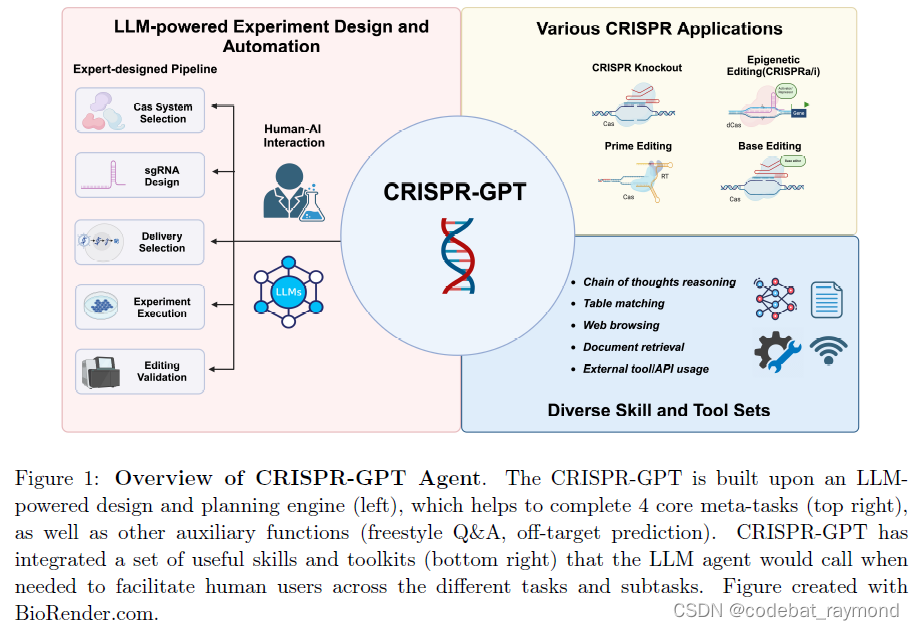
前言
在上一篇文章中,我们学习了如何利用MetaGPT框架构建单智能体和多智能体,并通过一个技术文档撰写Agent和课后作业较为完整的理解一个Agent的需求分析和开发流程;但是技术要和应用结合才能得到更广泛的推广;在本文中,作者将以一个Github订阅智能体为例,带领读者感受Agent应用的潜力;
一、介绍
不知各位读者有没有阅读GitHub Trending的习惯,GitHub Trending 是 GitHub 上一个专门显示当前最受欢迎项目的页面。它根据项目在过去一个月内的星标数、分支数和贡献者数等因素进行排名,展示出最热门的开源项目。无论对程序员、技术极客以及科技博主,GitHub Trending都是一个绝好的信息源,其类似新闻的热榜,阅读``GitHub Trending`有如下的好处:
- 了解最新技术趋势:最热门的编程语言、框架和工具,帮助开发者保持对技术发展的敏锐。
- 发现优秀项目:很多优秀开源项目通常具有创新性、实用性和可拓展性,可以为我们自己的项目提供灵感和参考。
- 学习先进经验:通过阅读热门项目的代码和文档,可以学习到其中的设计思想、编码技巧和最佳实践,提高自己的编程能力。
- 参与开源社区:通过参与热门项目的讨论和贡献代码,可以与其他开发者建立联系,扩展自己的社交圈子,并为开源社区做出贡献。
因此,及时高效地从GitHub中获取最新的技术发展信息和资源对于开发者很重要。而今天,我们就以这个为我们的需求,构建我们的OSS 订阅Agent。
通过本文,你将学习到:
- 基于Python构建GitHub Trending爬虫Action
- 基于MetaGPT构建仓库内容生成Action
- 构建Discord机器人
- 构建邮箱订阅的论文总结Agent
二、OSS订阅Agent实现
1.需求分析
开始之前,我们首先需要知道MetaGPT中,订阅Agent机制SubscriptionRunner模块;
SubscriptionRunner模块是metagpt中的一个模块,它提供了``SubscriptionRunner类,用于提供一个Role的定时运行方式。基于SubscriptionRunner类,我们可以定时触发运行一个Role,然后将Role`的执行输出通知给用户。下面是一个参考案例代码:
import asyncio
from metagpt.subscription import SubscriptionRunner
from metagpt.roles import Searcher
from metagpt.schema import Message
# 定义触发器,每24小时抛出一个Message
async def trigger():
while True:
yield Message("the latest news about OpenAI")
await asyncio.sleep(3600 * 24)
# 回调函数,实例话一个订阅器实例,当触发器触发后,打印返回的内容
async def callback(msg: Message):
print(msg.content)
# 主函数,开始运行该计划任务
async def main():
pb = SubscriptionRunner()
await pb.subscribe(Searcher(), trigger(), callback)
await pb.run()
asyncio.run(main())
这个模块中,我们的OSS订阅智能体,主要包含三个要素:
- Role:智能体本身
- Trigger:触发器
- Callback:回调函数
我们整理一下实现的思路:

- 1.构建一个爬虫
Action,其会从Github Trending将我们感兴趣的开源类目信息爬取下来; - 2.触发
Trigger,即什么情况下我们的Agent才会运行,即按照哪些机制判断是否爬取,如定时爬取或者页面更新时爬取,本文中以每天早上9点定时爬取为例; - 3.回调函数
callback,当Agent启动爬取到页面数据,后续执行的操作是什么,本文中我们将爬取的信息根据Prompt模版整理为一个每日推送的文章;然后将文章信息发送到我们的订阅平台(Discord、Telegram或QQ邮箱);
理清思路以后,我们开始逐个实现:
2.OSSAgent Role实现
按照我们上一篇文章的思路,我们这里分别需要构建爬虫Crawl Action和模版输出Action:
(1)Crawl Action实现
①爬取方式确定
实现数据爬取有三种方式:
- 基于API:最高效,最稳定,但是经过作者的检索,Github并没有提供Github Trending的API接口,这个方案放弃😣;
- 基于自动化页面抓取:稳定,低效,开发较复杂,例如使用selenium等框架,模拟人类行为进行数据抓取,可以获得大多数页面数据;但是需要配置环境;可选🫡:
- 基于网页爬虫:稳定情况看爬取目标,但是实现较为简单,爬取静态页面高效;可以用这个😏;
我们选择了使用基于网页爬取,当然,这也是需要一定的Python爬虫基础和Web基础,了解页面元素构成和各种元素选择器;作者常用的爬虫框架组合是常见的requests和BeautifulSoup,前者用于数据爬取,后者用于数据解析,今天学习的时候发现官方文档使用的是aiohttp,作者并不熟悉这个第三方库,与GPT-4o学习了一下,总结了其与requests的异同和特点:
区别:
- 同步和异步:requests 是一个同步库,它发送请求后会阻塞代码执行,直到收到响应;aiohttp 是一个异步库,它发送请求后可以继续执行其他代码,收到响应后再处理。
- 性能:由于 aiohttp 是异步库,在处理大量请求时,它的性能比 requests 更好,因为它可以在等待响应的同时处理其他请求。
- 功能:虽然 requests 和 aiohttp 都可以发送 HTTP 请求,但 aiohttp 还支持 websocket、中间件等功能。
联系:
- 都是 Python 中用于发送 HTTP 请求的库。
- 都支持常见的 HTTP 方法,如 GET、POST、PUT、DELETE 等。
- 都支持 SSL 加密和代理服务器。
特点:
- requests 的特点:
简单易用:requests 的 API 简单易用,只需几行代码就可以发送 HTTP 请求。
支持各种数据格式:requests 支持 JSON、表单数据、多部分文件上传等各种数据格式。
自动处理重定向和 cookie:requests 可以自动处理重定向和 cookie,无需手动处理。
- aiohttp 的特点:
异步处理:aiohttp 基于 Python 的 async/await 语法,支持异步处理多个请求。
高性能:aiohttp 使用异步 I/O 模型,在处理大量请求时表现出色。
支持 websocket:aiohttp 支持 websocket 协议,可以用于实时通信。
总而言之,aiohttp库看起来最大的特点就是异步高效了,对于``MetaGPT,其框架中处处都能看到异步的痕迹,这对Agent数据爬取处理更友好,我们今天就使用aiohttp`库进行数据爬取;
如果爬取目标为国外网页,但代码在国内本地运行,请修改``metagpt
项目文件夹下的config/key.yaml`中配置代理服务器地址:GLOBAL_PROXY: http://127.0.0.1:8118 # 改成自己的代理服务器地址
②确定爬取目标
打开[GitHub Trending 页面],选择我们要爬取的数据:

作者这里要爬取的数据有:
- 仓库名称
- 仓库链接
- 仓库简介
- 仓库Star数
- 仓库fork数
- 仓库的readme文件(如果有)
选择筛选条件:
- 语言:
python、nodejs- 时间范围:This week
- 关注目标:
repositories
细心的读者会发现,当我们选择不同的筛选条件时,我们请求的页面URL也是不同的,这说明页面筛选是Get请求,因此我们如果我们要爬取对应的数据,应该先筛选条件,再确定请求的URL:
 ##### ③解析网页
##### ③解析网页
我们进入到上一步选择的URL页面,然后按下F12进入到开发者页面,按照下图流程点击,确定爬取的目标元素:

由图可知,我们要爬取的目标中,每一个仓库项目信息都存储在class为Box-row的元素中,选择一个元素,逐级点击查看每个元素内部,可以看到,我们需要的这些数据都存储在这些元素中,我们只需要使用``aiphttp库爬虫请求目标页面,目标页面则返回整个页面的字符串数据,然后我们使用BeautifulSoup库解析获得的数据为结构化元素树格式,然后按照这些元素的定位符,如id和class`,定位数据,通过循环然后将这些数据爬取下来;

整理一下我们需要的数据的定位符:
- 单仓库所有信息元素类:
Box-row- 仓库名称:
h2标签下的a标签下的文本,可写作h2 a- 仓库链接:
h2标签下的a标签下的href属性值与https://github/com/组合- 作者:
a标签下class为text-normal的元素文本- 简介:
p标签下文本- Star:
a标签下class包含Link--muted的第一个元素文本,写作a.Link--muted[0]- Fork:
a标签下class包含Link--muted的第二个元素文本,写作a.Link--muted[1]- 本周Star数量:
span标签下class包含d-inline-block的元素文本,写作span.d-inline-block
页面分析完成,开始撰写代码爬取!!!🫡🫡🤓
④仓库列表数据爬取
代码学习非一日之功,但是在AI发达的当下,读者可以直接用我的代码来询问AI,我的思路:
- 先爬取页面提取所有
class属性值为Box-row的元素列表,存储起来,即获得所有仓库信息; - 对获取的列表信息进行循环遍历,对每个元素进行深入元素提取,包括该仓库的
name,url,description,language,
爬取网页并进行提取的代码如下:
import aiohttp # 导入 aiohttp 库,用于发送异步 HTTP 请求
import asyncio # 导入 asyncio 库,用于处理异步任务
from bs4 import BeautifulSoup # 导入 BeautifulSoup 库,用于解析 HTML 文档
async def fetch_html(url):
# 定义一个异步函数 fetch_html,用于获取 URL 对应的 HTML 内容
async with aiohttp.ClientSession() as session:
# 使用 aiohttp 创建一个会话上下文管理器
async with session.get(url) as response:
# 使用会话对象发送 GET 请求,并在响应对象上使用上下文管理器
return await response.text()
# 返回响应内容的文本格式
async def parse_github_trending(html):
# 定义一个异步函数 parse_github_trending,用于解析 GitHub Trending 页面的 HTML 内容
soup = BeautifulSoup(html, 'html.parser')
# 使用 BeautifulSoup 解析 HTML 内容,生成一个 BeautifulSoup 对象
repositories = []
# 创建一个空列表,用于存储解析后的仓库信息
for article in soup.select('article.Box-row'):
# 使用 CSS 选择器选择所有类名为 Box-row 的 article 标签
repo_info = {}
# 创建一个空字典,用于存储单个仓库的信息
repo_info['name'] = article.select_one('h2 a').text.strip()
# 获取仓库名称,使用 CSS 选择器选择 h2 标签下的 a 标签,并提取其文本内容
repo_info['url'] = article.select_one('h2 a')['href'].strip()
# 获取仓库 URL,使用 CSS 选择器选择 h2 标签下的 a 标签,并提取其 href 属性值
# Description
description_element = article.select_one('p')
# 使用 CSS 选择器选择 p 标签
repo_info['description'] = description_element.text.strip() if description_element else None
# 获取仓库描述,如果存在 p 标签,则提取其文本内容,否则为 None
# Language
language_element = article.select_one('span[itemprop="programmingLanguage"]')
# 使用 CSS 选择器选择 itemprop 属性为 programmingLanguage 的 span 标签
repo_info['language'] = language_element.text.strip() if language_element else None
# 获取仓库语言,如果存在该标签,则提取其文本内容,否则为 None
# Stars and Forks
stars_element = article.select('a.Link--muted')[0]
# 使用 CSS 选择器选择类名为 Link--muted 的 a 标签,并选择第一个元素
forks_element = article.select('a.Link--muted')[1]
# 使用 CSS 选择器选择类名为 Link--muted 的 a 标签,并选择第二个元素
repo_info['stars'] = stars_element.text.strip()
# 获取仓库星标数,提取第一个元素的文本内容
repo_info['forks'] = forks_element.text.strip()
# 获取仓库分支数,提取第二个元素的文本内容
# week's Stars
today_stars_element = article.select_one('span.d-inline-block.float-sm-right')
# 使用 CSS 选择器选择类名为 d-inline-block 和 float-sm-right 的 span 标签
repo_info['week_stars'] = today_stars_element.text.strip() if today_stars_element else None
# 获取本周星标数,如果存在该标签,则提取其文本内容,否则为 None
repositories.append(repo_info)
# 将仓库信息添加到列表中
return repositories
# 返回解析后的仓库信息列表
async def main():
url = "https://github.com/trending/python?since=weekly"
html = await fetch_html(url)
repos = await parse_github_trending(html)
# 格式化输出仓库信息
format_str = "{:<5} {:<50} {:<10} {:<10} {:<10} {}"
print(format_str.format("Rank", "Name", "Language", "Stars", "Forks", "Description"))
for i, repo in enumerate(repos, start=1):
print(format_str.format(i, repo["name"], repo["language"], repo["stars"], repo["forks"],repo["description"]))
if __name__ == "__main__":
asyncio.run(main())
运行python文件,输出如下:

⑤ readme文件读取
按照本次学习,我们爬取到页面数据即可,但是对于一个真正的``Github用户,我们想要知道的是该仓库的**技术栈,**其**解决了哪些任务?核心思想是什么?以及如何部署和贡献**;而这些信息基本都被保存在readme.md文件中,因此作者在这里补充一个获取readme`文件的代码;
相关配置
1.获取token:进入到Personal Access Tokens (Classic) (github.com)页面,然后生成你的Token,需要进行相关配置

2.安装
pyGithub仓库pip install PyGithub代码实现
import aiohttp # 导入 aiohttp 库,用于发送异步 HTTP 请求
import asyncio # 导入 asyncio 库,用于处理异步任务
from bs4 import BeautifulSoup # 导入 BeautifulSoup 库,用于解析 HTML 文档
from github import Github
import os
from dotenv import load_dotenv
load_dotenv() # 加载我们配置在.env文件中的环境变量
async def fetch_html(url):
# 定义一个异步函数 fetch_html,用于获取 URL 对应的 HTML 内容
async with aiohttp.ClientSession() as session:
# 使用 aiohttp 创建一个会话上下文管理器
async with session.get(url) as response:
# 使用会话对象发送 GET 请求,并在响应对象上使用上下文管理器
return await response.text()
# 返回响应内容的文本格式
async def parse_github_trending(html):
# 定义一个异步函数 parse_github_trending,用于解析 GitHub Trending 页面的 HTML 内容
soup = BeautifulSoup(html, 'html.parser')
# 使用 BeautifulSoup 解析 HTML 内容,生成一个 BeautifulSoup 对象
repositories = []
# 创建一个空列表,用于存储解析后的仓库信息
g = Github(os.getenv("GITHUB_ACCESS_TOKEN"))
# g = Github("your_access_token")
# 使用您的 GitHub 访问令牌创建一个 Github 对象
for article in soup.select('article.Box-row'):
# 使用 CSS 选择器选择所有类名为 Box-row 的 article 标签
repo_info = {}
# 创建一个空字典,用于存储单个仓库的信息
repo_info['name'] = article.select_one('h2 a').text.strip().replace('\n', '').replace(' ', '')
# 获取仓库名称,使用 CSS 选择器选择 h2 标签下的 a 标签,并提取其文本内容
print(repo_info['name'])
repo_info['url'] = "https://github.com"+article.select_one('h2 a')['href'].strip()
# 获取仓库 URL,使用 CSS 选择器选择 h2 标签下的 a 标签,并提取其 href 属性值,并拼接成完整的 GitHub 仓库链接
# 获取 README.md 文件
try:
# 尝试获取仓库的 README.md 文件
repo = g.get_repo(repo_info['name'])
contents = repo.get_contents("README.md", ref="main")
repo_info['readme'] = contents.decoded_content.decode()
print(repo_info['readme'])
except Exception as e:
# 如果仓库没有 README.md 文件或发生其他错误,则打印错误信息并跳过该仓库
print(f"Error getting README.md file for {repo_info['name'] }: {e}")
continue
# Description
description_element = article.select_one('p')
# 使用 CSS 选择器选择 p 标签
repo_info['description'] = description_element.text.strip() if description_element else None
# 获取仓库描述,如果存在 p 标签,则提取其文本内容,否则为 None
# Language
language_element = article.select_one('span[itemprop="programmingLanguage"]')
# 使用 CSS 选择器选择 itemprop 属性为 programmingLanguage 的 span 标签
repo_info['language'] = language_element.text.strip() if language_element else None
# 获取仓库语言,如果存在该标签,则提取其文本内容,否则为 None
# Stars and Forks
stars_element = article.select('a.Link--muted')[0]
# 使用 CSS 选择器选择类名为 Link--muted 的 a 标签,并选择第一个元素
forks_element = article.select('a.Link--muted')[1]
# 使用 CSS 选择器选择类名为 Link--muted 的 a 标签,并选择第二个元素
repo_info['stars'] = stars_element.text.strip()
# 获取仓库星标数,提取第一个元素的文本内容
repo_info['forks'] = forks_element.text.strip()
# 获取仓库分支数,提取第二个元素的文本内容
# week's Stars
today_stars_element = article.select_one('span.d-inline-block.float-sm-right')
# 使用 CSS 选择器选择类名为 d-inline-block 和 float-sm-right 的 span 标签
repo_info['week_stars'] = today_stars_element.text.strip() if today_stars_element else None
# 获取本周星标数,如果存在该标签,则提取其文本内容,否则为 None
repositories.append(repo_info)
# 将仓库信息添加到列表中
return repositories
# 返回解析后的仓库信息列表
async def main():
url = "https://github.com/trending/python?since=weekly"
html = await fetch_html(url)
repos = await parse_github_trending(html)
# 格式化输出仓库信息
format_str = "{:<5} {:<50} {:<10} {:<10} {:<10} {}"
print(format_str.format("Rank", "Name", "Language", "Stars", "Forks", "Description"))
for i, repo in enumerate(repos, start=1):
print(format_str.format(i, repo["name"], repo["language"], repo["stars"], repo["forks"], repo["description"]))
if __name__ == "__main__":
asyncio.run(main())
运行结果如下:

可以看到,我们已经成功获得了目标页面readme的数据,
现在,我们再稍微对其进行完善修改,将其修改为一个crawlAction类,以便我们的Agent使用,代码如下:
import aiohttp
from bs4 import BeautifulSoup
import asyncio # 导入 asyncio 库,用于处理异步任务
from github import Github
from metagpt.actions.action import Action
from metagpt.config import CONFIG
# 定义一个爬虫动作类,继承自Action类
class CrawlAction(Action):
async def run(self, url: str = "https://github.com/trending/python?since=weekly"):
# 定义一个异步方法run,用于执行爬虫动作
# URL默认为GitHub上按星标排名的Python项目周榜单
async with aiohttp.ClientSession() as client:
# 使用aiohttp创建一个会话对象client
async with client.get(url) as response:
# 使用client对象发送GET请求,并使用代理配置
response.raise_for_status()
# 如果响应状态码不是200,则raise_for_status()会抛出HTTPError异常
html = await response.text()
# 获取响应的HTML文本
soup = BeautifulSoup(html, 'html.parser')
# 使用BeautifulSoup解析HTML文本,生成一个BeautifulSoup对象
repositories = []
# 创建一个空列表,用于存储爬取到的仓库信息
g = Github(os.getenv("GITHUB_ACCESS_TOKEN"))
# 使用您的 GitHub 访问令牌创建一个 Github 对象
for article in soup.select('article.Box-row'):
# 使用 CSS 选择器选择所有类名为 Box-row 的 article 标签
repo_info = {}
# 创建一个空字典,用于存储单个仓库的信息
repo_info['name'] = article.select_one('h2 a').text.strip().replace('\n', '').replace(' ', '')
# 获取仓库名称,使用 CSS 选择器选择 h2 标签下的 a 标签,并提取其文本内容
print(repo_info['name'])
repo_info['url'] = "https://github.com"+article.select_one('h2 a')['href'].strip()
# 获取仓库 URL,使用 CSS 选择器选择 h2 标签下的 a 标签,并提取其 href 属性值,并拼接成完整的 GitHub 仓库链接
# 获取 README.md 文件
try:
# 尝试获取仓库的 README.md 文件
repo = g.get_repo(repo_info['name'])
contents = repo.get_contents("README.md", ref="main")
repo_info['readme'] = contents.decoded_content.decode()
print(repo_info['readme'])
except Exception as e:
# 如果仓库没有 README.md 文件或发生其他错误,则打印错误信息并跳过该仓库
print(f"Error getting README.md file for {repo_info['name'] }: {e}")
repo_info['readme'] = None
continue
# Description
description_element = article.select_one('p')
repo_info['description'] = description_element.text.strip() if description_element else None
# 获取仓库描述信息,如果不存在则设置为None
# Language
language_element = article.select_one('span[itemprop="programmingLanguage"]')
repo_info['language'] = language_element.text.strip() if language_element else None
# 获取仓库使用的编程语言,如果不存在则设置为None
# Stars and Forks
stars_element = article.select('a.Link--muted')[0]
forks_element = article.select('a.Link--muted')[1]
repo_info['stars'] = stars_element.text.strip()
repo_info['forks'] = forks_element.text.strip()
# 获取仓库的星标数和分支数
# week's Stars
today_stars_element = article.select_one('span.d-inline-block.float-sm-right')
repo_info['week_stars'] = today_stars_element.text.strip() if today_stars_element else None
# 获取仓库在本周新增的星标数,如果不存在则设置为None
if repo_info.get("readme") != None:
repositories.append(repo_info)
# 将仓库信息添加到列表中
return json.dumps(repositories)# 使用json.dumps将字典转换为JSON字符串,并存储到字符串中 返回爬取到的仓库信息列表
至此,Crawl Action成功实现,相比于原项目,我们这里返回的是每个仓库信息的列表!
作者开发的时候发现
metagpt似乎会将action链中每个action的返回转为字符串格式,例如上述repositories是列表,到导致下一步处理困难,因此我这里提前打包为字符串,再下一步中解析,可以避免这个问题;
(2)AnalysisOSSRepository Action实现
当我们获取到Github订阅页面的数据后,我们可以让LLM将我们上文中爬取的页面数据和对应仓库的readme信息进行分析了;
这个Action实现起来比较简单,之前的文章中,我们都已经撰写过类似的Action,因此我们这里说一说思路后直接给出完整代码,我们的思路是:
对单个仓库信息为元素,遍历整个仓库列表,每个仓库我们要将我们仓库的信息列为
prompt模版字符串;设定LLM的处理逻辑和输出格式,如关注重点与输出markdown格式;
从LLM的输出中提取出改仓库的名称,链接,作用,技术栈,实现思路,部署方式。相关链接等这些信息
完整代码如下:
from typing import Any from metagpt.actions.action import Action # Actions 的实现 class AnalysisOSSRepository(Action): def prompt_format(self,repo_info): question = """# 需求 您是一名 GitHub 仓库分析师,旨在为用户提供有见地的、个性化的仓库分析。根据上下文,填写以下缺失的信息,生成吸引人并有信息量的标题,确保用户发现与其兴趣相符的仓库。 关于仓库的标题 仓库分析:深入探索 xxx项目的特点和优势!基于基本内容,如网页链接,了解其背后的作用,技术栈,实现思路,部署方式等信息。 --- 格式示例项目名称
项目地址
xxx
仓库介绍
xxx 是一个用于 xxx 的开源项目。它使用 xxx 技术栈实现,采用 xxx 的实现思路。
特点和优势
- 特点1
- 特点2
部署和使用
可以通过 <部署方式,如Docker,本地部署,云服务器> 的方式部署和使用该项目。详细信息可以参考以下链接:
- 执行代码:
pip install …
--- 当前已有信息如下: 项目名称:{repository_name} 项目地址:{repository_URL} 项目Star:{repository_star} 项目Fork:{repository_fork} 项目语言:{repository_language} 项目readme:{repository_readme} """.format(repository_name=repo_info["name"], repository_URL=repo_info["url"], repository_star=repo_info["stars"], repository_fork=repo_info["forks"], repository_language=repo_info["language"], repository_readme=repo_info["readme"]) return question async def run(self, repo_info_list: Any): repo_summary_list = [] for repo_info in json.loads(repo_info_list): repository_info = self.prompt_format(repo_info) summary = await self._aask(repository_info) repo_summary_list.append(summary) return repo_summary_list提示词工程在这里很重要
(3)OSSWatchAgent实现
我们已经实现了两个主要的Action,我现在我只需要设计好我们的OSS订阅Agent即可,代码如下:
import asyncio import os from typing import Any, AsyncGenerator, Awaitable, Callable, Dict, Optional, List from github import Github import aiohttp import discord from aiocron import crontab from bs4 import BeautifulSoup from pydantic import BaseModel, Field from pytz import BaseTzInfo import json from metagpt.actions.action import Action from metagpt.logs import logger from metagpt.roles import Role from metagpt.schema import Message # 修复 SubscriptionRunner 未完全定义的问题 from metagpt.environment import Environment as _ # noqa: F401 from dotenv import load_dotenv load_dotenv() # 加载我们配置在.env文件中的环境变量 # 定义一个爬虫动作类,继承自Action类 class CrawlAction(Action): async def run(self, url: str = "https://github.com/trending/python?since=weekly"): # 定义一个异步方法run,用于执行爬虫动作 # URL默认为GitHub上按星标排名的Python项目周榜单 async with aiohttp.ClientSession() as client: # 使用aiohttp创建一个会话对象client async with client.get(url) as response: # 使用client对象发送GET请求,并使用代理配置 response.raise_for_status() # 如果响应状态码不是200,则raise_for_status()会抛出HTTPError异常 html = await response.text() # 获取响应的HTML文本 soup = BeautifulSoup(html, 'html.parser') # 使用BeautifulSoup解析HTML文本,生成一个BeautifulSoup对象 repositories = [] # 创建一个空列表,用于存储爬取到的仓库信息 g = Github(os.getenv("GITHUB_ACCESS_TOKEN")) # 使用您的 GitHub 访问令牌创建一个 Github 对象 for article in soup.select('article.Box-row'): # 使用 CSS 选择器选择所有类名为 Box-row 的 article 标签 repo_info = {} # 创建一个空字典,用于存储单个仓库的信息 repo_info['name'] = article.select_one('h2 a').text.strip().replace('\n', '').replace(' ', '') # 获取仓库名称,使用 CSS 选择器选择 h2 标签下的 a 标签,并提取其文本内容 print(repo_info['name']) repo_info['url'] = "https://github.com"+article.select_one('h2 a')['href'].strip() # 获取仓库 URL,使用 CSS 选择器选择 h2 标签下的 a 标签,并提取其 href 属性值,并拼接成完整的 GitHub 仓库链接 # 获取 README.md 文件 try: # 尝试获取仓库的 README.md 文件 repo = g.get_repo(repo_info['name']) contents = repo.get_contents("README.md", ref="main") repo_info['readme'] = contents.decoded_content.decode() print(repo_info['readme']) except Exception as e: # 如果仓库没有 README.md 文件或发生其他错误,则打印错误信息并跳过该仓库 print(f"Error getting README.md file for {repo_info['name'] }: {e}") repo_info['readme'] = None continue # Description description_element = article.select_one('p') repo_info['description'] = description_element.text.strip() if description_element else None # 获取仓库描述信息,如果不存在则设置为None # Language language_element = article.select_one('span[itemprop="programmingLanguage"]') repo_info['language'] = language_element.text.strip() if language_element else None # 获取仓库使用的编程语言,如果不存在则设置为None # Stars and Forks stars_element = article.select('a.Link--muted')[0] forks_element = article.select('a.Link--muted')[1] repo_info['stars'] = stars_element.text.strip() repo_info['forks'] = forks_element.text.strip() # 获取仓库的星标数和分支数 # week's Stars today_stars_element = article.select_one('span.d-inline-block.float-sm-right') repo_info['week_stars'] = today_stars_element.text.strip() if today_stars_element else None # 获取仓库在本周新增的星标数,如果不存在则设置为None if repo_info.get("readme") != None: repositories.append(repo_info) # 将仓库信息添加到列表中 return json.dumps(repositories)# 使用json.dumps将字典转换为JSON字符串,并存储到字符串中 返回爬取到的仓库信息列表 # Actions 的实现 class AnalysisOSSRepository(Action): def prompt_format(self,repo_info): question = """# 需求 您是一名 GitHub 仓库分析师,旨在为用户提供有见地的、个性化的仓库分析。根据上下文,填写以下缺失的信息,生成吸引人并有信息量的标题,确保用户发现与其兴趣相符的仓库。 关于仓库的标题 仓库分析:深入探索 xxx项目的特点和优势!基于基本内容,如网页链接,了解其背后的作用,技术栈,实现思路,部署方式等信息。 --- 格式示例项目名称
项目地址
xxx
仓库介绍
xxx 是一个用于 xxx 的开源项目。它使用 xxx 技术栈实现,采用 xxx 的实现思路。
特点和优势
- 特点1
- 特点2
部署和使用
可以通过 <部署方式,如Docker,本地部署,云服务器> 的方式部署和使用该项目。详细信息可以参考以下链接:
- 执行代码:
pip install …
--- 当前已有信息如下: 项目名称:{repository_name} 项目地址:{repository_URL} 项目Star:{repository_star} 项目Fork:{repository_fork} 项目语言:{repository_language} 项目readme:{repository_readme} """.format(repository_name=repo_info["name"], repository_URL=repo_info["url"], repository_star=repo_info["stars"], repository_fork=repo_info["forks"], repository_language=repo_info["language"], repository_readme=repo_info["readme"]) return question async def run(self, repo_info_list: Any): repo_summary_list = [] for repo_info in json.loads(repo_info_list): repository_info = self.prompt_format(repo_info) summary = await self._aask(repository_info) repo_summary_list.append(summary) return repo_summary_list # 角色设计 class OssWatcher(Role): def __init__(self): super().__init__( name="cheems", profile="OssWatcher", goal="根据我提供给你的资料生成一个有见地的 GitHub 仓库 分析报告。", constraints="仅基于提供的 GitHub 仓库 数据进行分析。", ) self.set_actions([CrawlAction(), AnalysisOSSRepository()]) self._set_react_mode(react_mode="by_order") async def _act(self) -> Message: logger.info(f"{self._setting}: ready to {self.rc.todo}") todo = self.rc.todo msg = self.get_memories(k=1)[0] result = await todo.run(msg.content) new_msg = Message(content=str(result), role=self.profile, cause_by=type(todo)) self.rc.memory.add(new_msg) return result这里作者并没有将
CrawlAction返回的是列表,不是字符串,因此我们循环遍历的所有仓库,因此执行完任务后我们不返回字符串信息,而是返回列表给回调函数callback;
(4)定时触发器(Trigger)的实现
这里主要有两种实现方法:
①使用 asyncio.sleep 实现简单的定时功能
import asyncio
import time
from datetime import datetime, timedelta
from metagpt.schema import Message
from pydantic import BaseModel, Field
# 定义一个包含URL和时间戳的基础信息模型
class OssInfo(BaseModel):
url: str
timestamp: float = Field(default_factory=time.time)
# 定义一个异步函数,用于定时生成消息
async def oss_trigger(hour: int, minute: int, second: int = 0, url: str = "https://github.com/trending"):
while True:
now = datetime.now()
next_time = datetime(now.year, now.month, now.day, hour, minute, second)
if next_time < now:
next_time += timedelta(days=1)
wait_seconds = (next_time - now).total_seconds()
print(f"等待时间:{wait_seconds}秒")
await asyncio.sleep(wait_seconds)
yield Message(url, OssInfo(url=url))
在这个例子中,我们使用了 asyncio.sleep 来实现定时功能。yield 语句用于在指定时间生成消息。通过添加时间戳,我们确保每次生成的消息都是唯一的,从而避免了消息去重的问题。
②使用 aiocron 实现更灵活的定时功能
import time
from aiocron import crontab
from typing import Optional
from pytz import BaseTzInfo
from pydantic import BaseModel, Field
from metagpt.schema import Message
# 定义一个基于aiocron的定时触发器类
class GithubTrendingCronTrigger:
def __init__(self, spec: str, tz: Optional[BaseTzInfo] = None, url: str = "https://github.com/trending"):
self.crontab = crontab(spec, tz=tz) # 使用cron表达式和时区初始化crontab
self.url = url
def __aiter__(self):
return self
async def __anext__(self):
await self.crontab.next() # 等待下一个触发时刻
return Message(content=self.url) # 生成消息
# 使用UTC时间10:00 AM作为触发时间
cron_trigger = GithubTrendingCronTrigger("0 10 * * *")
aiocron 提供了一个强大的定时功能,可以使用 cron 语法灵活地配置定时规则。这使得代码更简洁,功能更全面。
第二种方法更加灵活,因此我们这里选择第二种方法,完整代码如下:
from pytz import timezone
from aiocron import crontab
from typing import Optional
from pytz import BaseTzInfo
from pydantic import BaseModel, Field
from metagpt.schema import Message
# 定义一个基于aiocron的定时触发器类
class GithubTrendingCronTrigger:
def __init__(self, spec: str, tz: Optional[BaseTzInfo] = None, url: str = "https://github.com/trending"):
self.crontab = crontab(spec, tz=tz) # 使用cron表达式和时区初始化crontab
self.url = url
def __aiter__(self):
return self
async def __anext__(self):
await self.crontab.next() # 等待下一个触发时刻
return Message(content=self.url) # 生成消息
# 获取北京时间的时区
beijing_tz = timezone('Asia/Shanghai')
# 创建定时触发器实例,每天北京时间上午9:00触发
cron_trigger = GithubTrendingCronTrigger("0 9 * * *", tz=beijing_tz)
在这个例子中,我们设置了北京时间上午9:00作为触发时间;
(5)Callback设计
callback也就是回调函数,当我们爬取到数据并且处理得到结果后,我们该怎么做呢,我们应该从应用角度出发,我们是为了订阅信息,那么我们就需要一个平台来发布这些信息;下面我们以Discord为例,实现Agent自动发布订阅信息;
①Discord配置

Discord[[Discord | 玩耍聊天的地方] 是一个免费的语音和文本聊天平台,专门为游戏玩家和社区设计,但现在已经发展成为一个更广泛的社区平台。Discord 支持实时语音和视频通话、屏幕分享、文本消息、图片和视频分享等功能。用户可以创建自己的服务器,或者加入其他人创建的服务器,与其他用户进行交流和讨论。很多开源项目都在Discord上有自己的社区,其具有以下特点:
- 高质量的语音和视频通话
- 强大的社区管理工具:角色授权、频道分类、_自动化机器人_等
- 丰富的扩展和插件
- 跨平台支持
因此,我们选择在该平台上构建一个自动化机器人,后端接受我们的Agent服务,然后通过调用Discord的API服务来实现信息订阅:
注意:注册登录Discord并使用本服务需要用户具有科学网络环境,如果没有则可以直接跳过,进入到下一节,考虑邮箱订阅实现;
②构架机器人
下面作者订阅的完整流程,参考文章:[创建机器人帐户

进入到页面后,配置应用的基本信息:


接着,按照如上内容进行配置:注意你的token不要和他人分享,如果不小心泄漏或者没有配置Token,应该在此界面点击reset Token重新设置;现在,我们就有了一个机器人帐户,可以使用该令牌token登录。

接下来邀请机器人到个人服务器:
进入到OAuth界面,勾选Bot,也就是当前Token选择的服务(其他不要勾选);

并且选择该机器人拥有的权限:

现在,这里生成的 URL 可用于将机器人添加到服务器。将复制的 URL 复制并粘贴到浏览器中,选择要邀请机器人访问的服务器,然后单击“授权”。


可以看到,我们的机器人已经被邀请进入我们的服务器;
开始撰写代码:
import asyncio
import discord
# 基于discord机器人发布信息函数
async def send_discord_msg(channel_id: int, msg: str, token: str):
intents = discord.Intents.default()
intents.message_content = True
client = discord.Client(intents=intents)
async with client:
await client.login(token)
channel = await client.fetch_channel(channel_id)
await channel.send(msg)
因为discord有单条信息的大小限制,过长的内容会导致发送不成功,并且Agent给我们返回的是一个仓库总结列表,因此我们可以遍历该列表,作为多条msg发送,最终实现的discord_callback函数如下:
import asyncio
import discord
from metagpt.config import CONFIG
async def discord_callback(msg_list:List):
intents = discord.Intents.default()
intents.message_content = True
client = discord.Client(intents=intents, proxy=CONFIG.global_proxy)
token = os.environ["DISCORD_TOKEN"]
channel_id = int(os.environ["DISCORD_CHANNEL_ID"])
async with client:
await client.login(token)
channel = await client.fetch_channel(channel_id)
for repo in msg_list:
lines = []
for i in repo.splitlines():
if i.startswith(("# ", "## ", "### ")):
if lines:
await channel.send("\n".join(lines))
lines = []
lines.append(i)
if lines:
await channel.send("\n".join(lines))
DISCORD_TOKEN:我们上面截图中有,就是我们之前复制的
reset tokenDISCORD_CHANNEL_ID:进入到我们选择的服务器后搜索栏URL最有一部分,如下图所示框选部分

这里我们再次回顾我们的完整步骤:
- 初始化和配置:确保依赖库已安装并正确配置。
- 爬虫动作:爬取
GitHub Trending数据。 - 分析动作:对爬取的数据进行分析,然后生成总结报告。
- 自动化定时任务:设置定时任务,每天定时执行爬虫和分析动作。
- 循环处理:确保对每个爬取的仓库进行处理,并生成报告。
现在我们将所有阶段的代码打包起来,得到一个完整的代码文件,这里因为测试需要,我们将时间每分钟运行一次,运行前可以先安装相关库:
pip install asyncio aiohttp discord aiocron beautifulsoup4 pydantic pytz PyGithub fire metagpt
完整运行代码如下:
import asyncio
import os
from typing import Any, AsyncGenerator, Awaitable, Callable, Dict, Optional, List
from github import Github
import aiohttp
import discord
from aiocron import crontab
from bs4 import BeautifulSoup
from pydantic import BaseModel, Field
from pytz import BaseTzInfo
import json
from metagpt.actions.action import Action
from metagpt.logs import logger
from metagpt.roles import Role
from metagpt.schema import Message
# 修复 SubscriptionRunner 未完全定义的问题
from metagpt.environment import Environment as _ # noqa: F401
from dotenv import load_dotenv
load_dotenv() # 加载我们配置在.env文件中的环境变量
# 订阅模块
class SubscriptionRunner(BaseModel):
tasks: Dict[Role, asyncio.Task] = Field(default_factory=dict)
class Config:
arbitrary_types_allowed = True
async def subscribe(
self,
role: Role,
trigger: AsyncGenerator[Message, None],
callback: Callable[[Message], Awaitable[None]],
):
# 异步订阅方法
loop = asyncio.get_running_loop()
async def _start_role():
async for msg in trigger:
resp = await role.run(msg)
await callback(resp)
self.tasks[role] = loop.create_task(_start_role(), name=f"Subscription-{role}")
async def unsubscribe(self, role: Role):
"""取消订阅角色并取消关联的任务"""
task = self.tasks.pop(role)
task.cancel()
async def run(self, raise_exception: bool = True):
while True:
for role, task in self.tasks.items():
if task.done():
if task.exception():
if raise_exception:
raise task.exception()
logger.opt(exception=task.exception()).error(
f"Task {task.get_name()} run error"
)
else:
logger.warning(
f"Task {task.get_name()} has completed. "
"If this is unexpected behavior, please check the trigger function."
)
self.tasks.pop(role)
break
else:
await asyncio.sleep(1)
# 定义一个爬虫动作类,继承自Action类
class CrawlAction(Action):
async def run(self, url: str = "https://github.com/trending/python?since=weekly"):
# 定义一个异步方法run,用于执行爬虫动作
# URL默认为GitHub上按星标排名的Python项目周榜单
async with aiohttp.ClientSession() as client:
# 使用aiohttp创建一个会话对象client
async with client.get(url) as response:
# 使用client对象发送GET请求,并使用代理配置
response.raise_for_status()
# 如果响应状态码不是200,则raise_for_status()会抛出HTTPError异常
html = await response.text()
# 获取响应的HTML文本
soup = BeautifulSoup(html, 'html.parser')
# 使用BeautifulSoup解析HTML文本,生成一个BeautifulSoup对象
repositories = []
# 创建一个空列表,用于存储爬取到的仓库信息
g = Github(os.getenv("GITHUB_ACCESS_TOKEN"))
# 使用您的 GitHub 访问令牌创建一个 Github 对象
for article in soup.select('article.Box-row'):
# 使用 CSS 选择器选择所有类名为 Box-row 的 article 标签
repo_info = {}
# 创建一个空字典,用于存储单个仓库的信息
repo_info['name'] = article.select_one('h2 a').text.strip().replace('\n', '').replace(' ', '')
# 获取仓库名称,使用 CSS 选择器选择 h2 标签下的 a 标签,并提取其文本内容
repo_info['url'] = "https://github.com"+article.select_one('h2 a')['href'].strip()
# 获取仓库 URL,使用 CSS 选择器选择 h2 标签下的 a 标签,并提取其 href 属性值,并拼接成完整的 GitHub 仓库链接
# 获取 README.md 文件
try:
# 尝试获取仓库的 README.md 文件
repo = g.get_repo(repo_info['name'])
contents = repo.get_contents("README.md", ref="main")
repo_info['readme'] = contents.decoded_content.decode()
except Exception as e:
# 如果仓库没有 README.md 文件或发生其他错误,则打印错误信息并跳过该仓库
print(f"Error getting README.md file for {repo_info['name'] }: {e}")
repo_info['readme'] = None
continue
# Description
description_element = article.select_one('p')
repo_info['description'] = description_element.text.strip() if description_element else None
# 获取仓库描述信息,如果不存在则设置为None
# Language
language_element = article.select_one('span[itemprop="programmingLanguage"]')
repo_info['language'] = language_element.text.strip() if language_element else None
# 获取仓库使用的编程语言,如果不存在则设置为None
# Stars and Forks
stars_element = article.select('a.Link--muted')[0]
forks_element = article.select('a.Link--muted')[1]
repo_info['stars'] = stars_element.text.strip()
repo_info['forks'] = forks_element.text.strip()
# 获取仓库的星标数和分支数
# week's Stars
today_stars_element = article.select_one('span.d-inline-block.float-sm-right')
repo_info['week_stars'] = today_stars_element.text.strip() if today_stars_element else None
# 获取仓库在本周新增的星标数,如果不存在则设置为None
if repo_info.get("readme") != None:
repositories.append(repo_info)
# 将仓库信息添加到列表中
return json.dumps(repositories[:2])# 使用json.dumps将字典转换为JSON字符串,并存储到字符串中 返回爬取到的仓库信息列表
# Actions 的实现
class AnalysisOSSRepository(Action):
def prompt_format(self,repo_info):
question = """# 需求
您是一名 GitHub 仓库分析师,旨在为用户提供有见地的、个性化的仓库分析。根据上下文,填写以下缺失的信息,生成吸引人并有信息量的标题,确保用户发现与其兴趣相符的仓库。
关于仓库的标题
仓库分析:深入探索 xxx项目的特点和优势!基于基本内容,如网页链接,了解其背后的作用,技术栈,实现思路,部署方式等信息。
---
格式示例
项目名称
项目地址
xxx
仓库介绍
xxx 是一个用于 xxx 的开源项目。它使用 xxx 技术栈实现,采用 xxx 的实现思路。
特点和优势
- 特点1
- 特点2
部署和使用
可以通过 <部署方式,如Docker,本地部署,云服务器> 的方式部署和使用该项目。详细信息可以参考以下链接:
- 执行代码:
pip install …
---
当前已有信息如下:
项目名称:{repository_name}
项目地址:{repository_URL}
项目Star:{repository_star}
项目Fork:{repository_fork}
项目语言:{repository_language}
项目readme:{repository_readme}
""".format(repository_name=repo_info["name"], repository_URL=repo_info["url"], repository_star=repo_info["stars"], repository_fork=repo_info["forks"], repository_language=repo_info["language"], repository_readme=repo_info["readme"])
return question
async def run(self, repo_info_list: Any):
repo_summary_list = []
for repo_info in json.loads(repo_info_list):
repository_info = self.prompt_format(repo_info)
summary = await self._aask(repository_info)
repo_summary_list.append(summary)
return repo_summary_list
# 角色设计
class OssWatcher(Role):
def __init__(self):
super().__init__(
name="cheems",
profile="OssWatcher",
goal="根据我提供给你的资料生成一个有见地的 GitHub 仓库 分析报告。",
constraints="仅基于提供的 GitHub 仓库 数据进行分析。",
)
self.set_actions([CrawlAction(), AnalysisOSSRepository()])
self._set_react_mode(react_mode="by_order")
async def _act(self) -> Message:
logger.info(f"{self._setting}: ready to {self.rc.todo}")
todo = self.rc.todo
msg = self.get_memories(k=1)[0]
result = await todo.run(msg.content)
new_msg = Message(content=str(result), role=self.profile, cause_by=type(todo))
self.rc.memory.add(new_msg)
return result
# 定义一个基于aiocron的定时触发器类
class GithubTrendingCronTrigger:
def __init__(self, spec: str, tz: Optional[BaseTzInfo] = None, url: str = "https://github.com/trending/python?since=weekly") -> None:
self.crontab = crontab(spec, tz=tz)
self.url = url
def __aiter__(self):
return self
async def __anext__(self):
await self.crontab.next()
return Message(content=self.url)
# discord 回调
async def discord_callback(msg_list: List):
intents = discord.Intents.default()
intents.message_content = True
# client = discord.Client(intents=intents, proxy= os.getenv("GLOBAL_PROXYGLOBAL_PROXY")) # 需要代理
client = discord.Client(intents=intents) # 无需代理
token = os.getenv("DISCORD_TOKEN")
channel_id = int(os.getenv("DISCORD_CHANNEL_ID"))
async with client:
await client.login(token)
channel = await client.fetch_channel(channel_id)
for repo in msg_list:
lines = []
for line in repo.splitlines():
if line.startswith(("# ", "## ", "### ")):
if lines:
await channel.send("\n".join(lines))
lines = []
lines.append(line)
if lines:
await channel.send("\n".join(lines))
# 运行入口
async def main(spec: str = "* * * * *", discord: bool = True, wxpusher: bool = True):
callbacks = []
if discord:
callbacks.append(discord_callback)
if not callbacks:
async def _print(msg: Message):
print(msg.content)
callbacks.append(_print)
async def callback(msg):
await asyncio.gather(*(call(msg) for call in callbacks))
runner = SubscriptionRunner()
await runner.subscribe(OssWatcher(), GithubTrendingCronTrigger(spec), callback) # 正式版本
await runner.run()
if __name__ == "__main__":
import fire
fire.Fire(main) # 使用 fire 库将 main 函数转换为命令行接口的入口点
当前程序运行后,每分钟会将爬虫处理的信息发送到Discord,如果需要测试,将**main函数中的spec值修改为"* * * * ",则会每分钟执行一次*
运行该函数,代码效果如下:

🎉🎉🎉🎉,费劲千辛万苦,我们终于实现了Discord订阅功能;🫡🫡给作者点个免费的赞鼓励一下吧🏆🏆🏆;
3.基于QQ邮箱实现Huggface论文总结订阅Agent
经过这个OSS订阅项目的完整流程,我们学习了MetaGPT订阅模块的使用,也了解了Python爬虫的基本知识,大家可以将这些模块进行任意组合以及自定义,来实现不同的功能,下面在作者爬取Huggface论文页面内容(前5篇),并且总结为文档,并整理发送到我们QQ邮箱的完整代码:完整代码如下:
下面是修改后的完整代码,包含爬取Huggingface Papers页面的Action,修改后的模板内容,以及通过QQ邮箱发送订阅的功能。运行此脚本前,请:
- 确保配置好
.env文件,以下是配置的环境变量内容:
GITHUB_ACCESS_TOKEN=your_github_access_token DISCORD_TOKEN=your_discord_token DISCORD_CHANNEL_ID=your_discord_channel_id QQ_EMAIL_USER=your_qq_email QQ_EMAIL_PASSWORD=your_qq_email_password QQ_EMAIL_TO=recipient_email
- 确保你已经安装了相关的Python包:
pip install aiohttp beautifulsoup4 pydantic python-dotenv discord.py aiocron smtplib fire
修改后的代码如下:
import asyncio
import os
import smtplib
from typing import Any, AsyncGenerator, Awaitable, Callable, Dict, Optional, List
from email.mime.multipart import MIMEMultipart
from email.mime.text import MIMEText
from github import Github
import aiohttp
import discord
from aiocron import crontab
from bs4 import BeautifulSoup
from pydantic import BaseModel, Field
from pytz import BaseTzInfo
import json
from metagpt.actions.action import Action
from metagpt.logs import logger
from metagpt.roles import Role
from metagpt.schema import Message
# 加载环境变量
from dotenv import load_dotenv
load_dotenv()
# 订阅模块
class SubscriptionRunner(BaseModel):
tasks: Dict[Role, asyncio.Task] = Field(default_factory=dict)
class Config:
arbitrary_types_allowed = True
async def subscribe(
self,
role: Role,
trigger: AsyncGenerator[Message, None],
callback: Callable[[Message], Awaitable[None]],
):
loop = asyncio.get_running_loop()
async def _start_role():
async for msg in trigger:
resp = await role.run(msg)
await callback(resp)
self.tasks[role] = loop.create_task(_start_role(), name=f"Subscription-{role}")
async def unsubscribe(self, role: Role):
task = self.tasks.pop(role)
task.cancel()
async def run(self, raise_exception: bool = True):
while True:
for role, task in self.tasks.items():
if task.done():
if task.exception():
if raise_exception:
raise task.exception()
logger.opt(exception=task.exception()).error(
f"Task {task.get_name()} run error"
)
else:
logger.warning(
f"Task {task.get_name()} has completed. "
"If this is unexpected behavior, please check the trigger function."
)
self.tasks.pop(role)
break
else:
await asyncio.sleep(1)
# 定义一个爬虫动作类,继承自Action类
class CrawlAction(Action):
async def run(self, url: str = "https://huggingface.co/papers"):
async with aiohttp.ClientSession() as client:
papers = await self._fetch_papers(url, client)
return json.dumps(papers[:5]) # 获取前5篇Paper信息
async def _fetch_papers(self, url: str, client: aiohttp.ClientSession):
async with client.get(url) as response:
response.raise_for_status()
html = await response.text()
soup = BeautifulSoup(html, 'html.parser')
papers = []
# 只爬取前5页
for article in soup.select('h3 > a[href^="/papers/"]')[:5]:
paper_info = {}
paper_info['title'] = article.text.strip()
print(article.text.strip())
paper_info['url'] = "https://huggingface.co" + article['href'].strip()
paper_html = await self._fetch_paper_detail(paper_info['url'], client)
paper_soup = BeautifulSoup(paper_html, 'html.parser')
paper_info['abstract'] = paper_soup.find("section").get_text(separator=' ', strip=True).strip()
papers.append(paper_info)
return papers
async def _fetch_paper_detail(self, url: str, client: aiohttp.ClientSession) -> str:
async with client.get(url) as response:
response.raise_for_status()
return await response.text()
# Actions 的实现
class AnalysisPaper(Action):
def prompt_format(self, paper_info):
question = """# 需求
您是一名学术论文分析师,旨在为用户提供有见地的、个性化的论文分析。根据上下文,填写以下缺失的信息,生成吸引人并有信息量的标题,确保用户发现与其兴趣相符的论文。
关于论文的标题
论文分析:深入探索 xxx论文的特点和贡献!基于基本内容,如网页链接,了解其背后的研究背景,研究方法,实验结果等信息。
---
格式示例
# 论文标题
## 论文链接
xxx
## 论文摘要
xxx
## 研究背景
xxx
## 研究方法
xxx
## 实验结果
xxx
## 结论
xxx
---
当前已有信息如下:
论文标题:{paper_title}
论文链接:{paper_URL}
论文摘要:{paper_abstract}
""".format(paper_title=paper_info["title"], paper_URL=paper_info["url"], paper_abstract=paper_info["abstract"])
return question
async def run(self, paper_info_list: Any):
paper_summary_list = []
for paper_info in json.loads(paper_info_list):
paper_info_str = self.prompt_format(paper_info)
summary = await self._aask(paper_info_str)
paper_summary_list.append(summary)
return paper_summary_list
# 角色设计
class PaperWatcher(Role):
def __init__(self):
super().__init__(
name="cheems",
profile="PaperWatcher",
goal="根据我提供给你的资料生成一个有见地的学术论文分析报告。",
constraints="仅基于提供的论文数据进行分析。",
)
self.set_actions([CrawlAction(), AnalysisPaper()])
self._set_react_mode(react_mode="by_order")
async def _act(self) -> Message:
logger.info(f"{self._setting}: ready to {self.rc.todo}")
todo = self.rc.todo
msg = self.get_memories(k=1)[0]
result = await todo.run(msg.content)
new_msg = Message(content=str(result), role=self.profile, cause_by=type(todo))
self.rc.memory.add(new_msg)
return result
# 定义一个基于aiocron的定时触发器类
class HuggingfacePapersCronTrigger:
def __init__(self, spec: str, tz: Optional[BaseTzInfo] = None, url: str = "https://huggingface.co/papers") -> None:
self.crontab = crontab(spec, tz=tz)
self.url = url
def __aiter__(self):
return self
async def __anext__(self):
await self.crontab.next()
return Message(content=self.url)
# 邮件回调
async def email_callback(paper_summary_list: List):
gmail_user = os.getenv("QQ_EMAIL_USER")
gmail_password = os.getenv("QQ_EMAIL_PASSWORD")
to = os.getenv("QQ_EMAIL_TO")
subject = "Huggingface Papers Weekly Digest"
body = "\n\n".join(paper_summary_list)
msg = MIMEMultipart()
msg['Subject'] = subject
msg['From'] = gmail_user
msg['To'] = to
msg.attach(MIMEText(body, 'plain'))
server = smtplib.SMTP('smtp.qq.com', 587)
server.starttls()
server.login(gmail_user, gmail_password)
server.send_message(msg)
server.quit()
print("send success!")
# 运行入口
async def main(spec: str = "* * * * *", email: bool = True):
callbacks = []
if email:
callbacks.append(email_callback)
if not callbacks:
async def _print(msg: Message):
print(msg.content)
callbacks.append(_print)
async def callback(msg):
await asyncio.gather(*(call(msg) for call in callbacks))
runner = SubscriptionRunner()
await runner.subscribe(PaperWatcher(), HuggingfacePapersCronTrigger(spec), callback)
await runner.run()
if __name__ == "__main__":
import fire
fire.Fire(main)
下面是作者的设计思路:
- 爬取Action:
CrawlAction类用于爬取Huggingface Papers页面的内容,包括每篇论文的标题和摘要,这里页面分析方式与之前相同。 - 分析Action:
AnalysisPaper类用于格式化爬取的论文信息并生成分析报告。 - 角色设计:
PaperWatcher角色包含了上述两个Action,负责爬取和分析论文。 - 定时触发器:
HuggingfacePapersCronTrigger类用于定时触发爬取任务。 - 邮件回调:
email_callback函数用于通过QQ邮箱发送邮件,包含爬取和分析的结果。
大家可以cmd启动脚本测试:
python main.py
运行效果如下:

如何系统的去学习大模型LLM ?
作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。
但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的 AI大模型资料 包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
😝有需要的小伙伴,可以V扫描下方二维码免费领取🆓

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。


四、AI大模型商业化落地方案

阶段1:AI大模型时代的基础理解
- 目标:了解AI大模型的基本概念、发展历程和核心原理。
- 内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践
- L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
- 目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
- 内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例
- L2.2 Prompt框架
- L2.2.1 什么是Prompt
- L2.2.2 Prompt框架应用现状
- L2.2.3 基于GPTAS的Prompt框架
- L2.2.4 Prompt框架与Thought
- L2.2.5 Prompt框架与提示词
- L2.3 流水线工程
- L2.3.1 流水线工程的概念
- L2.3.2 流水线工程的优点
- L2.3.3 流水线工程的应用
- L2.4 总结与展望
阶段3:AI大模型应用架构实践
- 目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
- 内容:
- L3.1 Agent模型框架
- L3.1.1 Agent模型框架的设计理念
- L3.1.2 Agent模型框架的核心组件
- L3.1.3 Agent模型框架的实现细节
- L3.2 MetaGPT
- L3.2.1 MetaGPT的基本概念
- L3.2.2 MetaGPT的工作原理
- L3.2.3 MetaGPT的应用场景
- L3.3 ChatGLM
- L3.3.1 ChatGLM的特点
- L3.3.2 ChatGLM的开发环境
- L3.3.3 ChatGLM的使用示例
- L3.4 LLAMA
- L3.4.1 LLAMA的特点
- L3.4.2 LLAMA的开发环境
- L3.4.3 LLAMA的使用示例
- L3.5 其他大模型介绍
阶段4:AI大模型私有化部署
- 目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
- 内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
学习计划:
- 阶段1:1-2个月,建立AI大模型的基础知识体系。
- 阶段2:2-3个月,专注于API应用开发能力的提升。
- 阶段3:3-4个月,深入实践AI大模型的应用架构和私有化部署。
- 阶段4:4-5个月,专注于高级模型的应用和部署。
这份完整版的大模型 LLM 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
😝有需要的小伙伴,可以Vx扫描下方二维码免费领取🆓