文章目录
原文: 有趣的Decimal 类型 如何被 PostgreSQL 和 Apache-Arrow 实现
背景
近期工作中有涉及到我们 向量化引擎的 Decimal 数据类型和 PostgreSQL built-in Decimal 数据类型的兼容问题, 在此做一个体系化的梳理.
从 Float 到 Double, 再到 Decimal
Decimal 这种数据类型的诞生背景是 以完全正确的方式表示 Float/Double这种浮点类型在计算机中无法精确表示的数据.
二进制浮点数据类型 Float && Double 如何存储数据
单精度浮点类型 Float(32位) 和 双精度浮点类型 Double(64位)都遵循 IEEE-754标准, 这两个精度是在 IEEE-754 1985年的标准下就推出了,属于最早的浮点类型.后来为了处理 Double 类型下的 overflow 问题, 相继推出了 三精度和四精度浮点类型, 即占 128bits 和 256bits 的浮点类型. 浮点类型的组成主要有以下几个部分:
- 符号位, 1bit, 表示数值的正负
- 指数, 用作计算小数点的位置
- 尾数, 去掉小数点后的所有数值的有效位
- 基数, 进制, 二进制浮点类型的基数就是2, decimal 小数类型的基数是10.当然, 这个不需要存储, 一般会直接和类型绑定. 发现是float/double, 基数默认就是2;用的是 decimal类型, 则基数是10.
Float 单精度浮点数的32bits 构造如下:

Double 双精度浮点数的64bit 构造如下:
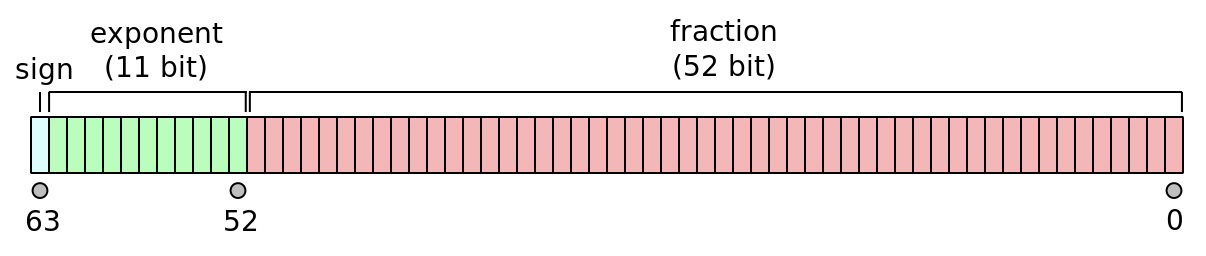
介绍浮点类型的完整存储之前我们先看看二进制小数是如何被计算出来的,比如对于人类可读的二进制的小数 1110.1101, 小数点前的位权从右向左分别是 2的 0次幂,1次幂, 2次幂…, 小数点后的位权从左向右依次是 2的 -1次幂, -2次幂, -3次幂. 用小数点前的数值加上小数点后的数值就是最后的十进制结果了.
1110.1101 转为十进制就可以通过这种方式来计算:
$
8 + 4 + 2 + 0 + 0.5 + 0.25 + 0 + 0.0625 = 14.8125
$
Float 浮点的完整二进制存储结果到二进制小数的计算方式如下:
(-1)^符号位 * 尾数部分数值 * 2^(指数部分数值 - 2^7 - 1)
以上图Float数值0.15625为例, 看看其如何被二进制表示:
- 符号位: 0 数值为正
- 指数部分: 01111100
- 尾数部分: 01000000000000000000000
(-1)^0 * 01000000000000000000000 * 2^(124 - 127)
= 1 * 1.01000000000000000000000 * 2^(-3)
= 0.00101
= 2^(-3) + 2^(-5)
= 0.125 + 0.03125
= 0.15625
上面的计算过程中有一个细节不知道大家注意到了没? 尾数部分计算前是 01000000000000000000000, 转成人类使用的二进制表示的形式之后却变成了 1.01000000000000000000000, 这个小数点前的1是怎么肥事.
这也是IEEE 标准中介绍的23位尾数之前还有一个隐式前导位 1, 主要是为了以统一的处理流程来处理所有的二进制浮点的数据类型, 将小数点前的值固定为1, 因为小数点前永远有一个隐式的1, 所以也就不需要单独占用一个bit了:
The true significand includes 23 fraction bits to the right of the binary point and an implicit leading bit (to the left of the binary point) with value 1, unless the exponent is stored with all zeros. Thus only 23 fraction bits of the significand appear in the memory format, but the total precision is 24 bits (equivalent to log10(224) ≈ 7.225 decimal digits).
以同样的方式我们可以将 1110.1101 小数转为完整的二进制存储格式.
- 符号为: 0, 数值为正
- 指数部分: 右移3位将小数点前的数值变为1, 1.1101101, 指数数值为 3 + (2^7 - 1) = 130 = 10000010
- 尾数部分: 1.1101101, 小数点后填充到23bits满足数据格式标准 即为 11011010000000000000000
大家可以以同样的计算方式来算一下其他的浮点类型的数值,或者换成其他的精度以同样的方式计算即可, 只是需要变更指数部分, 比如double的指数位数是11bits.
二进制浮点类型存在的问题
接下来就到了有趣的问题时刻, 对于 0.1 或者 0.3这样的十进制有理数很容易在十进制体系中存在,但是如果要用二进制来表示这样的数值就会发现会出现和十进制中 1/3 的表示相同的问题. 因为十进制中 3 无法被10 整除, 同样的二进制中 小数点后的位权求和本质上是一个以 1/2 为公比的幂级数求和问题, 是无限趋近于1的,所以要表示十进制的0.1, 最终的二进制结果也只能是一个近似值.
比如:
Float 的0.1表示是:0.100000001490116119384765625
Double 的0.1 表示是: 0.100000000000000005551115123126
Float和Double的表示差异是两者二进制对0.1的计算不同导致的,Float的完整二进制对0.1 的表示为:00111101 11001100 11001100 11001101, 因为只能支持到32bits, 后续要更大的精度会以 1100 为循环.
二进制的结果可以直接看如下图:
s eeeeeeee mmmmmmmmmmmmmmmmmmmmmmm 1/n
0 01111011 10011001100110011001101
| || || || || || +- 8388608
| || || || || |+--- 2097152
| || || || || +---- 1048576
| || || || |+------- 131072
| || || || +-------- 65536
| || || |+----------- 8192
| || || +------------ 4096
| || |+--------------- 512
| || +---------------- 256
| |+------------------- 32
| +-------------------- 16
+----------------------- 2
通过float的二进制结果直接算一下完整的0.1表示:
(-1)^0 * 2^(123-127) * (1/2+1/16+1/32+…+1/8388608)
= 1/16 * (1/2+1/16+1/32+…+1/8388608)
= 1/16 * 1.60000002384185791015625
= 0.100000001490116119384765625
但本质上还是没有办法完全正确得表示0.1,即使IEEE-754 也相继推出了 128和256bits 的浮点类型, 但是也只能通过提升精度来降低对0.1 这样的有理数的表示误差, 也无法完全正确的表示.
100个double 表示的0.1求和和100个float表示的0.1 求和完全不同. double最终的结果是:9.9999999999999804601; float最终的结果是10.000001907348632812.
十进制浮点类型 Decimal 如何解决问题
Decimal 类型就是在二进制浮点类型存在问题的情况下诞生的,IEEE-754 在2008年引入了 decimal32/decimal64/decimal128 [2] 类型,但是各个语言标准对decimal的支持度还不够, 比如c/c++目前还没有支持标准的decimal类型, 而C#/JAVA 已经支持了32/64的decimal类型了.
Decimal 类型 解决问题的方式非常聪明, 主要是将基数变更为十进制, 通过十进制来表示十进制.这样, 0.1/0.3这样的需要二进制无限循环表示的数据就简单而直接了,并且完全准确.
Decimal 类型的组成部分和二进制浮点类型的组成一样,也由 符号位、指数部分、尾数部分组成、基数, 差异主要是Decimal的基数是10.
比如 IEEE-754 提出的 Decimal32的组成:
- 符号位: 1bit
- 指数部分: 11bits, 以十为基数的负指数幂,代表小数点应该点在尾数代表的有效数字的位置
- 尾数部分: 20bits, 代表有效数字
Decimal32 类型中没有像是二进制浮点类型中的 隐式前导"1", 所以尾数部分代表的有效数字也就只有20bits(1048576), 意味着十进制的有效数字最多只能有7个有效位, 且十进制的最高位只能是1, 之后的6个有效位才能是0-9的任意数字. 意味着小数点在十进制中可以放置的位置只有7个, 但是指数部分有11bits, 也就是对于超过7的指数则需要损失精度, 能表示的有效位数只有7.这个问题也是Decimal数据类型暂时无法解决的劣势, 只能通过扩展更多的存储空间来解决.
比如对于 10485769 这个数值, 在decimal32中只能表示为 +1.048576e8, 原始数据的最后一个数值 9 会被丢弃. 但是decimal是能完全正确得表示自己精度范围内的数值, 比如 0.1 在decimal32中就非常容易了(可以有多种表示方式, 110-e1, 0.1, 0.0110-e2…), 只要用尾数部分的数值表示1/10/100…, 指数部分表示对应的小数点即可.
在PostgreSQL中实现的Decimal类型中通过较多的内存空间的占用,实现了十多万位的有效数字. Arrow则实现的更为轻量,支持了 Decimal128bits和256bits的类型,分别支持38位有效数字和76位有效数字, 因为arrow服务于计算体系 且类型系统扩展性良好, 76位有效数字的精度完全能支持现在大多数分析型计算系统的精度需求, 暂时没有像PG这种支持超大精度的必要性.
接下来我们详细看看 服务于TP系统 的PostgreSQL 和 服务器分析型列存AP场景的内存数据处理平台Arrow 这两种系统的Decimal实现.
Decimal 在 PostgreSQL 中的实现
Postgresql 使用 Numeric 数据类型表示 Decimal, 并提供了相关的计算方法以及 内存和磁盘的数据表示. 后续对于PG 中的Decimal数据类型统称为 Numerci 数据类型(PG 其实也提供了 DECIMAL 的语法 create table a(c1 DECIMAL/DECIMAL(precision,scale));, 只是底层对于数据的操作都会转成 Numeric).
Numeric 的磁盘格式表示
当我们向带有 NUMERIC 数据类型的表中插入数据, 在rewrite 或者 executor阶段, NUMERCI 数据类型会通过内部的一些方法 numeric_in 将用户输入的数据从字符串转为 NUMERIC 的内存格式NumericVar, 再转为磁盘格式NumericData, 最终以 Datum 这样的字节数组返回. 这一些数据再通过 AM 并带着自己的schema 以 Tuple形式存储在 heap表中.
NUMERCI 数据类型的转换, 从用户的字符串输入到其磁盘格式NumericData 以及磁盘格式 NumericData 到字符串的转换其实都是在 AM之上的阶段完成的.
先看看 NumericData 这个磁盘格式,其表示方式本身也决定了 PG 的numeric类型能支持的范围 或者说精度.
NumericData 这个数据结构带了一个所有磁盘数据类型都会有的varlena长度 以及一个 union NumericChoice.
在 NumericChoice union中会通过 16 字节的 n_header 来决定用 NumericLong 还是 NumericShort.
union NumericChoice
{
uint16 n_header; /* Header word */
struct NumericLong n_long; /* Long form (4-byte header) */
struct NumericShort n_short; /* Short form (2-byte header) */
};
NumericLong 相比于 NumericShort 多了个一个 uint16 的字段来表示 weight, 所以它能有更大的表示范围.
对于 NumericChoice, 可以用存储于 n_header 中的前两个 bits 来区分是否使用 Short/Long:
- NUMERIC_POS – 0x0000 正数 且按照 LONG的格式来取
- NUMERIC_NEG – 0x4000 负数 同上
- NUMERIC_SHORT – 0x8000 按照SHORT 格式来取, 正负符号在下一位
- NUMERIC_NAN – 0xC000 NAN 无效数据
PG 实现的Numerci
在LONG中, 对于数据的表示方式如下:
- header部分的2 bits 已经被header占用, 表示正负.
- header部分的14 bits 表示scale, 即小数点后的位数 (1<<15)-1 = 32767 位
- n_weight 16bits 则用于表示小数点前的位数, 可以理解为指数部分, 只是基数在PG里变成了10000. 因为decimal的基数都是10, 对于每一个n_weight数值, 按照 NBASE(10^4) 4个十进制数据位来拆分, 所以最终小数点前可以表示的位数就变成了 (1<<16/2 )* 4 = 131072
- n_data 是一个int16可以动态扩容的数组, 用于存储实际的 Numeric数据, 每一个十进制数都会占用一个字节.
struct NumericLong
{
uint16 n_sign_dscale; /* Sign + display scale */
int16 n_weight; /* Weight of 1st digit */
NumericDigit n_data[FLEXIBLE_ARRAY_MEMBER]; /* Digits */
};
在SHORT中, 没有额外的字段存储 n_weight, 所以sign,scale和n_weight的数值都会被存储在 n_header 剩下的14 bits中, 可以表示的位数自然就小了很多.
struct NumericShort
{
uint16 n_header; /* Sign + display scale + weight */
NumericDigit n_data[FLEXIBLE_ARRAY_MEMBER]; /* Digits */
};
很明显, PG 的Decimal类型 为了支持十万多位的有效位数牺牲了不少存储空间, 每一个bytes来表示一个十进制数据位,显然成本是比较高的,而且计算成本也会很高. 这一些牺牲换来的是兼容性极高的精度度, 这对于按行处理的 TP 数据库来说就非常稳了, 可以支持大数以及大浮点数的高精度四则运算, 在AP 场景这会导致很难向量化.
接下来再看看 Numeric 数据类型的内存表示, 内存格式会尽可能将这一些字段展开, 方便取值计算.
Numeric的内存格式表示
其内存格式是通过 NumericVar 来表示, 直接看其数据结构:
typedef struct NumericVar
{
int ndigits; /* # of digits in digits[] - can be 0! */
int weight; /* weight of first digit */
int sign; /* NUMERIC_POS, NUMERIC_NEG, or NUMERIC_NAN */
int dscale; /* display scale */
NumericDigit *buf; /* start of palloc'd space for digits[] */
NumericDigit *digits; /* base-NBASE digits */
} NumericVar;
结构还是非常清晰的:
- ndigits 表示去掉前导零和末尾零, 存储到digits数组中占用的数组大小
- weight 表示指数部分, 只不过基数是要乘 10^4, 当然如果是负数, 则就需要乘 10^(-4).
- sign 符号位, 正、负、NAN, 用int 来玩, TP就是这么奢侈.
- dscale 小数点之后的位数
- buf 是实际 digits的内存空间拥有者 且 buf[0] 不会被使用,会用作处理进位; digits 实际的内存空间是从 buf[1]开始.
- digits, 用于对外访问 numeric 数据, 不负责numeric 数据的内存管理.
直接看2024.2800 在 NumericVar结构中的表示:
(gdb) p value
$69 = {ndigits = 2, weight = 0, sign = 0, dscale = 4, buf = 0x56383f58c148, digits = 0x56383f58c14a}
(gdb) p *value.digits@2
$71 = {2024, 2800}
(gdb) $72 = {2024, 2800}
(gdb) p *value.buf@3
$73 = {0, 2024, 2800}
在digits 数组中可以看到数值内容: 2024 2800; 小数点后有 4位, 则dscale就是4; sign 是0 表示正数; weight 表示最高位 log基数为10^4的值, 因为当前数值小于10^4, 所以weight 用0就可以. ndigits 2 就足够了, 后面介绍 numeric_in 函数时会详细介绍 ndigits的计算规则, 对于数值范围小于 10^4, 如何确定数值的最高位的大小.
除了digits 数组之外, 还打印出 buf 数组, 很明显 buf 的第一个元素是预留元素, 仅负责进位而已, 这也意味着这个空间没有进位的时候是闲置的, 只是为了保障正确性, PG也说了这中情况仅存在于 NUMERIC类型, 对于其他的数据类型不会用到这个类型…但对于每一个 Numeric元素, 其实都会占用额外的2bytes…
numeric_in 实现
numeric_in 函数的主要工作是将 以字符串输入的 Numeric 类型数值转为 NumericVar 的内存数据结构 以及 NumericData的磁盘格式, 最后以 Datum 返回.
numric_in 的输入参数有两个, 第一个是小数的字符串表示, 第二个是typemod, 可以被用于解析 precision 和 scale, 这个参数是可选的.
整个函数处理逻辑如下:
- 跳过前导空格
- 检查 NaN, 是则返回结果
- 通过
set_var_from_str解析字符串, 转为NumericVar - 通过
apply_typmod解析输入的typemode并设置NumericVar的精度. - 通过
make_result构造NumericData结构, 返回结果
其中核心逻辑是 set_var_from_str 以及 apply_typmod.
在 set_var_from_str中需要将小数字符串转为NumericVar结构 ,主要做的事情如下:
- 通过前导 ‘+’ 以及 '-'设置 sign 标记, 默认为 ‘+’
- 确认小数点前位数. 逐个字符 判断是否是数字,是则增加 dweight
- 确认小数点后位数. 遇到小数点, 设置了
have_dp = true标记之后遇到数字, 会增加 dscale, 作为小数点后位数. - 处理科学计数法, 比如遇到 ‘e’ 或者 ‘E’ 字符,则需要重新设置dweight和dscale.
- 计算
NumericVar需要的 weight 以及 ndigits, 并分配对应的 buf, 输入的小数字符串按照 ndigits 补齐并写入到buf中. - 去掉输入的小数字符串的前导零和末尾零, 对于前导零是不影响数值本身的, 不需要存储; 对于末尾零, 则只需要记住dscale即可, 不需要占用实际的buf存储空间.
第5步通过第2步统计的 dweight 来计算以 NBASE(10000) 为基数的 weight, 计算公式如下:
- dweight >= 0,
weight = (dweight + 1 + DEC_DIGITS - 1) / DEC_DIGITS - 1; - dweight <0,
weight = -((-dweight - 1) / DEC_DIGITS + 1);
其中DEC_DIGITS 表示的是 每一个以 NBASE为基数的数值表示的 decimal的小数位数, 肯定是4; dweight本质上是小数点前的位数, 但是初始值是-1, 所以统计出来的dweight值会比实际的小数点前位数少1.
计算完 weight之后还会计算一个 offset, 这个数值表示的是在存储小数的 digits 数组中第一个数值为了对齐4个数值位所需要的零的个数. 比如 32.113, 32 是小数点的数值, 会被独立存储, 但是只有两位, 所以offset会被设置为0.
ndigits的计算公式如下:
ndigits = (ddigits + offset + DEC_DIGITS - 1) / DEC_DIGITS, 其中 ddigits 数值跳过了 digits 数组的第一个元素的四个有效位数,所以后续的 ndigits的计算也需要带着 offset, 它其实代表的是 digits数组中第一个元素需要的零的个数.
最后统一处理 decdigits 数组中的数值, 将其按照 DEC_DIGITS = 4 4个一组转为十进制的数值存储到 digits 数组中,并通过 strip_var 统一去除前导零和末尾零, 需要注意的是这里去除的末尾零是 digits数组中整个元素为0的情况, 比如最后一个元素是9000, 那么这三个零是不会被去除的.
set_var_from_str 之后拿到了一个 不包含前导零和末尾零的原始 NumericVar数值, 接下来需要通过 apply_typmod 根据用户输入的 typemod 做精度的裁剪, 主要步骤如下:
- 从输入的 typmod中提取 precision和scale; scale是小数点之后的位数,会被设置位
NumericVar的 dscale; (precision - scale) 则是小数点前最大的位数 maxdigits, 用于计算ndigits和weight. - 在函数
round_var中根据scale 做小数点后的精度裁剪. 主要工作是重新计算保存小数点后的 digits数组的元素数值. - 检查是否发生 overflow, 即会确保当前
NumericVar的小数点前位数是不大于用户指定的 maxdigits(precision - scale); 如果不满足就会报错, 需要用户重新指定 precision 和 scale. 这里的原则是不能改变小数点前的位数,确保用户输入的maxdigits 是超过数值本身的小数点前的位数, 否则数值就不准确了, 只能报 overflow 问题.
Decimal 在 Apache-Arrow 中的实现
arrow 作为一个内存数据处理的平台, 其支持的类型系统当然也要支持Decimal数据类型. 相比于 PG, arrow实现的 Decimal类型更为轻量, 目前支持的 Decimal128Type 以及 Decimal256Type 底层都是通过uint64_t的std::array 实现的. 比如 128 bits的decimal 数据存储 会由两个 uint64_t 的数值存储, 256 bits则对应的由 4个uint64_t 的数值存储.
128bits 的decimal 在 arrow中能够支持的十进制最大的有效位数是38位,不同于 IEEE 标准中的decimal128 仅用110bits作为尾数,还预留了符号位和指数位数. arrow 自定义了整个Decimal类型, 对于decimal的数值表示可以用更多的内存来表示 IEEE标准中的符号位以及指数部分, 将底层两个uint64_t的数值 128bits 全部用于尾数部分, 这样可以表示的数值范围会更大.
Arrow decimal体系的实现过程中, 对于 decimal的 数值表示主要有如下两种类型:
WordArray = std::array<uint64_t, NWORDS>用于存储实际的decimal数值,相关的 precision 以及 scale 则由arrow::DecimalType保存, 使用 arrow的 array保存以及操作数据都需要arrow::DecimalType参与, 而 decimal type中会携带 scale和precision的信息用来从WordArray中取出 decimal 数值并转为正确的小数形态的表示方式.DecimalComponents用于将 strings/streams 中的数据解析为DecimalComponents作为中间结果, 便于最终转为WordArray存储下来.
从用户侧影响 decimal 数值表示的其实只有 Precision 和 Scale 这两个与 type相关的变量, 它们本身与第一种的数值表示 WordArray 直接关联.
而DecimalComponents internal的中间转换, 用于辅助将decimal 转为 WordArray中的 uint64_t数值, 类似 PG 的 NumericVar 作为中间数值, 最终还是会以 NumericData 格式存储到磁盘.
下文的介绍都以 128bits 的类型为例, 基于的代码版本 commit 193e39cad4d8e1a01376d6b5199077e401484838.
DecimalType
先看一下最基础的Decimal 类型, 整体的继承关系如下:
class ARROW_EXPORT DecimalType : public FixedSizeBinaryType
class ARROW_EXPORT Decimal128Type : public DecimalType
class ARROW_EXPORT Decimal256Type : public DecimalType
很有意思的是 不考虑 decimal 在 arrow的底层数值表示, 从类型这里 arrow就明确了 Decimal是定长的类型,也就基本清楚其底层的数值存储肯定是基础的数值类型. Decimal256Type 以及 Decimal128Type 也分别给出了 byte_width_ 分别是 32 和 16.
因为deicmal是定长类型, DecimalArray 的数据存储也就只有两个 buffer, 一个用于null_bitmap, 另一个buffer保存实际定长数值的字节数组. 取值时则可以按照bit_width 来取值并转为 WordArray 按照指定的规则去进行计算.
// 按照 byte_width取值
const uint8_t* FixedSizeBinaryArray::GetValue(int64_t i) const {
return raw_values_ + (i + data_->offset) * byte_width_;
}
// 转为Decimal128Type
std::string Decimal128Array::FormatValue(int64_t i) const {
const auto& type_ = checked_cast<const Decimal128Type&>(*type());
const Decimal128 value(GetValue(i));
return value.ToString(type_.scale());
}
这样对于底层 Decimal 体系 和类型系统的体系进行交互就比较清楚了, 接下来直接看更上层的 Decimal 体系如何实现.
BasicDecimal128
这个类管理的是 WordArray 以及 相关的基础操作, 包括取反、取绝对值、四则运算、与、或、非、左移、右移等.
从BasicDecimal128 管理的操作中能看出, Precision 其实并不重要,它主要用于 check 是 否overflow. 本质上 decimal的正确表示还是取决于 scale这个数值, 它决定了小数点应该被点在那里.
所以对于 WordArray 中两个 uint64_t 数值hit_bist和low_bits 的操作, 尤其是rescale这种调整精度的高频操作 都是通过scale来重新计算 uint64_t 中的数值.
以Rescale 函数为例, 它会将当前decimal 的小数位数从原本的scale变为新的scale. 调整 scale的时候会拿着这两个输入scale差值的绝对值 取一个 multiplier. 因为最终要操作的是两个uint64_t的数值 hit_bits和low_bits, 且 scale的位数在128bits 类型中是38, 这是固定的. 因为要操作的是十进制, hit_bits和low_bits在不同的位数下的最大乘数是固定的, 那完全可以提前计算好 从1-38 每一个scale下 两个数值的乘数, 用的时候直接取就可以.
constexpr BasicDecimal128 kDecimal128PowersOfTen[38 + 1] = {
BasicDecimal128(1LL),
BasicDecimal128(10LL),
BasicDecimal128(100LL),
BasicDecimal128(1000LL),
...
BasicDecimal128(0LL, 10000000000000000000ULL),
// 超过了低位uint64_t 表示的最大乘数之后有部分数值会进入高位,
// 高位也需要设置乘数
BasicDecimal128(5LL, 7766279631452241920ULL),
BasicDecimal128(54LL, 3875820019684212736ULL),
BasicDecimal128(542LL, 1864712049423024128ULL),
}
其他的四则运算则主要是对 WordArary进行操作, 比如 +/- 操作就是对输入的两个数值的 high_bits 以及 low_bits 对应 +/-, 最后考虑一下是否需要进位或者退位.
BasicDecimal128& BasicDecimal128::operator+=(const BasicDecimal128& right) {
int64_t result_hi = SafeSignedAdd(high_bits(), right.high_bits());
uint64_t result_lo = low_bits() + right.low_bits();
result_hi = SafeSignedAdd<int64_t>(result_hi, result_lo < low_bits());
*this = BasicDecimal128(result_hi, result_lo);
return *this;
}
BasicDecimal128& BasicDecimal128::operator-=(const BasicDecimal128& right) {
int64_t result_hi = SafeSignedSubtract(high_bits(), right.high_bits());
uint64_t result_lo = low_bits() - right.low_bits();
result_hi = SafeSignedSubtract<int64_t>(result_hi, result_lo > low_bits());
*this = BasicDecimal128(result_hi, result_lo);
return *this;
}
* 操作也是转为了对输入数值的 high_bits 和 low_bits的 * 操作.
/ 操作则复杂一些,和 PG 一样都参考的是 TAOCP 中的第四章节 浮点运算相关的部分.
Decimal128
这个类是在 BasicDecimal128 基础上实现的, 主要操作的是 strings/streams 这样的 decimal输入源, 更贴近用户.
比如它提提供了:
static Status FromString(std::string_view s, Decimal128* out, int32_t* precision,
int32_t* scale = NULLPTR);
可以从一个输入的string_view 中解析出带有 precision 和 scale 的 Decimal128 数据, 这是一些数据导入的必备功能.
其底层实现就类似与 PG的numeric_in 函数, arrow 在这个过程中利用了前面介绍的 第二种数据类型 DecimalComponents 作为中间结果.
DecimalComponents 的基本结构如下:
struct DecimalComponents {
std::string_view whole_digits; // 小数点前的数值位数
std::string_view fractional_digits; // 小数点后位数
int32_t exponent = 0; // 指数部分 数值
char sign = 0; // 符号部分
bool has_exponent = false; // 是否有指数
};
其中一些细节还是需要提前说一下:
- exponent 只有在用科学计数法表示的时候才会有效, 并不是像PG的weight一样 表示整数部分的乘数.
- sign 奢侈得用了一个字节来表示符号位,主要是 DecimalComponents 本身只是中间状态, 不常驻内存.
- whole_digits 是包含了前导零的所有小数点前的数值位.
在通过FromString 调度的 DecimalFromString函数主要做了如下几件事情:
- 通过
ParseDecimalComponents将输入的字符串转为DecimalComponents变量 dec. - dec.whole_digits 和 dec.fractional_digits 结合计算出 precision 和 scale.
- 通过ShiftAndAdd 将输入的 dec.whole_digits 和 dec.fractional_digits 转为 WordArray 中的两个uint64_t数值
- 如果有 exponent 且 计算的scale为负数, 则取 scale绝对值 获取乘数, 并对转换完成的 WordArray 进行乘操作, 并返回最终的结果.
其中 ParseDecimalComponents 操作就是从字符串提取 DecimalComponents 结构的基本操作, 整体链路很简单, 主要就是字符串解析.
- 先解析符号位
- 解析小数点前的数值位 到whole_digits, 遇到非数值终止
- 遇到小数点 解析后续的数值位 到 fractional_digits
- 处理科学计数法的情况,
StartsExponent仅判断满足e和E, 是则设置 has_exponent = true标记.
因为解析出来的 whole_digits 会包含前导零, precision 则是有效数值位, 计算 significant_dits时 用的是 significant_digits += dec.whole_digits.size() - first_non_zero;.
Arrow compute 体系下的 Decimal
前面主要介绍了 Decimal与类型系统 以及 Decimal 数值处理 internal的内容, 但是 precision 和尤为关键的 scale 如何被arrow的计算体系调度还需要再说明一下.
scale 我们在 Decimal128和BasicDecimal128的操作里并没有相关的scale参与计算, 但是实际使用的时候 arrow 除了作为内存数据处理平台,还会作为数据计算平台对输入的数据进行 internal 计算. 这个时候要处理的 decimal数据肯定会有不同的 precision和scale, 这个过程如何用一套统一的规则处理 precision和scale 并调度底层的 Decimal128 的计算操作则是 arrow compute 体系下的工作.
compute 中有很多内存数据计算相关的组件, 比如 Expression, 比如 Function. 这一块之前的文章 Apache arrow 极致模块化、可组合的数据平台 是有介绍过. Decimal的处理我们主要的关注点也是在 Expression 和 Function 组件中.
Expression 组件服务于数据库相关系统的表达式处理, 对于它的使用则是先生成一个静态的表达式树, 再后续计算表达式求值的时候通过表达式中的function对输入的列数据进行计算. 所以静态的 expression 需要在生成之后通过 Bind 操作填充表达式中 列引用的type, 之后的表达式求值时才能知道对应列的类型, 从而正确的调度对应类型的数值处理函数.
我们的 Decimal 中计算完成输出 Decimal 结果 的 precision和 scale就是在 Bind阶段 确定的. 一张简单的图来描述这个过程:
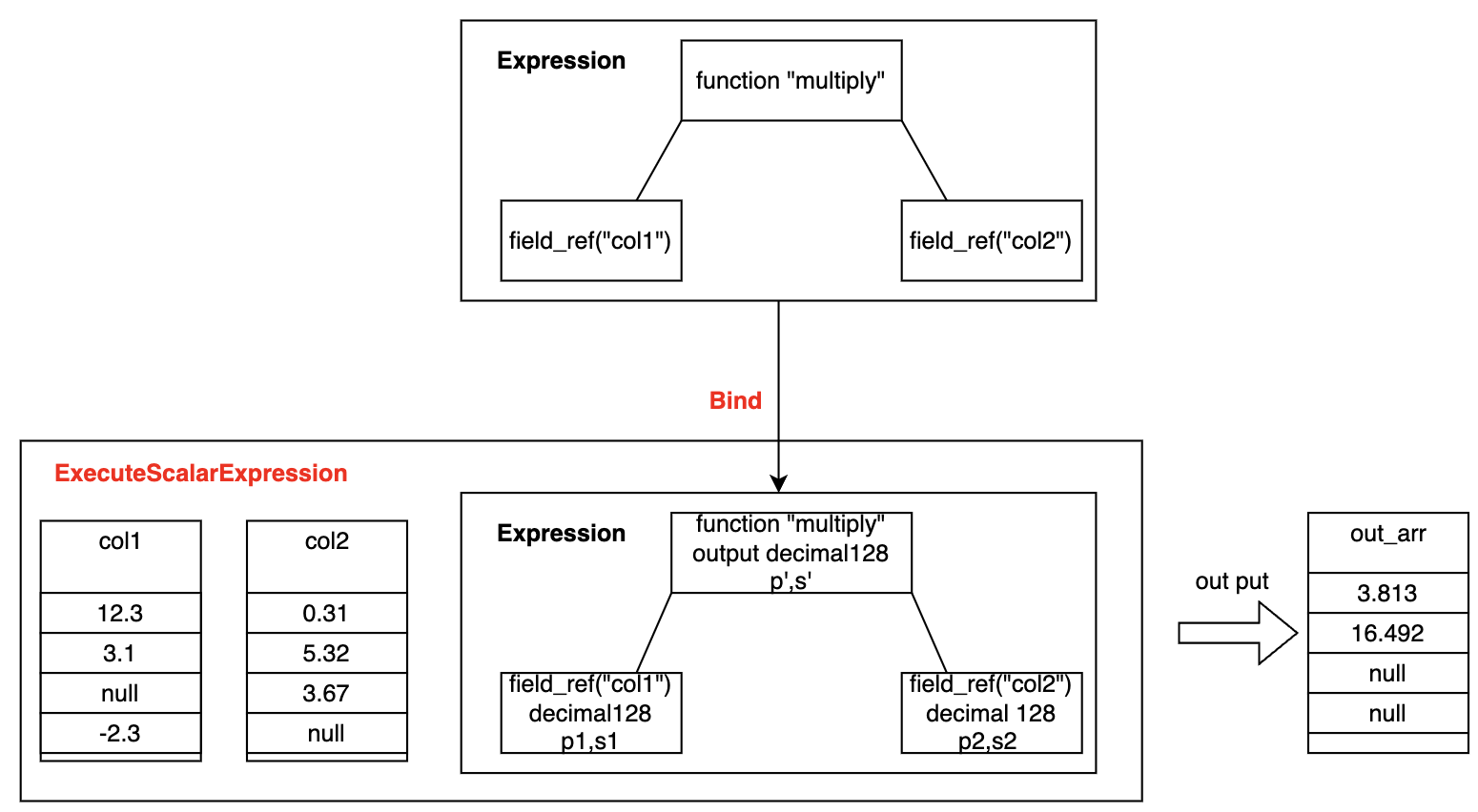
Bind 实现的逻辑核心有两步:
- 确认 filed_ref 这种列引用表达式在 数据schema中的类型
- 确认操作列引用的 function 最终的输出类型
第二步是在BindNonRecursive 中实现的, 因为上图中 multiply 是一个数值计算的function ArithmeticFunction, 其属于 ScalarFunction 也就是单值 function 体系, 参与计算的函数的输入类型都是 FixedType. 在 ArithmeticFunction 中重写了 DispatchBest, 这个函数主要是返回一个function对应的kernel, kernel包含了这个function执行需要的所有信息, 包括 signature(输入参数类型、输出类型), 注册方法、执行方法等.
我们的 ArithmeticFunction::DispatchBest 中会对输入 “col1” 和 “col2” 类型进行处理:
Result<const Kernel*> DispatchBest(std::vector<TypeHolder>* types) const override {
// 函数注册的时候需要设置参数个数, 检查一下
RETURN_NOT_OK(CheckArity(types->size()));
// Decimal 类型的internal cast
RETURN_NOT_OK(CheckDecimals(types));
...
}
在 CheckDecimals 函数中会根据数值计算的函数类型对 Decimal类型进行cast, 按照 Aws-Redshift 的decimal计算规则进行cast:
| Operation | Result precision and scale |
|---|---|
| + or - | Scale = max(s1,s2) Precision = max(p1-s1,p2-s2)+1+scale |
| * | Scale = s1+s2 Precision = p1+p2+1 |
| / | Scale = max(4,s1+p2-s2+1) Precision = p1-s1+ s2+scale |
最终的输出类型会在 BindNonRecursive 中的确认:
ARROW_ASSIGN_OR_RAISE(
call.type, call.kernel->signature->out_type().Resolve(&kernel_context, types));
Multiply 函数 kernel signature 的resolver_是在函数注册的时候确认的, 通过 RegisterScalarArithmetic 函数注册数值计算时会通过
AddDecimalBinaryKernels<Multiply>("multiply", multiply.get());
注册 Decimal类型的 乘法操作,其内部设置了 resolver_ callback:
template <typename Op>
void AddDecimalBinaryKernels(const std::string& name, ScalarFunction* func) {
OutputType out_type(null());
const std::string op = name.substr(0, name.find("_"));
// 注册 resolver_ 回调, 用于设置output type
if (op == "add" || op == "subtract") {
out_type = OutputType(ResolveDecimalAdditionOrSubtractionOutput);
} else if (op == "multiply") {
out_type = OutputType(ResolveDecimalMultiplicationOutput);
} else if (op == "divide") {
out_type = OutputType(ResolveDecimalDivisionOutput);
} else {
DCHECK(false);
}
// 注册执行方法回调
auto in_type128 = InputType(Type::DECIMAL128);
auto in_type256 = InputType(Type::DECIMAL256);
auto exec128 = ScalarBinaryNotNullEqualTypes<Decimal128Type, Decimal128Type, Op>::Exec;
auto exec256 = ScalarBinaryNotNullEqualTypes<Decimal256Type, Decimal256Type, Op>::Exec;
DCHECK_OK(func->AddKernel({in_type128, in_type128}, out_type, exec128));
DCHECK_OK(func->AddKernel({in_type256, in_type256}, out_type, exec256));
}
通过 ResolveDecimalMultiplicationOutput 我们就确定了 Decimal 输出类型的具体 precision和scale.
到了 ExecuteScalarExpression时 会拿着上面注册的 ScalarBinaryNotNullEqualTypes<Decimal128Type, Decimal128Type, Op>::Exec 执行回调 来处理单个数值的乘法操作.
感兴趣的同学可以看一下 ScalarBinaryNotNullEqualTypes模版类的封装, 非常优雅, 其封装了所有数值类型的计算调度.
像是两个 DecimalArray 的计算会通过如下模版类中的函数进行调度:
Status ArrayArray(KernelContext* ctx, const ArraySpan& arg0, const ArraySpan& arg1,
ExecResult* out) {
Status st = Status::OK();
OutputArrayWriter<OutType> writer(out->array_span_mutable());
VisitTwoArrayValuesInline<Arg0Type, Arg1Type>(
arg0, arg1,
[&](Arg0Value u, Arg1Value v) {
writer.Write(op.template Call<OutValue, Arg0Value, Arg1Value>(ctx, u, v, &st));
},
[&]() { writer.WriteNull(); });
return st;
}
非常喜欢 VisitTwoArrayValuesInline 的封装, 虽然编译时类型展开会有极多的代码, 代码简洁优雅通用.
到此整个 Arrow Decimal 从表达式体系的执行到底层的数值表示和计算都介绍完了, 客观来说 Arrow 的可扩展性是非常的好.
总结
聪明的Decimal 类型完全解决了 double/float 这种二进制浮点类型的痛点, 能够完全正确得表示后者无法正确表示的数据, 当然代价便是更高的内存以及CPU消耗.
功能上来看, PG 的Decimal实现肯定是更为通用, 为了服务于高精度的TP场景, 通过牺牲较多的内存, 支持了小数点后3万多位以及小数点前13万位的表示, 这个精度是非常高的. 相反 Arrow 目前只能支持最高 256bits 78个十进制位, 精度肯定差不少, 但是对于 AP场景来说 小数点后数十位其实完全足够.
从性能上来看, 显然使用多个uint64_t 表示的 Arrow Decimal在数值计算的时候对 cpu-cache 更友好.
参考
- [1] PostgreSQL source codes: REL_12_STABLE
- [2] https://en.wikipedia.org/wiki/IEEE_754
- [3] Apache-Arrow source codes: commit 193e39cad4d8e1a01376d6b5199077e401484838
- [4] Arrow Compute Functions