整型提升介绍
C语言中整型算术运算总是至少以缺省(默认)整型类型的精度来进行的。为了获得这个精度,表达式中字符、短整型操作数在使用前被转换为普通整型。而这个过程是悄悄发生的。
整型提升的意义:
表达式的整型运算要在CPU的相应运算器件内执行,CPU整型运算器(ALU)的操作数的字节长度一般就是int的字节长度,同时也是CPU的通用寄存器的长度。
因此,即使是进行两个char类型的相加,在CPU执行时实际上也要先转换为CPU内整型操作数的标准长度。
通用CPU难以直接实现两个8bit字节的直接加法运算。所以,表达式中各种长度可能小于int长度的整型值,都必须先转换为int或unsigned int,然后才能送入CPU去执行。
举个例子:
char a = 20;
char b = 130;
char c = a + b;
printf("%d\n", c);
根据我们上面说的,在这段代码中,其实会先把a、b提升为整型类型才计算。
怎么整型提升
有符号整数的整型提升是按照变量的数据类型的符号位来提升的;
无符号整数提升,高位就补0。
回到我们刚才的例子:
char a = 20;20本身是个整数,整数存到整型中应该有32个比特位(bit),因为是个正整数,它的原码、反码、补码相同:
00000000000000000000000000010100但是我们现在要将它存放到char类型(只有1个字节,也就是8bit)中去,会发生截断。
我们只能存下这个:
00010100同样的道理,b里面我们只能存的是:
10000010那么现在,c里面放的是什么?
因为我们已经知道,a+b在具体计算前会先发生整型提升,我们也知道整型提升的规则是:有符号整数的整型提升是按照变量的数据类型的符号位来提升的;无符号整数提升,高位就补0。因为是a、b是有符号整型,所以按照符号位来提升:
00010100 ---> 00000000000000000000000000010100 //因为符号位为0
10000010 ---> 11111111111111111111111110000010 //因为在提升时认为符号位是1
a + b: 1111111111111111111111111001011011111111111111111111111110010110 ---> 10010110 //因为c只能存8位,又截断所以c里面存的是10010110,但是这还没有结束,最后我们要打印的时候用的是%d,这是打印一个有符号的整型,我们此时又要进行提升:
10010110 ---> 11111111111111111111111110010110
//因为%d是有符号整型,提升时按符号位提升,而1被视作符号位而此时%d打印出来的结果并不是这个二进制序列直接翻译成十进制的结果,因为内存中存储的是补码,而我们要找出它的原码直接翻译的结果才是我们会打印出来的值:
因为现在的符号位上还是1,被当做负整数,所以原码、反码、补码并不相同,我们可以通过将补码取反+1的方法得到原码:
11111111111111111111111110010110 ---> 10000000000000000000000001101001
//取反的规则是符号位不变,其它位取反10000000000000000000000001101001 ---> 10000000000000000000000001101010
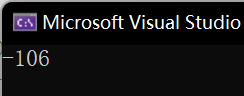
//将取反的结果再加1最后这个原码直接翻译:因为%d是有符号整数,符号位为1所以是负数,1101010转换为10进制是106,所以最后打印的结果就是-106。
另一种视角(char取值范围)
char a = 20;
char b = 130;
char c = a + b;
printf("%d\n", c);关于这段代码,通过上面的讲解我们多次感受到了整型提升, 这是我们从内存中存储了什么的角度一步步去看为什么结果是-106的,其实还有另一个角度可以解释结果为什么结果为-106:
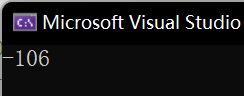
我们不要忘记char类型的取值范围,一般情况下char就是指的有符号的char,取值范围是-128~127(而unsigned char范围是0~255,都是256个不同数值)。
(本文不解释为什么是这样)这是我们char能存储的值的示意图,就像一个轮回:
所以其实130大于char的取值,我们无法将其存进b里。
我们可以通过监视看看b存的是什么:
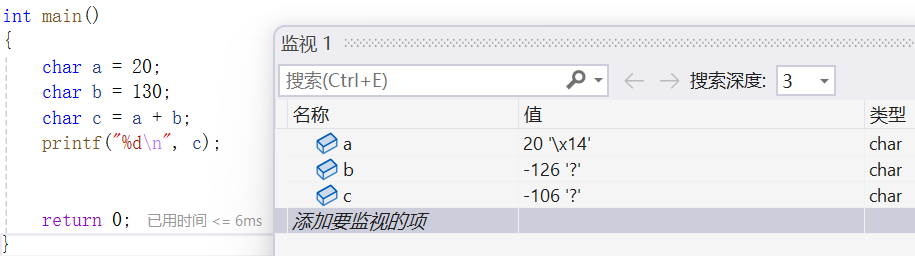
可以看到我们存的值就是-126,那么a+b就变成了-106。
那么为什么b里面会存为-126呢?在上面我们已经得到了a+b的二进制序列被截断为8bit,也就是c里实际存的二进制序列是:
10010110在计算器中我们可以观察到这个二进制序列直接翻译为10进制的值是150。
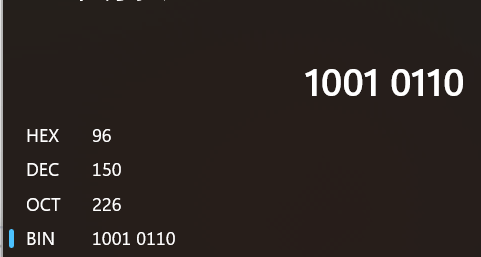
但是对于char而言,这个二进制序列可不是代表150。 为什么?
因为char只能存8bit,且为有符号类型,所以最高位是符号位,1说明是负整数,那么说明存的是补码,原码需要计算,根据取反(符号位不变,其他位按位取反)再+1,我们得到原码是:
10010110 ---> 11101001 ---> 11101010
取反 加1最高位是符号位,代表是负数,而剩下的有效位转化为十进制是106。所以原码就是106,

补充:char能存储的补码
我们知道char有8位,而每一位非0即1,所以我们能存的补码就是00000000~11111111,又因为char是有符号的char,所以当最高位变为1的时候我们会将其作为符号位而非有效位,而存的又是补码,在翻译为10进制数的时候要先取反加1得到原码,直接翻译才是其对应的10进制数。
其中10000000的求原码比较特殊,取反加1后我们得到100000000是9位的,而char只能存8位,所以会变为00000000,但是我们却不将其翻译为10进制的0而是-128。除了这个特殊情况外,其它情况都可以正常方式得到原码:

通过这张图,你应该就理解了上面那个“轮回”的图为什么是那样的了。
我们还可以发现,除了127加1得到的是-128的特殊情况,其他时候补码加1就是10进制加1的效果。
到此,整型提升和char取值范围的讲解就结束了,祝阅读愉快^-^





































![[书生·浦语大模型实战营]——第二节:课后作业](https://img-blog.csdnimg.cn/direct/4722dacae081444190aab04345e037c9.png)