声明:案例只用于学习,不得恶意使用
要求:获取直播间标题、类型、主播、热度,并实现翻页
定位随着网站更新可能不会实现,请自行更改
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
import time
chrome_options = Options()
chrome_options.page_load_strategy = 'eager'
service = Service('chromedriver.exe路径')
class Douyu(object):
def __init__(self):
self.url = 'https://www.douyu.com/directory/all'
self.driver = webdriver.Chrome(service=service, options=chrome_options)
self.driver.implicitly_wait(5)
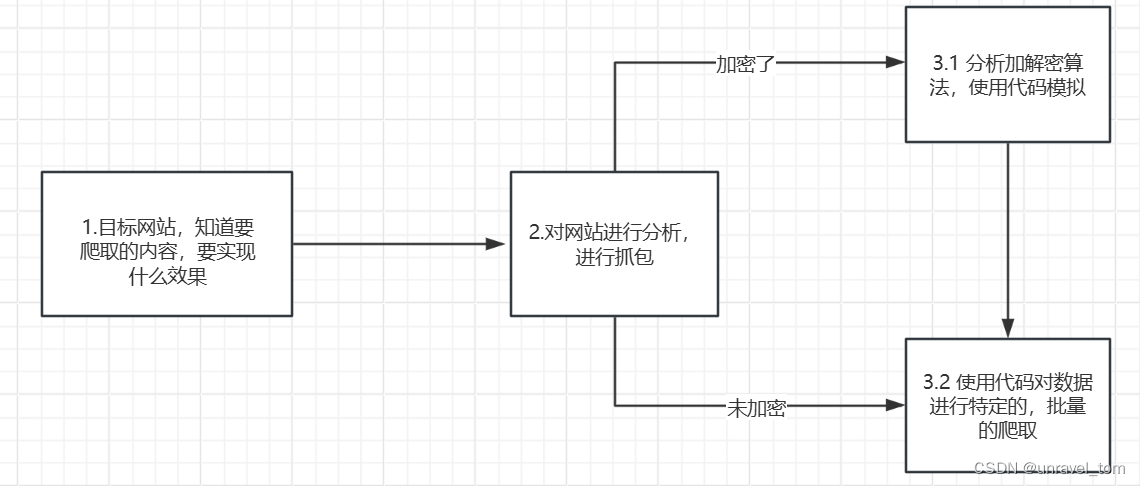
def parse_data(self):
time.sleep(3)
data_list= []
# 遍历房间列表,从每一个房间节点中获取数据
for i in range(1,121):
temp = {}
temp['title'] = self.driver.find_element(By.XPATH, f'//li[{i}]/div/a/div[2]/div[1]/h3').text
temp['type'] = self.driver.find_element(By.XPATH, f'//li[{i}]/div/a/div[2]/div[1]/span').text
temp['owner'] = self.driver.find_element(By.XPATH, f'//li[{i}]/div/a/div[2]/div[2]/h2').text
temp['num'] = self.driver.find_element(By.XPATH, f'//li[{i}]/div/a/div[2]/div[2]/span').text
data_list.append(temp)
return data_list
def save_data(self,data_list):
for data in data_list:
print(data)
def run(self):
self.driver.get(self.url)
while True:
data_list = self.parse_data()
self.save_data(data_list)
try:
el_next = self.driver.find_element(By.XPATH, '//*[@title="下一页"][@aria-disabled="false"]')
self.driver.execute_script('scrollTo(0,1000000)')
el_next.click()
except:
break
if __name__ == '__main__':
douyu = Douyu()
douyu.run()































![[数据集][目标检测]鱼头鱼尾检测数据集VOC+YOLO格式200张2类别](https://img-blog.csdnimg.cn/direct/ba4e005aa56d478896de05a80905d234.png)
