由于文章篇幅太长了,这里分成两篇文章“上”和“下”进行学习,“上”篇在https://blog.csdn.net/csdn_xmj/article/details/139482432,这是“下”篇!
本文来源公众号“江大白”,仅用于学术分享,侵权删,干货满满。
原文链接:2W字长文,带你深入浅出视觉Transformer
以下文章来源于知乎:深度眸@知乎
作者:深度眸
链接:https://zhuanlan.zhihu.com/p/308301901
本文仅用于学术分享,如有侵权,请联系后台作删文处理
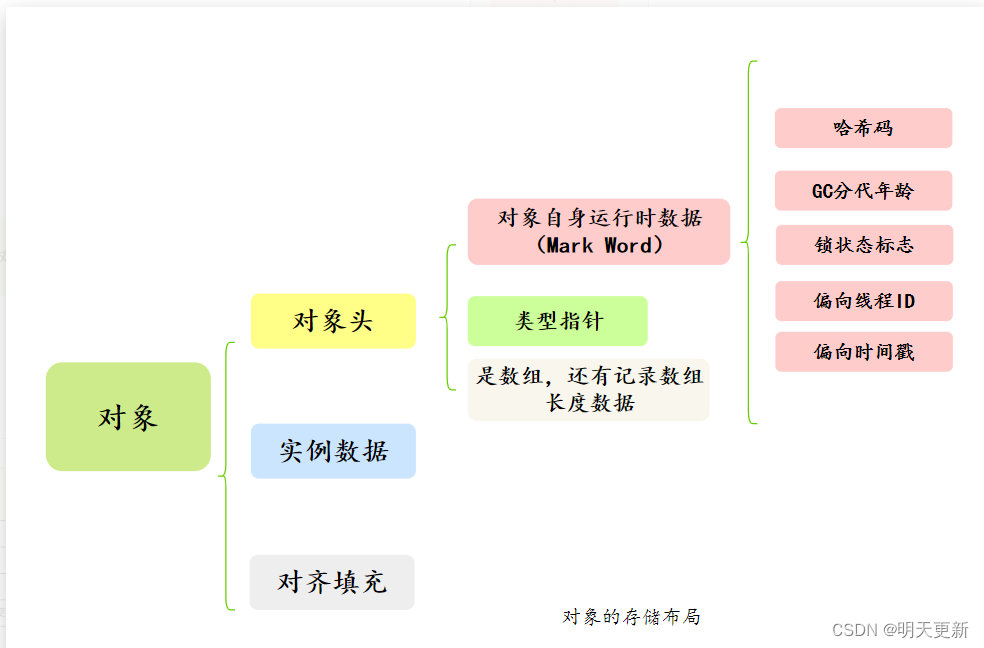
2 视觉领域的transformer
在理解了标准的transformer后,再来看视觉领域transformer就会非常简单,因为在cv领域应用transformer时候大家都有一个共识:尽量不改动transformer结构,这样才能和NLP领域发展对齐,所以大家理解cv里面的transformer操作是非常简单的。
2.1 分类vision transformer
论文题目:An Image is Worth 16x16 Words:Transformers for Image Recognition at Scale
论文地址:https://arxiv.org/abs/2010.11929
github: https://github.com/lucidrains/vit-pytorch
其做法超级简单,只含有编码器模块:
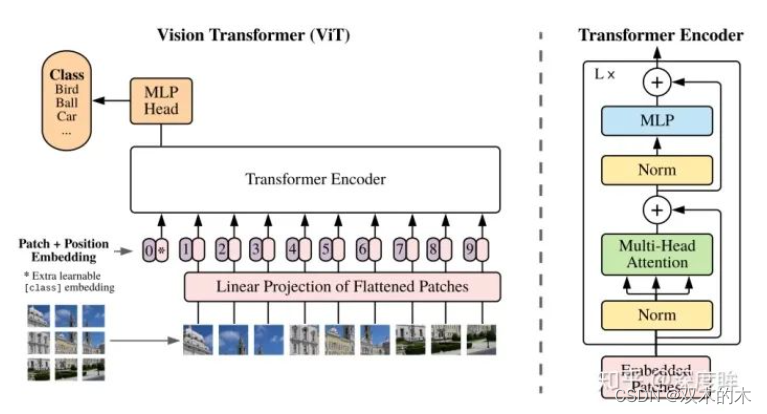
本文出发点是彻底抛弃CNN,以前的cv领域虽然引入transformer,但是或多或少都用到了cnn或者rnn,本文就比较纯粹了,整个算法几句话就说清楚了,下面直接分析。
2.1.1 图片分块和降维
因为transformer的输入需要序列,所以最简单做法就是把图片切分为patch,然后拉成序列即可。假设输入图片大小是256x256,打算分成64个patch,每个patch是32x32像素
x = rearrange(img, 'b c (h p1) (w p2) -> b (h w) (p1 p2 c)', p1=p, p2=p)这个写法是采用了爱因斯坦表达式,具体是采用了einops库实现,内部集成了各种算子,rearrange就是其中一个,非常高效。不懂这种语法的请自行百度。p就是patch大小,假设输入是b,3,256,256,则rearrange操作是先变成(b,3,8x32,8x32),最后变成(b,8x8,32x32x3)即(b,64,3072),将每张图片切分成64个小块,每个小块长度是32x32x3=3072,也就是说输入长度为64的图像序列,每个元素采用3072长度进行编码。
考虑到3072有点大,故作者先进行降维:
# 将3072变成dim,假设是1024
self.patch_to_embedding = nn.Linear(patch_dim, dim)
x = self.patch_to_embedding(x)仔细看论文上图,可以发现假设切成9个块,但是最终到transfomer输入是10个向量,额外追加了一个0和_。为啥要追加?原因是我们现在没有解码器了,而是编码后直接就进行分类预测,那么该解码器就要负责一点点解码器功能,那就是:需要一个类似开启解码标志,非常类似于标准transformer解码器中输入的目标嵌入向量右移一位操作。试下如果没有额外输入,9个块输入9个编码向量输出,那么对于分类任务而言,我应该取哪个输出向量进行后续分类呢?选择任何一个都说不通,所以作者追加了一个可学习嵌入向量输入。那么额外的可学习嵌入向量为啥要设计为可学习,而不是类似nlp中采用固定的token代替?个人不负责任的猜测这应该就是图片领域和nlp领域的差别,nlp里面每个词其实都有具体含义,是离散的,但是图像领域没有这种真正意义上的离散token,有的只是一堆连续特征或者图像像素,如果不设置为可学习,那还真不知道应该设置为啥内容比较合适,全0和全1也说不通。自此现在就是变成10个向量输出,输出也是10个编码向量,然后取第0个编码输出进行分类预测即可。从这个角度看可以认为编码器多了一点点解码器功能。具体做法超级简单,0就是位置编码向量,_是可学习的patch嵌入向量。
# dim=1024
self.cls_token = nn.Parameter(torch.randn(1, 1, dim))
# 变成(b,64,1024)
cls_tokens = repeat(self.cls_token, '() n d -> b n d', b=b)
# 额外追加token,变成b,65,1024
x = torch.cat((cls_tokens, x), dim=1)2.1.2 位置编码
位置编码也是必不可少的,长度应该是1024,这里做的比较简单,没有采用sincos编码,而是直接设置为可学习,效果差不多
# num_patches=64,dim=1024,+1是因为多了一个cls开启解码标志
self.pos_embedding = nn.Parameter(torch.randn(1, num_patches + 1, dim))对训练好的pos_embedding进行可视化,如下所示:
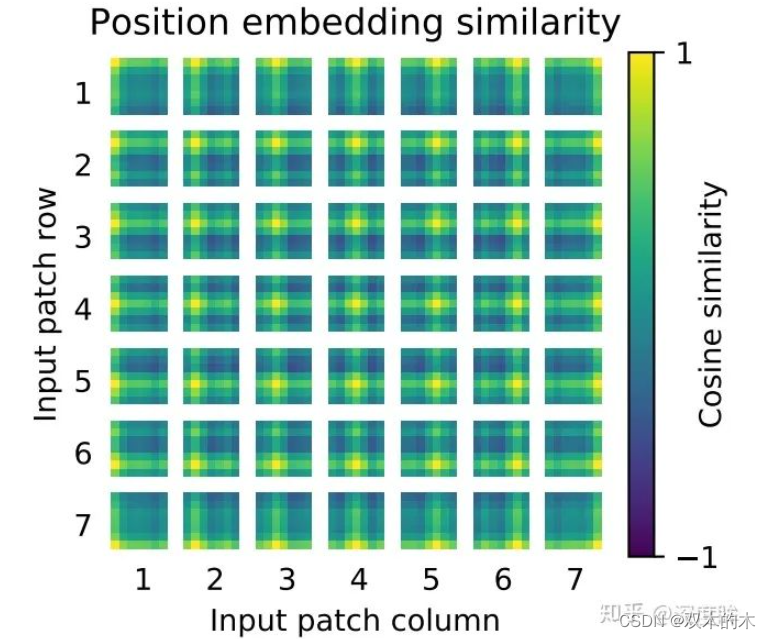
相邻位置有相近的位置编码向量,整体呈现2d空间位置排布一样。
将patch嵌入向量和位置编码向量相加即可作为编码器输入
x += self.pos_embedding[:, :(n + 1)]
x = self.dropout(x)2.1.3 编码器前向过程
作者采用的是没有任何改动的transformer,故没有啥说的。
self.transformer = Transformer(dim, depth, heads, mlp_dim, dropout)假设输入是(b,65,1024),那么transformer输出也是(b,65,1024)
2.1.4 分类head
在编码器后接fc分类器head即可
self.mlp_head = nn.Sequential(
nn.LayerNorm(dim),
nn.Linear(dim, mlp_dim),
nn.GELU(),
nn.Dropout(dropout),
nn.Linear(mlp_dim, num_classes)
)
# 65个输出里面只需要第0个输出进行后续分类即可
self.mlp_head(x[:, 0])到目前为止就全部写完了,是不是非常简单,外层整体流程为:
class ViT(nn.Module):
def __init__(self, *, image_size, patch_size, num_classes, dim, depth, heads, mlp_dim, channels=3, dropout=0.,emb_dropout=0.):
super().__init__()
# image_size输入图片大小 256
# patch_size 每个patch的大小 32
num_patches = (image_size // patch_size) ** 2 # 一共有多少个patch 8x8=64
patch_dim = channels * patch_size ** 2 # 3x32x32=3072
self.patch_size = patch_size # 32
# 1,64+1,1024,+1是因为token,可学习变量,不是固定编码
self.pos_embedding = nn.Parameter(torch.randn(1, num_patches + 1, dim))
# 图片维度太大了,需要先降维
self.patch_to_embedding = nn.Linear(patch_dim, dim)
# 分类输出位置标志,否则分类输出不知道应该取哪个位置
self.cls_token = nn.Parameter(torch.randn(1, 1, dim))
self.dropout = nn.Dropout(emb_dropout)
# 编码器
self.transformer = Transformer(dim, depth, heads, mlp_dim, dropout)
# 输出头
self.mlp_head = nn.Sequential(
nn.LayerNorm(dim),
nn.Linear(dim, mlp_dim),
nn.GELU(),
nn.Dropout(dropout),
nn.Linear(mlp_dim, num_classes)
)
def forward(self, img, mask=None):
p = self.patch_size
# 先把图片变成64个patch,输出shape=b,64,3072
x = rearrange(img, 'b c (h p1) (w p2) -> b (h w) (p1 p2 c)', p1=p, p2=p)
# 输出 b,64,1024
x = self.patch_to_embedding(x)
b, n, _ = x.shape
# 输出 b,1,1024
cls_tokens = repeat(self.cls_token, '() n d -> b n d', b=b)
# 额外追加token,变成b,65,1024
x = torch.cat((cls_tokens, x), dim=1)
# 加上位置编码1,64+1,1024
x += self.pos_embedding[:, :(n + 1)]
x = self.dropout(x)
x = self.transformer(x, mask)
# 分类head,只需要x[0]即可
# x = self.to_cls_token(x[:, 0])
x = x[:, 0]
return self.mlp_head(x)2.1.5 实验分析
作者得出的结论是:cv领域应用transformer需要大量数据进行预训练,在同等数据量的情况下性能不然cnn。一旦数据量上来了,对应的训练时间也会加长很多,那么就可以轻松超越cnn。

同时应用transformer,一个突出优点是可解释性比较强:

2.2 目标检测detr
论文名称:End-to-End Object Detection with Transformers
论文地址:https://arxiv.org/abs/2005.12872
github:https://github.com/facebookresearch/detr
detr是facebook提出的引入transformer到目标检测领域的算法,效果很好,做法也很简单,符合其一贯的简洁优雅设计做法。
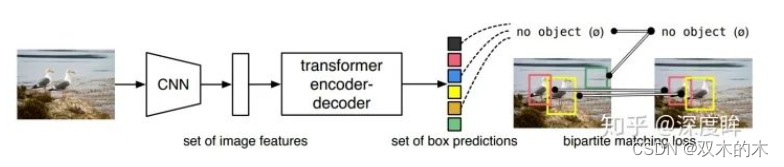
对于目标检测任务,其要求输出给定图片中所有前景物体的类别和bbox坐标,该任务实际上是无序集合预测问题。针对该问题,detr做法非常简单:给定一张图片,经过CNN进行特征提取,然后变成特征序列输入到transformer的编解码器中,直接输出指定长度为N的无序集合,集合中每个元素包含物体类别和坐标。其中N表示整个数据集中图片上最多物体的数目,因为整个训练和测试都Batch进行,如果不设置最大输出集合数,无法进行batch训练,如果图片中物体不够N个,那么就采用no object填充,表示该元素是背景。
整个思想看起来非常简单,相比faster rcnn或者yolo算法那就简单太多了,因为其不需要设置先验anchor,超参几乎没有,也不需要nms(因为输出的无序集合没有重复情况),并且在代码程度相比faster rcnn那就不知道简单多少倍了,通过简单修改就可以应用于全景分割任务。可以推测,如果transformer真正大规模应用于CV领域,那么对初学者来说就是福音了,理解transformer就几乎等于理解了整个cv领域了(当然也可能是坏事)。
2.2.1 detr核心思想分析
相比faster rcnn等做法,detr最大特点是将目标检测问题转化为无序集合预测问题。论文中特意指出faster rcnn这种设置一大堆anchor,然后基于anchor进行分类和回归其实属于代理做法即不是最直接做法,目标检测任务就是输出无序集合,而faster rcnn等算法通过各种操作,并结合复杂后处理最终才得到无序集合属于绕路了,而detr就比较纯粹了。
尽管将transformer引入目标检测领域可以避免上述各种问题,但是其依然存在两个核心操作:
无序集合输出的loss计算
针对目标检测的transformer改进
2.2.2 detr算法实现细节
下面结合代码和原理对其核心环节进行深入分析。
2.2.2.1 无序集合输出的loss计算
在分析loss计算前,需要先明确N个无序集合的target构建方式。作者在coco数据集上统计,一张图片最多标注了63个物体,所以N应该要不小于63,作者设置的是100。为啥要设置为100?有人猜测是和coco评估指标只取前100个预测结果算法指标有关系。
detr输出是包括batchx100个无序集合,每个集合包括类别和坐标信息。对于coco数据而言,作者设置类别为91(coco类别标注索引是1-91,但是实际就标注了80个类别),加上背景一共92个类别,对于坐标分支采用4个归一化值表征即cxcywh中心点、wh坐标,然后除以图片宽高进行归一化(没有采用复杂变换策略),故每个集合是 yi=(ci;bi) ,c是长度为92的分类向量,b是长度为4的bbox坐标向量。总之detr输出集合包括两个分支:分类分支shape=(b,100,92),bbox坐标分支shape=(b,100,4),对应的target也是包括分类target和bbox坐标target,如果不够100,则采用背景填充,计算loss时候bbox分支仅仅计算有物体位置,背景集合忽略。
现在核心问题来了:输出的bx100个检测结果是无序的,如何和gt bbox计算loss?这就需要用到经典的双边匹配算法了,也就是常说的匈牙利算法,该算法广泛应用于最优分配问题,在bottom-up人体姿态估计算法中进行分组操作时候也经常使用。detr中利用匈牙利算法先进行最优一对一匹配得到匹配索引,然后对bx100个结果进行重排就和gt bbox对应上了(对gt bbox进行重排也可以,没啥区别),就可以算loss了。
匈牙利算法是一个标准优化算法,具体是组合优化算法,在scipy.optimize.linear_sum_assignmen函数中有实现,一行代码就可以得到最优匹配,网上解读也非常多,这里就不写细节了,该函数核心是需要输入A集合和B集合两两元素之间的连接权重,基于该重要性进行内部最优匹配,连接权重大的优先匹配。
上述描述优化过程可以采用如下公式表达:

# detr分类输出,num_queries=100,shape是(b,100,92)
bs, num_queries = outputs["pred_logits"].shape[:2]
# 得到概率输出(bx100,92)
out_prob = outputs["pred_logits"].flatten(0, 1).softmax(-1)
# 得到bbox分支输出(bx100,4)
out_bbox = outputs["pred_boxes"].flatten(0, 1)
# 准备分类target shape=(m,)里面存储的是类别索引,m包括了整个batch内部的所有gt bbox
tgt_ids = torch.cat([v["labels"] for v in targets])
# 准备bbox target shape=(m,4),已经归一化了
tgt_bbox = torch.cat([v["boxes"] for v in targets])
#核心
#bx100,92->bx100,m,对于每个预测结果,把目前gt里面有的所有类别值提取出来,其余值不需要参与匹配
#对应上述公式,类似于nll loss,但是更加简单
cost_class = -out_prob[:, tgt_ids]
#计算out_bbox和tgt_bbox两两之间的l1距离 bx100,m
cost_bbox = torch.cdist(out_bbox, tgt_bbox, p=1)
#额外多计算一个giou loss bx100,m
cost_giou = -generalized_box_iou(box_cxcywh_to_xyxy(out_bbox), box_cxcywh_to_xyxy(tgt_bbox))
#得到最终的广义距离bx100,m,距离越小越可能是最优匹配
C = self.cost_bbox * cost_bbox + self.cost_class * cost_class + self.cost_giou * cost_giou
# bx100,m--> batch,100,m
C = C.view(bs, num_queries, -1).cpu()
#计算每个batch内部有多少物体,后续计算时候按照单张图片进行匹配,没必要batch级别匹配,徒增计算
sizes = [len(v["boxes"]) for v in targets]
#匈牙利最优匹配,返回匹配索引
indices = [linear_sum_assignment(c[i]) for i, c in enumerate(C.split(sizes, -1))]
return [(torch.as_tensor(i, dtype=torch.int64), torch.as_tensor(j, dtype=torch.int64)) for i, j in indices]在得到匹配关系后算loss就水到渠成了。分类分支计算ce loss,bbox分支计算l1 loss+giou loss
def loss_labels(self, outputs, targets, indices, num_boxes, log=True):
#shape是(b,100,92)
src_logits = outputs['pred_logits']
#得到匹配后索引,作用在label上
idx = self._get_src_permutation_idx(indices)
#得到匹配后的分类target
target_classes_o = torch.cat([t["labels"][J] for t, (_, J) in zip(targets, indices)])
#加入背景(self.num_classes),补齐bx100个
target_classes = torch.full(src_logits.shape[:2], self.num_classes,
dtype=torch.int64, device=src_logits.device)
#shape是(b,100,),存储的是索引,不是one-hot
target_classes[idx] = target_classes_o
#计算ce loss,self.empty_weight前景和背景权重是1和0.1,克服类别不平衡
loss_ce = F.cross_entropy(src_logits.transpose(1, 2), target_classes, self.empty_weight)
losses = {'loss_ce': loss_ce}
return losses
def loss_boxes(self, outputs, targets, indices, num_boxes):
idx = self._get_src_permutation_idx(indices)
src_boxes = outputs['pred_boxes'][idx]
target_boxes = torch.cat([t['boxes'][i] for t, (_, i) in zip(targets, indices)], dim=0)
#l1 loss
loss_bbox = F.l1_loss(src_boxes, target_boxes, reduction='none')
losses = {}
losses['loss_bbox'] = loss_bbox.sum() / num_boxes
#giou loss
loss_giou = 1 - torch.diag(box_ops.generalized_box_iou(
box_ops.box_cxcywh_to_xyxy(src_boxes),
box_ops.box_cxcywh_to_xyxy(target_boxes)))
losses['loss_giou'] = loss_giou.sum() / num_boxes
return losses2.2.2.2 针对目标检测的transformer改进
分析完训练最关键的:双边匹配+loss计算部分,现在需要考虑在目标检测算法中transformer如何设计?下面按照算法的4个步骤讲解。
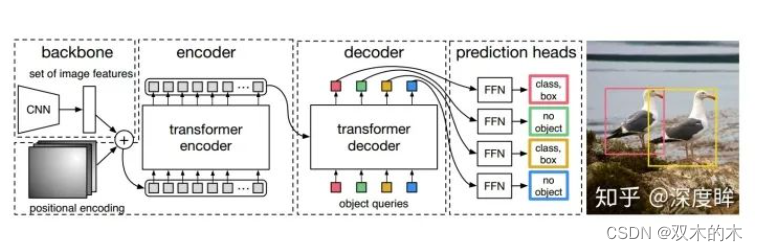
transformer细节如下:
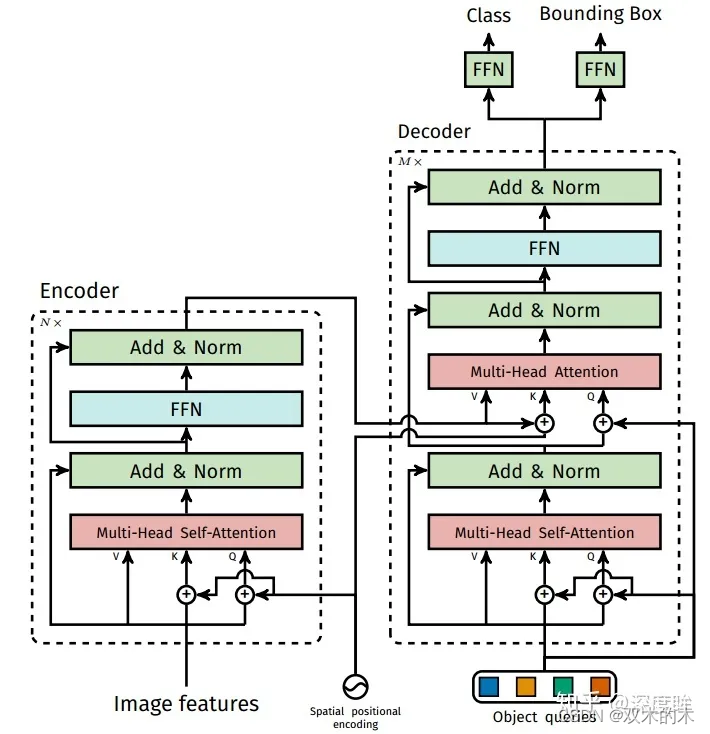
(1) cnn骨架特征提取
骨架网络可以是任何一种,作者选择resnet50,将最后一个stage即stride=32的特征图作为编码器输入。由于resnet仅仅作为一个小部分且已经经过了imagenet预训练,故和常规操作一样,会进行如下操作:
resnet中所有BN都固定,即采用全局均值和方差
resnet的stem和第一个stage不进行参数更新,即parameter.requires_grad_(False)
backbone的学习率小于transformer,lr_backbone=1e-05,其余为0.0001
假设输入是(b,c,h,w),则resnet50输出是(b,1024,h//32,w//32),1024比较大,为了节省计算量,先采用1x1卷积降维为256,最后转化为序列格式输入到transformer中,输入shape=(h'xw',b,256),h'=h//32
self.input_proj = nn.Conv2d(backbone.num_channels, hidden_dim, kernel_size=1)
# 输出是(b,256,h//32,w//32)
src=self.input_proj(src)
# 变成序列模式,(h'xw',b,256),256是每个词的编码长度
src = src.flatten(2).permute(2, 0, 1)(2) 编码器设计和输入
编码器结构设计没有任何改变,但是输入改变了。
a) 位置编码需要考虑2d空间
由于图像特征是2d特征,故位置嵌入向量也需要考虑xy方向。前面说过编码方式可以采用sincos,也可以设置为可学习,本文采用的依然是sincos模式,和前面说的一样,但是需要考虑xy两个方向(前面说的序列只有x方向)。
#输入是b,c,h,w
#tensor_list的类型是NestedTensor,内部自动附加了mask,
#用于表示动态shape,是pytorch中tensor新特性https://github.com/pytorch/nestedtensor
x = tensor_list.tensors # 原始tensor数据
# 附加的mask,shape是b,h,w 全是false
mask = tensor_list.mask
not_mask = ~mask
# 因为图像是2d的,所以位置编码也分为x,y方向
# 1 1 1 1 .. 2 2 2 2... 3 3 3...
y_embed = not_mask.cumsum(1, dtype=torch.float32)
# 1 2 3 4 ... 1 2 3 4...
x_embed = not_mask.cumsum(2, dtype=torch.float32)
if self.normalize:
eps = 1e-6
y_embed = y_embed / (y_embed[:, -1:, :] + eps) * self.scale
x_embed = x_embed / (x_embed[:, :, -1:] + eps) * self.scale
# 0~127 self.num_pos_feats=128,因为前面输入向量是256,编码是一半sin,一半cos
dim_t = torch.arange(self.num_pos_feats, dtype=torch.float32, device=x.device)
# 归一化
dim_t = self.temperature ** (2 * (dim_t // 2) / self.num_pos_feats)
pos_x = x_embed[:, :, :, None] / dim_t
pos_y = y_embed[:, :, :, None] / dim_t
# 输出shape=b,h,w,128
pos_x = torch.stack((pos_x[:, :, :, 0::2].sin(), pos_x[:, :, :, 1::2].cos()), dim=4).flatten(3)
pos_y = torch.stack((pos_y[:, :, :, 0::2].sin(), pos_y[:, :, :, 1::2].cos()), dim=4).flatten(3)
pos = torch.cat((pos_y, pos_x), dim=3).permute(0, 3, 1, 2)
# 每个特征图的xy位置都编码成256的向量,其中前128是y方向编码,而128是x方向编码
return pos # b,n=256,h,w可以看出对于h//32,w//32的2d图像特征,不是类似vision transoformer做法简单的将其拉伸为h//32 x w//32,然后从0-n进行长度为256的位置编码,而是考虑了xy方向同时编码,每个方向各编码128维向量,这种编码方式更符合图像特定。
还有一个细节需要注意:原始transformer的n个编码器输入中,只有第一个编码器需要输入位置编码向量,但是detr里面对每个编码器都输入了同一个位置编码向量,论文中没有写为啥要如此修改。
b) QKV处理逻辑不同
作者设置编码器一共6个,并且位置编码向量仅仅加到QK中,V中没有加入位置信息,这个和原始做法不一样,原始做法是QKV都加上了位置编码,论文中也没有写为啥要如此修改。
其余地方就完全相同了,故代码就没必要贴了。总结下和原始transformer编码器不同的地方:
输入编码器的位置编码需要考虑2d空间位置
位置编码向量需要加入到每个编码器中
在编码器内部位置编码仅仅和QK相加,V不做任何处理
经过6个编码器forward后,输出shape为(h//32xw//32,b,256)。
c) 编码器部分整体运行流程
6个编码器整体forward流程如下:
class TransformerEncoder(nn.Module):
def __init__(self, encoder_layer, num_layers, norm=None):
super().__init__()
# 编码器copy6份
self.layers = _get_clones(encoder_layer, num_layers)
self.num_layers = num_layers
self.norm = norm
def forward(self, src,
mask: Optional[Tensor] = None,
src_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None):
# 内部包括6个编码器,顺序运行
# src是图像特征输入,shape=hxw,b,256
output = src
for layer in self.layers:
# 每个编码器都需要加入pos位置编码
# 第一个编码器输入来自图像特征,后面的编码器输入来自前一个编码器输出
output = layer(output, src_mask=mask,
src_key_padding_mask=src_key_padding_mask, pos=pos)
return output每个编码器内部运行流程如下:
def forward_post(self,
src,
src_mask: Optional[Tensor] = None,
src_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None):
# 和标准做法有点不一样,src加上位置编码得到q和k,但是v依然还是src,
# 也就是v和qk不一样
q = k = src+pos
src2 = self.self_attn(q, k, value=src, attn_mask=src_mask,
key_padding_mask=src_key_padding_mask)[0]
src = src + self.dropout1(src2)
src = self.norm1(src)
src2 = self.linear2(self.dropout(self.activation(self.linear1(src))))
src = src + self.dropout2(src2)
src = self.norm2(src)
return src(3) 解码器设计和输入
解码器结构设计没有任何改变,但是输入也改变了。
a) 新引入Object queries
object queries(shape是(100,256))可以简单认为是输出位置编码,其作用主要是在学习过程中提供目标对象和全局图像之间的关系,相当于全局注意力,必不可少非常关键。代码形式上是可学习位置编码矩阵。和编码器一样,该可学习位置编码向量也会输入到每一个解码器中。我们可以尝试通俗理解:object queries矩阵内部通过学习建模了100个物体之间的全局关系,例如房间里面的桌子旁边(A类)一般是放椅子(B类),而不会是放一头大象(C类),那么在推理时候就可以利用该全局注意力更好的进行解码预测输出。
# num_queries=100,hidden_dim=256
self.query_embed = nn.Embedding(num_queries, hidden_dim)论文中指出object queries作用非常类似faster rcnn中的anchor,只不过这里是可学习的,不是提前设置好的。
b) 位置编码也需要
编码器环节采用的sincos位置编码向量也可以考虑引入,且该位置编码向量输入到每个解码器的第二个Multi-Head Attention中,后面有是否需要该位置编码的对比实验。
c) QKV处理逻辑不同
解码器一共包括6个,和编码器中QKV一样,V不会加入位置编码。上述说的三个操作,只要看下网络结构图就一目了然了。
d) 一次解码输出全部无序集合
和原始transformer顺序解码操作不同的是,detr一次就把N个无序框并行输出了(因为任务是无序集合,做成顺序推理有序输出没有很大必要)。为了说明如何实现该功能,我们需要先回忆下原始transformer的顺序解码过程:输入BOS_WORD,解码器输出i;输入前面已经解码的BOS_WORD和i,解码器输出am...,输入已经解码的BOS_WORD、i、am、a和student,解码器输出解码结束标志位EOS_WORD,每次解码都会利用前面已经解码输出的所有单词嵌入信息。现在就是一次解码,故只需要初始化时候输入一个全0的查询向量A,类似于BOS_WORD作用,然后第一个解码器接受该输入A,解码输出向量作为下一个解码器输入,不断推理即可,最后一层解码输出即为我们需要的输出,不需要在第二个解码器输入时候考虑BOS_WORD和第一个解码器输出。
总结下和原始transformer解码器不同的地方:
额外引入可学习的Object queries,相当于可学习anchor,提供全局注意力
编码器采用的sincos位置编码向量也需要输入解码器中,并且每个解码器都输入
QKV处理逻辑不同
不需要顺序解码,一次即可输出N个无序集合
e) 解码器整体运行流程
n个解码器整体流程如下:
class TransformerDecoder(nn.Module):
def forward(self, tgt, memory,
tgt_mask: Optional[Tensor] = None,
memory_mask: Optional[Tensor] = None,
tgt_key_padding_mask: Optional[Tensor] = None,
memory_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None,
query_pos: Optional[Tensor] = None):
# 首先query_pos是query_embed,可学习输出位置向量shape=100,b,256
# tgt = torch.zeros_like(query_embed),用于进行一次性解码输出
output = tgt
# 存储每个解码器输出,后面中继监督需要
intermediate = []
# 编码每个解码器
for layer in self.layers:
# 每个解码器都需要输入query_pos和pos
# memory是最后一个编码器输出
# 每个解码器都接受output作为输入,然后输出新的output
output = layer(output, memory, tgt_mask=tgt_mask,
memory_mask=memory_mask,
tgt_key_padding_mask=tgt_key_padding_mask,
memory_key_padding_mask=memory_key_padding_mask,
pos=pos, query_pos=query_pos)
if self.return_intermediate:
intermediate.append(self.norm(output))
if self.return_intermediate:
return torch.stack(intermediate) # 6个输出都返回
return output.unsqueeze(0)内部每个解码器运行流程为:
def forward_post(self, tgt, memory,
tgt_mask: Optional[Tensor] = None,
memory_mask: Optional[Tensor] = None,
tgt_key_padding_mask: Optional[Tensor] = None,
memory_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None,
query_pos: Optional[Tensor] = None):
# query_pos首先是可学习的,其作用主要是在学习过程中提供目标对象和全局图像之间的关系
# 这个相当于全局注意力输入,是非常关键的
# query_pos是解码器特有
q = k = tgt+query_pos
# 第一个自注意力模块
tgt2 = self.self_attn(q, k, value=tgt, attn_mask=tgt_mask,
key_padding_mask=tgt_key_padding_mask)[0]
tgt = tgt + self.dropout1(tgt2)
tgt = self.norm1(tgt)
# memory是最后一个编码器输出,pos是和编码器输入中完全相同的sincos位置嵌入向量
# 输入参数是最核心细节,query是tgt+query_pos,而key是memory+pos
# v直接用memory
tgt2 = self.multihead_attn(query=tgt+query_pos,
key=memory+pos,
value=memory, attn_mask=memory_mask,
key_padding_mask=memory_key_padding_mask)[0]
tgt = tgt + self.dropout2(tgt2)
tgt = self.norm2(tgt)
tgt2 = self.linear2(self.dropout(self.activation(self.linear1(tgt))))
tgt = tgt + self.dropout3(tgt2)
tgt = self.norm3(tgt)
return tgt解码器最终输出shape是(6,b,100,256),6是指6个解码器的输出。
(4) 分类和回归head
在解码器输出基础上构建分类和bbox回归head即可输出检测结果,比较简单:
self.class_embed = nn.Linear(256, 92)
self.bbox_embed = MLP(256, 256, 4, 3)
# hs是(6,b,100,256),outputs_class输出(6,b,100,92),表示6个分类分支
outputs_class = self.class_embed(hs)
# 输出(6,b,100,4),表示6个bbox坐标回归分支
outputs_coord = self.bbox_embed(hs).sigmoid()
# 取最后一个解码器输出即可,分类输出(b,100,92),bbox回归输出(b,100,4)
out = {'pred_logits': outputs_class[-1], 'pred_boxes': outputs_coord[-1]}
if self.aux_loss:
# 除了最后一个输出外,其余编码器输出都算辅助loss
out['aux_outputs'] = self._set_aux_loss(outputs_class, outputs_coord)作者实验发现,如果对解码器的每个输出都加入辅助的分类和回归loss,可以提升性能,故作者除了对最后一个编码层的输出进行Loss监督外,还对其余5个编码器采用了同样的loss监督,只不过权重设置低一点而已。
(5) 整体推理流程
基于transformer的detr算法,作者特意强调其突出优点是部署代码不超过50行,简单至极。

当然上面是简化代码,和实际代码不一样。具体流程是:
将(b,3,800,1200)图片输入到resnet50中进行特征提取,输出shape=(b,1024,25,38)
通过1x1卷积降维,变成(b,256,25,38)
利用sincos函数计算位置编码
将图像特征和位置编码向量相加,作为编码器输入,输出编码后的向量,shape不变
初始化全0的(100,b,256)的输出嵌入向量,结合位置编码向量和query_embed,进行解码输出,解码器输出shape为(6,b,100,256)
将最后一个解码器输出输入到分类和回归head中,得到100个无序集合
对100个无序集合进行后处理,主要是提取前景类别和对应的bbox坐标,乘上(800,1200)即可得到最终坐标,后处理代码如下:
prob = F.softmax(out_logits, -1) scores, labels = prob[..., :-1].max(-1) # convert to [x0, y0, x1, y1] format boxes = box_ops.box_cxcywh_to_xyxy(out_bbox) # and from relative [0, 1] to absolute [0, height] coordinates img_h, img_w = target_sizes.unbind(1) scale_fct = torch.stack([img_w, img_h, img_w, img_h], dim=1) boxes = boxes * scale_fct[:, None, :] results = [{'scores': s, 'labels': l, 'boxes': b} for s, l, b in zip(scores, labels, boxes)]
既然训练时候对6个解码器输出都进行了loss监督,那么在测试时候也可以考虑将6个解码器的分类和回归分支输出结果进行nms合并,稍微有点性能提升。
2.2.3 实验分析
(1) 性能对比

Faster RCNN-DC5是指的resnet的最后一个stage采用空洞率=stride设置代替stride,目的是在不进行下采样基础上扩大感受野,输出特征图分辨率保持不变。+号代表采用了额外的技巧提升性能例如giou、多尺度训练和9xepoch训练策略。可以发现detr效果稍微好于faster rcnn各种版本,证明了视觉transformer的潜力。但是可以发现其小物体检测能力远远低于faster rcnn,这是一个比较大的弊端。
(2) 各个模块分析

编码器数目越多效果越好,但是计算量也会增加很多,作者最终选择的是6。

可以发现解码器也是越多越好,还可以观察到第一个解码器输出预测效果比较差,增加第二个解码器后性能提升非常多。上图中的NMS操作是指既然我们每个解码层都可以输入无序集合,那么将所有解码器无序集合全部保留,然后进行nms得到最终输出,可以发现性能稍微有提升,特别是AP50。

作者对比了不同类型的位置编码效果,因为query_embed(output pos)是必不可少的,所以该列没有进行对比实验,始终都有,最后一行效果最好,所以作者采用的就是该方案,sine at attn表示每个注意力层都加入了sine位置编码,相比仅仅在input增加位置编码效果更好。
(3) 注意力可视化
前面说过transformer具有很好的可解释性,故在训练完成后最终提出了几种可视化形式
a) bbox输出可视化
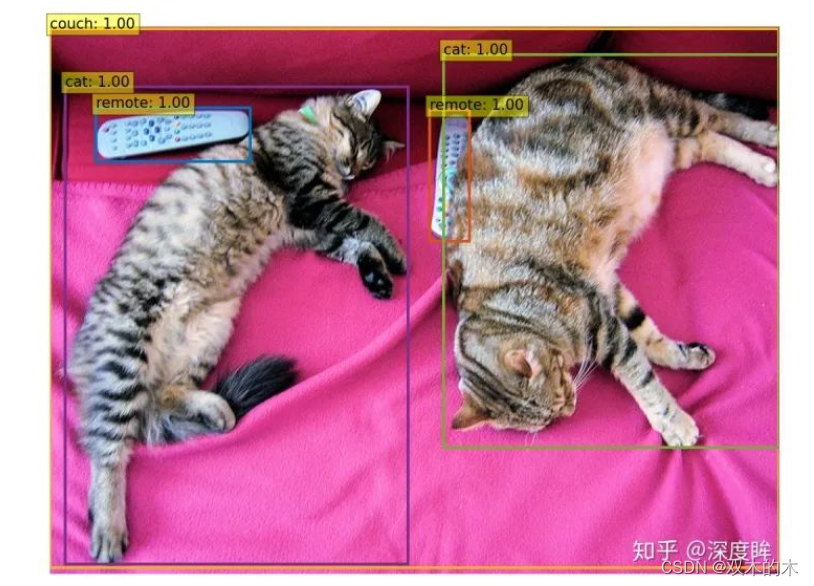
这个就比较简单了,直接对预测进行后处理即可
probas = outputs['pred_logits'].softmax(-1)[0, :, :-1]
# 只保留概率大于0.9的bbox
keep = probas.max(-1).values > 0.9
# 还原到原图,然后绘制即可
bboxes_scaled = rescale_bboxes(outputs['pred_boxes'][0, keep], im.size)
plot_results(im, probas[keep], bboxes_scaled)b) 解码器自注意力层权重可视化

这里指的是最后一个解码器内部的第一个MultiheadAttention的自注意力权重,其实就是QK相似性计算后然后softmax后的输出可视化,具体是:
# multihead_attn注册前向hook,output[1]指的就是softmax后输出
model.transformer.decoder.layers[-1].multihead_attn.register_forward_hook(
lambda self, input, output: dec_attn_weights.append(output[1])
)
# 假设输入是(1,3,800,1066)
outputs = model(img)
# 那么dec_attn_weights是(1,100,850=800//32x1066//32)
# 这个就是QK相似性计算后然后softmax后的输出,即自注意力权重
dec_attn_weights = dec_attn_weights[0]
# 如果想看哪个bbox的权重,则输入idx即可
dec_attn_weights[0, idx].view(800//32, 1066//32)c) 编码器自注意力层权重可视化

这个和解码器操作完全相同。
model.transformer.encoder.layers[-1].self_attn.register_forward_hook(
lambda self, input, output: enc_attn_weights.append(output[1])
)
outputs = model(img)
# 最后一个编码器中的自注意力模块权重输出(b,h//32xw//32,h//32xw//32),其实就是qk计算然后softmax后的值即(1,25x34=850,850)
enc_attn_weights = enc_attn_weights[0]
# 变成(25, 34, 25, 34)
sattn = enc_attn_weights[0].reshape(shape + shape)
# 想看哪个特征点位置的注意力
idxs = [(200, 200), (280, 400), (200, 600), (440, 800), ]
for idx_o, ax in zip(idxs, axs):
# 转化到特征图尺度
idx = (idx_o[0] // fact, idx_o[1] // fact)
# 直接sattn[..., idx[0], idx[1]]即可
ax.imshow(sattn[..., idx[0], idx[1]], cmap='cividis', interpolation='nearest')2.2.4 小结
detr整体做法非常简单,基本上没有改动原始transformer结构,其显著优点是:不需要设置啥先验,超参也比较少,训练和部署代码相比faster rcnn算法简单很多,理解上也比较简单。但是其缺点是:改了编解码器的输入,在论文中也没有解释为啥要如此设计,而且很多操作都是实验对比才确定的,比较迷。算法层面训练epoch次数远远大于faster rcnn(300epoch),在同等epoch下明显性能不如faster rcnn,而且训练占用内存也大于faster rcnn。
整体而言,虽然效果不错,但是整个做法还是显得比较原始,很多地方感觉是尝试后得到的做法,没有很好的解释性,而且最大问题是训练epoch非常大和内存占用比较多,对应的就是收敛慢,期待后续作品。
3 总结
本文从transformer发展历程入手,并且深入介绍了transformer思想和实现细节;最后结合计算机视觉领域的几篇有典型代表文章进行深入分析,希望能够给cv领域想快速理解transformer的初学者一点点帮助。
4 参考资料
1 http://jalammar.github.io/illustrated-transformer/
2 https://zhuanlan.zhihu.com/p/54356280
3 https://zhuanlan.zhihu.com/p/44731789
4 https://looperxx.github.io/CS224n-2019-08-Machine%20Translation,%20Sequence-to-sequence%20and%20Attention/
5 https://github.com/lucidrains/vit-pytorch
6 https://github.com/jadore801120/attention-is-all-you-need-pytorch
7 https://github.com/facebookresearch/detr
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。