- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊 | 接辅导、项目定制
目录
本周任务:
- 了解文本分类的基本流程
- 学习常用数据清洗方法
- 学习如何使用jieba实现英文分词
- 学习如何构建文本向量
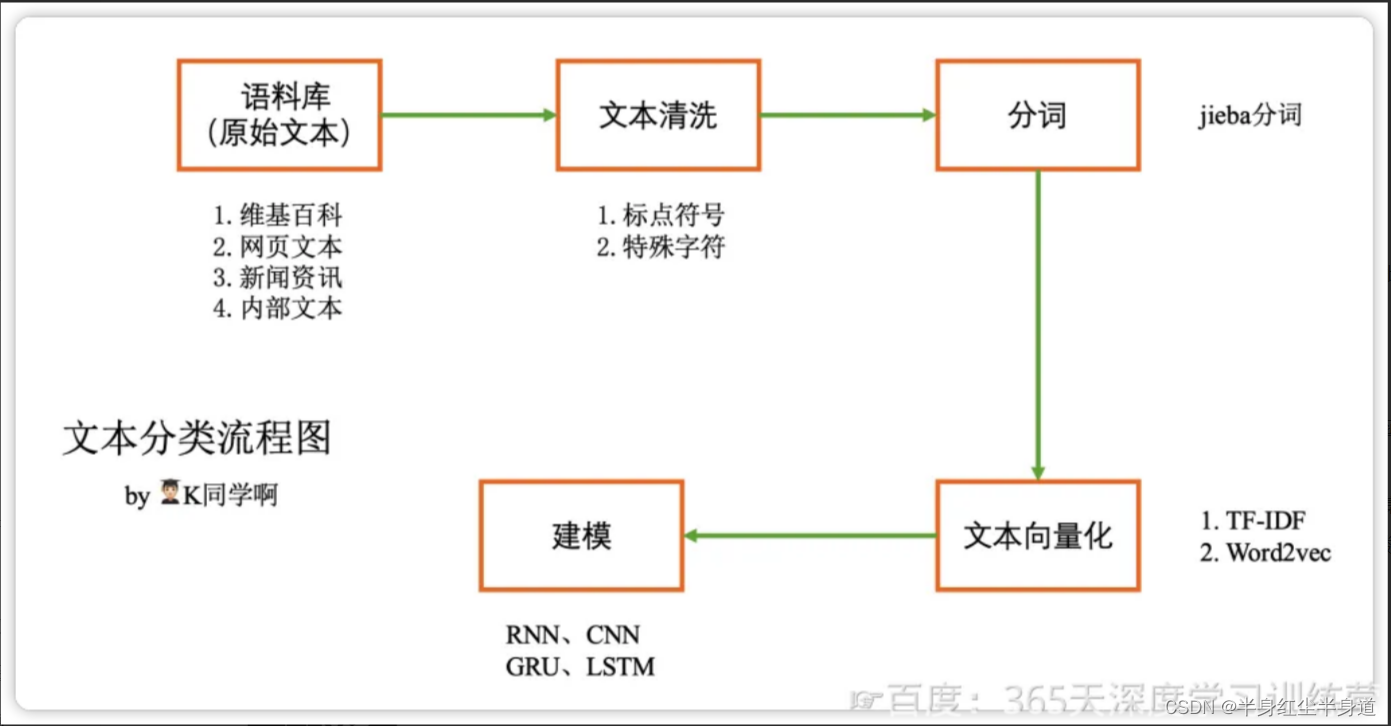
文本分类流程图:
需要的环境:
- pytorch
- torchtext库
- portalocker库
- torchdata
数据集:
AG News数据集是一个用于文本分类任务的广泛使用的数据集,特别是在新闻文章分类领域。该数据集由4类新闻文章组成,每类包含不同主题的新闻,具体类别如下:
- World(世界新闻)
- Sports(体育新闻)
- Business(商业新闻)
- Sci/Tech(科学和技术新闻)
torchtext.datasets.AG_NEWS()类加载的数据集是一个列表,其中每个条目都是一个元组(label, text) ,包含以下两个元素:
- text:一条新闻文章的文本内容。
- label:新闻文章所属的类别(一个整数,从1到4,分别对应世界、科技、体育和商业)
TextClassificationModel模型介绍:
TextClassificationModel 是一个用于文本分类任务的简单神经网络模型,通常包括一个嵌入层和一个线性层。
首先对文本进行嵌入,然后对句子嵌入之后的结果进行均值聚合。
模型结构
嵌入层 (EmbeddingBag):
- 该层用于将输入的文本数据转化为稠密的向量表示。
EmbeddingBag比Embedding更高效,因为它在计算时结合了嵌入和平均/加权操作,这对于处理变长的输入特别有用。
- 该层用于将输入的文本数据转化为稠密的向量表示。
线性层 (Linear):
- 该层接收来自嵌入层的输出,并将其映射到输出类别。输出类别的数量与分类任务中的类别数量一致。
模型结构图:

实现代码:
import torch
import torch.nn as nn
import torchvision
from torchvision import transforms, datasets
import os,PIL,pathlib,warnings
import torch
torch.utils.data.datapipes.utils.common.DILL_AVAILABLE = torch.utils._import_utils.dill_available()
warnings.filterwarnings("ignore")
#win10
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
from torchtext.datasets import AG_NEWS
train_iter = AG_NEWS(split='train')#加载 AG News 数据集
from torchtext.data.utils import get_tokenizer
from torchtext.vocab import build_vocab_from_iterator
#返回分词器
tokenizer = get_tokenizer('basic_english')
def yield_tokens(data_iter):
for _, text in data_iter:
yield tokenizer(text)
vocab = build_vocab_from_iterator(yield_tokens(train_iter), specials=["<unk>"])
vocab.set_default_index(vocab["<unk>"])#设置默认索引
print(vocab(['here', 'is', 'an', 'example']))
text_pipeline = lambda x: vocab(tokenizer(x))
label_pipeline = lambda x: int(x) - 1
print(text_pipeline('here is an example '))
print(label_pipeline('10'))
from torch.utils.data import DataLoader
def collate_batch(batch):
label_list,text_list,offsets =[],[],[0]
for(_label,_text)in batch:
#标签列表
label_list.append(label_pipeline(_label))
#文本列表
processed_text =torch.tensor(text_pipeline(_text),dtype=torch.int64)
text_list.append(processed_text)
#偏移量,即语句的总词汇量
offsets.append(processed_text.size(0))
label_list =torch.tensor(label_list,dtype=torch.int64)
text_list=torch.cat(text_list)
offsets=torch.tensor(offsets[:-1]).cumsum(dim=0)
#返回维度dim中输入元素的累计和
return label_list.to(device),text_list.to(device),offsets.to(device)
#数据加载器
dataloader =DataLoader(train_iter,batch_size=8,shuffle =False,collate_fn=collate_batch)
from torch import nn
class TextClassificationModel(nn.Module):
def __init__(self,vocab_size,embed_dim,num_class):
super(TextClassificationModel,self).__init__()
self.embedding =nn.EmbeddingBag(vocab_size,#词典大小
embed_dim,#嵌入的维度
sparse=False)#
self.fc =nn.Linear(embed_dim,num_class)
self.init_weights()
def init_weights(self):
initrange =0.5
self.embedding.weight.data.uniform_(-initrange,initrange)
self.fc.weight.data.uniform_(-initrange,initrange)
self.fc.bias.data.zero_()
def forward(self,text,offsets):
embedded =self.embedding(text,offsets)
return self.fc(embedded)
num_class = len(set([label for(label,text)in train_iter]))
vocab_size = len(vocab)
em_size = 64
model = TextClassificationModel(vocab_size,em_size,num_class).to(device)
import time
def train(dataloader):
model.train() #切换为训练模式
total_acc,train_loss,total_count =0,0,0
log_interval =500
start_time =time.time()
for idx,(label,text,offsets) in enumerate(dataloader):
predicted_label =model(text,offsets)
optimizer.zero_grad()#grad属性归零
loss =criterion(predicted_label,label)#计算网络输出和真实值之间的差距,labe1为真实值
loss.backward()#反向传播
optimizer.step() #每一步自动更新
#记录acc与loss
total_acc +=(predicted_label.argmax(1)==label).sum().item()
train_loss +=loss.item()
total_count +=label.size(0)
if idx %log_interval ==0 and idx >0:
elapsed =time.time()-start_time
print('|epoch {:1d}|{:4d}/{:4d}batches'
'|train_acc {:4.3f}train_loss {:4.5f}'.format(epoch,idx,len(dataloader),total_acc/total_count,train_loss/total_count))
total_acc,train_loss,total_count =0,0,0
start_time =time.time()
def evaluate(dataloader):
model.eval() #切换为测试模式
total_acc,train_loss,total_count =0,0,0
with torch.no_grad():
for idx,(label,text,offsets)in enumerate(dataloader):
predicted_label =model(text,offsets)
loss = criterion(predicted_label,label) #计算loss值#记录测试数据
total_acc +=(predicted_label.argmax(1)==label).sum().item()
train_loss +=loss.item()
total_count +=label.size(0)
return total_acc/total_count,train_loss/total_count
from torch.utils.data.dataset import random_split
from torchtext.data.functional import to_map_style_dataset
#超参数
EPOCHS=10 #epoch
LR=5 #学习率
BATCH_SIZE=64 #batch size for training
criterion =torch.nn.CrossEntropyLoss()
optimizer =torch.optim.SGD(model.parameters(),lr=LR)
scheduler =torch.optim.lr_scheduler.StepLR(optimizer,1.0,gamma=0.1)
total_accu =None
train_iter,test_iter =AG_NEWS()#加载数据
train_dataset =to_map_style_dataset(train_iter)
test_dataset =to_map_style_dataset(test_iter)
num_train=int(len(train_dataset)*0.95)
split_train_,split_valid_=random_split(train_dataset,
[num_train,len(train_dataset)-num_train])
train_dataloader =DataLoader(split_train_,batch_size=BATCH_SIZE,
shuffle=True,collate_fn=collate_batch)
valid_dataloader =DataLoader(split_valid_,batch_size=BATCH_SIZE,
shuffle=True,collate_fn=collate_batch)
test_dataloader=DataLoader(test_dataset,batch_size=BATCH_SIZE,
shuffle=True,collate_fn=collate_batch)
for epoch in range(1,EPOCHS +1):
epoch_start_time =time.time()
train(train_dataloader)
val_acc,val_loss =evaluate(valid_dataloader)
if total_accu is not None and total_accu >val_acc:
scheduler.step()
else:
total_accu =val_acc
print('-'*69)
print('|epoch {:1d}|time:{:4.2f}s|'
'valid_acc {:4.3f}valid_loss {:4.3f}'.format(epoch,
time.time()-epoch_start_time,val_acc,val_loss))
print('-'*69)
print('Checking the results of test dataset.')
test_acc,test_loss =evaluate(test_dataloader)
print('test accuracy {:8.3f}'.format(test_acc))
报错:
ImportError: cannot import name 'DILL_AVAILABLE' from 'torch.utils.data.datapipes.utils.common' (D:\miniconda\envs\nlp_pytorch\lib\site-packages\torch\utils\data\datapipes\utils\common.py)
解决:torchdata pytorch2.3 报错-CSDN博客
import torch
torch.utils.data.datapipes.utils.common.DILL_AVAILABLE = torch.utils._import_utils.dill_available()
tps://github.com/pytorch/pytorch/pull/122616
结果:
[475, 21, 30, 5297]
[475, 21, 30, 5297]
9
|epoch 1| 500/1782batches|train_acc 0.719train_loss 0.01115
|epoch 1|1000/1782batches|train_acc 0.867train_loss 0.00620
|epoch 1|1500/1782batches|train_acc 0.882train_loss 0.00550
---------------------------------------------------------------------
|epoch 1|time:8.96s|valid_acc 0.898valid_loss 0.005
---------------------------------------------------------------------
|epoch 2| 500/1782batches|train_acc 0.903train_loss 0.00459
|epoch 2|1000/1782batches|train_acc 0.905train_loss 0.00440
|epoch 2|1500/1782batches|train_acc 0.907train_loss 0.00436
---------------------------------------------------------------------
|epoch 2|time:8.14s|valid_acc 0.884valid_loss 0.005
---------------------------------------------------------------------
|epoch 3| 500/1782batches|train_acc 0.925train_loss 0.00351
|epoch 3|1000/1782batches|train_acc 0.929train_loss 0.00339
|epoch 3|1500/1782batches|train_acc 0.928train_loss 0.00343
---------------------------------------------------------------------
|epoch 3|time:7.56s|valid_acc 0.912valid_loss 0.004
---------------------------------------------------------------------
|epoch 4| 500/1782batches|train_acc 0.930train_loss 0.00333
|epoch 4|1000/1782batches|train_acc 0.932train_loss 0.00327
|epoch 4|1500/1782batches|train_acc 0.931train_loss 0.00331
---------------------------------------------------------------------
|epoch 4|time:7.80s|valid_acc 0.913valid_loss 0.004
---------------------------------------------------------------------
|epoch 5| 500/1782batches|train_acc 0.933train_loss 0.00322
|epoch 5|1000/1782batches|train_acc 0.930train_loss 0.00330
|epoch 5|1500/1782batches|train_acc 0.934train_loss 0.00320
---------------------------------------------------------------------
|epoch 5|time:8.47s|valid_acc 0.914valid_loss 0.004
---------------------------------------------------------------------
|epoch 6| 500/1782batches|train_acc 0.937train_loss 0.00309
|epoch 6|1000/1782batches|train_acc 0.933train_loss 0.00324
|epoch 6|1500/1782batches|train_acc 0.932train_loss 0.00315
---------------------------------------------------------------------
|epoch 6|time:8.37s|valid_acc 0.912valid_loss 0.004
---------------------------------------------------------------------
|epoch 7| 500/1782batches|train_acc 0.936train_loss 0.00308
|epoch 7|1000/1782batches|train_acc 0.938train_loss 0.00298
|epoch 7|1500/1782batches|train_acc 0.934train_loss 0.00314
---------------------------------------------------------------------
|epoch 7|time:8.38s|valid_acc 0.914valid_loss 0.004
---------------------------------------------------------------------
|epoch 8| 500/1782batches|train_acc 0.938train_loss 0.00302
|epoch 8|1000/1782batches|train_acc 0.937train_loss 0.00306
|epoch 8|1500/1782batches|train_acc 0.934train_loss 0.00308
---------------------------------------------------------------------
|epoch 8|time:8.26s|valid_acc 0.915valid_loss 0.004
---------------------------------------------------------------------
|epoch 9| 500/1782batches|train_acc 0.939train_loss 0.00297
|epoch 9|1000/1782batches|train_acc 0.935train_loss 0.00316
|epoch 9|1500/1782batches|train_acc 0.934train_loss 0.00313
---------------------------------------------------------------------
|epoch 9|time:8.27s|valid_acc 0.915valid_loss 0.004
---------------------------------------------------------------------
|epoch 10| 500/1782batches|train_acc 0.935train_loss 0.00308
|epoch 10|1000/1782batches|train_acc 0.938train_loss 0.00301
|epoch 10|1500/1782batches|train_acc 0.936train_loss 0.00308
---------------------------------------------------------------------
|epoch 10|time:8.08s|valid_acc 0.915valid_loss 0.004
---------------------------------------------------------------------
Checking the results of test dataset.
test accuracy 0.908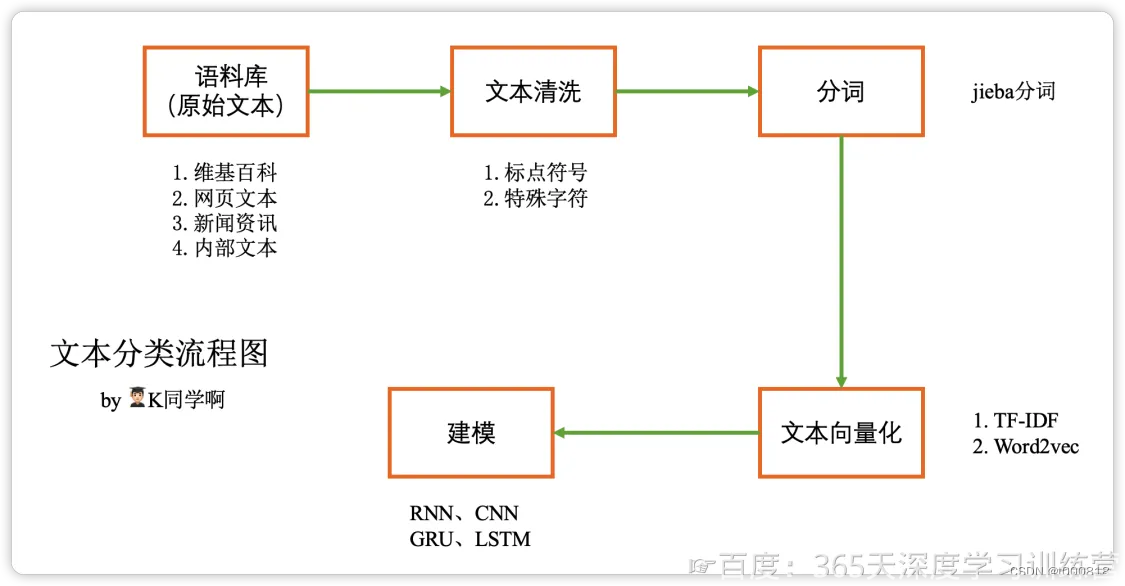
























![[网络基础]——计算机网络(OSI)参考模型 详解](https://img-blog.csdnimg.cn/direct/3b7ecfb50593488a85d6a18de8a57bc8.gif)



![[数据集][目标检测]csgo头部身体检测数据集VOC+YOLO格式1265张4类别](https://img-blog.csdnimg.cn/direct/96249d24a1b048ef877985ce3661202c.png)