的Storage
shortestIndex = i; // 保存最小距离的Storage 的index
}
}
//switch position index & shortestIndex
if (index != shortestIndex) {
storages[shortestIndex] = storages[index];
storages[index] = shortestStorage; // 将最小距离的这个Storage放到当前的比较位置
}
writer = shortestStorage.getDatanodeDescriptor();
}
}
return storages;
}
其中,最关键的,对节点距离的计算是通过方法getDistance()进行的,它的实现基于节点树结构,假设从一个节点到其父节点的距离为1。两个节点之间的距离通过求它们到最近公共祖先的距离之和来计算:
public int getDistance(Node node1, Node node2) {
.....
int level1=node1.getLevel(), level2=node2.getLevel();
// 层级较深的节点逐渐向上回溯,同时距离加1
while(n1!=null && level1>level2) {
n1 = n1.getParent();
level1--;
dis++;
}
// 层级较深的节点逐渐向上回溯,同时距离加1
while(n2!=null && level2>level1) {
n2 = n2.getParent();
level2--;
dis++;
}
// 层级相同以后,一起向上回溯,直到找到公共祖先。每共同向上回溯一步,距离+2
while(n1!=null && n2!=null && n1.getParent()!=n2.getParent()) {
n1=n1.getParent();
n2=n2.getParent();
dis+=2;
}
...
return dis+2;
}
假设有以下节点:
- node1: A
- node2: B
树结构如下图所示:
Root
/ \
A C
/ \
B D
计算距离步骤:
节点层级:
- node1 (A) 的层级为1
- node2 (B) 的层级为2
对齐层级:
- node1 (A) 和 node2 (B) 层级不同,所以将层级较高的 node2 (B) 移动到父节点 C,距离 dis 增加1。
寻找最近公共祖先:
- 现在 node1 (A) 和 node2 © 在同一层级,继续向上移动:
- node1 (A) 移动到 Root
- node2 © 移动到 Root
- 距离 dis 增加2(因为两个节点各自移动一次)
返回结果: 总距离 dis = 1 + 2 = 3
所以,节点 A 和 B 之间的距离为 3。这个方法通过对齐层级和找到最近公共祖先来计算两个节点之间的距离。
块放置失败以后的关键日志
上面讲过chooseRandom()方法会根据我们已经确定的范围(同主机、同机架、远程机架)以及其他条件来随机选择机器然后选择机器上的存储,即:1
- 通过方法isGoodDatanode()确定是否是合适的候选机器。只要有条件无法满足,就放弃该机器,并打印放弃原因:
boolean isGoodDatanode(DatanodeDescriptor node,
int maxTargetPerRack, boolean considerLoad,
List<DatanodeStorageInfo> results,
boolean avoidStaleNodes) {
// check if the node is (being) decommissioned
if (!node.isInService()) {
logNodeIsNotChosen(node, "the node isn't in service."); // 打印原因
return false;
}
if (avoidStaleNodes) {
if (node.isStale(this.staleInterval)) {
logNodeIsNotChosen(node, "the node is stale "); // 打印原因
return false;
}
}
....
private static void logNodeIsNotChosen(DatanodeDescriptor node,
String reason) {
if (LOG.isDebugEnabled()) {
// build the error message for later use.
debugLoggingBuilder.get()
.append("\n Datanode ").append(node)
.append(" is not chosen since ").append(reason).append(".");
}
}
- 通过方法chooseStorage4Block()确定是否有合适的存储,如果没有合适的存储,也会告知是存储选择失败(但是没有告知没有合适Storage的具体原因)
DatanodeStorageInfo chooseStorage4Block(DatanodeDescriptor dnd,
long blockSize,
List<DatanodeStorageInfo> results,
StorageType storageType) {
DatanodeStorageInfo storage =
dnd.chooseStorage4Block(storageType, blockSize);
if (storage != null) {
results.add(storage);
} else {
// 打印这行日志,说明节点本身符合要求,但是没有任何一个符合要求的storage
logNodeIsNotChosen(dnd, "no good storage to place the block ");
}
return storage;
}
所以,我们可以根据这些关键的DEBUG日志,在系统发生该问题的时候,定位到其根本原因。
比如,在我们的这个出问题的集群写满以后,我们在打开了BlockPlacementPolicy的DEBUG日志的时候,看到了下面的日志:
2024-05-28 03:04:20,381 DEBUG org.apache.hadoop.hdfs.server.blockmanagement.BlockPlacementPolicy: Failed to choose from local rack (location = /default); the second replica is not found, retry choosing ramdomly
org.apache.hadoop.hdfs.server.blockmanagement.BlockPlacementPolicy$NotEnoughReplicasException: [
Node /default/10.8.4.105:50010 [
Datanode 10.8.4.105:50010 is not chosen since no good storage to place the block .
]
Node /default/10.8.3.105:50010 [
Datanode 10.8.3.105:50010 is not chosen since no good storage to place the block .
]
Node /default/10.8.2.105:50010 [
Datanode 10.8.2.105:50010 is not chosen since no good storage to place the block .
]
但是,其实如果不结合代码,我们是无法理解这条日志的准确含义的。
我们从日志中看到的,是这个节点并没有选择成为这个Block的候选节点。但是,问题是,这是不是为这个Block挑选节点的最终决定?即,当我们看到这一行日志的时候,我们是否可以断定,这是最终决定,这些节点在任何情况下都不可能被选作这个Block的存储节点了?因为对HDFS的节点选择策略稍有了解的都知道,整个节点选择策略是一个不断退而求其次的过程,比如,先选择与客户端在一台机器上的节点,然后选择在同一个机架的节点,然后再选择任意节点。因此,我们怀疑,这个日志只是为这个Block进行节点选择过程中的某一个约束条件下的失败日志,不证明代表最终的选择失败。
从上面的事故分析可以看到,事故第一次出现的事后,我们从日志中看到的大量FBR(Full Block Report)的异常转移了我们的视线,日志中大量的FBR的异常是块汇报失败导致,同时写文件
事故处理的最终方案
- 先解决系统的块汇报问题的直接报错,即将ipc.maximum.data.length从默认的64MB增大为128MB, 同时将块汇报的切分阈值dfs.blockreport.split.threshold从100K降低到20K。重启系统,FBR成功。
- 修改代码,将NameNode这一端的scheduledBlock的数量、DataNode这一端除去scheduledBlock占有后剩下的可用空间,都通过JMX暴露出来。这样,我们可以对这个指标进行提前预警,而不是在事故发生了以后才进行干预。
- 确定相同写数据问题再次发生时候的措施:
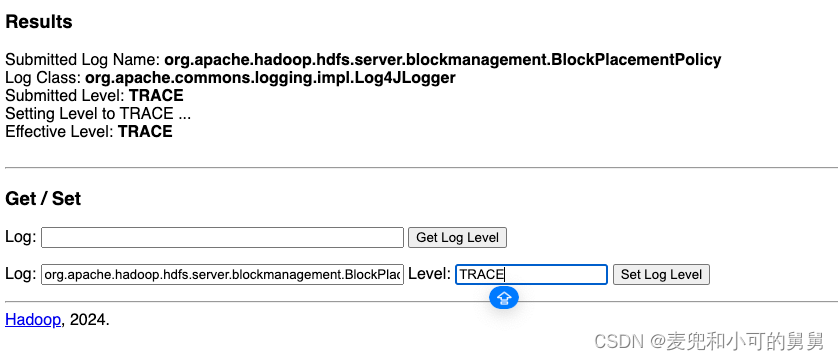
- 立刻打开BlockPlacementPolicyDefault的DEBUG日志。通过访问http://{{NameNode DNS Address}}:{{NameNode Port}}/logLevel页面,快速动态设置BlockPlacementPolicyDefault类的日志级别
- 在日志中抓取
is not chosen since以获取无法承载Replica的节点和无法承载的原因, - 修复对应DataNode的问题。
- 立刻打开BlockPlacementPolicyDefault的DEBUG日志。通过访问http://{{NameNode DNS Address}}:{{NameNode Port}}/logLevel页面,快速动态设置BlockPlacementPolicyDefault类的日志级别