文章目录
更多相关内容可查看
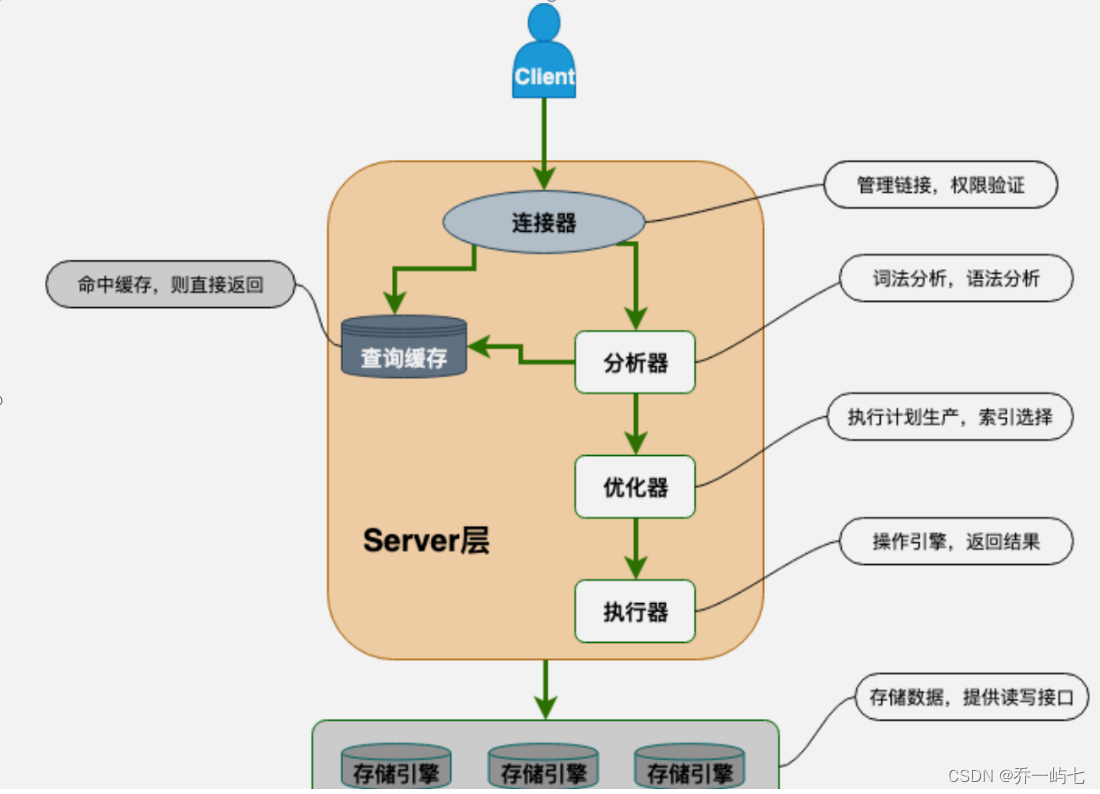
什么是分库分表?
分库分表,是企业里面比较常见的针对高并发、数据量大的场景下的一种技术优化方案,所谓"分库分表",根本就不是一件事儿,而是三件事儿,他们要解决的问题也都不一样。
这三个事儿分别是 “只分库不分表”、“只分表不分库”、以及"既分库又分表”。
分库的原理
分库主要解决的是并发量大的问题。因为并发量一旦上来了,那么数据库就可能会成为瓶颈,因为数据库的连接数是有限的,虽然可以调整,但是也不是无限调整的。所以,当你的数据库的读或者写的QPS过高,导致你的数据库连接数不足了的时候,就需要考虑分库了,通过增加数据库实例的方式来提供更多的可用数据库链接,从而提升系统的并发度。
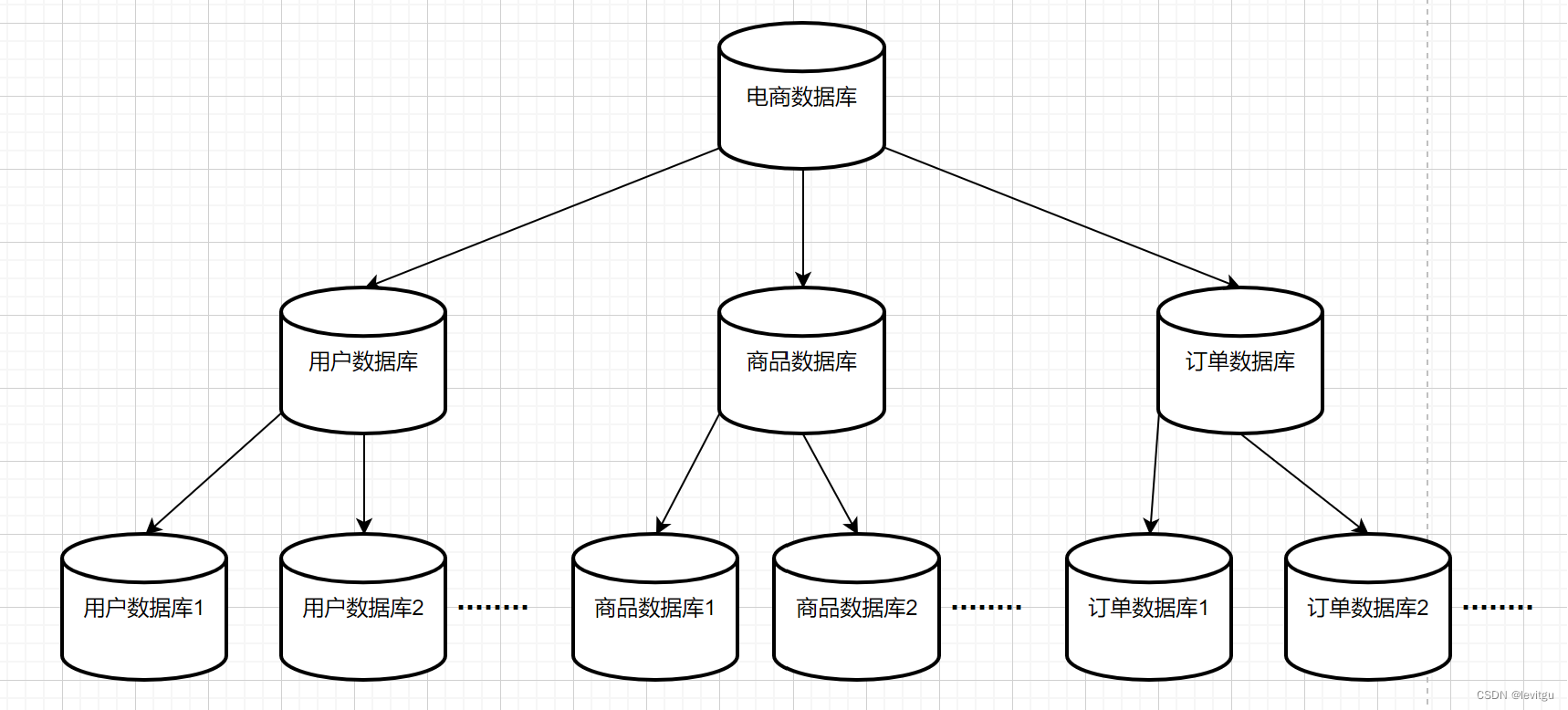
分库主要解决的是并发量大的问题。比较典型的分库的场景就是我们在做微服务拆分的时候,就会按照业务边界,把各个业务的数据从一个单一的数据库中拆分开,分别把订单、物流、商品、会员等单独放到单独的数据库中。

还有就是有的时候可能会需要把历史订单挪到历史库里面去。这也是分库的一种具体做法
微服务项目在开发的过程中需要根据业务和数据进行拆分, 拆分成不同的微服务, 一般而言数据也会一起拆分 , 拆分成多个库, 每个微服务单独对应一个库 , 所以微服务天然分库 , 所以能够支撑的并发量比较高
分表的原理
分表主要解决的是数据量大的问题。假如你的单表数据量非常大,因为并发不高,数据量连接可能还够,但是存储和查询的性能遇到了瓶颈了,你做了很多优化之后还是无法提升效率的时候,就需要考虑做分表了。那么,当你的数据库链接也不够了,并且单表数据量也很大导致查询比较慢的时候,就需要做既分库又分表了。
分表主要解决的是数据量大的问题。通过将数据拆分到多张表中,来减少单表的数据量,从而提升查询速度。

一般我们认为,单表行数超过500万行或者单表容量超过2GB之后,就需要考虑做分库分表了,小于这个数据量,遇到性能问题先建议通过其他优化来解决。
以上数据,是阿里巴巴Java开发手册中给出的数据,偏保守,根据实际经验来说,单表抗1000万数据量问题不大,但具体的数据里还是要看记录大小、存储引擎设置、硬件配置等。
分库分表的情况
那如果既需要解决并发量大的问题,又需要解决数据量大的问题时候。通常情况下,高并发和数据量大的问题都是同时发生的,所以,我们会经常遇到分库分表需要同时进行的情况。
所以,当你的数据库链接也不够了,并且单表数据量也很大导致查询比较慢的时候,就需要做既分库又分表了。
如何对表进行拆分?
通常在做拆分的时候有两种分法,分别是横向拆分(水平拆分)和纵向拆分(垂直拆分)。假如我们有一张表,如果把这张表中某一条记录的多个字段,拆分到多张表中,这种就是纵向拆分。那如果把一张表中的不同的记录分别放到不同的表中,这种就是横向拆分。
横向拆分
横向拆分的结果是数据库表中的数据会分散到多张分表中,使得每一个单表中的数据的条数都有所下降。比如我们可以把不同的用户的订单分表拆分放到不同的表中。

纵向拆分
纵向拆分的结果是数据库表中的数据的字段数会变少,使得每一个单表中的数据的存储有所下降。比如我可以把商品详情信息、价格信息、库存信息等等分别拆分到不同的表中。

分区和分表有什么区别?
数据库中数据量过多,表太大的时候,不仅可以做分库分表,还可以做表分区,分区和分表类似,都是按照一定的规则将一张大表进行分解。
听上去好像也差不多,不就是将表拆分吗?那具体有什么差别呢?
主要是分区和分表后数据的数据存储方式有变化
在Innodb中(8.0之前),表存储主要依赖两个文件,分别是.frm文件和.ibd文件。.frm文件用于存储表结构定义信息,而.ibd文件则用于存储表数据。
分区的原理
假如我们有一张users表,想要对他进行分区和分表,区别如下:
分区 :MySQL InnoDB存储引擎在分区表时,会将每一个分区分别存放在一个单独的.ibd文件中,所有的.ibd文件组合构成表的物理结构,即表空间(Table Space)对于上面分区的users表,存储都时会在MySQL的data目录下创建一个用户名+表名+分区名.ibd的文件(如:users_p1.ibd),用来存储users表中第一个分区的数据,同样会有users p2.ibd和users p.3.ibd来存储第二和第三个分区的数据:
分表的原理
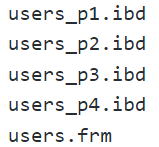
分表 : **MySQL InnoDB存储引擎在分表时,会将每一个分表分别存放在一个单独的.frm文件中,所有的.frm文件组合构成表的罗辑结构,即Table
Definition。
对于上面分表的users表,存储时会在MySQL的data目录下创建后缀名为"users1.frm”的表格文件,存储users表中第一个分表的数据,同样会有users2.frm和users3.frm来存储第二和第三个分表的数据:

- 在做了分区后,表面是还是只有一张表,只不过数据保存在不同的位置上了(同一个.f文件),在做数据读取的时候操作的表名还是usrs表,数据库会自己去组织各个分区的数据。
- 而在做了分表之后,不管是表面上,还是实际上,都已经是不同的表了(多个.fr文件),数据库操作的时候,需要去指定具体的表名。
一般来说,数据量变大时,我们应该先考虑分区,分区搞不定再考虑分表,因为分表可以在分区的基础上,进一步减少查询时的系统开销。因为分表后,单表数据量小,页缓存率更高,读写性能更优,另外分表也能降低了锁带来的阻塞,也可以提高事务处理效率。还有就是小的表可以提升备份和恢复的速度、并且具有更好的横向扩展性。
分区的方式
表分区的方式有水平分区、垂直分区:
- 水平分区:将表根据行进行划分,即把一个表的数据划分成多个表的数据,每个表形成一个分区;这些细分出来的部分存放在多个不同的分区表中(比如按年份等)。每块数据都存放在不同的表中,可以显著提高操作的效率。
- 垂直分区:将表根据表字段进行划分,将表中的列(或字段)分割成多个数据表,用于存储不同的业务场景内的数据。使分区后的数据表垂直分离,可以有效减少数据库查询中非必要的访问。
MySQL数据库支持的分区类型为水平分区。常见的表分区实践中,可以按照下列原则进行分区:
- 按照系统负载,将数据分到不同的区域中;
- 按照应用程序查询模式,将数据库分为不同的分区;
- 按照月份或者年份分区;
- 通过实践哈希法可以将记录放置到不同的分区中;
- 基于范围查询,使用分段来将记录放置到不同的分区中,以便提高查询效率。
分库分表的工具?
在选定了分表字段和分表算法之后,那么,如何把这些功能给实现出来,需要怎么做呢?
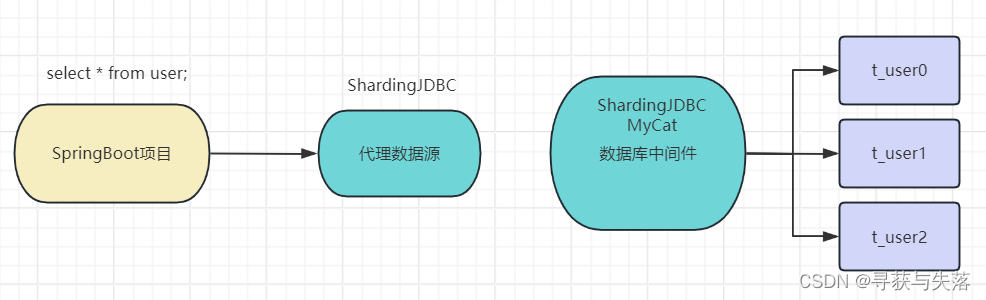
我们如何可以做到像处理单表一样处理分库分表的数据呢?这就需要用到一个分库分表的工具了。
目前市面上比较不错的分库分表的开源框架主要有三个,分别是 sharding-jdbc、TDDL 和 Mycat
Sharding-JDBC
具体操作可参考官网:https://shardingsphere.apache.org/document/current/cn/quick-start/shardingsphere-jdbc-quick-start/
现在叫ShardingSphere(Sharding-JDBC、Sharding-Proxy和Sharding-Sidecari这3款相互独立的产品组成)。它定位为轻量级ava框架,在Java的JDBC层提供的额外服务。它使用客户端直连数据库,以jar包形式提供服务,无需额外部署和依赖,可理解为增强版的JDBC驱动,完全兼容JDBC和各种ORM框架
Mycat
具体操作可参考官网:[https://www.yuque.com/ccazhw/ml3nkf?]
Mycat是一款分布式关系型数据库中间件。它支持分布式SQL查询,兼容SQL通信议,以Java生态支持多种后端数据库,通过数据分片提高数据查询处理能力。
分表字段如何选择(电商案例)?
在分库分表的过程中,我们需要有一个字段用来进行分表,比如按照用户分表、按照时间分表、按照地区分表。这里面的用户、时间、地区就是所谓的分表字段。
那么,在选择这个分表字段的时候,一定要注意,要根据实际的业务情况来做慎重的选择。
比如说我们要对交易订单进行分表的时候,我们可以选择的信息有很多,比如买家id、卖家id、订单号、时间、地区等等,具体应该如何选择呢?
通常,如果有特殊的诉求,比如按照月度汇总、地区汇总等以外,我们通常建议大家按照买家进行分表。因为这样可以避免一个关键的问题那就是—数据倾斜(热点数据)
例如 : 电商订单系统分表 , 可选的分表字段有买家id、卖家id、订单号、时间、地区
首先,我们先说为什么不按照卖家分表?
因为我们知道,电商网站上面是有很多买家和卖家的,但是,一个大的卖家可能会产生很多订单,比如像苏宁易购、当当等这种店铺,他每天在天猫产生的订单量就非常的大。如果按照卖家d分表的话,那同一个卖家的很多订单都会分到同一张表。
就会使得有一些表的数据量非常的大,但是有些表的数据量又很小,这就是发生了数据倾斜。这个卖家的数据就变成了热点数据,随着时间的增长,就会使得这个卖家的所有操作都变得异常缓慢。

但是,买家ID做分表字段就不会出现这类问题,因为不太容易出现一个买家能把数据买倾斜了。
但是需要注意的是,我们说按照买家id做分表,保证的是同一个买家的所有订单都在同一张表,并不是要给每个买家都单独分配一张表。
我们在做分表路由的时候,是可以设定一定的规则的,比如我们想要分1024张表,那么我们可以用买家ID或者买家ID的hnashcode对1024取模,结果是0000-1023,那么就存储到对应的编号的分表中就行了。
卖家查询怎么办
如果按照买家id进行了分表,卖家的查询怎么办,这不就意味着要跨表查询了吗?
首先,业务问题我们要建立在业务背景下讨论。电商网站订单查询有几种场景?
1、买家查自己的订单
2、卖家查自己的订单
3、平台的小二查用户的订单。
首先,我们用买家ID做了分表,那么买家来查询的时候,是一定可以把买家D带过来的,我们直接去对应的表里面查询就行了。
那如果是卖家查呢?卖家查询的话,同样可以带卖家id过来,那么,我们可以有一个基于binlog、flink等准实时的同步一张卖家维度的分表,这张表只用来查询,来解决卖家查询的问题。

本质上就是用空间换时间的做法。
不知道大家看到这里会不会有这样的疑问:同步一张卖家表,这不又带来了卖家的热点问题了吗?
首先,我们说同步一张卖家维度的表来,但是其实所有的写操作还是要写到买家表的,只不过需要准实时同步的方案同步到卖家表中。也就是说,我们的这个卖家表理论上是没有业务的写操作,只有读操作的。
所以,这个卖家库只需要有高性能的读就行了,那这样的话就可以有很多选择了,比如可以部署到一些配置不用那么高的机器、或者其实可以干脆就不用MYSQL,而是采用ElasticSearch 或者 MongoDB , HBase等数据库就可以了。这些数据库都是可以海量数据,并提供高性能查询的。
还有呢就是,大卖家一般都是可以识别的,提前针对大卖家,把他的订单,再按照一定的规则拆分到多张表中。因为只有读,没有写操作,所以拆分多张表也不用考虑事务的问题。
订单查询怎么办
上面说的都是有买卖家ID的情况,那没有买卖家ID呢?用订单号直接查怎么办呢?
这种问题的解决方案是,在生成订单号的时候,我们一般会把分表结果编码到订单号中去,因为订单生成的时候是一定可以知道买家ID的,那么我们就把买家ID的路由结果比如1023,作为一段固定的值放到订单号中就行了。这就是所谓的"基因法"
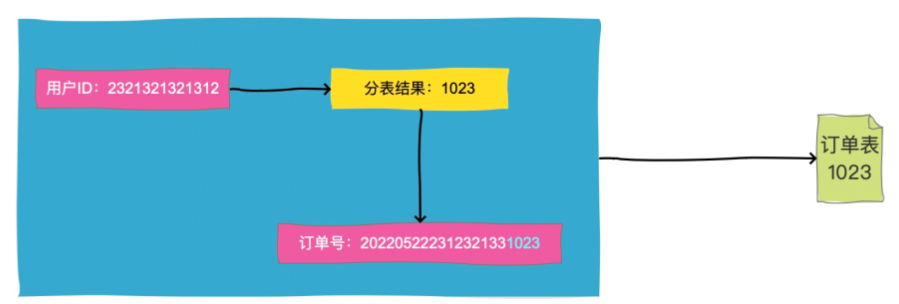
这样按照订单号查询的时候,解析出这段数字,直接去对应分表查询就好了。
至于还有人问其他的查询,没有买卖家ID,也没订单号的,那其实就属于是低频查询或者非核心功能查询了,那就可以用ES等搜索引擎的方案来解决了
分表算法都有哪些?
如何基于这个分表字段来准确的把数据分表到某一张表中?
这就是分表算法要做的事情了,但是不管什么算法,我们都需要确保一个前提,
那就是同一个分表字段,经过这个算法处理后,得到的结果一定是一致的,不可变的。
通常情况下,当我们对oder表进行分表的时候,比如我们要分成128张表的话,那么得到的128表应该是:order0000、order0001、order0002.order0126、order0127
通常的分表算法有以下几种:直接取模 , 按照关键字 , Hash取模 , 一致性Hash(二次分表)
直接取模
在分库分表时,我们是事先可以知道要分成多少个库和多少张表的,所以,比较简单的就是取模的方式。比如我们要分成128张表的话,就用一个整数来对128取模就行了,得到的结果如果是0002,那么就把数据放到order0002这张表中。
按照关键字
有的时候,我们在分表的时候,可以给予一定的关键字做拆分,比如按照时间,比如某个月份或者年份的数据单独放在某一个表中,或者可以按照地区分表也比较常见。
Hash取模
那如果分表字段不是数字类型,而是字符串类型怎么办呢?有一个办法就是哈希取模,就是先对这个分表字段取Hash,然后在再取模。但是需要注意的是,Java中的hash方法得到的结果有可能是负数,需要考虑这种负数的情况。
一致性Hash
前面两种取模方式都比较不错,可以使我们的数据比较均匀的分布到多张分表中。但是还是存在一个缺点。那就是如果需要扩容二次分表,表的总数量发生变化时,就需要重新计算hsh值,就需要涉及到数据迁移了。为了解决扩容的问题,我们可以采用一致性哈希的方式来做分表。
分库分表后会带来哪些问题?
首先,做了分库分表之后,所有的读和写操作,都需要带着分表字段,这样才能知道具体去哪个库、哪张表中去查询数据。如果不带的话,就得支持全表扫描。
但是,单表的时候全表扫描比较容易,但是做了分库分表之后,就没办法做扫表的操作了,如果要扫表的话就要把所有的物理表都要扫一遍。
还有,一旦我们要从多个数据库中查询或者写入数据,就有很多事情都不能做了,比如跨库事务就是不支持的。还有跨表查询的问题
所以,分库分表之后就会带来因为不支特事务而导致的数据一致性的问题。可能就需要用到分布式事务控制的问题了
其次,做了分库分表之后,以前单表中很方便的分页查询、排序等等操作就都失效了。因为我们不能跨多表进行分页、排序。
除此之外,还有一些其他的问题,比如二次分表的问题,一致性的问题等等。
分库分表后如何进行分页查询?
在我们做了分库分表之后,数据会散落在不同的数据库中,这时候跨多个库的分页查询、以及排序等都非常的麻烦。如果分的库不多,那么我们还可以通过扫表的方式把多个库中的数据都取出来,然后在内存中进行分页和排序。
比如我要查询limt100,100的话,有三个库,那我就分别到这三个库中把0-200之间的数据都取回来,然后再在内存中给他们排序,之后再取出第100-200之间的数据。这种做法非常的麻烦,而且随着偏移量越大,当要分的页很多的时候,查询效率就会很低
shardingkeyi查询
一般来说,买家的订单查询是最高频的,而对于买家来说,查询的时候天然就是可以带买家ID的,所以就可以路由到单个库中进行分页以及排序了。
非shardingkey的关键查询
那么,电商网站上不仅有买家,还有卖家,他们的查询也很高频,该怎么做呢?
一般来说,业务上都会采用空间换时间的方案,同步出一张按照卖家维度做分表的表来,同步的过程中一般是使用canal基于bin log做自动同步。虽然这种情况下可能存在秒级的延迟,但是一般业务上来说都是可以接受的。
也就是说,当一条订单创建出来之后,会在买家表创建一条记录,以买家ID作为分表字段,同时,也会在卖家表创建一条记录出来,用卖家ID进行分表。并且这张卖家表不会做任何写操作,只提供查询服务,完全可以用一些机器配置没有那么高的数据库实例。这样,卖家的分页等查询就可以直连卖家表做查询了。
本篇小结
有小伙伴对其他数据库内容感兴趣,可以通过以下链接进行查看
数据库-索引(基础篇)
数据库-索引结构(B-Tree,B+Tree,Hash,二叉树)
数据库-索引语法(增删查)
数据库-索引分类(主键索引、唯一索引、普通索引、全文索引)
数据库-索引使用(验证索引效率、单列索引与联合索引、最左前缀法则)
索引失效情况
数据库-Mysql锁详解(全局锁、表级锁、行级锁)