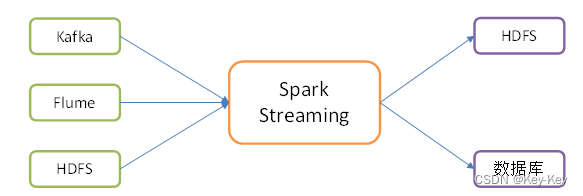
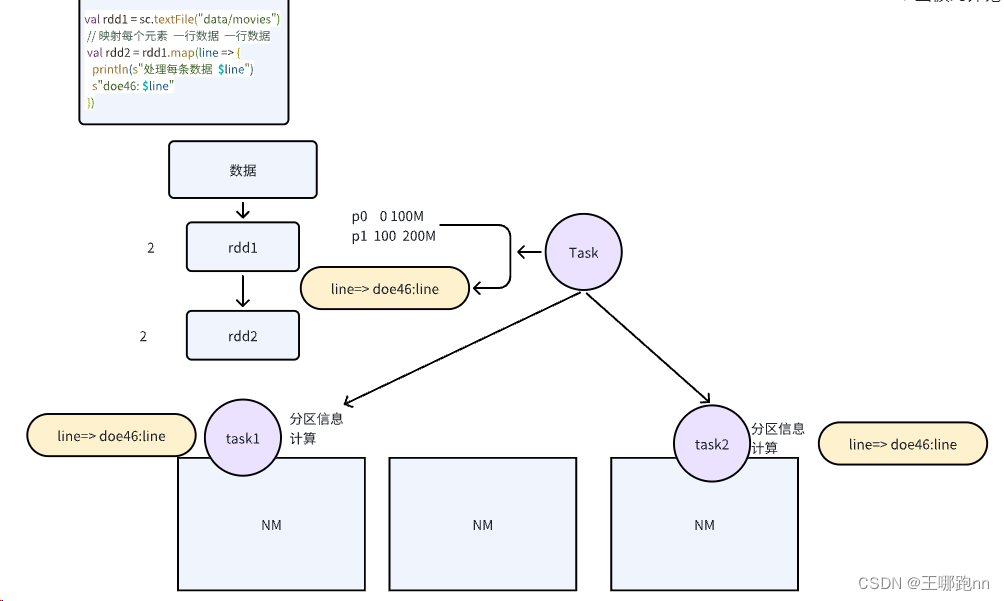
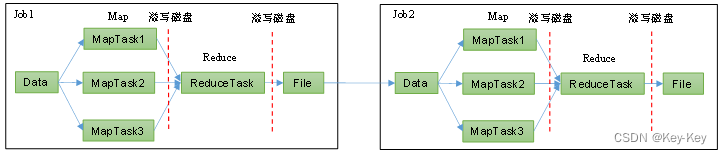
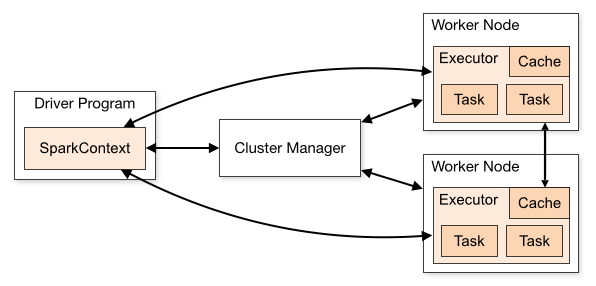
Apache Spark 提供了两种主要类型的算子:Transformation(转换)和Action(动作)。这些算子是Spark的核心功能,用于处理分布式数据集(RDD或DataFrame/Dataset)。
1. Transformation 算子
- Lazy Evaluation(惰性求值) - Transformation算子不会立即执行,而是在遇到Action算子时触发一个完整的计算过程。
map(func): 对RDD中的每个元素应用函数func进行转换。flatMap(func): 类似于map,但是返回的是一个序列,因此结果是一个扁平化的RDD。filter(func): 根据给定的条件函数过滤出满足条件的元素。groupBy(keyFunc, valueFunc): 按照keyFunc的结果对RDD进行分组,并可以对每个分组应用valueFunc进一步转换。join(otherDataset, [joinExprs]): 将两个RDD按指定键进行连接操作。union(otherDataset): 合并两个RDD。distinct(): 返回RDD中所有不重复的元素。
2. Action 算子
- Eager Evaluation(及早求值) - Action算子会触发实际的计算,并将结果返回到驱动程序或者写入外部存储系统。
collect(): 获取整个RDD的所有元素,并作为一个数组返回到驱动程序。count(): 计算RDD中元素的数量。first(): 获取RDD的第一个元素。take(n): 获取RDD的前n个元素。reduce(func): 使用一个二元函数对RDD中的元素进行聚合操作,返回单个结果。saveAsTextFile(path): 将RDD的内容以文本文件的形式保存在HDFS或其他支持的文件系统上。foreach(func): 对RDD中的每个元素执行一个函数操作,通常用于副作用操作,如打印、写入数据库等。
对于DataFrame/Dataset API,Spark SQL提供了更多特定于结构化数据的操作,例如:
select(exprs): 选择列或者基于现有列创建新列。where(cond): 过滤行。groupBy(cols): 按指定列进行分组。agg(exprs): 在分组后进行聚合操作。
请注意,上述内容适用于Spark 2.x版本,而在Spark 3.x中,API可能有更新和改进。在实际使用时,请查阅最新的Spark官方文档以获取最新信息。