本文继续给大家分享ComfyUI的基本使用技巧:抠图,或者说去除背景。抠图是处理图片的一项常见工作,是设计师们的基本能力,现在有了AI,抠图的效率也得到了极大的提升。最近看到有小伙伴通过AI抠图赚了外国人1000美刀,怀着激动的心情,特别把这个技术给大家分享一下。
除了抠图,我还会介绍一下基于抠图的背景替换,不仅会介绍图片背景的替换,也会分享视频背景的替换方法。
大家抓好扶手,我们马上就要开车了。

ComfyUI 是什么?
有的同学可能还不知道 ComfyUI 是什么,我这里做一个简单的介绍。
ComfyUI 是一个基于扩散模型的AI绘画创作工具,扩散模型就是大家常说的 Stable Diffusioin,简称SD。
ComfyUI 使用工作流的方式,可定制性很强,可以让创作者们搞出各种新奇的玩意,也可以实现更高的自动化水平,创作方法更容易传播复现,发展势头特别迅猛。
不过 ComfyUI 的上手门槛有点高,用户需要对 Stable Diffusion 以及各种数字技术的原理有一定的了解才行。这个系列就会介绍 ComfyUI 的一些基础概念和使用方法,让大家更快的掌握 ComfyUI 的使用技巧,创作出自己独特的艺术作品。
到哪里使用 ComfyUI
安装 ComfyUI 的难处
ComfyUI 本身是一个开源软件,大家可以安装到自己的电脑上使用。
但是但是事情往往没有说起来这么简单:
- 首先你要通过Github来下载程序,后续还要下载大量的模型,这需要特殊网络设置;
- 然后你还要懂点电脑技术,需要执行一大堆的命令;
- 最后你还要有一个牛逼的Nvidia显卡,显存8G起步,越大越好。
前两个花点小钱就能解决,最后这个要求可是要花大价钱的,差不多的3090显卡就需要七八千,玩起来没压力的4090更需要1.5个W左右。
当然,如果上边的这三个要求对你来说都是小菜一碟,你可以看看我这篇文章:
ComfyUI 完全入门:安装部署 - 掘金 (juejin.cn)
云环境免费使用
你可能就是想试试,或者说就处理几张图片,没必要搞这么大的阵仗啊。怎么办?
使用云服务器。
- 最近乘着AI的狂风,京东也大举进入AIGC领域了,新用户赠送两个小时的使用时长,足够我们应应急或者尝尝鲜了。
- 我也在京东云上制作了一个 ComfyUI 的镜像,内置了常见的模型和工作流(包括本文介绍的抠图工作流),点点鼠标,就能开始创作。
也就是说你不用特殊网络,也不用自己安装,更不用花钱,就可以体验到这个强大的AI绘画工具。
京东云赠送的使用时长通过代金券的形式发放,给公众号“萤火遛AI”发消息:京东云,即可领取。
京东云官方地址:www.jdcloud.com/,注册登陆就不说了,相信大家应该都能搞定。
领取到代金券后,请在“费用”-“代金券管理”中激活代金券,操作如下图所示。

然后我们就可以去开AI服务器了,访问地址:gcs-console.jdcloud.com/instance/li…
请按照下边的步骤创建AI服务器:
1、首先在“实例列表”页面点击“创建”:

2、在打开的“购买GCS实例”页面点击“按配置”,这种就是按使用量计费,GCS目前按照分钟计费。页面上没有显示常见的显卡型号,不过经我实际测试,目前配置的是RTX 4090显卡的GPU实例。

3、还是在“购买GCS实例”页面,我们移动到下方,应用这里选择“ComfyUI”,注意其中提到这是“萤火遛AI定制版本”,是萤火君专门给大家定制的,填了很多坑。因为上边已经激活了代金券,所以直接点击“立即购买”就可以了。

4、返回到GCS实例列表页面,等待GCS实例创建成功。
实例启动成功后,状态会显示“运行中”,我们只要依次点击“应用”-“自定义应用”,就可以在浏览器中打开ComfyUI了,不用执行任何技术命令,是不是很爽!
当然如果你要进行一些技术操作,也可以通过实例提供的 JupyterLab 去完成。
目前京东云还没有停止服务器的功能(据打听正在开发中),用完了记得点击“释放”,以免继续扣费。

5、加载工作流:如下图所示,初次打开是英文界面,先切换到中文;然后“加载”按钮右侧有个下拉按钮,点击就可以加载镜像内置的工作流。如果你想加载本地工作流,点击“加载”按钮本身就可以了。

AI抠图
这个工作流很简单,我们直接看下吧。

左边有两个节点:
- 加载图像:就是上传一张待处理的图片。点击“choose file to upload”按钮即可上传。
- 图像缩放:这个不是必需的,只是如果图片太小不容易识别,图片太大则处理的太慢,所以我加了一个缩放,你可以根据自己的需要来,不想要就删掉。
这里分享一个小窍门,如果暂时不想用某个节点,我们可以在这个节点上点击右键,选择“忽略节点”,这个节点就被跳过了。如果想恢复,还是点击这个“忽略节点”。

这个工作流的右边,也有两个节点,其实是两种抠图的方法,很难说哪个更好,大家根据实际效果选择吧。
RemBG:比较老牌的抠图方式,介绍下它的几个参数:
model:有多个抠图模型可供选择:
- u2net:通用的的预训练模型,通常用这个就行。
- u2netp:u2net的轻量级版本。
- u2net_human_seg:专门针对人像分割的预训练模型,只是分割人像时建议使用。
- u2net_cloth_seg:专门从人像上抠衣服的预训练模型,它会把衣服分成三部分:上半身、下半身和全身。
- silueta:和u2net相同,但是大小减少到43Mb,方便在小内存机器上使用。
- isnet-general-use :一个新的通用的预训练模型。
- isnet-anime:专门针对动画人物的高精度分割。
Alpha matting:Alpha遮罩,这是一个比较专业的图像处理术语。在图像处理中,有一个东西用来表示图像中每个像素点的透明度,这个东西称为Alpha通道;Alpha遮罩利用Alpha通道来控制图像的透明度,从而达到隐藏或显示某些部分的目的;在抠图这里就是努力让前景部分都显示出来,让背景部分都变透明。这个选项有三个参数:
-
- Foreground threshold:前景图像的阈值,值过小背景可能被识别为前景,值过大前景可能被识别为背景。
- Background threshold:背景图像的阈值,值小了前景可能被识别为背景,值大了背景可能识别为前景。
- Erode size:Alpha抠图腐蚀尺寸,通过在图像中构建一个长宽为这个值的矩形进行腐蚀。太小了前景和背景分离不彻底,边缘有交叉;太大了前景和背景会腐蚀的太多,边缘缺损明显。
使用Alpha遮罩时可以先用这几个经验值:( 220, 100, 15),具体参数值再根据实际情况进行调整。
BRIA:新进的抠图模型,很多时候效果比RemBG要棒。没啥参数可以设置的,需要两个节点:
- BRIA_RMBG Model Loader:用来加载模型。
- BRIA RMBG:对图片进行抠图。
工作流,以及其中用到的插件、模型,我已经整理好了,需要的同学请到文末获取。
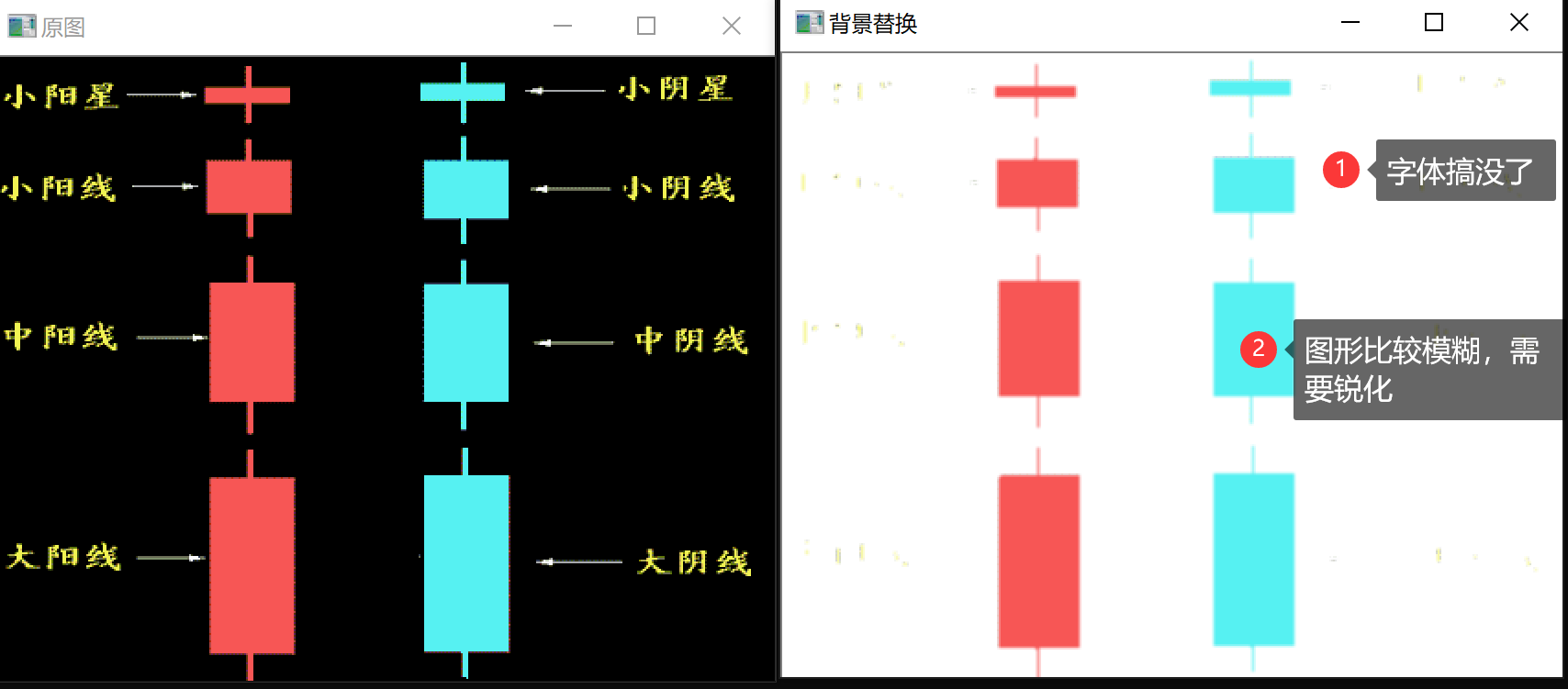
图片背景替换
图片背景替换就是在抠图的基础上再增加图片合成的能力,如下图所示:

其中增加的就是这个“图像混合模式节点”:

这个节点是 WAS Node Suite 插件提供的,官方访问地址:github.com/WASasquatch…。
工作流,以及其中用到的插件、模型,我已经整理好了,需要的同学请到文末获取。
视频背景替换
视频背景替换的基本思路是,先把视频帧拆出来,然后一帧帧的替换背景。
我在抖音上找到了一个小姐姐的跳舞视频,准备把视频背景替换成蓝天白云草地。
这个工作流主要由3部分组成,分别介绍下:
加载素材
这里涉及三个节点:

加载视频:选择本地视频上传即可。注意这里的两个参数:
- 强制频率:视频一般都是每秒30帧,但是帧数越多,我们拆出来的图片也越多,所以这里可以适当降低,不影响观看就行了。
- 强制尺寸:太大视频处理起来慢,太小的视频可能效果不好,这里可以调整下。Custom Height 就是固定高度,宽度自适应。
视频信息:提取出视频的宽高、帧数、帧率等,后边合成新视频的时候会用到这个帧率,提取出来就不用手动设置了。
加载图像:这里就是要使用的视频新背景,注意和视频的宽高保持一致。
替换背景
主要节点和设置前边替换图片背景已经讲过了,注意这里增加了两个信息的节点:
图像批次到图像列表、图像列表到图像批次
主要是因为视频需要的是图像批次,而图像混合需要的是图像列表,做一个适配而已。

合成视频
最后就是合成视频了,注意选择格式为mp4, 别的没什么好讲的。

合并为视频使用的是插件:ComfyUI-VideoHelperSuite,官方程序地址:github.com/Kosinkadink…
最后小姐姐跳舞的视频可以在这里看:
资源下载
别忘了领京东云代金券哦,给公/众\号 “萤火遛AI” 发消息:京东云 ,即可获取。
单张抠图工作流、插件、抠图模型:给公/众\号 “萤火遛AI” 发消息:抠图 ,即可获取。
批量抠图工作流:制作不易,目前仅在我的AI绘画专栏发布。加入专栏,可以零门槛,全面系统的学习 Stable Diffusion 创作,让灵感轻松落地!如有需要请点击链接进入:xiaobot.net/post/033402…
以上就是本文的主要内容。
用好 ComfyUI:
- 首先需要对 Stable Diffusion 的基本概念有清晰的理解,熟悉 ComfyUI 的基本使用方式;
- 然后需要在实践过程中不断尝试、不断加深理解,逐步掌握各类节点的能力和使用方法,提升综合运用各类节点进行创作的能力。
我将在后续文章中持续输出 ComfyUI 的相关知识和热门作品的工作流,帮助大家更快的掌握 Stable Diffusion,创作出满足自己需求的高质量作品,感兴趣的同学请及时关注。
那么,我们该如何学习大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
一、大模型全套的学习路线
学习大型人工智能模型,如GPT-3、BERT或任何其他先进的神经网络模型,需要系统的方法和持续的努力。既然要系统的学习大模型,那么学习路线是必不可少的,下面的这份路线能帮助你快速梳理知识,形成自己的体系。
L1级别:AI大模型时代的华丽登场

L2级别:AI大模型API应用开发工程

L3级别:大模型应用架构进阶实践

L4级别:大模型微调与私有化部署

一般掌握到第四个级别,市场上大多数岗位都是可以胜任,但要还不是天花板,天花板级别要求更加严格,对于算法和实战是非常苛刻的。建议普通人掌握到L4级别即可。
以上的AI大模型学习路线,不知道为什么发出来就有点糊,高清版可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。