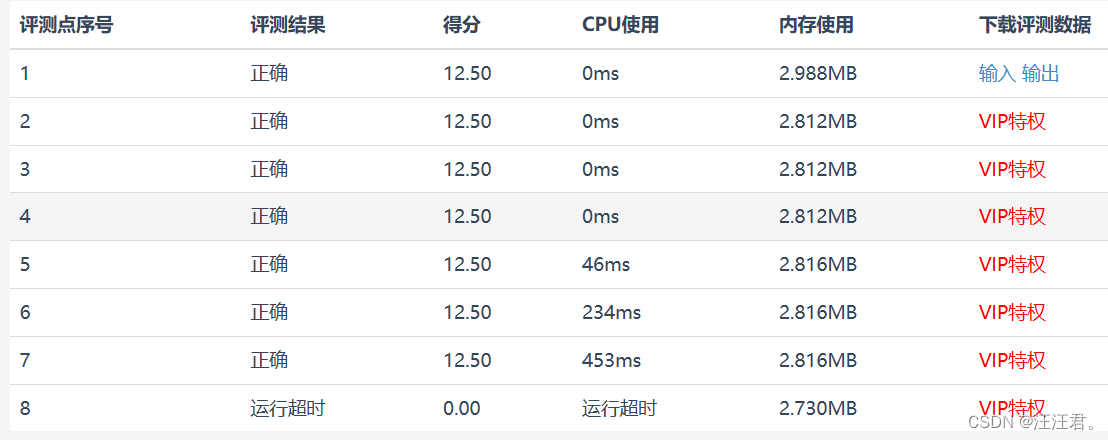
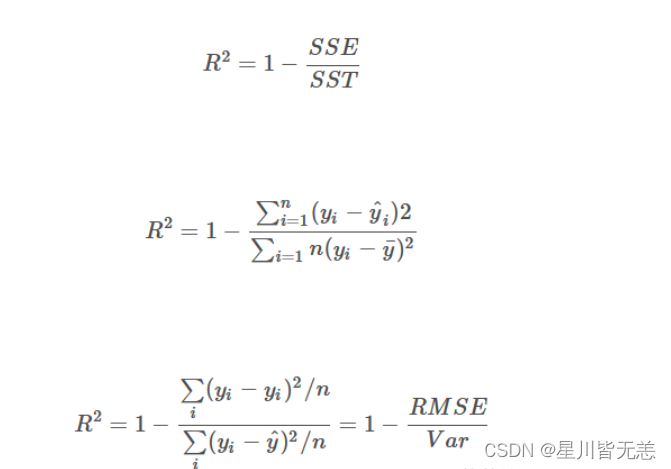1 经验误差与过拟合

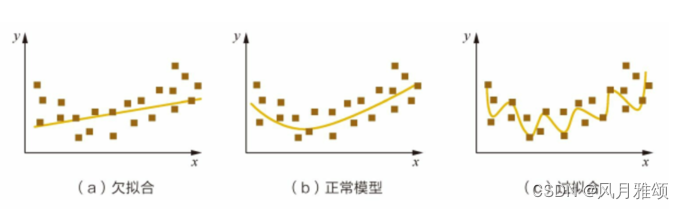
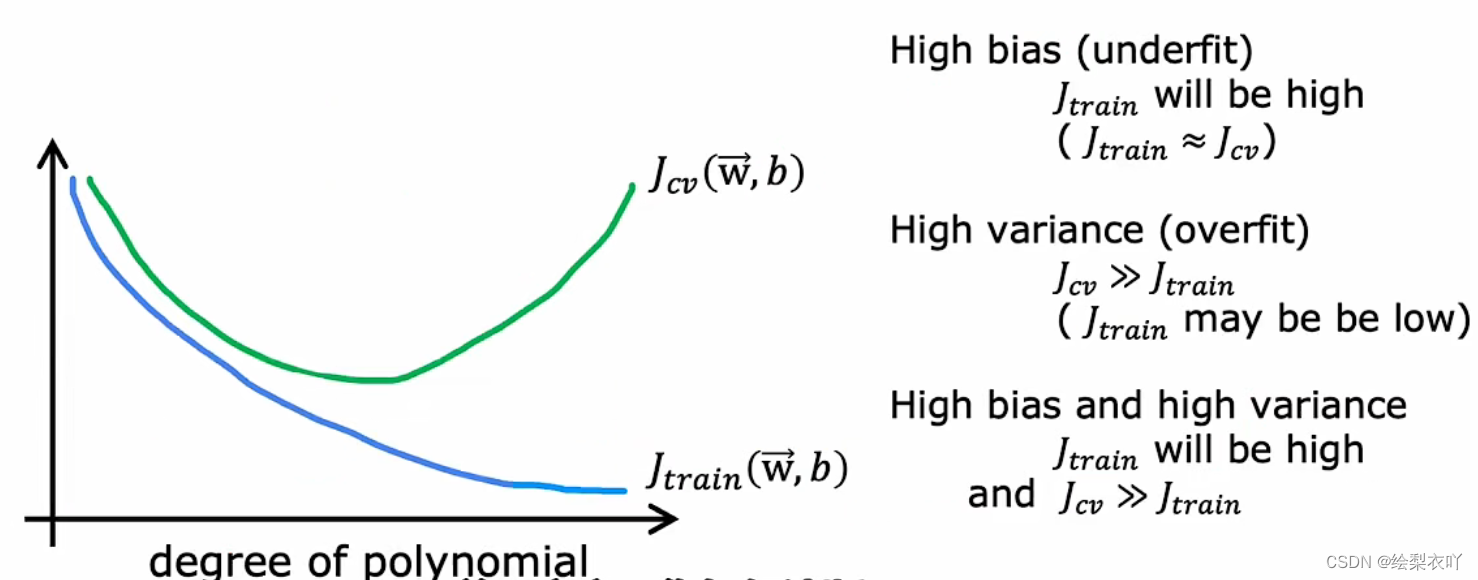
过拟合:当学习器把训练样本学得“太好”了的时候,很可能已经把训练样本自身的一些特点当作了所有潜在样本都会具有的一般性质,这样就会导致泛化性能下降.这种现象在机器学习中称为“过拟合”(overfitting)、与“过拟合”相对的是“欠拟合”(underfitting)。
2 评估方法
通常,我们可通过实验测试来对学习器的泛化误差进行评估并进而做出选择.为此,需使用一个“测试集”(testing set)来测试学习器对新样本的判别能力,然后以测试集上的“测试误差”(testing error)作为泛化误差的近似.通常我们假设测试样本也是从样本真实分布中独立同分布采样而得.但需注意的是,测试集应该尽可能与训练集互斥,即测试样本尽量不在训练集中出现、未在训练过程中使用过.
2.1 留出法

以二分类任务为例,假定D包含1000个样本,将其划分为S包含700个样本,T包含300个样本,用S进行训练后,如果模型在T上有90个样本分类错误,那么其错误率为(90/300)x 100%=30%,相应的,精度为1一30%=70%。
常见做法:将大约2/3~4/5的样本用于训练,剩余样本用于测试。
2.2 交叉验证法

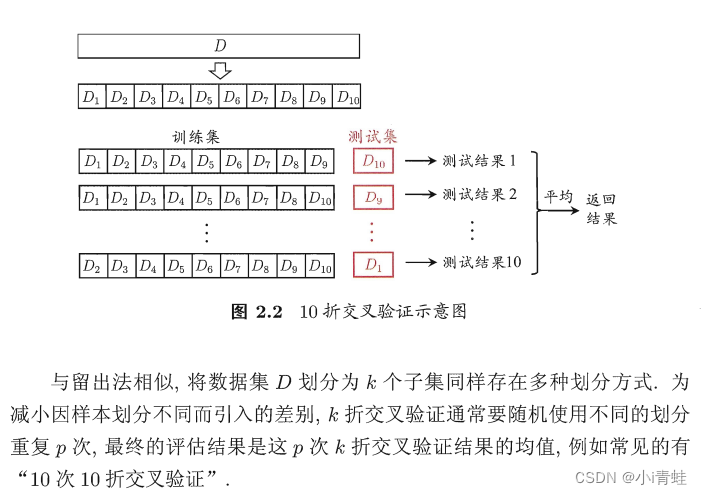
2.3 自助法

自助法在数据集较小、难以有效划分训练/测试集时很有用;此外,自助法能从初始数据集中产生多个不同的训练集,这对集成学习等方法有很大的好处.然而,自助法产生的数据集改变了初始数据集的分布,这会引入估计偏差.因此,在初始数据量足够时,留出法和交叉验证法更常用一些.
2.4 调参与最终模型

3 性能度量

3.1 错误率与精度