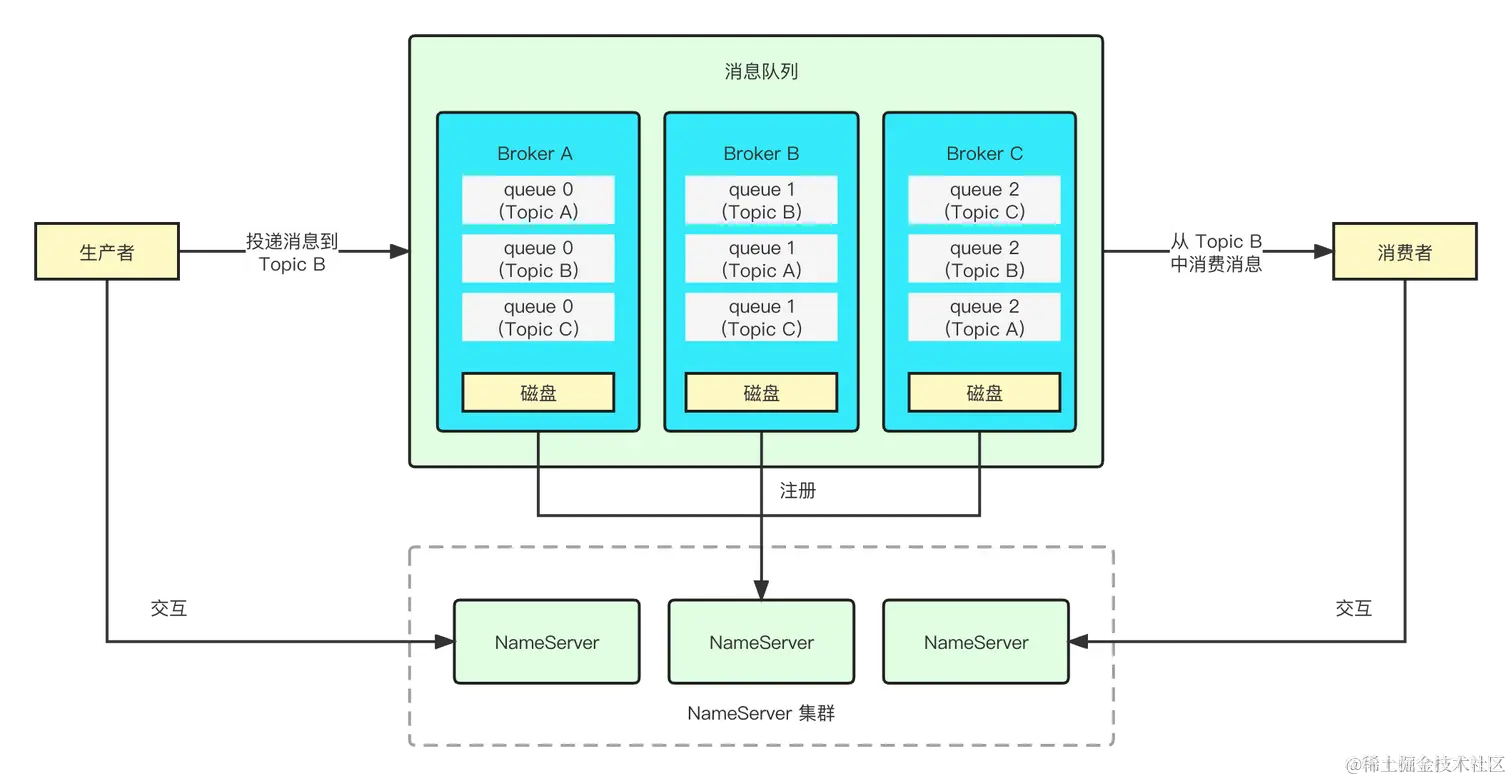
介绍
Hadoop 是一个开源框架,由 Apache Software Foundation 开发和维护,用于分布式存储和处理大规模数据集。Hadoop 允许用户通过简单的编程模型跨大型集群分布式处理大量数据。它特别适用于大数据应用,可以处理数千台服务器上的 PB 级数据。
Hadoop 的核心组件包括:
- Hadoop 分布式文件系统 (HDFS):
- HDFS 是 Hadoop 的核心组件,用于存储大量数据。它将数据分布式存储在多个节点上,确保数据的可靠性和高效访问。
- HDFS 通过将数据分割成块(通常是 128MB 或 256MB)并存储在多个节点上来实现数据的分布式存储。每个数据块都会在多个节点上保存副本,以实现数据的容错和高可用性。
- Hadoop YARN:
- YARN(Yet Another Resource Negotiator)是 Hadoop 的集群管理工具,负责管理资源和调度作业。
- YARN 将资源管理和作业调度/监控分为两个独立的实体:ResourceManager 和 NodeManager。ResourceManager 负责分配资源给应用程序,而 NodeManager 负责监控容器并确保它们按预期运行。
- Hadoop MapReduce:
- MapReduce 是 Hadoop 的编程模型,用于大规模数据处理。
- MapReduce 将数据处理任务分解为两个主要阶段:Map 阶段和 Reduce 阶段。Map 阶段将输入数据分割成小块并处理成键值对,而 Reduce 阶段则对中间结果进行聚合和总结。
除了这些核心组件,Hadoop 生态系统还包括其他工具和框架,如:
- Hive:一个数据仓库基础设施,提供数据摘要、查询和分析。
- Pig:一个高级平台,用于创建 MapReduce 程序,用于数据分析。
- HBase:一个分布式、可扩展、面向列的存储系统,用于随机实时读/写访问大规模数据集。
- Spark:一个用于大规模数据处理的快速通用计算引擎。
- Flume 和 Sqoop:用于数据采集和迁移的工具。
- Oozie:一个工作流调度系统,用于协调 Hadoop 作业。
Hadoop 适用于各种行业和用例,包括数据分析、日志处理、机器学习、推荐系统等。由于其开源性质和强大的社区支持,Hadoop 已经成为大数据处理的事实标准之一。
HDFS
Hadoop Distributed File System (HDFS) 是 Hadoop 应用程序的主要数据存储系统,它是一个分布式文件系统,设计用来跨多个物理服务器运行,以便处理大量数据。HDFS 适合运行在通用硬件上,并且是高度容错的,适合部署在廉价的硬件上。
HDFS 的关键特性包括:
- 高容错性:
- HDFS 通过在多个节点上存储数据的副本(默认为三个副本),来确保数据的可靠性和可用性。
- 如果一个节点失败,HDFS 能够在其他的副本上继续处理数据,从而确保了系统整体的鲁棒性。
- 高吞吐量:
- HDFS 适合处理大量数据集,它的设计目标是优化大规模数据集的吞吐量,而不是单个文件的操作速度。
- 它通过将大文件分割成块(block),并将这些块分布存储在集群中的不同节点上来实现高吞吐量。
- 大数据集:
- HDFS 适用于存储和分析大规模数据集,它支持存储 PB 级别的数据。
- 它通过其架构设计,使得可以轻松扩展存储容量,只需将新的节点添加到集群中即可。
- 简单的一致性模型:
- HDFS 提供了类似于传统文件系统的接口,但它有一个简化的一致性模型,主要是为了提高数据吞吐量。
- 文件一旦被创建、写入和关闭,就不需要改变,这有助于实现高吞吐量。
- 硬件故障的检测和快速恢复:
- HDFS 能够检测并快速响应硬件故障,通过维护多个副本,它可以在检测到故障后立即使用其他副本继续工作。
HDFS 的组件:
- NameNode:
- NameNode 是 HDFS 的主节点,负责维护文件系统的命名空间,管理文件系统树及整个文件系统的元数据。
- 它不存储实际的数据,而是存储文件的元数据,如文件和目录的权限信息、块映射信息等。
- DataNode:
- DataNode 是 HDFS 的从节点,负责存储实际的数据块。
- 每个数据块默认存储三个副本,这些副本可能分布在不同的 DataNode 上。
- Secondary NameNode:
- Secondary NameNode 不是 NameNode 的备份或热备,而是帮助 NameNode 维护文件系统元数据的辅助节点。
- 它定期合并 NameNode 的编辑日志(edits log)和文件系统镜像(fsimage),以防止编辑日志过大。
HDFS 适合于需要高吞吐量的大规模数据集的应用场景,例如大数据分析、日志处理和机器学习。它的设计目的是为了简化大规模数据集的处理,使得用户和应用程序无需关心数据是如何分布在集群中的细节。