1.Spark MLlib概述
MLlib是Spark的机器学习(Machine Learning)库,旨在简化机器学习的工程实践工作,并方便扩展到更大规模。
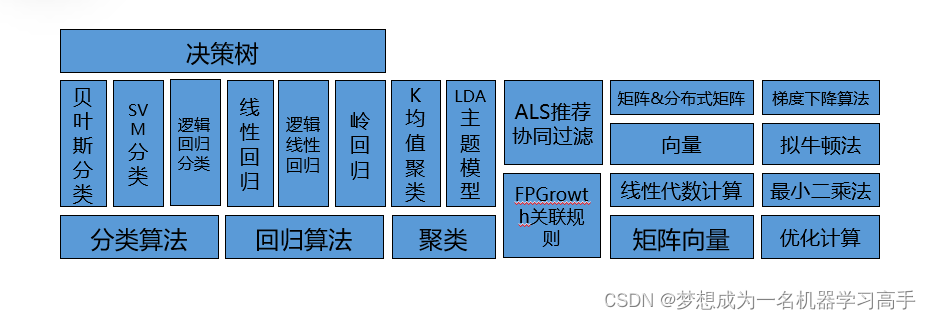
MLlib由一些通用的学习算法和工具组成,包括分类、回归、聚类、协同过滤、降维等,同时还包括底层的优化原语和高层的管道API。
2.Spark MLlib算法库
3.Spark核心概念RDD
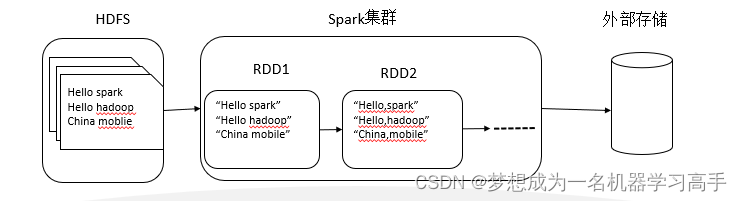
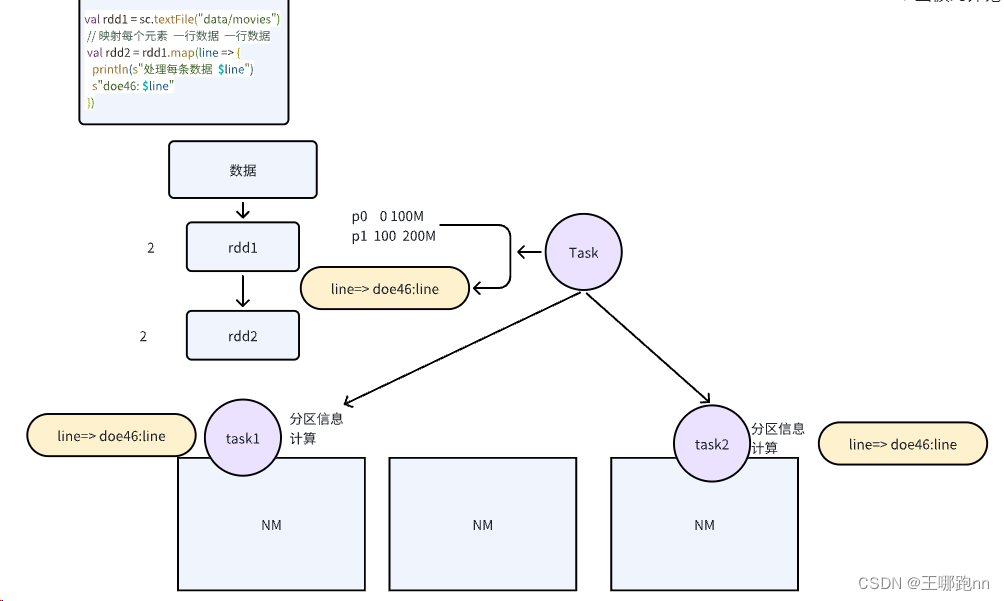
RDD(Resilient Distributed Datasets) 即弹性分布式数据集,是一个只读的,可分区的分布式数据集。
RDD 默认存储在内存,当内存不足时,溢写到磁盘。
RDD 数据以分区的形式在集群中存储。
RDD 具有血统机制( Lineage ),发生数据丢失时,可快速进行数据恢复。
RDD是Spark对基础数据的抽象。
RDD的生成:从Hadoop文件系统(或与Hadoop兼容的其它存储系统)输入创建(如HDFS);从父RDD转换得到新的RDD。
RDD的存储:用户可以选择不同的存储级别存储RDD以便重用(11种);RDD默认存储于内存,但当内存不足时,RDD会溢出到磁盘中。
RDD的分区:为减少网络传输代价,和进行分布式计算,需对RDD进行分区。在需要进行分区时会根据每条记录Key进行分区,以此保证两个数据集能高效进行Join操作。
RDD的优点:RDD是只读的,静态的。因此可提供更高的容错能力;可以实现推测式执行。
RDD属性
- RDD是在集群节点上的不可变的、只读的、已分区的集合对象
- 通过并行转换的方式来创建如(map,filter,join 等等)
- 失败自动重建
- 可以控制存储级别(内存、磁盘等)来进行重用
- 必须是可序列化的
RDD特点
- 分区列表(数据块列表)
- 计算每个分片的函数(根据父RDD计算出此RDD)
- 对父RDD的依赖列表
- RDD默认是存储于内存,但当内存不足时,会spill到disk(设置StorageLevel来控制)
- 每个数据分区的地址(如HDFS),key-value数据类型分区器,分区策略和分区数
RDD:Lineage和Dependency
Dependency(依赖)
- Narrow Dependencies(窄依赖)是指父RDD的每个分区最多被一个子RDD的一个分区所用。
- Wide Dependencies(宽依赖)是指父RDD的每个分区对应一个子RDD的多个分区。
Lineage(血统):
- 依赖的链条
- RDD数据集通过Lineage记住了它是如何从其他RDD中演变过来的。
4.RDD的算子
Transformation
- Transformation是通过转换从一个或多个RDD生成新的RDD,该操作是lazy的,当调用action算子,才发起job。
- 典型算子:map、flatMap、filter、reduceByKey等。
Action
- 当代码调用该类型算子时,立即启动job。
- Action操作是从RDD生成最后的计算结果
- 典型算子:take、count、saveAsTextFile等。
Transformation:
map算子:
map是对RDD中的每个元素都执行一个指定的函数来产生一个新的RDD;RDD之间的元素是一对一关系;
filter算子:
Filter是对RDD元素进行过滤;是经过func函数后返回值为true的原元素组成,返回一个新的数据集;
flatMap算子:
flatMap类似于map,但是每一个输入元素,会被映射为0到多个输出元素(因此,func函数的返回值是一个Seq,而不是单一元素),RDD之间的元素是一对多关系;
mapPartitions算子:
mapPartitions是map的一个变种。map的输入函数是应用于RDD中每个元素,而mapPartitions的输入函数是每个分区的数据,也就是把每个分区中的内容作为整体来处理的。
mapPartitionsWithIndex 算子:
mapPartitionsWithSplit与mapPartitions的功能类似, 只是多传入split index而已,所有func 函数必需是 (Int, Iterator<T>) => Iterator<U> 类型。
sample算子:
sample(withReplacement,fraction,seed)是根据给定的随机种子seed,随机抽样出数量为frac的数据。
withReplacement:是否放回抽样;fraction:比例,seed:0.1表示10% ;
union算子:
union(otherDataset)是数据合并,由原数据集和otherDataset联合而成,返回一个新的数据集。
intersection算子
intersection(otherDataset)是数据交集,包含两个数据集的交集数据,返回一个新的数据集;
distinct算子
distinct([numTasks]))是数据去重,是对两个数据集去除重复数据,numTasks参数是设置任务并行数量,返回一个数据集。
groupByKey算子
groupByKey([numTasks])是数据分组操作,在一个由(K,V)对组成的数据集上调用,返回一个(K,Seq[V])对的数据集。
reduceByKey算子
reduceByKey(func, [numTasks])是数据分组聚合操作,在一个(K,V)对的数据集上使用,返回一个(K,V)对的数据集,key相同的值,都被使用指定的reduce函数聚合到一起。
aggregateByKey算子
aggregateByKey(zeroValue: U)(seqOp: (U, T)=> U, combOp: (U, U) =>U) 和reduceByKey的不同在于,reduceByKey输入输出都是(K, V),而aggregateByKey输出是(K,U),可以不同于输入(K, V) ,aggregateByKey的三个参数:
zeroValue: U,初始值,比如空列表{} ;
seqOp: (U,T)=> U,seq操作符,描述如何将T合并入U,比如如何将item合并到列表 ;
combOp: (U,U) =>U,comb操作符,描述如果合并两个U,比如合并两个列表 ;
所以aggregateByKey可以看成更高抽象的,更灵活的reduce或group
combineByKey算子
combineByKey是对RDD中的数据集按照Key进行聚合操作。聚合操作的逻辑是通过自定义函数提供给combineByKey。
combineByKey[C](createCombiner: (V) ⇒ C, mergeValue: (C, V) ⇒ C, mergeCombiners: (C, C) ⇒ C, numPartitions: Int):RDD[(K, C)]把(K,V) 类型的RDD转换为(K,C)类型的RDD,C和V可以不一样。
sortByKey算子
sortByKey([ascending],[numTasks])是排序操作,对(K,V)类型的数据按照K进行排序,其中K需要实现Ordered方法。
join算子
join(otherDataset, [numTasks])是连接操作,将输入数据集(K,V)和另外一个数据集(K,W)进行Join, 得到(K, (V,W));该操作是对于相同K的V和W集合进行笛卡尔积 操作,也即V和W的所有组合。
连接操作除join 外,还有左连接、右连接、全连接操作函数: leftOuterJoin、rightOuterJoin、fullOuterJoin
cogroup算子
cogroup(otherDataset, [numTasks])是将输入数据集(K, V)和另外一个数据集(K, W)进行cogroup,得到一个格式为(K, Seq[V], Seq[W])的数据集。
cartesian算子
cartesian(otherDataset)是做笛卡尔积:对于数据集T和U 进行笛卡尔积操作, 得到(T, U)格式的数据集。
Action:
reduce算子
reduce(func)是对数据集的所有元素执行聚集(func)函数,该函数必须是可交换的。
collect算子
collect是将数据集中的所有元素以一个array的形式返回。
count算子
返回数据集中元素的个数。
takeOrdered算子
takeOrdered(n, [ordering])是返回包含随机的n个元素的数组,按照顺序输出。
saveAsTextFile算子
把数据集中的元素写到一个文本文件,Spark会对每个元素调用toString方法来把每个元素存成文本文件的一行。
countByKey算子
对于(K, V)类型的RDD. 返回一个(K, Int)的map, Int为K的个数。
foreach算子
foreach(func)是对数据集中的每个元素都执行func函数。
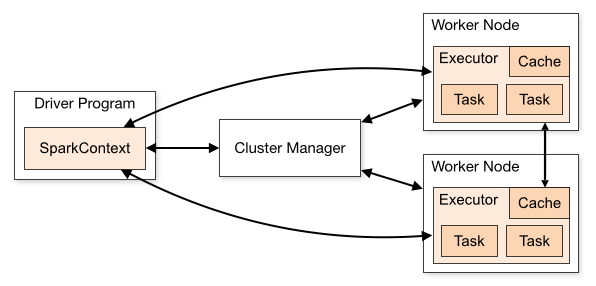
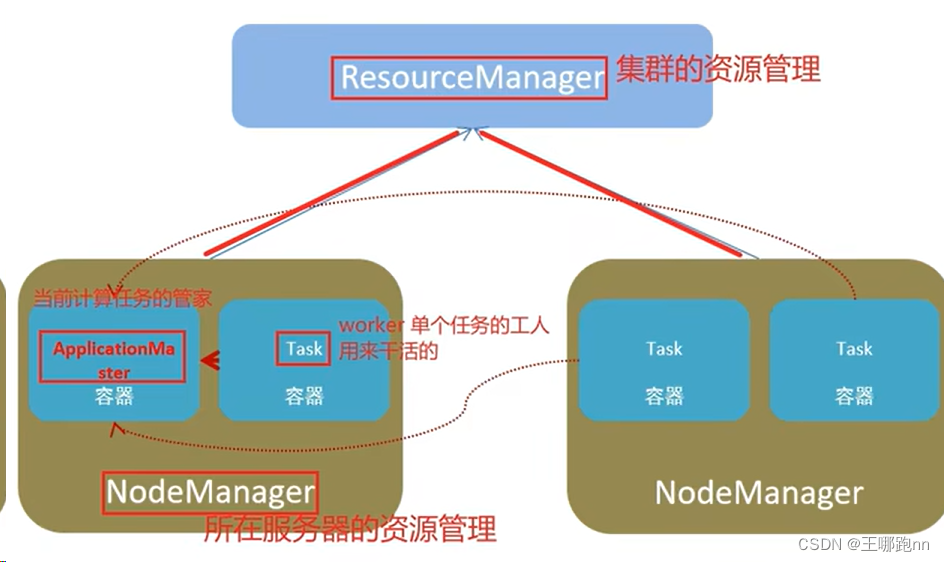
Spark环境的搭建:
Spark这里我们用到了java API,搭建的语言我们主要是用到了Scala,下面是Scala语言对Spark环境的搭建,Scala的搭建我会在后续文章讲到
import org.apache.spark.{SparkConf, SparkContext}
object spark {
def main(args: Array[String]): Unit = {
val conf = new SparkConf() // Spark的配置文件
conf.setMaster("local")
conf.setAppName("RDD8.18") // 上面都是在设置Spark的部署模式,和名字
val sc = new SparkContext(conf) // 将Spark的配置文件导入
// RDD算子的创建方法有两种
// 1 先随便创建,之后将其转换为RDD算子
val lst = List(1,3,5)
val rdd1 = sc.parallelize(lst)
// 直接创建RDD算子
val rdd2 = sc.parallelize(List("hello world","hello Spark","hello linux"))
// 我们可以通过Ctrl键加鼠标左键点击map,我们可以发现其返回值是RDD,因此map属于transformstions算子,count同理,可以看出其返回值类型不是RDD,因此我们可以判断出其是ACtion算子
val rdd3 = rdd1.map((x:Int) => println("x="+x))
rdd3.count()
rdd2.flatMap((word:String)=>{
val danci = word.split(" ")
danci
}).map((_,1)).foreach(println(_))
}
}




















![[Redis]Zset类型](https://img-blog.csdnimg.cn/direct/be9e257eb6794c4783d31acaaf30f303.png)