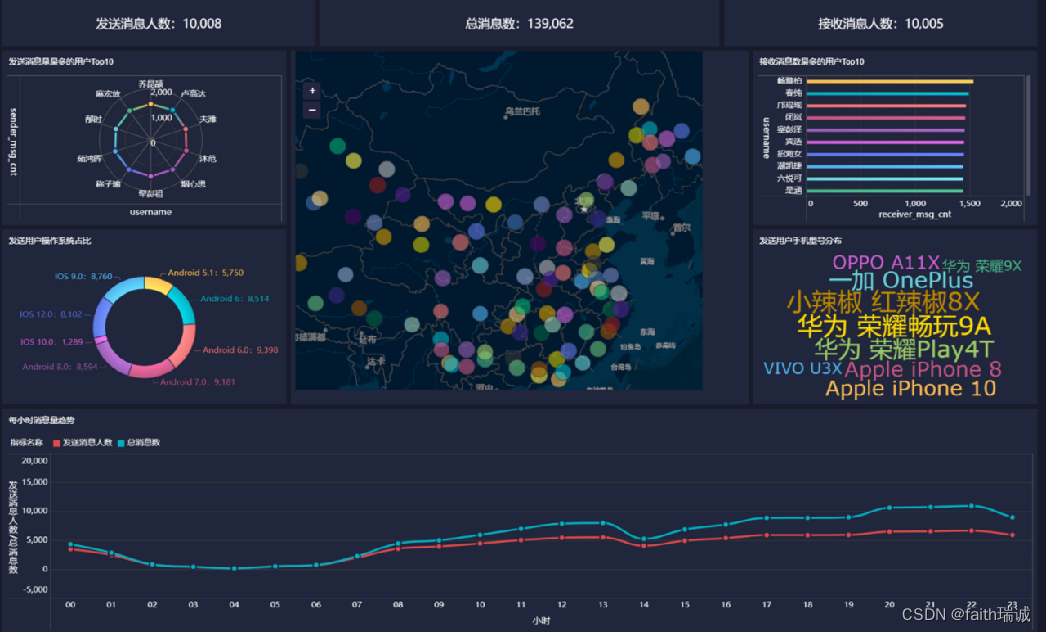
Apache Kylin的入门教程可以大致分为以下几个步骤:
一、概述
Apache Kylin是一个开源的分布式分析引擎,它提供Hadoop/Spark之上的SQL接口及多维分析(OLAP)能力以支持大数据分析。Kylin能在亚秒级查询PB级数据。
二、环境准备
- 操作系统:Kylin建议在Linux系统上运行,如CentOS 6.5+或Ubuntu 16.0.4+。
- Java环境:需要安装Java 1.8或更高版本的JDK或JRE。
- Hadoop环境:Kylin需要一个Hadoop集群来存储和处理大规模数据。Hadoop版本应为2.7+或3.1+(自v2.5起)。
- HBase环境:Kylin使用HBase作为存储引擎,因此需要先安装HBase 1.1+或2.0+(自v2.5起)。
- Zookeeper环境:Kylin需要Zookeeper来管理集群,因此需要安装Zookeeper。
三、安装与配置
- 下载与解压:从Apache Kylin官网下载适用于你的Hadoop版本的二进制包,并解压到目标目录。
- 配置环境变量:将Kylin的bin目录添加到PATH环境变量中,以便在命令行中直接运行Kylin命令。
- 配置属性文件:编辑Kylin的配置文件(如
kylin.properties),指定Hadoop、HBase和其他相关服务的配置信息。
四、数据导入与建模
- 数据导入:使用Hadoop的MapReduce作业或其他工具将数据导入到HBase中,供Kylin使用。
- 创建项目与模型:
- 在Kylin的Web界面中,点击“项目”菜单,创建新的项目并输入相关信息。
- 在项目中,点击“模型”菜单,创建新的数据模型,并定义数据源、维度和度量等信息。
- 构建Cube:在模型创建完成后,你需要构建一个Cube。Cube是Kylin的核心概念,它是一个多维数据集,用于加速查询。
五、查询与分析
在Cube构建完成后,你可以使用Kylin提供的SQL接口或REST API进行数据查询与分析。你可以在Kylin的Web界面的“查询”菜单中输入SQL语句进行查询,也可以通过其他工具或应用程序使用REST API进行数据查询。
六、硬件要求
- 运行Kylin的服务器建议配置为4核CPU、16GB内存和100GB磁盘。对于高负载的场景,建议使用24核CPU、64GB内存或更高的配置。
七、注意事项
- 在安装和配置过程中,确保按照官方文档和社区指南进行操作。
- 在进行数据建模和查询时,考虑数据的规模和复杂性,以优化性能和查询效率。
- 定期关注官方文档和社区更新,以获取最新的功能、修复和改进。
遵循以上步骤和注意事项,你应该能够成功入门Apache Kylin并开始使用它进行大数据分析。