文章目录
原文: Apache arrow 极致模块化、可组合的数据平台
背景
Apache-Arrow 是 Wes McKinney 大佬在2016年开启的一个项目, 用于解决 他创建的Pandas 的一堆问题.
Pandas最核心的几个问题如下:
- 缺少统一的内存数据管理方式, pandas每对接一个外部系统都需要单独实现一套数据转化工具, 比如将pandas的数据格式转为 spark的 dataframe, 性能极差.
- 内存数据处理无法高效利用现代计算硬件: CPU/GPU/FPGA, 比如向量化能力较差, 无法高效利用SIMD指令.
- 数据格式的扩展性较差, 因为都是耦合在 pandas内部(BlockManager).
- 大数据集的支持度不高, 数据处理以及传递链路上存在较多的内存拷贝, 导致一份数据集在内存中会放大多倍.
于是, Wes 在2015年和Kudu,Spark,Drill等项目出来的一些人和Apache 软件基金会, 从2016-2020年 Wes 分别创立了两家非营利性的数据科学公司 Ursa Labs 和 VoltronData, 并且后来拿到了1.1亿美金的首轮融资. 2023年11月 的时候 Wes选择从 VoltronData 卸任首席架构师加入到 Posit 继续全新的数据科学领域的一些新的挑战. 因为 Arrow 社区在 VoltronData 的把控下每一个子方向都有比较靠谱的负责人 且 未来的发展方向也都比较明确, Wes觉得交给他们没有什么问题, 如果自己继续呆在这里反而没法发挥自身最大的价值. 再加上 做 2016-2020年开发 arrow 期间 Wes也和 Posit的前身 RStudio 深度合作过, 利用 arrow 打通了 R语言 和 Python语言这两种数据科学领域顶级工具之间的数据交换通道, 也和 RStudio 的创始人 建立了深厚的感情(都是为了让数据科学领域更好的发展, 而不是争论到底python还是R 更适合做数据分析之类的无意义的争论).
Arrow 是 数据分析领域的资深大佬对整个数据计算体系的多年实践要解决的痛点下 诞生的, 从设计之初就是为了成为下一个数据科学领域的核心工具而存在, 未来数据分析领域是 arrow-native的.
基本架构
前面介绍了arrow 诞生的背景是服务于数据分析领域, Wes对 其基本功能的描述是 Arrow是用于加速内存数据交换和处理、支持多语言的工具集.

之前不同的数据处理系统之间都会有一套独立的数据转换方式 以及 传输过程中大量的数据拷贝, 如今都可以被 Arrow统一处理.
Arrow 在架构设计上也是走 LLVM 风格, 每一个组件都可以独立为用户所用. 因为考虑的是通用的计算平台, 组件内部拥有极强的可扩展性,组件之间又可以互相搭配使用.
基本组件如下图:

- 多语言支持: C++ 和 rust 都是语言native的(所有C++的功能都会同步到rust). 在这两种语言的基础上支持了更多的其他语言, 比如C++基础上支持C语言,又可以利用cgo和jni支持go以及java等.
- Columnar Format: 支持高性能的列式内存数据格式, 包括基本的类型系统以及完备的向量化的数据管理结构
- IPC protocols: 支持了进程间通信的数据格式且可以以 flatbuffer 的扁平格式写入到文件. 加速进程间通信的数据读取/写入 以及 零拷贝传输.
- Query Engine Components: 支持了计算引擎需要的一些基础组件. 比如 compute下的一些向量化的计算Function, Function之上的 Expression 表达式处理框架, 还有C++库实现的 Acero 以及 Rust库实现的 DataFusion 计算引擎, 并且支持了像是 scan/sort/hashjoin/agg/project/filter 这样的算子. 再结合 substrait 这样的可以识别逻辑查询计划的组件, 就能够将arrow的计算能力接入到各种各样的分析性数据库中, 简直不要太爽.
- IO / File Format Backends: Arrow 支持了基本的文件格式 和 文件数据的访问源. 比如 parquet/ORC 这样的列存文件格式 从 S3/HDFS 等远端存储读取.
- Flight & FlightSQL : 跨服务器的网络传输协议, Flight拥有 RPC 能力, FlightSQL 结合 ADBC 可以零拷贝的SQL协议.
- JIT Expression Compilation: Gandiva 子项目 结合 LLVM-JIT 功能实现了 Arrow 表达式执行期间的Runtime和SIMD优化.
这一些组件内部都是可以扩展的, 比如 Expression 框架下可以快速扩展自己的function, Acero 内部的 ExecNode也可以扩展自己的算子; 而且这一些组件之间是可以组合的(比如 内存格式+表达式计算框架), 从底层的数据读写 到上层的query执行 + FlightSQL 全链路都可以是零拷贝的高性能.
没错, 这一些你都可以直接白嫖!
Columnar Format
Arrow 的内存格式以及相关的数据结构和周边计算功能的设计都是服务于列式内存格式的.

列式数据的内存表示可以用一块连续的内存区域来表示拥有相同类型的一列数据, 这样就能够更加高效得利用 CPU-cache 以及 SIMD指令.
Arrow 在内存格式的设计中主要有几个数据结构:
Buffer. 数据内存格式存储实际数据的最底层数据结构, 主要维护了一段连续的内存区域.主要有以下几个字段:
const uint8_t* data_; // 表示一段连续内存区域的字节数组 且不保存实际的数据 // 仅指向一个实际数据存储区域的地址,实现数据访问的零拷贝. int64_t size_; // 这段连续内存区域有效数据的大小 int64_t capacity_; // 这段内存区域分配的空间大小, size和capacity之间可以填充0除了这几个字段之外, 还有像是
is_cpu_这样的标识,用来区分 GPU/CPU device, 只有cpu能够利用 Buffer 提供的随机访问的能力. Buffer 提供了一些 比如Slice 这样的接口, 用户提供 offset+length 就可以随机访问任意一份Buffer区域的数据. 也提供了一些修改/拷贝 Buffer数据的接口, 方便用户对当前数据做一些独立性的操作.需要注意的是Buffer 本身并不提供内存对齐的能力, arrow 通过
MemoryManager来管理buffer 占用的内存区域, buffer初始化时指向的内存是否对齐会由MemoryManager来决定. 除了基本的Buffer之外还提供了像是ResizableBuffer和MutableBuffer用来对buffer 指向的数据或者存储空间进行操作.类型系统 DataType 和 Array.
DataType是Arrow提供的一套通用的类型系统,支持了:- Scalar Types(单值类型) :
- Boolean
- [u]int[8,16,32,64], Decimal, Float, Double
- Data, Time, TimeStamp
- UTF8, String, Binary
- …
- Nested Types(嵌套类型) :
- Struct
- List
- Union
- Map
…
- Dictionary Type 字典类型
- REE(Run-Ended Encoding) Arrow将这种重复值较多的数据集编码方式也作为了一个单独的数据类型.算是嵌套类型的一种.
- UDT(User Defined Types)
- Scalar Types(单值类型) :
这一些数据类型的基础数据结构如下:
/*
* ListType LargeListType FixedListType
* │ │ │
* │ ▼ │
* └───────► BaseListType◄────┘ StructType UnionType RunEndEncodedType
* │ │ │ │
* │ │ │ │
* └───────────────────┴───►NestedTyp◄────┴───────────────────┘ ExtensionType
* │ │
* │ │
* └──────────────► DataType ◄─────────────────────┘
* ▲
* │
* ┌────────────────┬──────────────────────┬────►FixedWidthType ◄───┬─────────────────────┬─────────────────┐
* │ │ │ │ │ │
* │ │ │ │ │ │
* │ │ │ │ │ │
* DictionaryType PrimitiveType ┌─►NumberType◄──┐ TemporaType FixedSizeBinaryType BaseBinaryType
* │ │ ▲ ▲ ▲ ▲
* │ │ │ │ │ │
* IntegerType FloatingPointType ┌─►DateType◄──┐ DecimalType StringType LargeStringType
* │ │ ▲ ▲
* │ │ │ │
* Date32Type Date64Type 128Type, 256Type
*/
自 DataType 继承的各种数据类型已经按照分类划分好了, 每一种数据类型对应的 Array数据部分的存储内存布局则是由 DataTypeLayout 决定, 主要的几种 layout 布局如下:
- FIXED_WIDTH 单值定长类型, 只需要有一个buffer保存就好了, 根据offset就能取值
- VARIABLE_WIDTH 变长类型, 需要两个buffer, 一个保存值的len, 另一个保存原值.
- BITMAP, bitmap buffer, 保存是否有空值
- ALWAYS_NULL 全为空
每一种 DataType 可能是以上几种的组合, 比如
BinaryType, 其layout 如下:
return DataTypeLayout({DataTypeLayout::Bitmap(),
DataTypeLayout::FixedWidth(sizeof(offset_type)),
DataTypeLayout::VariableWidth()});
DataTypeLayout 仅表示基本的Scalar类型有内存布局, 嵌套类型是在 Scalar 类型的基础上通过维护嵌套的父子关系来实现 嵌套类型, 具体实现是
ArrayData数据结构提供的child_data字段, 保存当前ArrayData的孩子 ArrayData 数组. 这样所有的嵌套类型都可以用统一的方式来管理其内部拥有上下级关系的单值类型的数据.
再看看 Array 这个结构, 而DataType可以理解为数据的描述信息, Array则直接保存列式的数据, 每一个Array对应一个 DataType描述的列式数据, Array的底层管理了一个或者多个Buffer, 选择的Buffer布局是根据运行时前面描述的 DataType::layout() 决定的.
如下是一个实际运行时Array的基本结构:

实际的数据管理结构是 ArrayData, 对于每一种前面介绍到的数据类型都会有对应的 Array(比如 StringArray, NumericArray – 处理数值类型的数据存储等) 以及 ArrayBuilder.
像是 DictionaryArray, 会有一个 indices int类型的数组来标识原本Array中值在 dicionary Array中的序列, 以及 实际的压缩后的数值类型的Array.
// 如下 StringArray:
["foo", "bar", "foo", "bar", "foo", "bar"]
// 存储为字典类型时的两个Array如下:
dictionary: ["bar", "foo"]
indices: [1, 0, 1, 0, 1, 0]
RecordBatch 和 Schema. RecordBatch 是一个或者多个 不同DataType 但是相同长度 Array 的集合, Schema 则是 RecordBatch 用来管理这一些Array类型的结构, 同时提供基本的描述信息的扩展.
如下图: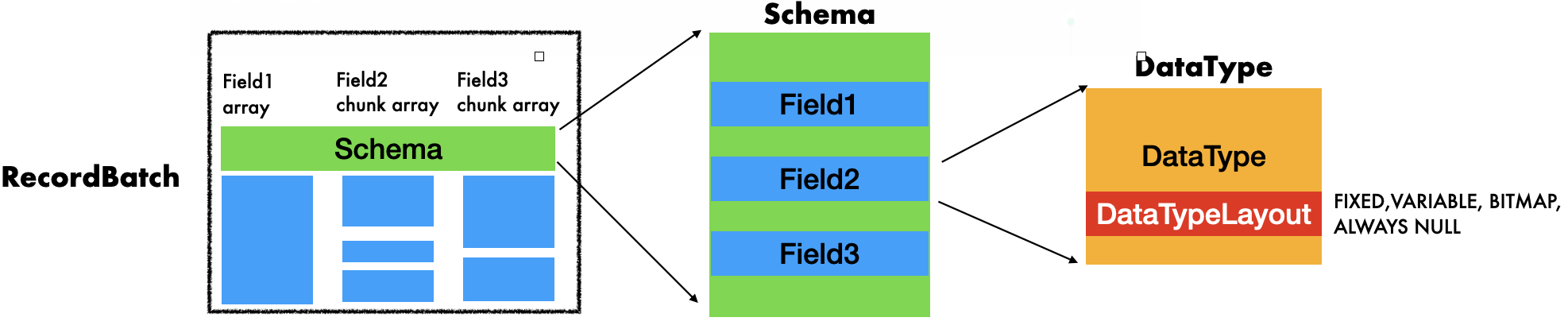
一个 RecordBatch中的 Array或者ChunkArray 在schema中 会有一个对应的 Field来描述这个 Array, Field会记录这个Array 被用户指定/从文件读取到的列名 以及 列 DataType; 多个Field 会统一由一个Schema的结构管理起来,Schema也提供了扩展列属性描述信息的key/value 形态的metadata.ChunkArray则是统一管理相同类型但是不同来源的 Array, 同一个Chunk内部的不同Array中存储数据的Buffer 在内存上是不连续的.Table. 这是后期为了查询引擎/Flight SQL 提供的一种在RecordBatch/ChunkedArray基础之上的一个内存结构,方便在内存中表示一个数据库中的数据表结构.
IPC format
IPC format是服务于进程间通信的内存格式, 用于序列化 多个 RecordBatch为二进制字节流, 并且能够在其他进程将该字节流反序列化为recordBatch, 从而让数据在不同的进程之间交换 且这个过程是不需要内存拷贝的. 本质上操作的还是 RecordBatch 对同一份数据的引用.
arrow 的 ipc format主要以stream 方式发送二进制字节流,其中ipc的metadata部分会以flatbuffer的形式封装如下几种 recordbatch:
- Schema
- RecordBatch
- DictionayBatch
ipc-format 体系中 arrow提供了三种format:
- Encapsulated message format, 这种格式的消息数据被当前进程接收到之后可以将metadata部分的数据通过 zero-copy的方式反序列化到内存.
- IPC Streaming format 则是由多个 Encapsulated message format messages组成的消息序列. 其中第一个 Encapsulated message format 主要传输 Schema 数据, 后续的多个messages则是拥有相同schema的 recordbatch messages. 可以高效跨进程处理stream式的数据.
- IPC File Format 则是在Streaming format的基础上增加了一些可以持久化到文件的编码格式, 比如 magic number 以及 footer. 最主要的是将 streaming format持久化到文件, 可以提供文件级别 对 recordbatch 的随机访问.
Encapsulated message format 的消息编码如下:
<continuation: 0xFFFFFFFF>
<metadata_size: int32>
<metadata_flatbuffer: bytes>
<padding>
<message body>
- continuation 如果是 0xFFFFFFFF 表示一个有效的消息.
- metadata_size, 元数据大小, 默认用小端编码
- metadata_flatbuffer, 是用flatbuffer 编码的元数据体.具体类型可以在
message.fbs中能找到. 主要包括对Schema, dictionary Batch, 以及 RecordBatch的描述. - padding 是可以在metadata数据之后padding 0, 来8bytes对齐
- message body 是真正的消息体, 需要8bytes对齐
flatbuffer 编码的是紧凑的二进制数据,可以节省很多的存储空间 并且能够支持在编码好的数据内快速访问和操作数据. 但是flatbuffer 只能发送扁平的数据, 对于 arrow的一些嵌套类型, 在传输之前需要先flatten, 比如下面schema:
col1: Struct<a: Int32, b: List<item: Int64>, c: Float64>
col2: Utf8
flatten之后的形态如下:
FieldNode 0: Struct name='col1'
FieldNode 1: Int32 name='a'
FieldNode 2: List name='b'
FieldNode 3: Int64 name='item'
FieldNode 4: Float64 name='c'
FieldNode 5: Utf8 name='col2'
IPC Streaming format 消息编码如下:
<SCHEMA>
<DICTIONARY 0>
...
<DICTIONARY k - 1>
<RECORD BATCH 0>
...
<DICTIONARY x DELTA>
...
<DICTIONARY y DELTA>
...
<RECORD BATCH n - 1>
<EOS [optional]: 0xFFFFFFFF 0x00000000>
每一个<> 符号内部都是一个 Encapsulated-message-format的消息体, streaming format 希望发送一批拥有相同schema的数据, 则会先发送一个schema message, 如果当前schema里有可以字典编码的message, 则后续发送的数据中会有字典编码的 DictionaryBatch.
IPC File Format 消息编码如下:
<magic number "ARROW1">
<empty padding bytes [to 8 byte boundary]>
<STREAMING FORMAT with EOS>
<FOOTER>
<FOOTER SIZE: int32>
<magic number "ARROW1">
File-format (arrow内部也叫 Feather V2 或者 Feather V1的扩展)是在 streaming format的基础上增加了一些要存储到文件的标识, 比如 footer 以及 magic number.
Footer里面有一些schema以及datablock 的offset/sizes 信息, 这一些信息能够支持对文件内部任意recordbatch的随机访问.
Footer的 flatbuffer 编码格式被放在了 File.fbs中.
Arrow Flight
Arrow-Flight 是在 grpc 和 ipc-format(确切得说应该是 ipc streaming format)的基础上构建的 高性能网络通信框架.一些 rpc的方法和消息的格式定义也都是通过 protobuf, 虽然protobuf本身因为有过多的编码以及传输过程的数据拷贝, 其并不适用于大量数据的传输, arrow这里仍然使用protobuf的原因是简化编码格式的同时利用 ipc-format减少数据传输过程的数据拷贝 以及 序列化和反序列化的开销, 从而极大得提升了大数据量下的rpc性能, 并为 Flight-SQL 的高性能做铺垫.
如下图, 利用 Arrow-Flight 利用rpc-client和rpc-server 从远端下载数据:
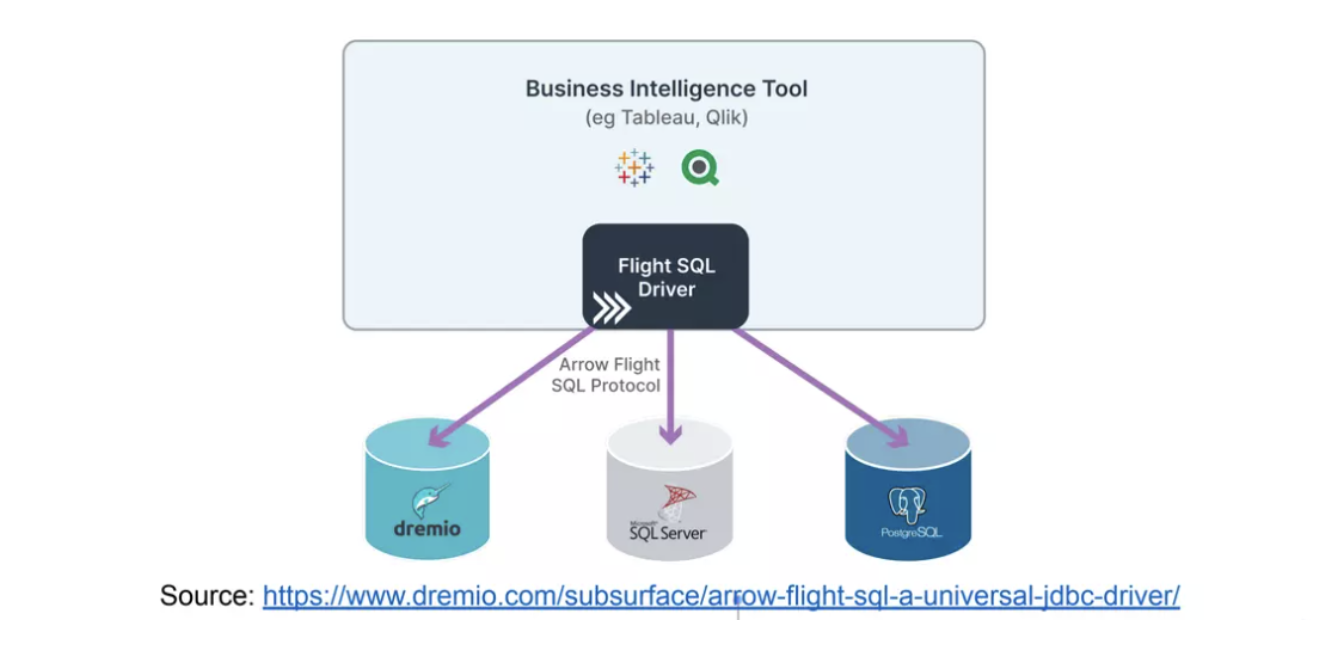
主要利用了在 flight.proto 文件中定义的一些service操作:
rpc GetFlightInfo(FlightDescriptor) returns (FlightInfo) {}能够获取要访问的数据节点的一些 endpoints 连接信息或者一些元数据信息等, 这一些信息会被作为FlightInfo返回.FlightDescriptor则是进行连接时的客户端要访问数据的唯一标识, 比如要访问的数据路径/SQL命令等.rpc DoGet(Ticket) returns (stream FlightData) {}实际下载数据的rpc 操作. 如果前面拿到的FlightInfo有多个endpoints, 则这一步可以并发进行. 数据会以 ipc-stream format的方式存储到FlightData返回给客户端.FlightData中定义的数据格式比如data_header就是 messages的类型(schema/DictionaryBatch/RecordBatch?).app_metadata自定义的一些应用的元数据信息.data_body是实际的batch数据.
Arrow-Flight Rpc除了基本的跨网络数据通信功能, 也提供了基本的通信过程中验证能力:
- 通过 Mutual TLS (mTLS) 的加密证书来验证 “Handshake” authentication
- 基于消息头部或者消息体中间部分的通信验证 来决定server是否接受连接请求.
Arrow-Flight 除了 grpc 之外还支持了 UCX 的rpc通信能力, UCX目前还在实验中, 并没有支持grpc所支持的所有 rpc能力. UCX 的主要优势是利用硬件资源换取吞吐, 对于每一个client的连接请求, UCX可以在client以及 server都各启动一个 UCP worker进行rpc的独立通信. 而不是像 grpc 可以通过一个线程 poll 的方式处理所有来自客户端的 rpc请求. 端对端的通信可以让硬件资源被通信线程独占, 从而提升传输效率. 所以 UCX rpc 适用于并发连接较少的场景.
Arrow-Flight 除了支持 grpc和UCX 之外, 也可以通过 arrow::flight::internal::ClientTransport 以及 arrow::flight::internal::ServerTransport 扩展更多的 rpc实现.
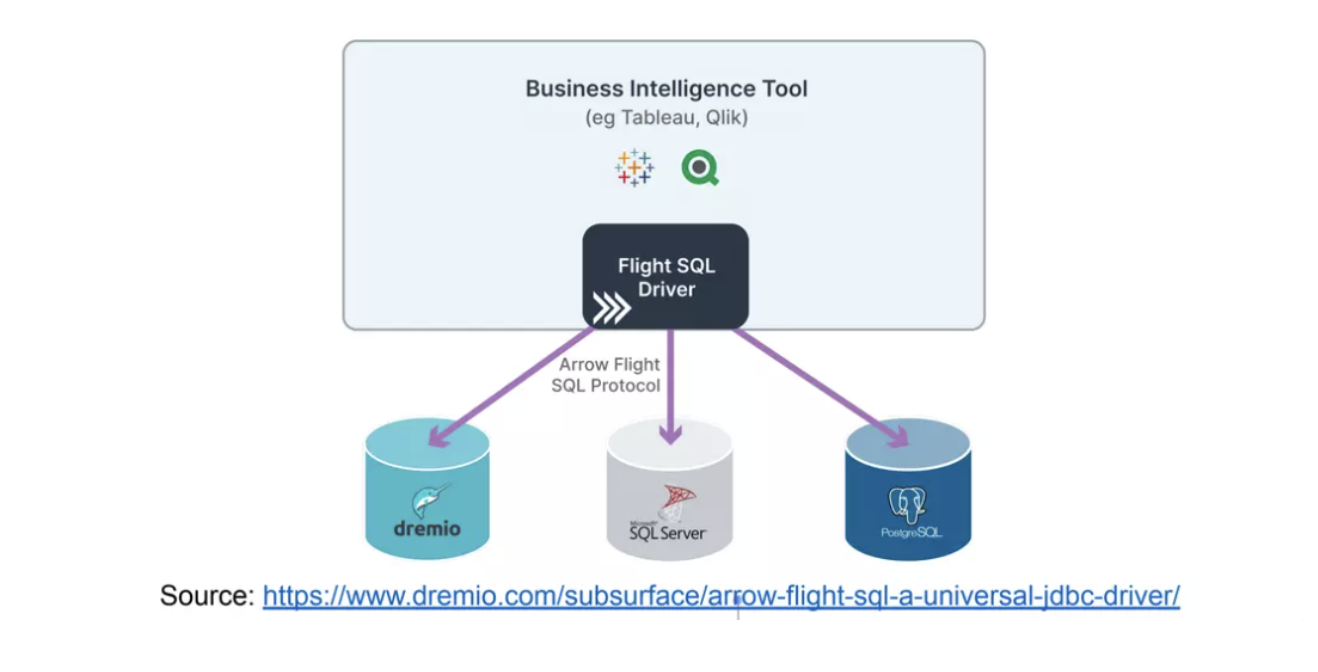
Arrow Flight SQL
Flight-SQL 是在 Flight-RPC 的技术上实现的具有 SQL 语义的通信操作, 前面介绍 Flight-RPC 操作的时候提到一个 pb结构叫做 FlightDescriptor, 它内部支持的 cmd就是为 Flight-SQL预留的 sql操作的接口.
Arrow 除了 Flight-SQL, 也提供了更靠近客户端的 ADBC 以及 JDBC-Conveter, 这样从客户端就可以通过 JDBC-Driver 下发 SQL查询命令, JDBC可以通过ADBC 高效得按列执行 Flight-SQL 并高效得提取返回的列数据.
对于Flight-SQL而言可以对客户端屏蔽底层的数据库(目前这一块 arrow 有一个 substrait项目来统一封装), 只需要在 Flight-SQL层实现对应数据库的Server就可以了. 用户下发统一的SQL查询命令, 并通过Flight-SQL 利用Flight-RPC client分发到自己实现的对应数据库的Server 中进行执行, 将执行的结果通过 Flight-SQL 返回给用户.
大体形态如下:
对于Flight-SQL的基本使用, 以下代码就很清晰了:
// 设置要连接的 flight-server 的ip和端口
ARROW_ASSIGN_OR_RAISE(auto location,
flight::Location::ForGrpcTcp(FLAGS_host, FLAGS_port));
std::cout << "Connecting to " << location.ToString() << std::endl;
// 启动 flight-sql的客户端
// 其底层还是一个 Flight-RPC 的client用于通信
std::unique_ptr<flight::FlightClient> flight_client;
ARROW_ASSIGN_OR_RAISE(flight_client, flight::FlightClient::Connect(location));
std::unique_ptr<flightsql::FlightSqlClient> client(
new flightsql::FlightSqlClient(std::move(flight_client)));
// 设置要执行的 SQL query cmd 并从 server 获取要访问的数据节点的endpoints信息
flight::FlightCallOptions call_options;
ARROW_ASSIGN_OR_RAISE(std::unique_ptr<flight::FlightInfo> flight_info,
client->Execute(call_options, FLAGS_query));
// 并发从多个数据节点提取数据,并转为 table格式
for (const flight::FlightEndpoint& endpoint : flight_info->endpoints()) {
ARROW_ASSIGN_OR_RAISE(auto stream, client->DoGet(call_options, endpoint.ticket));
ARROW_ASSIGN_OR_RAISE(auto table, stream->ToTable());
}
不过对于单机数据库, arrow并没有实现通用的flight-sql接口, 像 PostgreSQL 这样的按行存储和访问的数据库直接使用 flight-sql 这样的为列式数据服务的协议并不合适, 所以 arrow社区单独开发了一个 arrow-flight-sql-postgres 来做一些性能验证. 目前是利用 PG 的 SPI 执行query 并将输出的结果行转为 arrow的列式格式(Array/RecordBatch)通过 Flight-SQL协议进行输出, 在数据量较大的情况利用 flight-sql的传输方式比 原本PG用libpq协议传输到client性能提升了2-3倍.
C Interface Support
Arrow为了让其他的数据库系统更方便得使用自己的列式内存格式, 提供了 C-API.
简单介绍一下C 接口的一些优势:
- ABI-Stable, C 接口是最稳定的接口
- 无需依赖 Arrow的任何一个语言实现, 只需要依赖C接口的lib库就可以通过C接口使用arrow的内存格式.
- 接口语义上一致性且跨平台兼容. Arm上运行的C-API接口可以在X86上同样运行, 维护起来就很方便了.
一个库想要让自己通用, C-API一定是少不了的. 比如foundationdb用C++实现的内核,对与C-API的支持度基本是100%.
Arrow的 C-API 就是被 duckdb/velox 这样的数据库引擎使用, 用于内部兼容Arrow的内存格式.比如Arrow支持的不同语言的客户端可以通过 (cgo)C-API 将来自客户端的arrow列式数据导入不同的计算引擎进行计算. 这对于一个数据平台来说非常重要, 像是go/python/java这样的用户极多, 而它们能够利用 arrow的 C-API来与不通的计算系统进行交互, 这个能力对用户来说还是有非常大的吸引力.
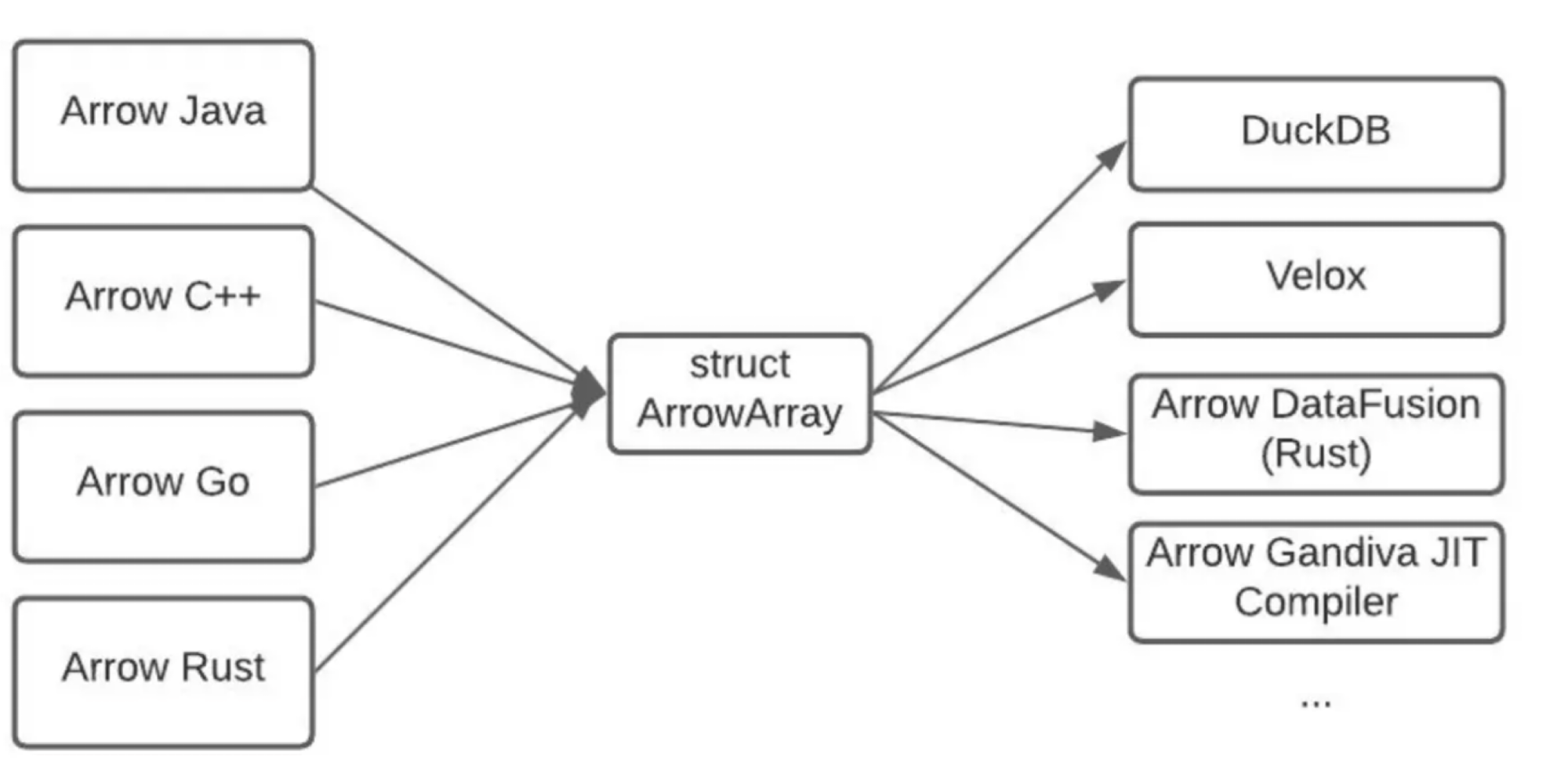
C-API中对 Array的封装如下:
struct ArrowArray {
// Array data description
int64_t length;
int64_t null_count;
int64_t offset;
int64_t n_buffers;
int64_t n_children;
const void** buffers;
struct ArrowArray** children;
struct ArrowArray* dictionary;
// Release callback
void (*release)(struct ArrowArray*);
// Opaque producer-specific data
void* private_data;
};
使用起来还是非常方便的, 且可以通过每一种语言 类似cpp实现的 bridge.h 提供的一批接口来做 ArrowArray C–>C++/Go/Java结构的转换. 在C接口侧, 用户也可以通过 release 回调函数来 控制 Array 的生命周期.
Compute & Acero
Arrow 的compute 用于处理 in-memory 列式数据计算的; Acero则是一个 C++版本的 push形态 查询执行引擎, 用于处理 stream式的列式数据. 前者需要数据都在内存中才能处理,后者则不需要,只关注当前处理的in-memory数据.
Compute
compute的核心是一个表达式处理框架, 这个需求来源于像是pandas/dplyr/DBMS 等需要做频繁复杂的数据处理和数据计算的系统.
Expression 表达式的执行需要三种数据结构, 如下代码已经很清晰了:
explicit Expression(Call call); // 函数调用体系
explicit Expression(Datum literal); // 常量体系, Datum 可以由scalar,array, chunked_array,
// recordbatch, table 构成.
explicit Expression(Parameter parameter); // 函数参数体系
数据体系
arrow 用 literal(Datum lit)来描述一个 引用了 Datum 的表达式,一般用于表示常量. 比如 y * 3 + x, 其中 y和x 都会用 Parameter 中的 FieldRef来表示, 只有 3 这个常量需要用 literal(3)表示.
函数参数体系
parameter 管理的是列引用. 主要的作用是说能够从实际计算时输入的recordbatch的schema中找到要操作的列, 把这个列引用和函数以及常量体系Bind起来, 完成统一的计算.
struct Parameter {
FieldRef ref; // 管理 field的 引用
// post-bind properties
TypeHolder type; // 这个 field 的数据类型
::arrow::internal::SmallVector<int, 2> indices; // 这个field 在后续输入数据的schema中的位置
};
对于parameter的处理可以直接关注 bind 的逻辑, 在表达式处理实际的batch数据之前需要先通过 bind 确保 parameter 这里管理的 FieldRef是schema中正确的位置, BindImpl中下面的这段逻辑就很清晰了.
if (const FieldRef* ref = expr.field_ref()) {
ARROW_ASSIGN_OR_RAISE(FieldPath path, ref->FindOne(in));
Expression::Parameter param = *expr.parameter();
param.indices.resize(path.indices().size());
std::copy(path.indices().begin(), path.indices().end(), param.indices.begin());
ARROW_ASSIGN_OR_RAISE(auto field, path.Get(in));
param.type = field->type();
return Expression{std::move(param)};
}
当然 BindImpl 本身的逻辑还有递归处理函数调用 Call的体系,因为函数Call 也有自己的参数, 参数也会有多个Expression组成, 这些Expression的parameter 部分都需要确保完成BindImpl.
函数调用体系
表达式处理框架 最复杂最核心的也就是函数调用体系的管理. 函数体系的管理除了需要支持数以百计各种类型function之外还需要支持 UDF.
函数调用体系在 Expression 的管理结构如下:
struct Call {
std::string function_name; // 函数名
std::vector<Expression> arguments; // 函数参数
std::shared_ptr<FunctionOptions> options; // 函数options
...
// post-Bind properties:
std::shared_ptr<Function> function; // 函数对象
const Kernel* kernel = NULLPTR; // 函数执行时需要的必要信息管理, 比如输入输出类型,实际的执行函数对象.
std::shared_ptr<KernelState> kernel_state; // 函数执行时额外的信息管理
TypeHolder type;
...
}
我们从最简单的UDF的注册来看一下如何将一个 Function 添加到 kernel 并可以被以在任何地方以 call("name",xxx) 的方式调用.
const std::string name = "add_three"; // 函数名
auto func = std::make_shared<cp::ScalarFunction>(name, cp::Arity::Ternary(), func_doc); // 构造一个函数对象
cp::ScalarKernel kernel({arrow::int64(), arrow::int64(), arrow::int64()},
arrow::int64(), SampleFunction); // 构造这个function 对应的kernel: 参数输入类型,输出类型,std::function对象
...
ARROW_RETURN_NOT_OK(func->AddKernel(std::move(kernel))); // 将kernel和函数对象绑定
auto registry = cp::GetFunctionRegistry(); // 获取函数注册器
ARROW_RETURN_NOT_OK(registry->AddFunction(std::move(func))); // 将函数对象注册到注册器中
...
ARROW_ASSIGN_OR_RAISE(auto res, cp::CallFunction(name, {x, y, z})); // 调用函数
其中比较关键的主要是两个结构: FunctionRegistry 和 ScalarKernel, 前者通过 unordered_map 建立从name->function对象的映射,来管理整个compute 所有的function, 可以快速得通过函数名拿到函数对象, 并且提供新函数注册、函数重命名的方法. 后者则用于和函数对象绑定, 管理函数运行时需要的状态数据.
对于前者, 我们能够从 CreateBuiltInRegistry() 函数中看到大量的 arrow builtin 的function如何被注册 以及这一些function被哪一些kernel管理.
kernel的设计是真的有趣,毕竟要支持数十种类型以及数百个复杂度不一的function. 要管理好这一些函数运行时的状态信息需要非常良好的代码框架设计.
Kernel基类的设计很简单, 抽象好可以公用的数据结构就好了:
std::shared_ptr<KernelSignature> signature; // 用来描述函数的输入输出的 Arrow 数据类型
KernelInit init; // 初始化 KernelState, 尤其进一步抽象管理 function 的状态,
// 比如 ScalarAggregator 管理的 agg function
bool parallelizable = true; // 确认是否开启函数并发执行, 比如将输入的 batch
// 拆分为多个小的chunk batch, 每一个batch由一个线程调度
SimdLevel::type simd_level = SimdLevel::NONE; // simd指令的级别
std::shared_ptr<KernelState> data; // 前面提到的更进一步的函数管理上的抽象
在这个 Kernel 的基类下继承了四种kernel类型:
- ScalarKernel 用于管理单值类型的计算函数, 其内部主要通过
ArrayKernelExec exec保存函数的std::function对象. - VectorKernel 管理聚类计算的函数, 除了基础的
ArrayKernelExec exec;之外还有 处理 chunked-array的ChunkedExec函数对象, 以及最终做数据聚合的FinalizeFunc函数对象. - ScalarAggregateKernel 管理单值聚集函数, 包含了三个聚集函数的函数对象:
consume,merge,finalize - HashAggregateKernel 管理 hash聚集函数
像前面介绍的UDF, 生成ScalarKernel的时候绑定需要的信息(管理输入输出类型的 KernelSignature、std::function的函数对象), 最后通过 AddScalarKernel 和kenel对应的函数对象绑定就好了.
从 kernel 出来之后函数的管理体系就被转交给 Function 对象了. Kernel管理实际的函数运行时的状态, Function 用于管理以及执行Kernel.
所以其维护的函数信息更多是对接外部调用的, 比如 FunctionDoc,FunctionOptions,Arity(函数参数个数), name(函数名). 这个函数对象可以由 FunctionRegistry 管理并被更上层的Computue用户使用, 也可以直接被 表达式框架通过 Call 体系使用.
Acero 则在之前的一篇文章中有过介绍, 可以简单看一下 HashJoin 在Apache Arrow和PostgreSQL 中的实现, 总的来说有几个优势:
- Arrow 内存格式下 C++ native 的查询执行引擎
- Push 模型 + 零拷贝的ExecBatch调度, 对向量化处理非常友好
- 可扩展性强, 执行节点是插拔式的. 实现自己的版本只需要实现几个接口就可以了.
劣势:
- 仅支持单机内存足量的执行, 不支持 spill.
- 数据库算子功能不全, 比如merge-join/nested-loop/MV 节点等.
- pipeline过于简单, 无法分布式执行.
这一些"劣势" 也只是功能上不完备而已, 需要大家一起努力建设, 但是 Arrow-native的生态已经有足够的吸引力来让初创节省大量的前期人力成本, 后续也会有足够的人力去投入到 Acero的建设中, 就像现在的 Arrow-rust 社区贡献的Datafusion 也让更多的 rust 数据库体系加入到了 DataFusion的贡献中.
Substrait
Substrait 拥有如下几种功能:
- 一个标准的表达式计算请求的中间层
- 一个公共的接口层来让用户通过统一的API使用不同的计算引擎后端, 计算请求由前端的用户API产生,被后端的引擎消费.

Gandiva for CodeGen
Gandiva 是利用LLVM JIT 编译执行来做一些 runtime的优化, 目前仅实现了project/filter 以及 compute function体系的编译优化.
之前也系统得介绍过 LLVM-JIT 在postgresql的应用, 利用编译器的能力来进一步提升性能是非常合理的. 毕竟像是JIT这样的编译运行本质上是利用cpu来换取更多的性能, 尤其在向量化以及列存的场景JIT在 runtime 所做的一些执行逻辑裁剪以及全局代码优化能够更好得利用CPU-Cache 以及 SIMD.
不过有很多人说 Gandiva已死之类的(因为仅支持的compute-function部分,并没有支持 Acero), 这里个人持不同的观点. Gandiva 或者说 JIT 应用的场景肯定是在整个查询引擎相对稳定的情况下去做才会有最大的收益 以及 最低的维护成本. 至少目前 PG 的JIT实现在Andres 实现了第一个版本之后基本不会有太大的变动,只是偶尔兼容一下 LLVM 的新版本 以及修一些bug.
所以 JIT 本身的特性就决定了其大规模的开发场景应该是在整个执行器 的架构和性能基本稳定之后才会去投入. 像现在的 Gandiva 也是在compute 稳定之后才加入的JIT能力, 对于compute-function本身调度后续也基本不会有太大的变动, 也是合理的. 但是 Acero目前无论是功能还是性能都还需要快速迭代, 所以很难快速的将JIT能力应用上, 这块还是需要大家多多关注, 持续投入才行.
Gandiva的基本执行架构如下:
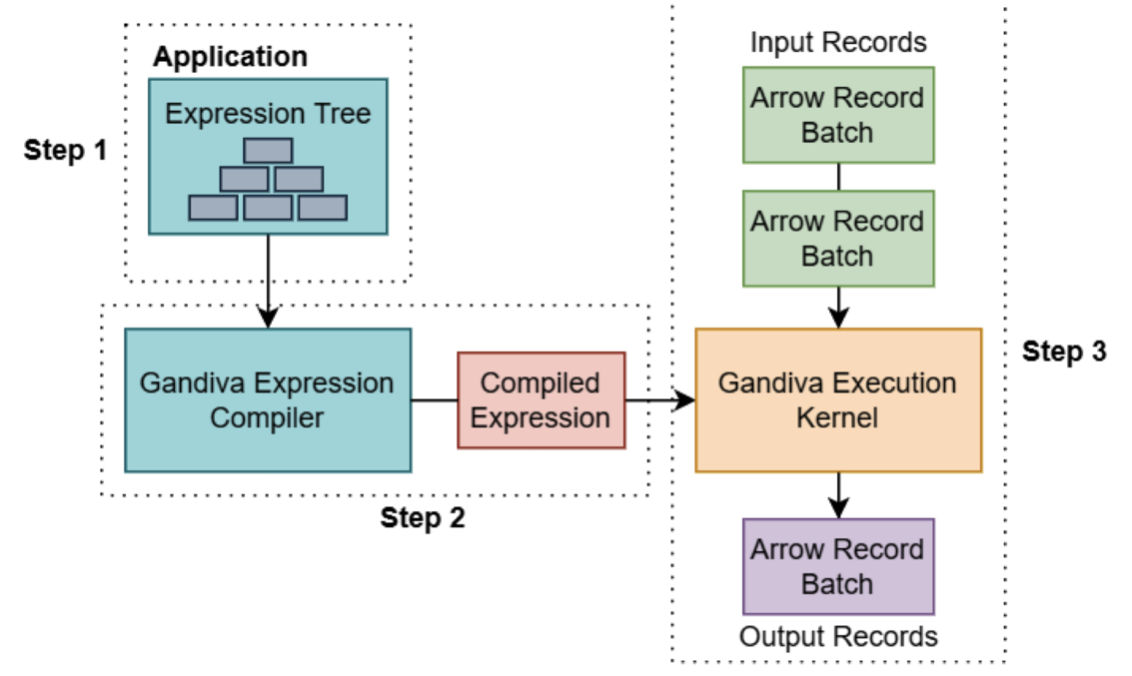
主要还是分为三步:
- 编译代码期间 利用 LLVM 前端工具clang 将compute-expression 体系相关的代码编译为 llvm bitcode 这种磁盘IR格式.
- 执行 compute-expression时 gandiva先 加载 bitcode 到内存中进行 expression 表达式的执行代码编译, 生成LLVM-IR 的内存格式(以 Module形态进行管理).
- 执行 编译好的 Expression代码, 利用LLVM-Pass不断得对执行代码进行后端优化, 因为此时已经能够拿到runtime的 record-batch数据, LLVM-Pass优化后就能够极大得减少代码的执行分支 以及 优化执行指令(比如 mem2reg,将对内存的访问转为对寄存器的访问).
总结
本文完整得介绍了 ARROW 如何利用自己的极致模块化以及可组合的能力 在列式数据的存储以及分析领域成为业界标准.
Arrow提供的下面几个核心设计能够节约大家至少数十个人年的时间:
- 高效且可扩展的内存格式. 那一套稳定且可扩展的类型系统 以及 对应的数据管理体系对人力的质量以及时间都有极高的要求.
- 对计算硬件支持度较高. 支持 CPU/CUDA/METAL/ROCM等计算硬件的特殊优化, 并且语言无关, 这样加速硬件的接入也就不需要过多的人力投入. 比如 可以用go语言的cgo 调度 CUDA 对 列存数据的处理.
- 高效的数据交换体系. 比如 支持了IPC、Flight 以及 FlightSQL. 数据从底层的parquet/orc 走IO到本机内存 到跨进程 再到跨服务器都可以用同一套数据格式,可以实现全链路零拷贝.
- 计算体系支持了嵌入式的计算引擎和表达式处理框架, 并且拥有良好的可扩展性 以及 SIMD 有好的性能. 在Acero中扩展新的算子或者在Function中增加UDF 都是非常容易的事情.