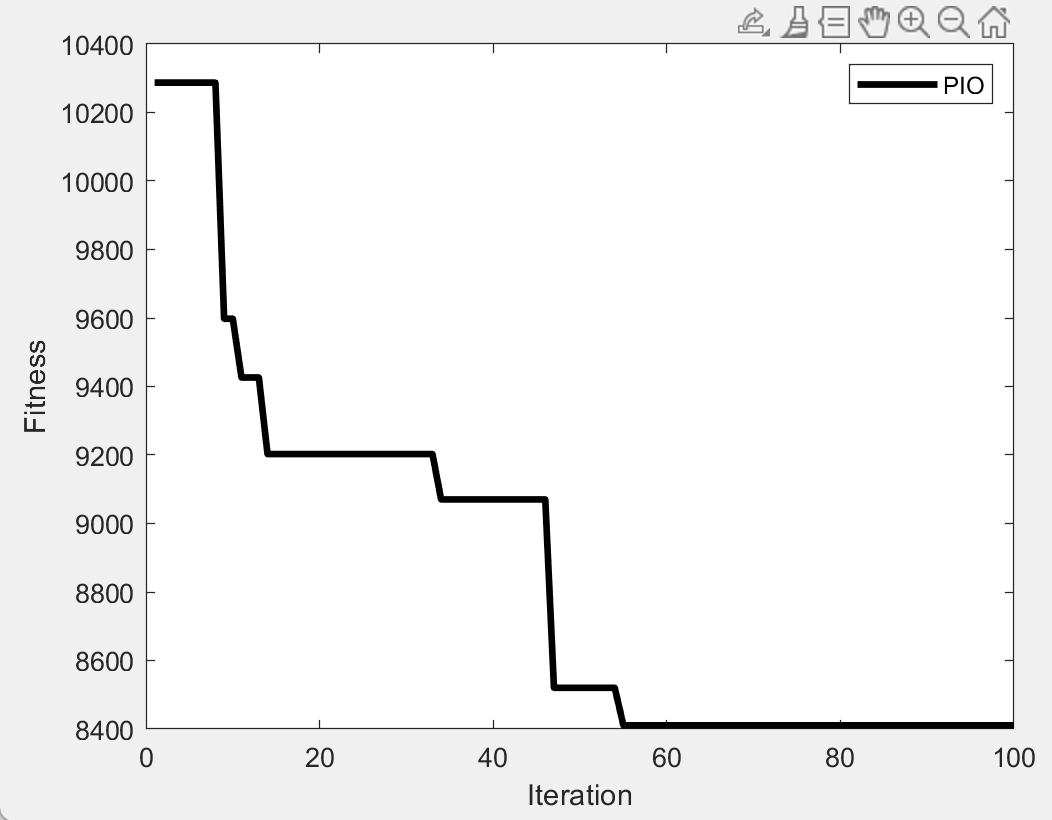
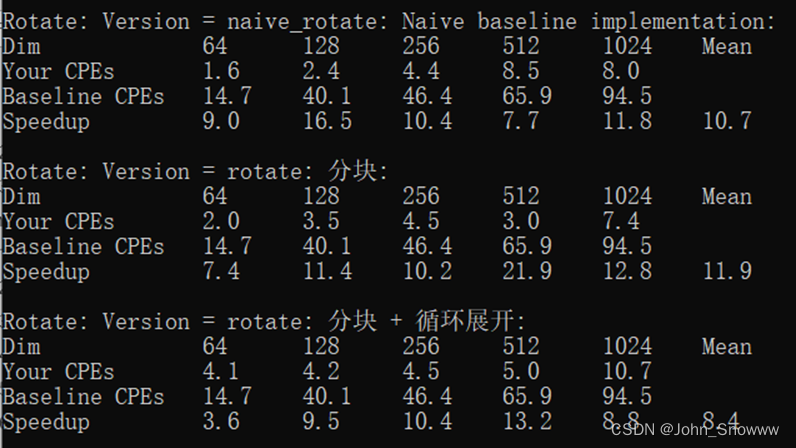
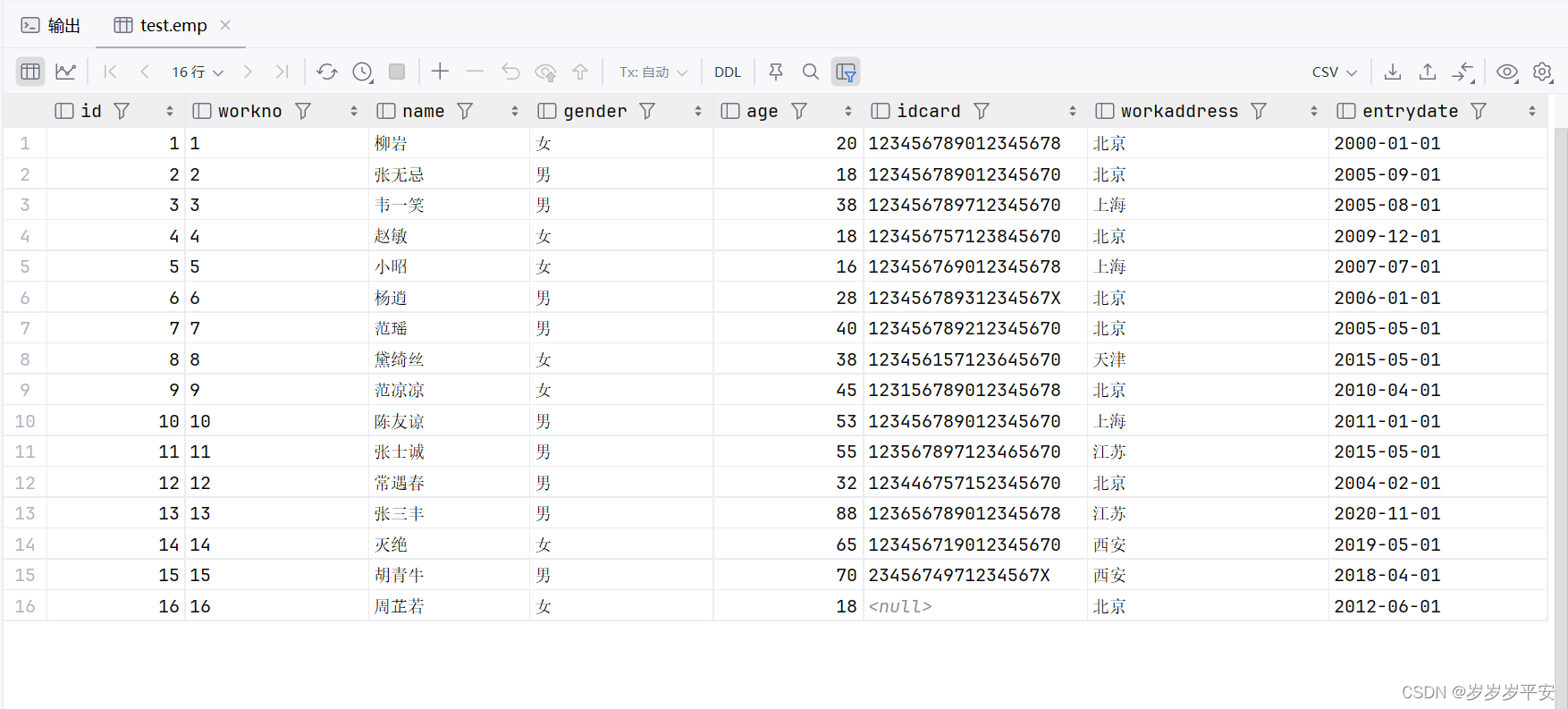
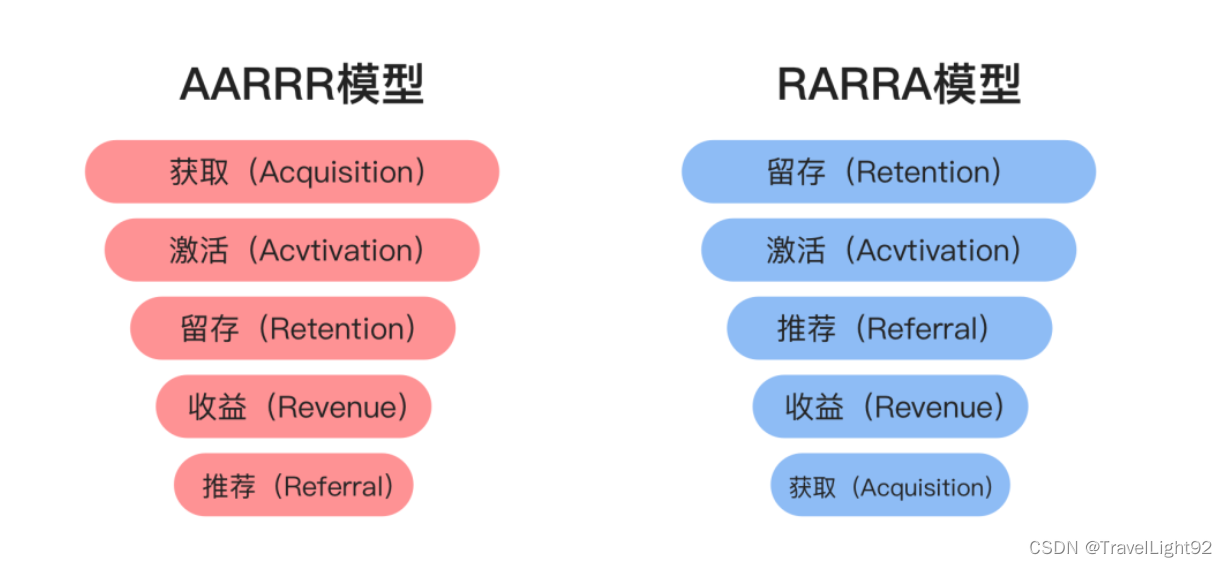
1.为什么要区分叶子节点和非叶子节点?
为了节省内存。在pytorch的计算图里只有两种元素:数据(tensor)和 运算(operation)。其中数据可分为:叶子节点(leaf node)和非叶子节点;叶子节点是用户创建的节点,不依赖其它节点;它们表现出来的区别在于反向传播结束之后,非叶子节点的梯度会被释放掉,只保留叶子节点的梯度,这样就节省了内存。
PS:注意这里的描述“非叶子节点的梯度会被释放掉”。这其实暗含了非叶子节点必须是要参与梯度计算的,也就是requires_grad=True,同时也意味着requires_grad=False的节点一定是叶子节点,因为这样的tensor压根不参与求导,也没梯度,自然不需要“释放掉梯度”。这就成为了判别叶子节点和非叶子节点的第一个标准,见下。
2.如何区分叶子节点和非叶子节点?
判断一个节点是否是叶子节点,只需满足以下条件之一:
A.所有requires_grad为False的张量(Tensor) 都为叶子节点( leaf Tensor)
B.requires_grad为True的张量(Tensor),如果他们是由用户创建的,则它们是叶张量(leaf Tensor)。这意味着它们不是运算的结果,因此grad_fn为None。
>>> a = torch.rand(10, requires_grad=True)
>>> a.is_leaf
True
#a was created by user
>>> b = torch.rand(10, requires_grad=False)
>>> b.is_leaf
True
>>> c = torch.rand(10, requires_grad=True) + 2
>>> c.is_leaf
False
# c was created by the addition operation
PS:神经网络层中的权值w的tensor均为叶子节点





























![YOLOv8_obb预测流程-原理解析[旋转目标检测理论篇]](https://img-blog.csdnimg.cn/direct/03ddebdec3124153b1101c6e9606766f.png)