1. 模型检验
1.1 Holdout交叉验证
1.1.1 算法
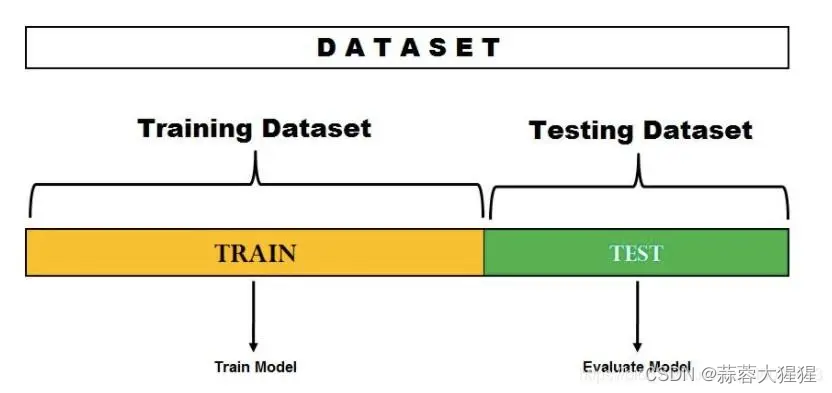
在这种交叉验证技术中,整个数据集被随机划分为训练集和验证集。根据经验,整个数据集的近 70% 用作训练集,其余 30% 用作验证集。
优点:可以快速进行区分,仅仅通过一次区分即可使用。
局限性:
1. 不适用于不平衡数据,例如有80%的正类样本,20%的负类样本,恰好将80%正类样本分为训练集,剩余为测试集,对模型的拟合造成误导。
2. 不适用于小数据集,可能具有我们的模型可能会错过的重要特征,因为它没有对该数据进行训练
1.1.2 代码实现:
from sklearn.model_selection import train_test_split
X = [[2,3,4],[1,2,3],[2,5,6],[1,2,3]]
y = [1,0,1,0]
X_train,x_test,Y_train,y_test = train_test_split(X,y)1.2 LOOCV
1.2.1 算法
LOOCV方法也包含将数据集分为训练集和测试集这一步骤。但是不同的是,我们现在只用一个数据作为测试集,其他的数据都作为训练集,并将此步骤重复N次(N为数据集的数据数量)。
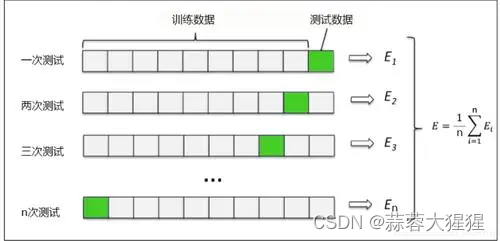
1.2.2 代码实现
from sklearn.model_selection import LeavePOut,cross_val_score
from sklearn.ensemble import RandomForestClassifier
lpo = LeavePOut(p=1) #p代表验证集的个数
lpo.get_n_splits(X)
tree = RandomForestClassifier()
score = cross_val_score(tree,X,y,cv=lpo) #每一个样本集合的准确率
print(score.mean())1.3 K-fold Cross Validation K折交叉验证
1.3.1 算法
在这种 K 折交叉验证技术中,整个数据集被划分为 K 个相等大小的部分。每个分区称为一个“折叠”。因此,因为我们有 K 个部分,所以我们称之为 K 折叠。一折用作验证集,其余 K-1 折用作训练集。
该技术重复 K 次,直到每个折叠用作验证集,其余折叠用作训练集。
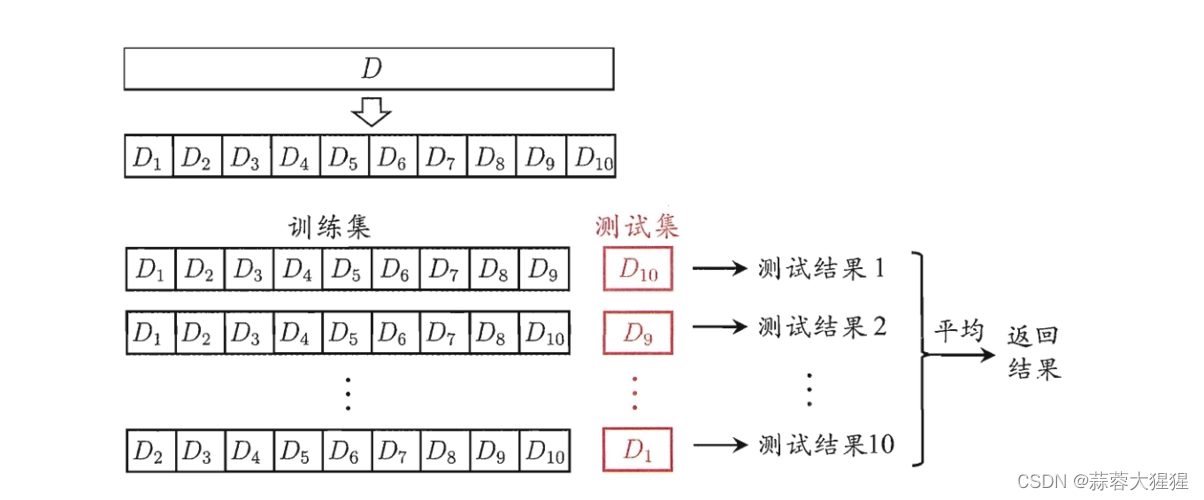
模型的最终精度是通过取 k-models 验证数据的平均精度来计算的。
1.3.2 代码实现
from sklearn.model_selection import KFold,cross_val_score
from sklearn.linear_model import LogisticRegression
logreg = LogisticRegression()
kf = KFold(n_splits=2)
score= cross_val_score(logreg,X,y,cv=kf)
print(score.mean())2. 模型评估
2.1 性能指标
准确率:表示预测正确的样本数占总样本数的比例:

精确率:表示预测为正的样本中,确实为正的样本数所占的比例:

召回率:所有确实为正的样本中预测也为正的占比:

F1分数:精确率和召回率的调和平均数,用于综合考虑二者的性能:

2.2 混淆矩阵
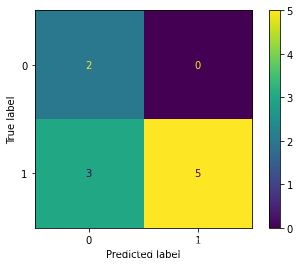
混淆矩阵是评判模型结果的指标,属于模型评估的一部分。此外,混淆矩阵多用于判断分类器(Classifier)的优劣,适用于分类型的数据模型。衡量正确预测以及错误预测的对应关系。
from sklearn.metrics import confusion_matrix
from sklearn.metrics import ConfusionMatrixDisplay
y_predict = [1,0,1,0,0,1,1,1,0,0]
y_true = [1,0,1,1,1,1,1,1,0,1]
C1 = confusion_matrix(y_true,y_predict)
CM = ConfusionMatrixDisplay(C1)
CM.plot()如图所示,横坐标代表预测标签,纵坐标为实际标签,每一个不同颜色的方块代表其对应关系,可以由混淆矩阵得出哪一类别分类效果好,哪一类别的分类效果不尽人意,从而针对化的去改善模型。
2.3 ROC & AUC曲线
2.3.1 概念
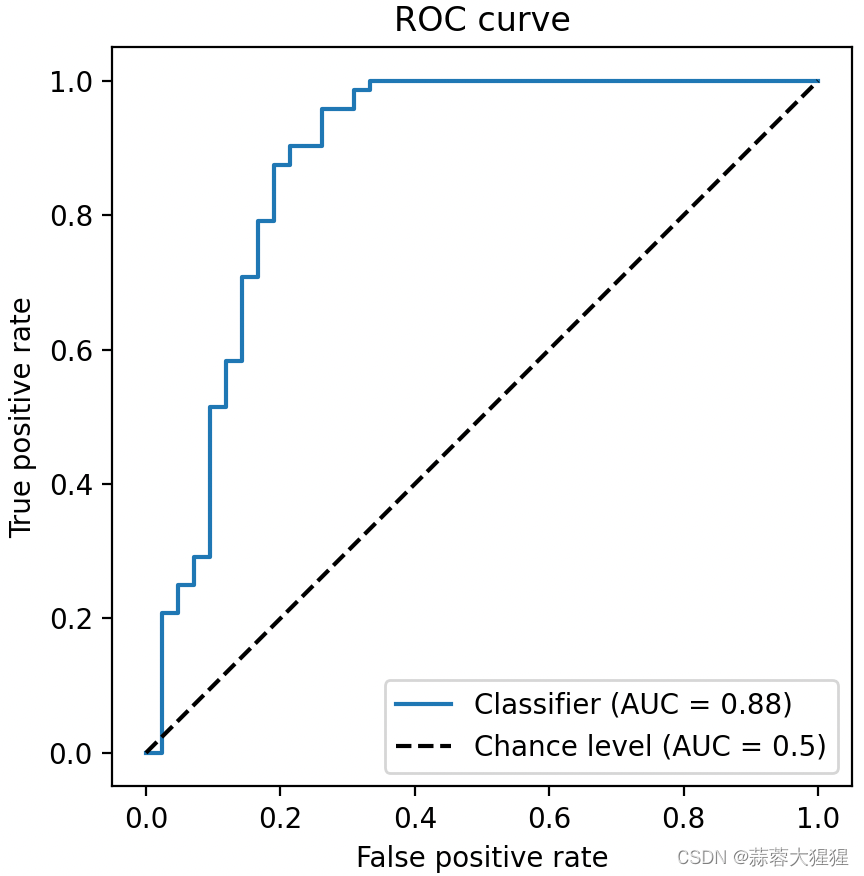
这是一个ROC曲线示例图,蓝色险段为ROC曲线,虚线为我们的基准线。其中 ROC 曲线距离基准线越远,则说明该模型的预测效果越好。
ROC 曲线接近左上角:模型预测准确率很高
ROC 曲线略高于基准线:模型预测准确率一般
ROC 低于基准线:模型未达到最低标准,无法使用
我们深层次的去剖析这张图表,图的横坐标为FPR,代表在所有真实为负的样本中,模型错误预测为正的比例;纵坐标为TPR也就是我们的Recall(召回率)。ROC曲线不依赖于具体的阈值选择,可以全面评估模型在不同阈值下的表现。
AUC(Area Under the Curve)是ROC曲线下的面积,AUC值越接近于1,模型的性能越好,AUC若等于0.5,则表示模型没有分类能力,相当于随机猜测。AUC值为模型性能提供了一个综合指标,可以比较不同模型的优劣。
但他们的解释起来比较复杂,在某些应用中,可能不如其他指标,例如精准率等。
2.3.2 手写代码演示
def roc(y_true,y_score,pos_label):
#统计正样本和负样本的个数
num_positive_examples = (y_true == pos_label).sum()
num_negative_examples = len(y_true) - num_positive_examples
tp,fp = 0,0
tpr,fpr,thresholds=[],[],[]
score = max(y_score)+1
for i in np.flip(np.argsort(y_score)):
if y_score[i] != score:
fpr.append(fp/num_negative_examples) #对于上一轮的结果进行汇总
tpr.append(tp/num_positive_examples)
thresholds.append(score) #记录阈值
score = y_score[i] #进入新一轮的计算
if y_true[i] == pos_label: #新一轮意味都会增加一个预测为pos_label的样本,只需要关注他的真实标签即可
tp += 1
else:
fp += 1
fpr.append(fp / num_negative_examples)
tpr.append(tp / num_positive_examples)
thresholds.append(score)
return fpr,tpr,thresholds
y_true = np.array([1,1,0,1,1,1])
y_score = np.array([.9,.8,.7,.6,.55,.54])
fpr,tpr,threshold = roc(y_true,y_score,pos_label=1)
import matplotlib.pyplot as plt
plt.plot(fpr,tpr)
plt.axis("square")
plt.xlabel("False")
plt.ylabel("True")
plt.show()2.3.3 调包代码演示
#库绘制ROC,AUC
from sklearn.metrics import roc_curve,auc
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
X,y = make_classification(n_samples=1000,n_classes=2,random_state=42)
X_train,X_test,y_train,y_test = train_test_split(X,y)
model = LogisticRegression()
model.fit(X_train,y_train)
y_scores = model.predict_proba(X_test)[:,1]
fpr,tpr,thresholds = roc_curve(y_test,y_scores)
roc_auc = auc(fpr,tpr)
plt.figure()
plt.xlim([0,1])
plt.ylim([0,1])
plt.plot(fpr,tpr,color='darkorange',lw=2)
plt.plot([0,1],[0,1],color='navy',linestyle='-')
plt
print(roc_auc)3. 应用前景
这些指标通过定量评估分类模型性能,帮助我们在实际应用中做出更明智的决策。
1. 制造业:
质量控制:评估自动化质量检测系统的性能,减少产品缺陷率,提高生产效率。
故障预测:精确预测设备故障,减少停机时间和维护成本。
2. 网络安全:
入侵检测:评估入侵检测系统的性能,确保能够准确识别网络攻击和减少误报。
恶意软件检测:评估恶意软件检测模型的精确率和召回率,以确保能够有效识别和阻止恶意软件。
3. 金融领域:
信用评分:高精准率和召回率可以帮助银行降低坏账率。
欺诈检测:高召回率对于捕捉尽可能多的欺诈行为非常重要,同时需要保持精确率以避免过多的误报。
etc.