双塔模型的结构
用户的特征,我们知道用户ID还能从用户填写的资料和用户行为中获取很多特征,包括离散特征和连续特征。所有这些特征不能直接输入神经网络,而是要先做一些处理,比如用embedding层把用户ID映射到一个向量
跟之前我们讲过的离散特征的做法相同,用户还有很多离散特征,比如所在城市感兴趣的话题等等。
用embedding层把用户的离散特征映射成向量,对于每个离散特征,用单独一个embedding层得到一个向量,比如用户所在城市,用一个embedding层
用户感兴趣的话题,用另一个embedding层
对于性别这样类别数量很少的离散特征,直接用one hot编码就行,可以不做embedding
用户还有很多连续特征,比如年龄、活跃程度、消费金额等等。
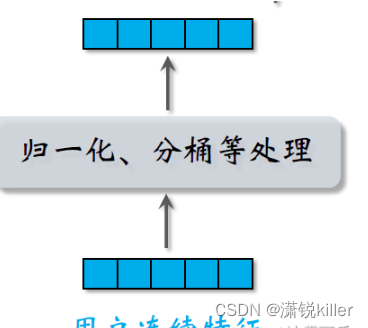
不同类型的连续特征有不同的处理方法,最简单的是做归一化,让特征均值是零,标准差是一。
有些长尾分布的连续特征需要特殊处理,比如取log,比如做分桶,做完特征处理,得到很多特征向量,把这些向量都拼起来输入神经网络。神经网络可以是简单的全连接网络,也可以是更复杂的结构,比如深度交叉网络。
神经网络输出一个向量,这个向量就是对用户的表征。
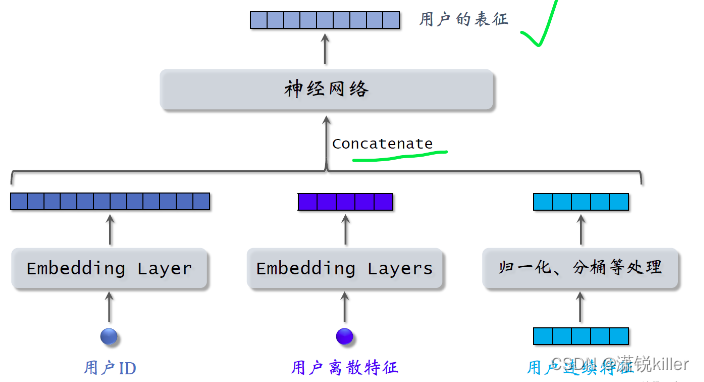
做召回用到这个向量。
物品的特征也是用类似的方法处理
用embedding层处理物品ID和其他离散特征,
用归一化取对数或者分桶等方法处理物品的连续特征,
把得到的特征输入一个神经网络。
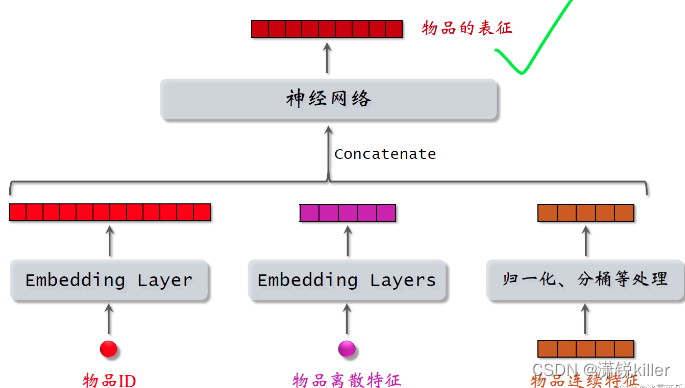
神经网络输出的向量就是物品的表征,用于召回。
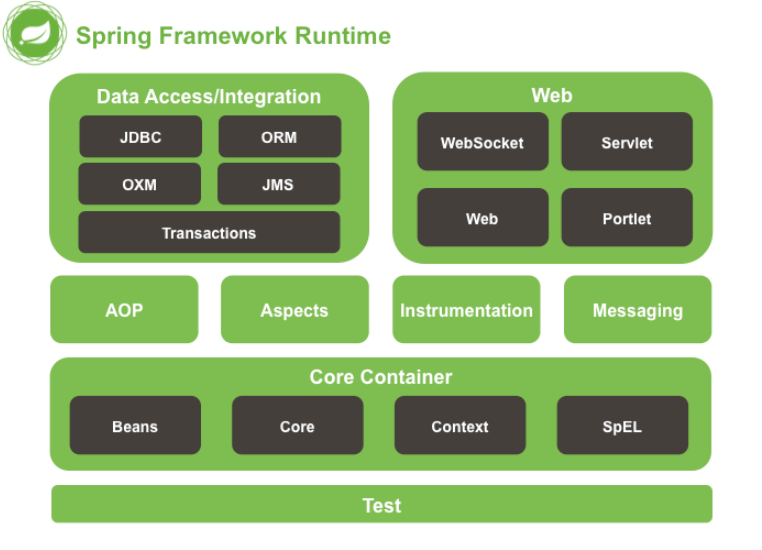
双塔模型
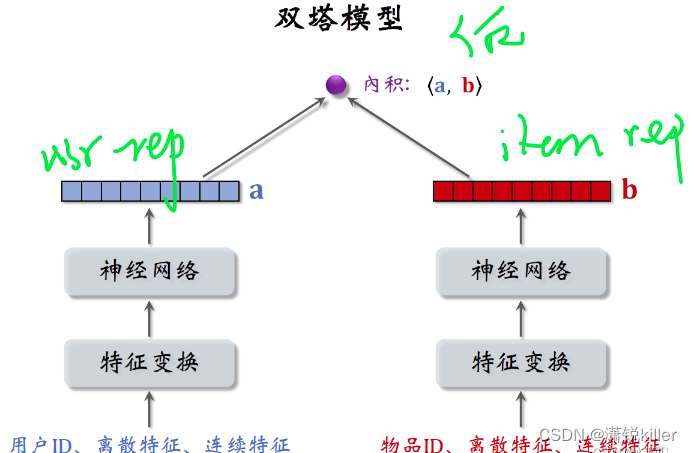
本模型直接拿用户表征rep和物品表征rep去融合,史称后端特征融合模型
左边的塔提取用户的特征
右边的它提取物品的特征
跟上一篇文章的矩阵补充模型相比,双塔模型的不同之处就在于使用了ID 之外的多种特征,
作为双塔的输入,两个塔各输出一个向量记作a和b,
两个向量的内积就是模型最终的输出rate,它即预估用户对物品的兴趣。
现在更常用的输出方法是余弦相似度。
两个塔的输出,分别记作向量a和b,余弦相似度意思是两个向量夹角的余弦值,
它等于向量内积除以a的二范数,再除以b的二范数,
其实就相当于先对两个向量做归因化,然后再求内积
余弦相似度的大小介于负一到正一之间。
二范数,也称为欧几里得范数或L2范数,在数学中是用来量化向量或矩阵大小的一种度量方式。根据不同的对象,二范数有两种主要的定义:

因为它提供了量化向量或矩阵大小的直观方式,并且与几何距离的概念紧密相关。
双塔模型的训练方法:pointwise,parawise,listwise

























![[数据集][目标检测]塑料纸张垃圾袋检测数据集VOC+YOLO格式1.5w张3类别](https://img-blog.csdnimg.cn/direct/d62db2c32c7345f9a9f11a482a983d90.png)