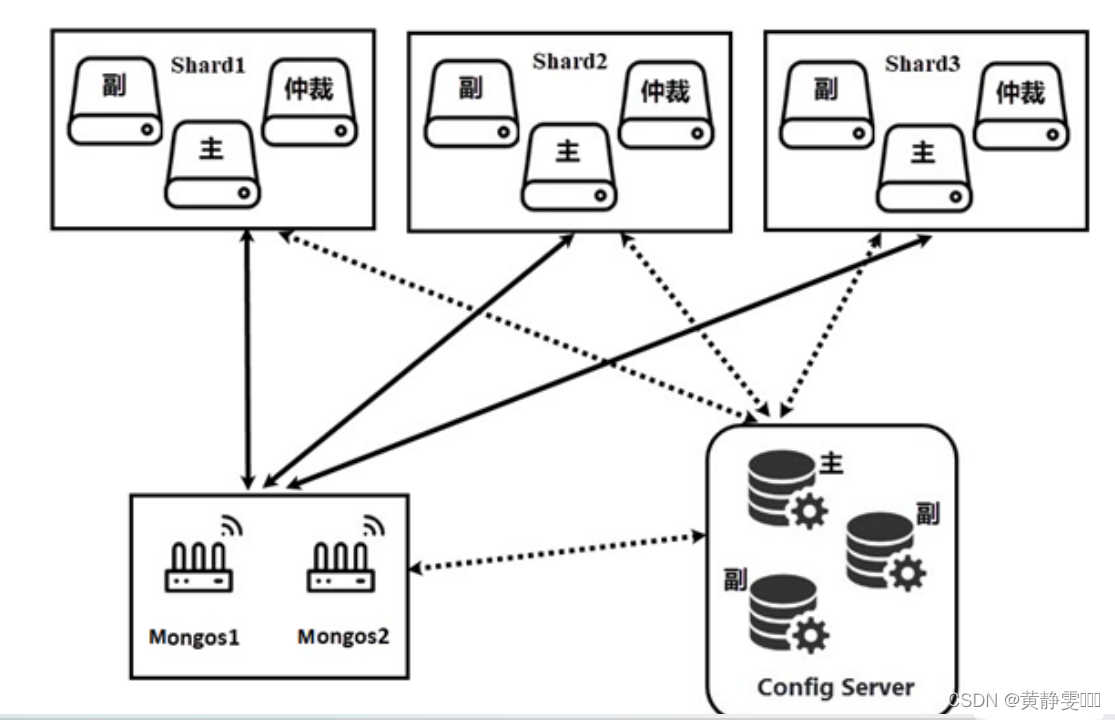
想识别出pdf页面右下角某处的编号。pdf是图片形式页面。查了下方法,有源码是先将页面提取成jpg,再用pytesseract提取图片文件中的内容。
直接用图片来识别。纯数字的图片,如条形码,可识别。带中文的不可以,很乱。

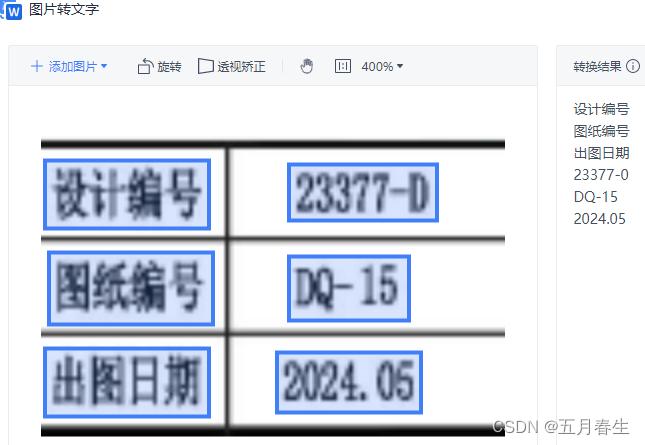
识别为:

如何形成wps图片中的文字识别效果呢?
import pytesseract
from PIL import Image
def extract_text_from_image(image_path):
image = Image.open(image_path)
text = pytesseract.image_to_string(image)
return text
image_path = r"D:\11.png"
text = extract_text_from_image(image_path)
print(f"图片内容:\n{text}\n")