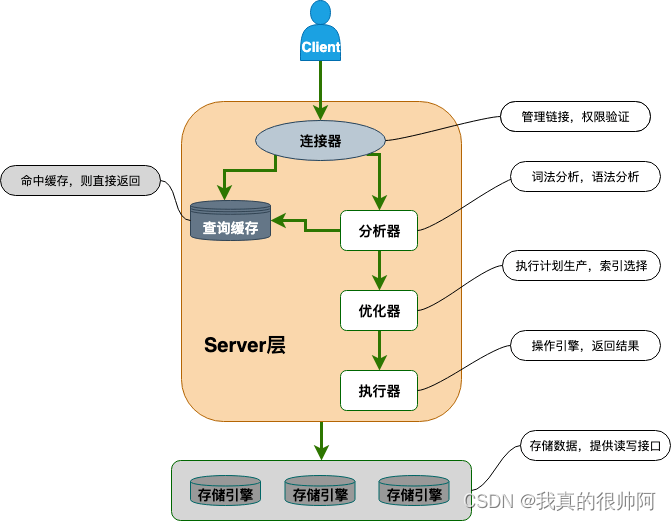
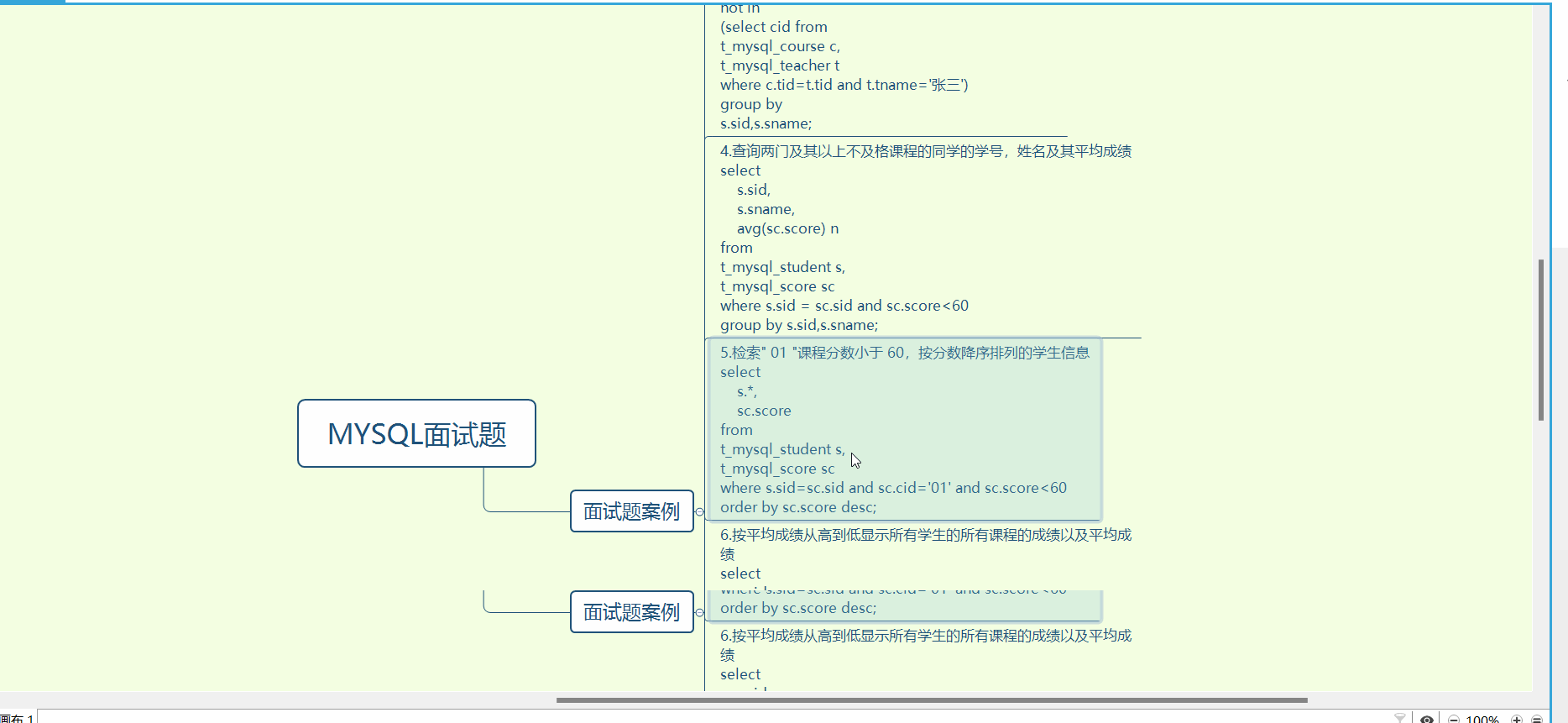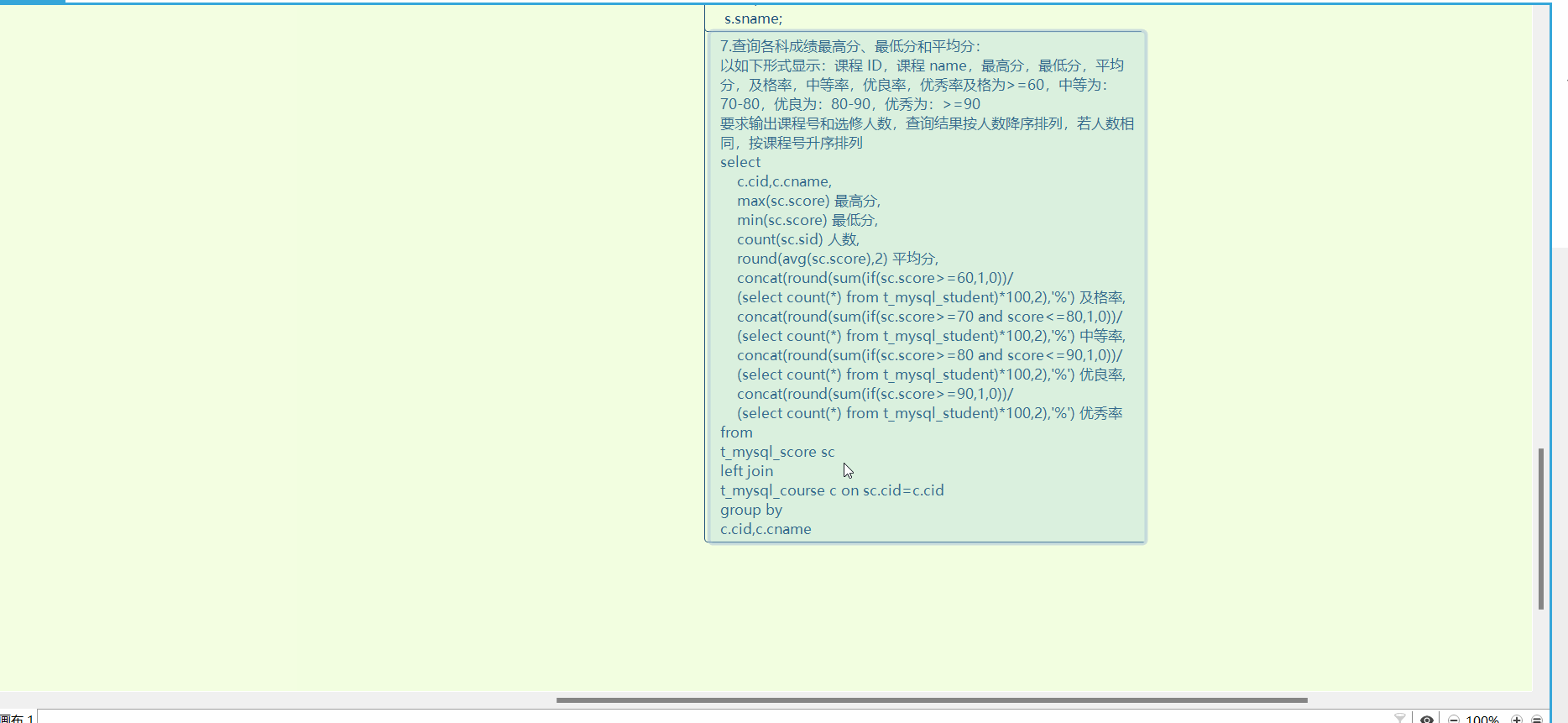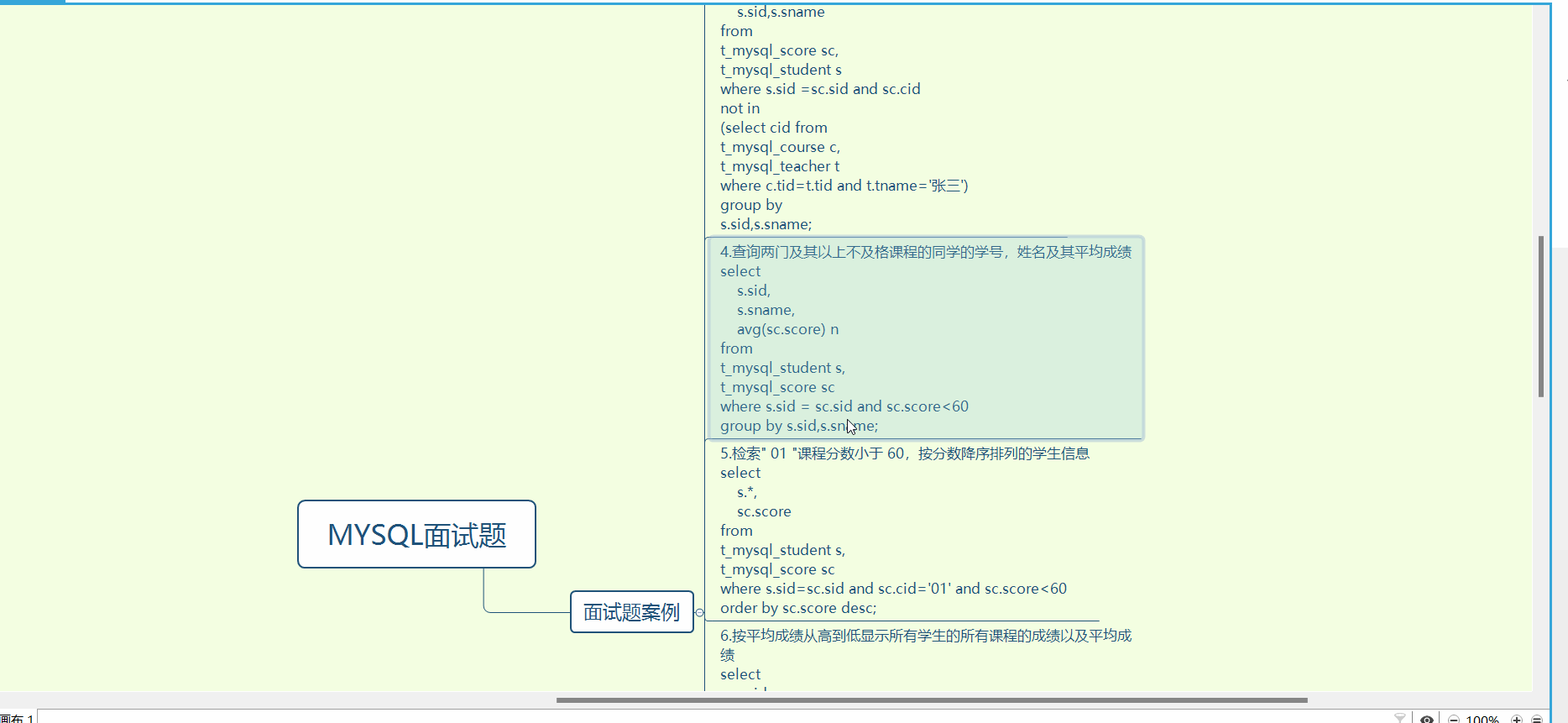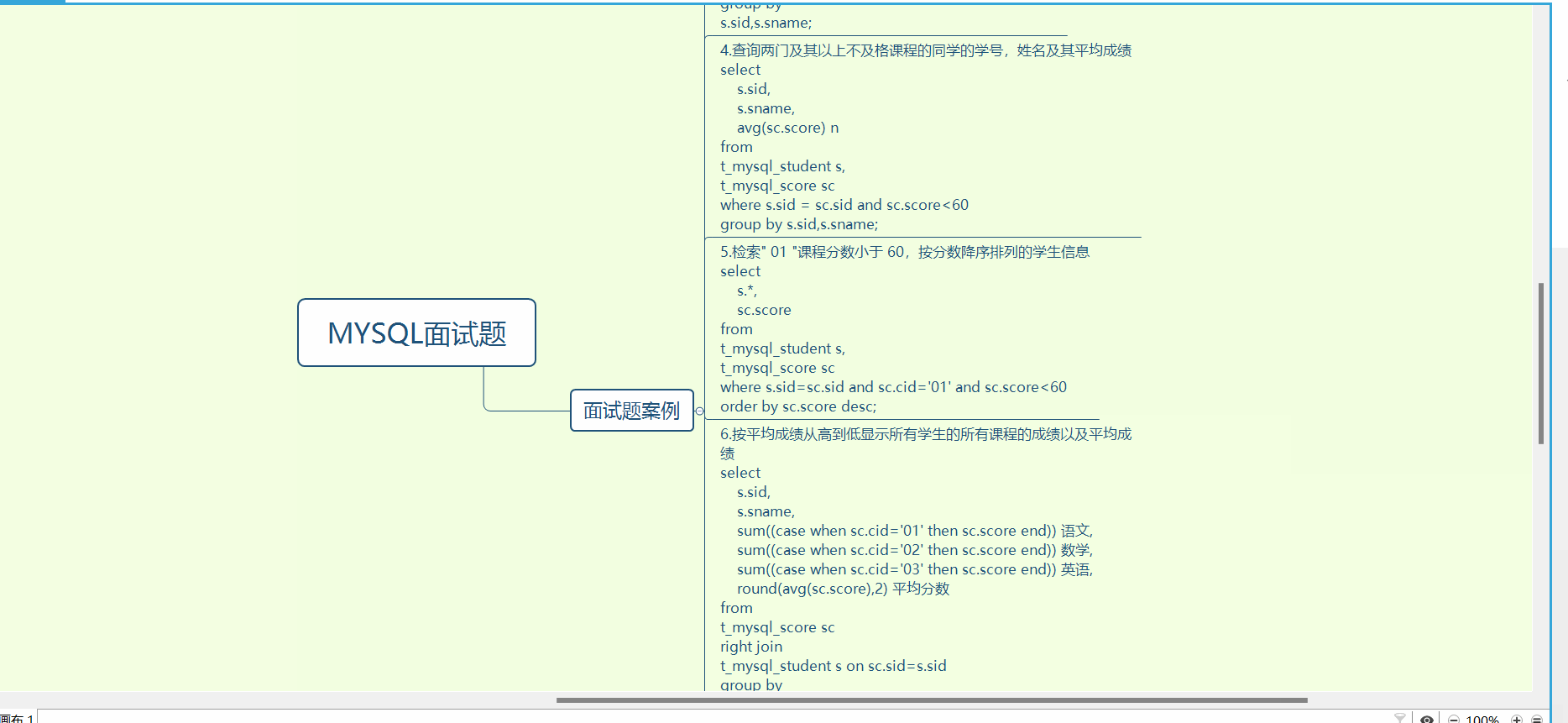
InnoDB是如何存储数据的?
InnoDB 的数据是按「数据页」为单位来读写的,默认数据页大小为 16 KB。每个数据页之间通过双向链表的形式组织起来,物理上不连续,但是逻辑上连续。
数据页内包含用户记录,每个记录之间用单向链表的方式组织起来,为了加快在数据页内高效查询记录,设计了一个页目录,页目录存储各个槽(分组),且主键值是有序的,于是可以通过二分查找法的方式进行检索从而提高效率。
为了高效查询记录所在的数据页,InnoDB 采用 b+ 树作为索引,每个节点都是一个数据页。
如果叶子节点存储的是实际数据的就是聚簇索引,一个表只能有一个聚簇索引;如果叶子节点存储的不是实际数据,而是主键值则就是二级索引,一个表中可以有多个二级索引。
在使用二级索引进行查找数据时,如果查询的数据能在二级索引找到,那么就是「索引覆盖」操作,如果查询的数据不在二级索引里,就需要先在二级索引找到主键值,需要去聚簇索引中获得数据行,这个过程就叫作「回表」。
间隙锁的工作原理
间隙锁,只存在于可重复读隔离级别,目的是为了解决可重复读隔离级别下幻读的现象。
假设,表中有一个范围 id 为(3,5)间隙锁,那么其他事务就无法插入 id = 4 这条记录了,这样就有效的防止幻读现象的发生。
心灵拷问:MySQL 到底是怎么加行级锁、间隙锁、临键锁的?_间隙锁怎么加-CSDN博客
Mysql的undolog redolog是干什么的
undolog和redolog都是在InnoDB引擎下才有的日志
undolog保证事务的原子性,有一个undolog版本链保存历史版本,可以进行回滚,这也在MVCC里面有所应用,MVCC就是基于readview决定快照读的时候去返回哪一个版本的数据
redolog主要有两份,在磁盘中有一份,在内存中也有一份,