一、ORACLE简介
(一)什么是ORACLE
分布式数据库
ORACLE(甲骨文)公司研发的
C/S 或 B/S 体系结构的数据库
特点:
(1) 支持多用户、大事务量的事务处理
(2) 数据安全性和完整性控制
(3) 支持分布式数据处理
(4) 可移植性(跨平台,支持不同操作系统上使用)
(二)ORACLE体系结构
1、数据库
Oracle只有一个大数据库,跟别的数据库概念不一样
2、实例
一个Oracle实例有一系列的后台进程和内存结构组成。一个数据库可以有n个实例。
3、数据文件
数据文件是数据库的物理存储单位。数据库的数据是存储在表空间中的,真正是在某一个或多个数据文件中。而一个表空间可以由一个或多个数据文件组成,一个数据文件著能属于一个表空间(一对多)。一旦数据文件被加入到某个表空间后,就不能删除这个文件,如果要删除某个数据文件,只能删除其所属于的表空间才行。
4、表空间
一个数据库有多个表空间
每个表空间由同一磁盘上的一个或多个文件组成,这些文件叫做数据文件。
oracle是有用户和表空间对数据进行管理和存放的。但是表不是由表空间去查询的,而是由用户去查的。因为不同用户可以在同一表空间建立同一个名字的表。这里区分就是用户了。

5、用户
用户是在表空间下建立的。用户登录后只能看到和操作自己的表,ORACLE的用户与MYSQL的数据库类似,每建立一个应用需要创建一个用户。不同用户下可以有相同名字的表。
二、ORACLE安装与配置
本地安装麻烦、卸载也麻烦,所以本文采用docker进行安装
(1)环境
虚拟机安装centos7版本的linux操作系统
安装oracle11gR2
使用docker v20.10
(2) docker下载及配置
- 下载
yum install -y docker - 开启服务
sudo systemctl start docker
sudo systemctl enable docker
sudo systemctl status docker - 配置下载加速
## 编辑文件 vim /etc/docker/daemon.json ## 填写内容,[]里的内容为阿里云容器中的,一人一个,这里是我自己的 { "registry-mirrors": ["xxx"] } ## 重启 sudo systemctl daemon-reload sudo systemctl restart docker
(3)拉取oracle镜像
docker pull registry.cn-hangzhou.aliyuncs.com/helowin/oracle_11g
(4)创建并启动容器
(4.1) 创建临时容器
docker run \
--name oracle_temp \
-p 1500:1521 \
--privileged=true \
-d \
registry.cn-hangzhou.aliyuncs.com/helowin/oracle_11g:latest
(4.2) 查找到挂载数据容器卷的位置
- 进入oracle容器
docker exec -it oracle_temp /bin/bash - 查找相关配置文件存放位置
whereis oracle
如果以上方法不行,则
- 进入oracle容器
- 输入
cd /home查找oracle里面,自己去寻找
(4.3) 继续创建临时容器
- 在宿主容器机上创建文件夹,用来安放oracle配置文件
mkdir -p /root/server/oracle/data/app/oracle/oradata
- 复制
docker cp oracle_temp:/home/oracle/app/oracle/oradata/ /root/server/oracle/data/app/oracle
- 修改挂载目录所属用户和用户组
chown -R 500:500 /root/server/oracle/data/app/oracle/oradata
(4.4) 删除临时容器
docker rm -f oracle_temp
(4.5)创建正式容器
docker run \
-d \
--name my_oracle \
-p 1521:1521 \
--privileged=true \
-v /root/server/oracle/data/app/oracle/oradata:/home/oracle/app/oracle/oradata \
registry.cn-hangzhou.aliyuncs.com/helowin/oracle_11g:latest
加了环境变量的写法(一定要根据实际情况选择加入-e)
docker run \
-d \
--name my_oracle \
-p 1521:1521 \
--privileged=true \
-e ORACLE_SID=ORCLCDB \
-e ORACLE_PDB=ORCLPDB1 \
-e ORACLE_PWD=123456 \
-e ORACLE_EDITION=standard \
-e ORACLE_CHARACTERSET=AL32UTF8 \
-v /root/server/oracle/data/app/oracle/oradata:/home/oracle/app/oracle/oradata \
registry.cn-hangzhou.aliyuncs.com/helowin/oracle_11g:latest
- docker run: 运行一个新的容器。
- -d: 以后台模式运行容器。
- -name my_oracle: 指定容器的名称为"my_oracle"。
- -p 1521:1521: 将主机的1521端口映射到容器的1521端口。这是Oracle数据库使用的默认端口。
- –privileged=true: 启用容器的特权模式,允许对主机系统进行一些特殊的操作。
- -e ORACLE_SID=ORCLCDB: 设置Oracle数据库实例的SID为"ORCLCDB"。
- -e ORACLE_PDB=ORCLPDB1: 设置Oracle数据库的PDB(Pluggable Database)名称为"ORCLPDB1"。PDB是Oracle 12c及更高版本中的一个特性,允许在单个实例中创建多个独立的数据库。
- -e ORACLE_PWD=123456: 设置Oracle数据库的管理员密码为"123456"。
- -e ORACLE_EDITION=standard: 指定Oracle数据库的版本为标准版。
- -e ORACLE_CHARACTERSET=AL32UTF8: 设置Oracle数据库的字符集为AL32UTF8,即UTF-8编码。
- -v /root/server/oracle/data/app/oracle/oradata:/home/oracle/app/oracle/oradata: 将主机上的目录"/root/server/oracle/data/app/oracle/oradata" 挂载到容器内部的目录"/home/oracle/app/oracle/oradata"。这样,容器可以访问主机上存储的数据。
(5)进入docker的oracle11g 容器
docker exec -it my_oracle bash
rm -rf /home/oracle/app/oracle/flash_recovery_area/helowin/control02.ctl.bak #删除oracle的机制文件
cp /home/oracle/app/oracle/oradata/helowin/control01.ctl /home/oracle/app/oracle/flash_recovery_area/helowin/control02.ctl #拷贝
exit;
docker restart my_oracle #重启
(6)进入容器设置
docker exec -it my_oracle bash
source ~/.bash_profile
(7)登录oracle并设置
sqlplus / as sysdba #登录sqlplus
alter user system identified by 新密码; #修改system用户账号密码
alter user sys identified by 新密码; #修改sys用户账号密码
create user test identified by test; #创建内部管理员账号密码都是test
grant connect,resource,dba to test; #将dba权限授权给内部管理员账号和密码
ALTER PROFILE DEFAULT LIMIT PASSWORD_LIFE_TIME UNLIMITED; #修改密码规则策略为密码永不过期
alter system set processes=1000 scope=spfile; #修改数据库最大连接数据
(8)创建表空间
create tablespace test
datafile '/home/oracle/app/oracle/oradata/helowin/test.dbf '
size 500m
autoextend on
next 10m
maxsize unlimited;
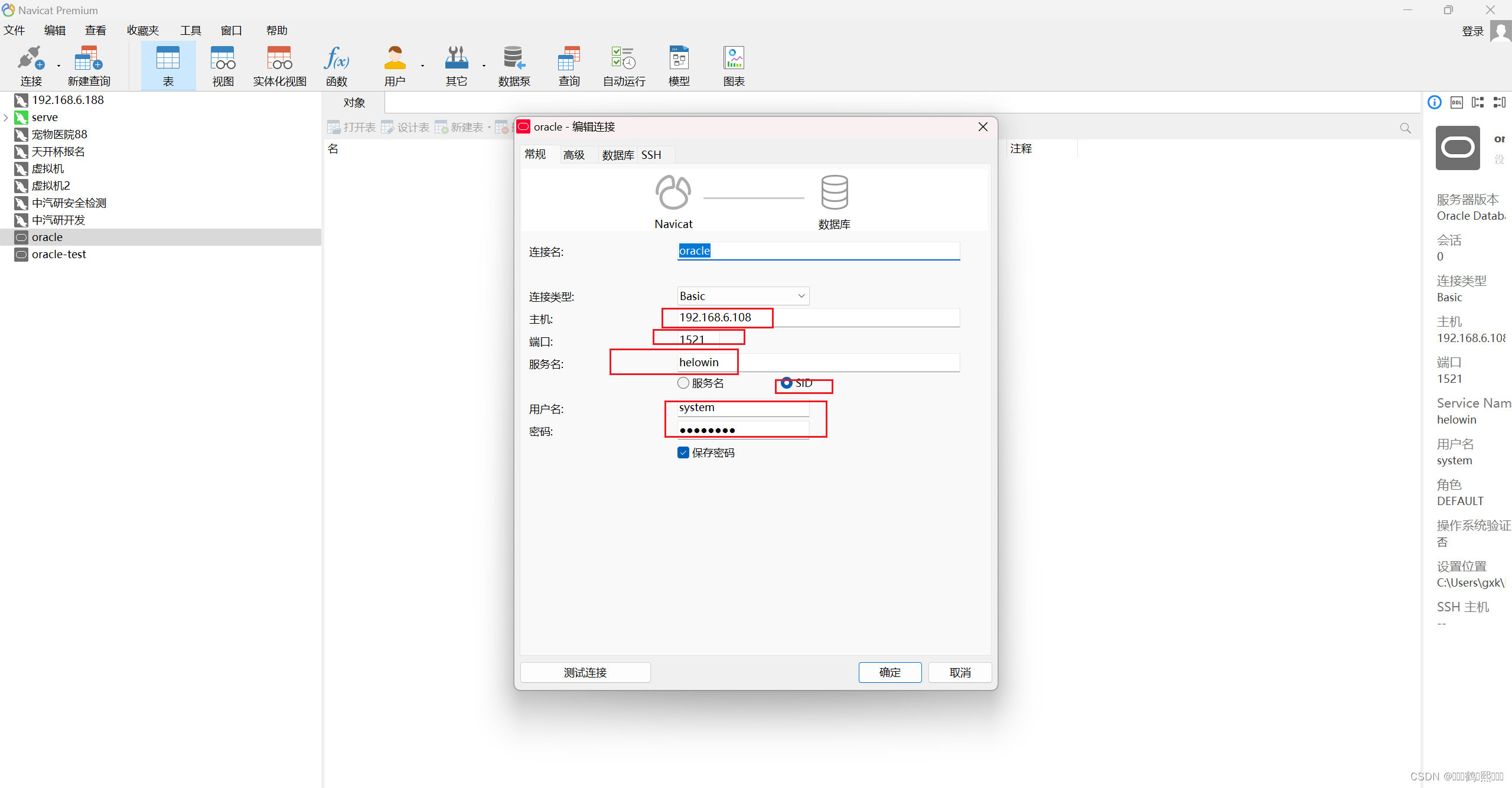
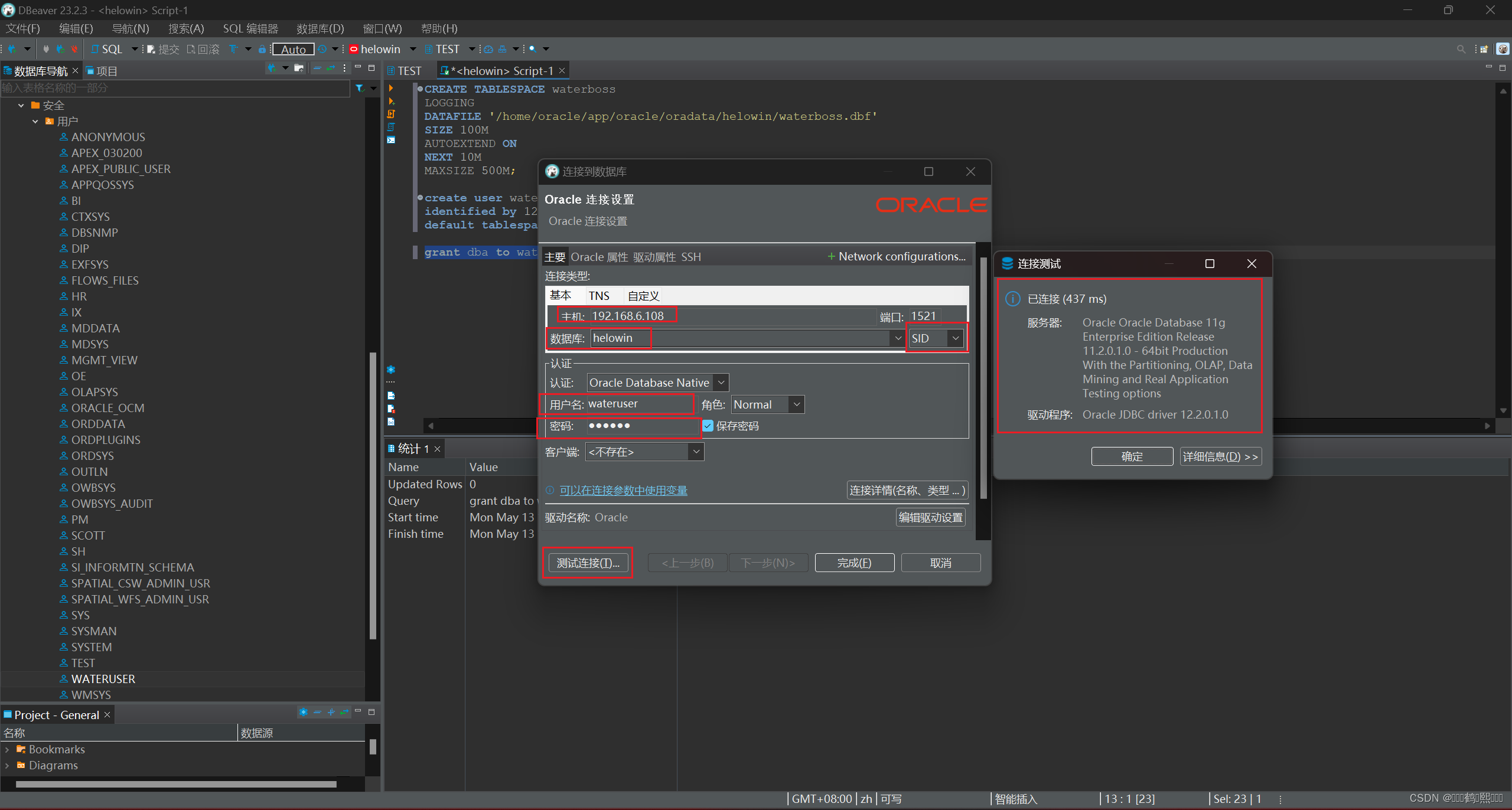
(9)使用连接工具进行验证
使用navicat或者DBeaver工具远程连接
用户名:system 密码: 123456 或者 用户名:test 密码: test
主机名: IP
端口:1521
SID: helowin
(10)中文编码设置
- 查看服务器端编码SQL:
select userenv('language') from dual

三、项目案例:《自来水公司收费系统》
(一) 项目介绍与需求分析
XXX市自来水公司为更好地对自来水收费进行规范化管理,决定委托公司开发《自来水公司收费系统》。考虑到自来水业务数量庞大,数据并发量高,决定数据库采用ORACLE数据库。主要功能包括:
1、基础信息管理:
(1)业主类型设置
(2)价格设置
(3)区域设置
(4)收费员设置
(5)地址设置
2、业主信息管理:
(1)业主信息维护
(2)业主信息查询
3、收费管理:
(1)抄表登记
(2)收费登记
(3)收费记录查询
(4)欠费用户清单
4、统计分析:
(1)收费日报单
(2)收费月报表
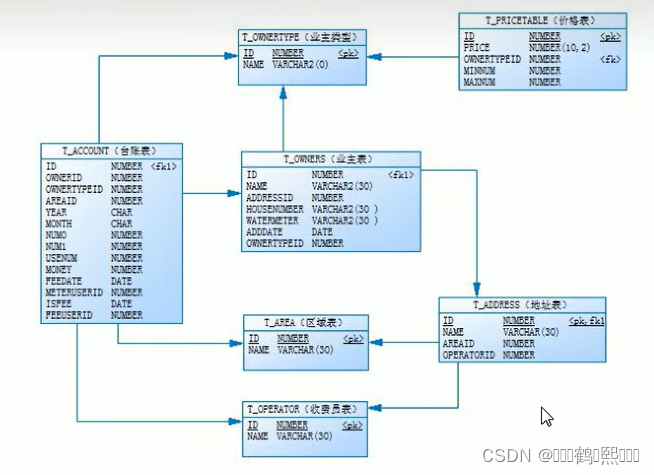
(二)表结构设计
(1)业主类型表(T_OWNERTYPE)

(2)价格表(T_PRICETABLE)

(3)区域表(T_AREA)
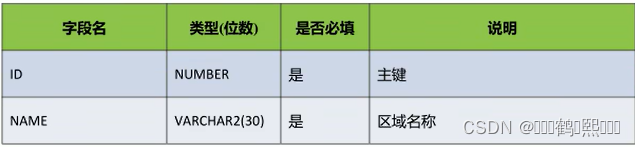
(4)收费员表(T_OPERATOR)
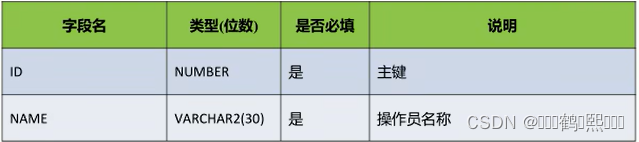
(5)地址表(T_ADDRESS)

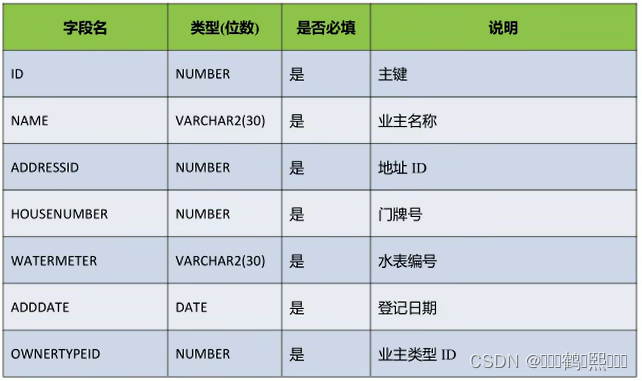
(6)业务表(T_OWNERS)
(7)收费台账(T_ACCOUNT)

上述七张表的物理模型如下:
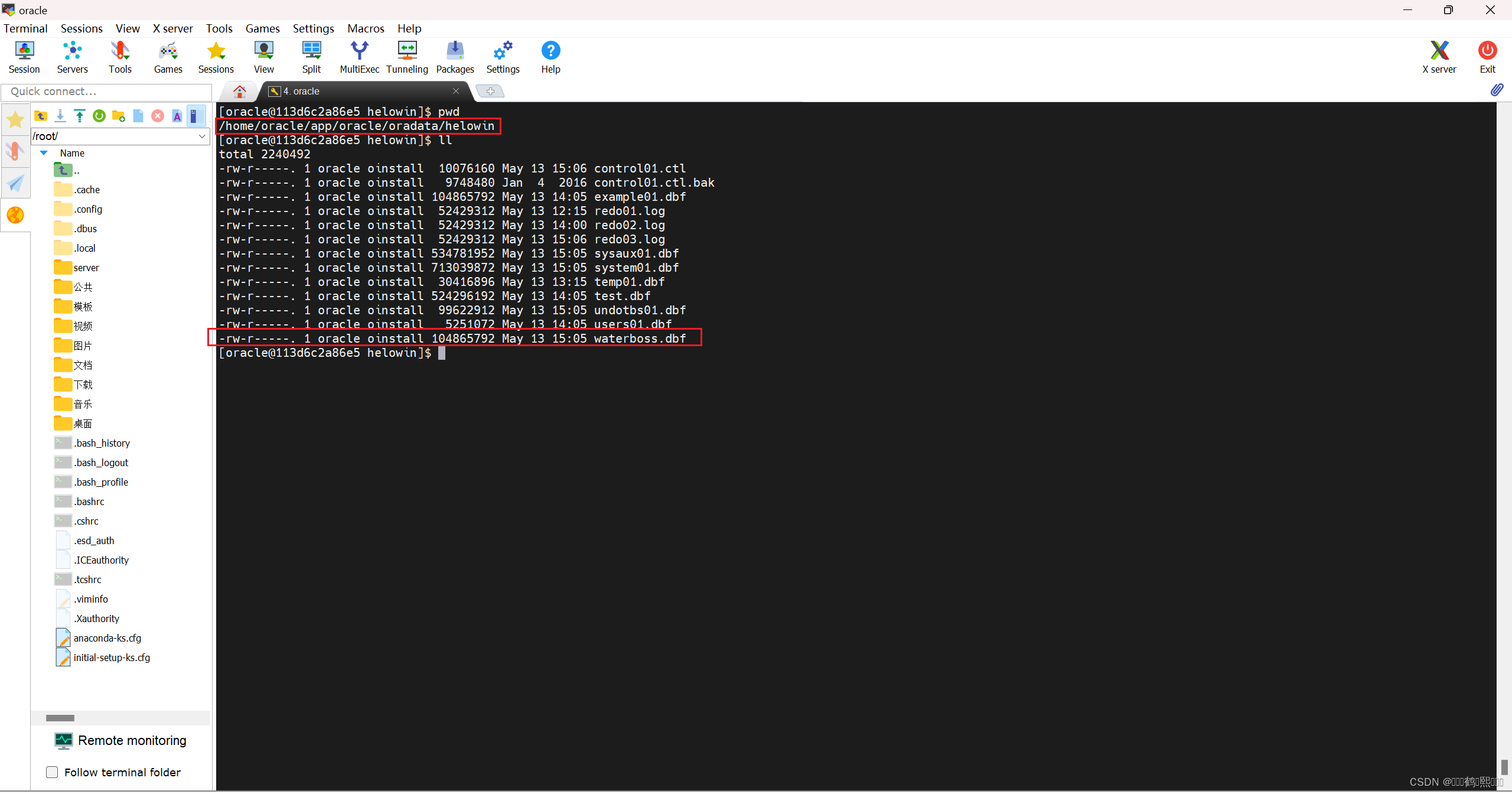
(三)创建表空间
表空间(Mysql里的数据库) -> 用户 -> 表
oracle连接的时候是以用户做连接,而不是表空间(Mysql是以连接数据库的)
CREATE TABLESPACE xxxx
LOGGING
DATAFILE '/home/oracle/app/oracle/oradata/helowin/xxx.dbf'
SIZE 100M
AUTOEXTEND ON
NEXT 10M
MAXSIZE 500M
EXTENT MANAGEMENT LOCAL;
1、CREATE TABLESPACE xxxx: 创建一个名为 “xxxx” 的表空间。
2、LOGGING: 指定该表空间启用日志记录,这意味着对该表空间中的数据更改将被记录在数据库的重做日志文件中,以支持恢复和回滚操作。
3、DATAFILE ‘/app/oracle/oradata/orcl/xxxx.dbf’: 指定该表空间的数据文件路径和名称为 ‘/app/oracle/oradata/orcl/xxxx.dbf’。数据文件是用于存储表空间中的数据的物理文件。
4、SIZE 100M: 设置数据文件的初始大小为 100MB。
5、AUTOEXTEND ON: 启用数据文件的自动扩展功能,当空间不足时,自动增加数据文件的大小以容纳更多数据。
6、NEXT 10M: 指定数据文件自动扩展时的增量大小为 10MB。当数据文件需要扩展时,会增加 10MB 的空间。
7、MAXSIZE 500M: 设置数据文件的最大大小限制为 500MB。即使自动扩展功能被启用,数据文件的大小也不会超过该限制。
8、EXTENT MANAGEMENT LOCAL: 指定表空间使用本地管理方式来管理数据块的分配。本地管理方式是一种较新的管理方式,它在表空间级别进行数据块分配,而不是在数据库级别进行分配。


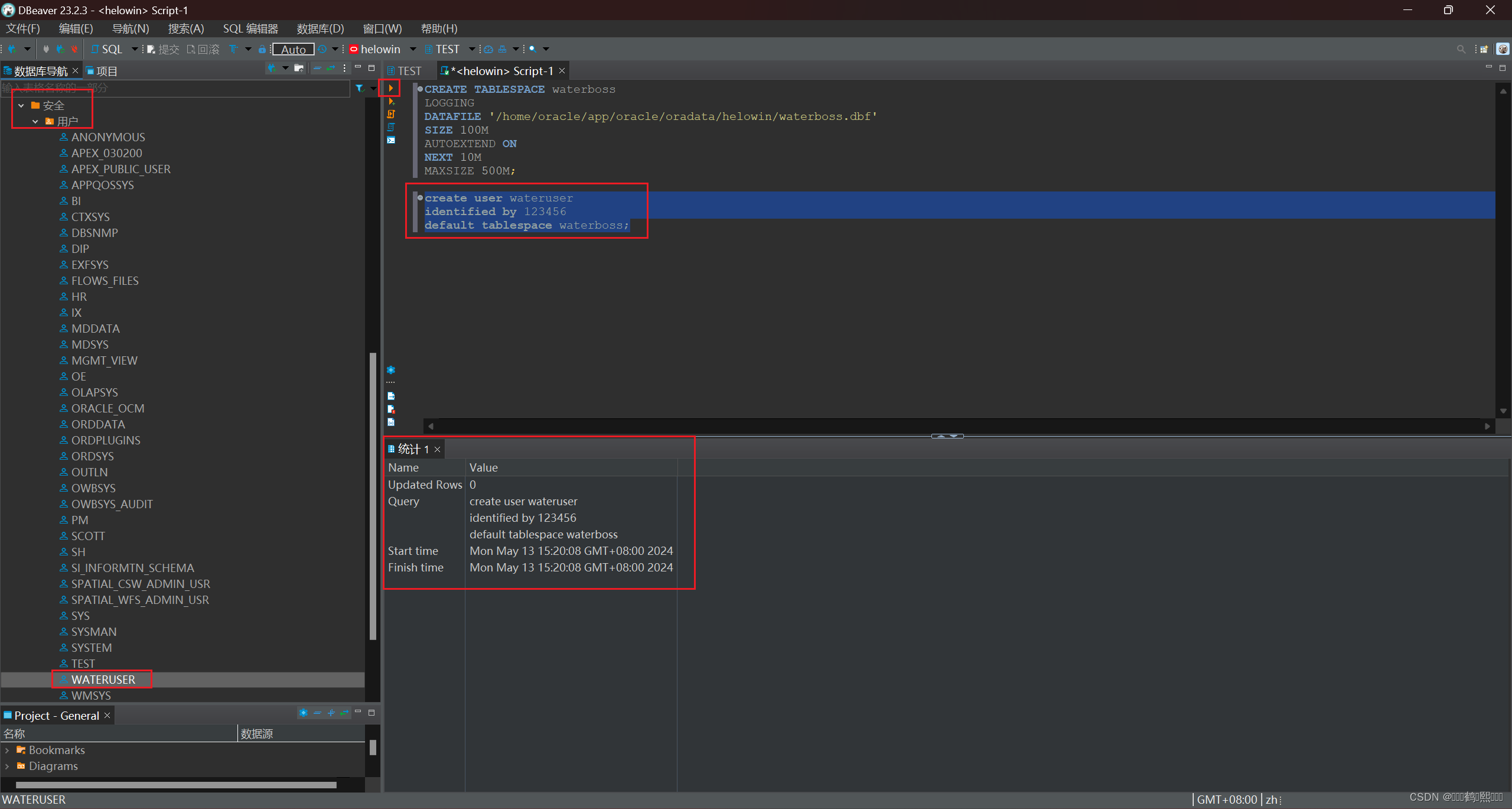
(四)创建用户
create user wateruser
identified by 123456
default tablespace waterboss;
1、CREATE USER wateruser: 创建一个名为 wateruser 的用户。
2、IDENTIFIED BY 123456: 设置该用户的密码为 123456。用户在登录时需要提供该密码进行身份验证。
3、DEFAULT TABLESPACE waterboss: 指定用户的默认表空间为 waterboss。默认表空间是用户创建对象时的默认存储位置,如果未显式指定表空间,则使用默认表空间。
(五)给指定用户赋权限
grant dba to wateruser;
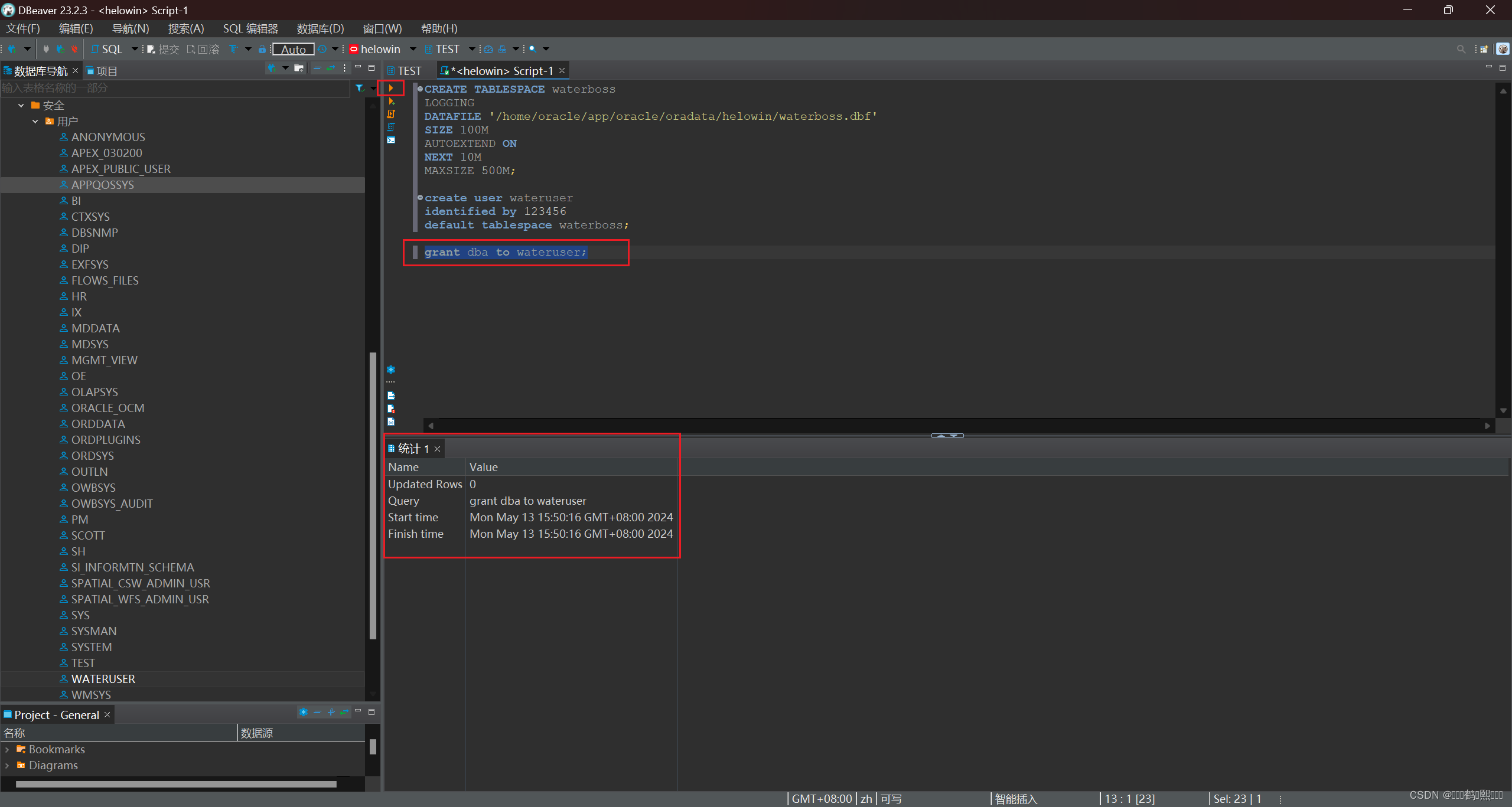
四、表的创建、修改与删除
(一)创建表
语法
CREATE TABLE 表名称(
字段名 类型(长度) primary key,
字段名 类型(长度),
......
)
数据类型
1、字符型
(1)CHAR:固定长度的字符类型,最多存储2000个字节
(2)VARCHAR2:可变长度的字符类型,最多存储4000个字节
(3)LONG:大文本类型,最多可以存储2个G
2、数值型
NUMBER:数值类型
列如:NUMBER(5) 最大可存的数为99999
---------NUMBER(5,2) 最大可存的数为999.99
3、日期型
(1)DATE:日期时间型,精确到秒
(2)TIMESTAMP:精确到秒的小数位后9位
4、二进制型(大数据类型)
(1)CLOB:存储字符,最大可以存4个G
(2)BLOB:存储图像、声音、视频等二进制数据,最多可以存4个G
实例
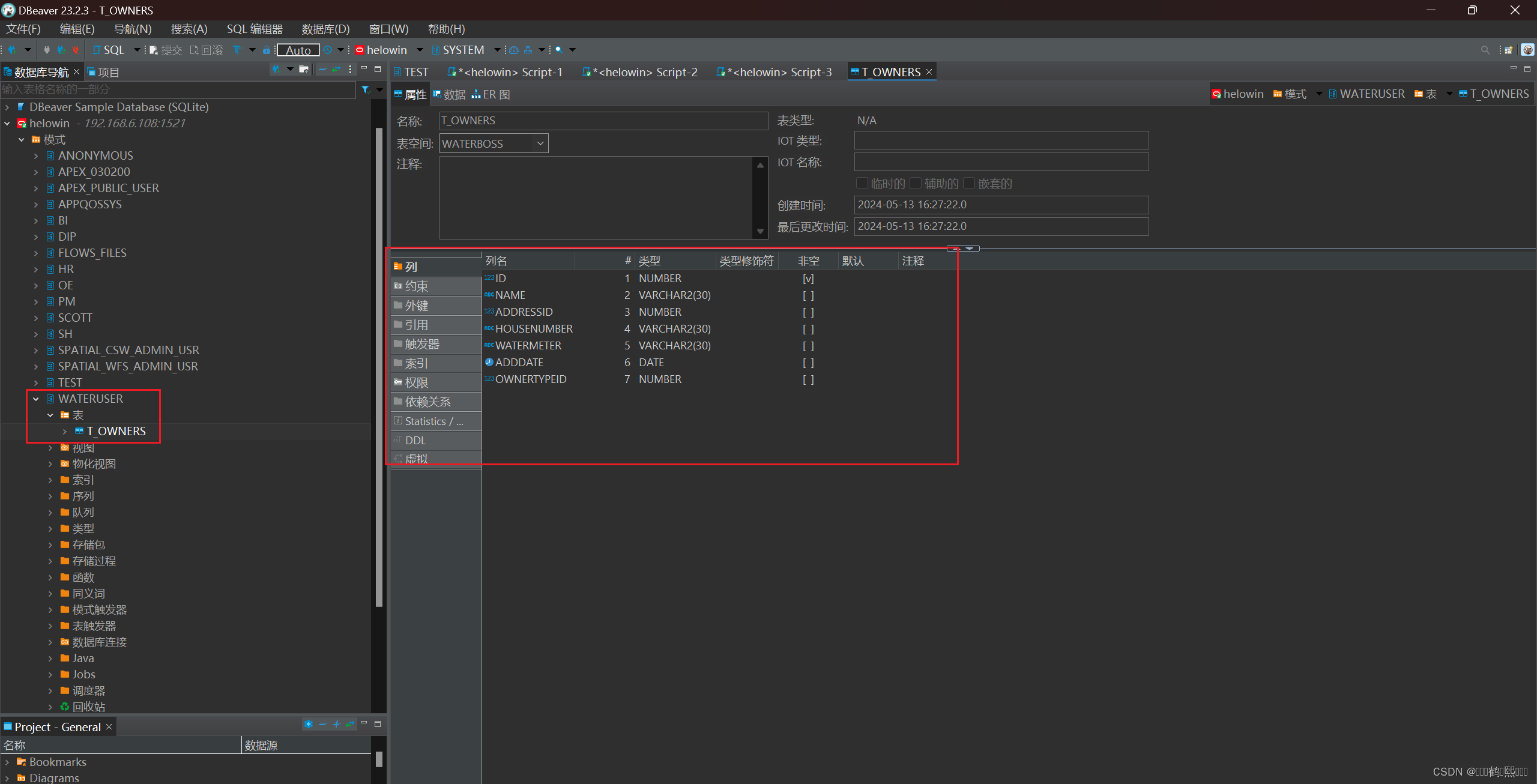
创建业主表
create table t_owners
(
id number primary key,
name varchar2(30),
addressid number,
housenumber varchar2(30),
watermeter varchar2(30),
adddate date,
ownertypeid number
);

(二) 修改表
(1)、增加字段
ALTER TABLE 表名称 ADD(列名1 类型 [DEFAULT 默认值],列名2 类型 [DEFAULT 默认值]...);
实例
ALTER TABLE T_OWNERS ADD
(
REMARK VARCHAR2(20),
OUTDATE DATE
);
(2)、修改字段(修改其数据类型)
ALTER TABLE 表名称 MODIFY(列名1 类型 [DEFAULT 默认值], 列明2 类型 [DEFAULT 默认值]...);
实例
ALTER TABLE T_OWNERS MODIFY
(
REMARK CHAR(20),
OUTDATE TIMESTAMP
);
(3)、修改字段名
ALTER TABLE 表名称 RENAME COLUMN 原列名 TO 新列名;
实例
ALTER TABLE T_OWNERS RENAME COLUMN OUTDATE TO EXITDATE;
(4)、删除字段名
ALTER TABLE 表名称 DROP COLUMN 列名1, 列名2;
实例
ALTER TABLE T_OWNERS DROP COLUMN REMARK;
(三) 删除表
DROP TABLE 表名称
五、数据增删改
(一)插入数据
INSERT INTO 表名[(列名1, 列名2, ...)] VALUES(值1, 值2, ...);
向业主表插入数据:
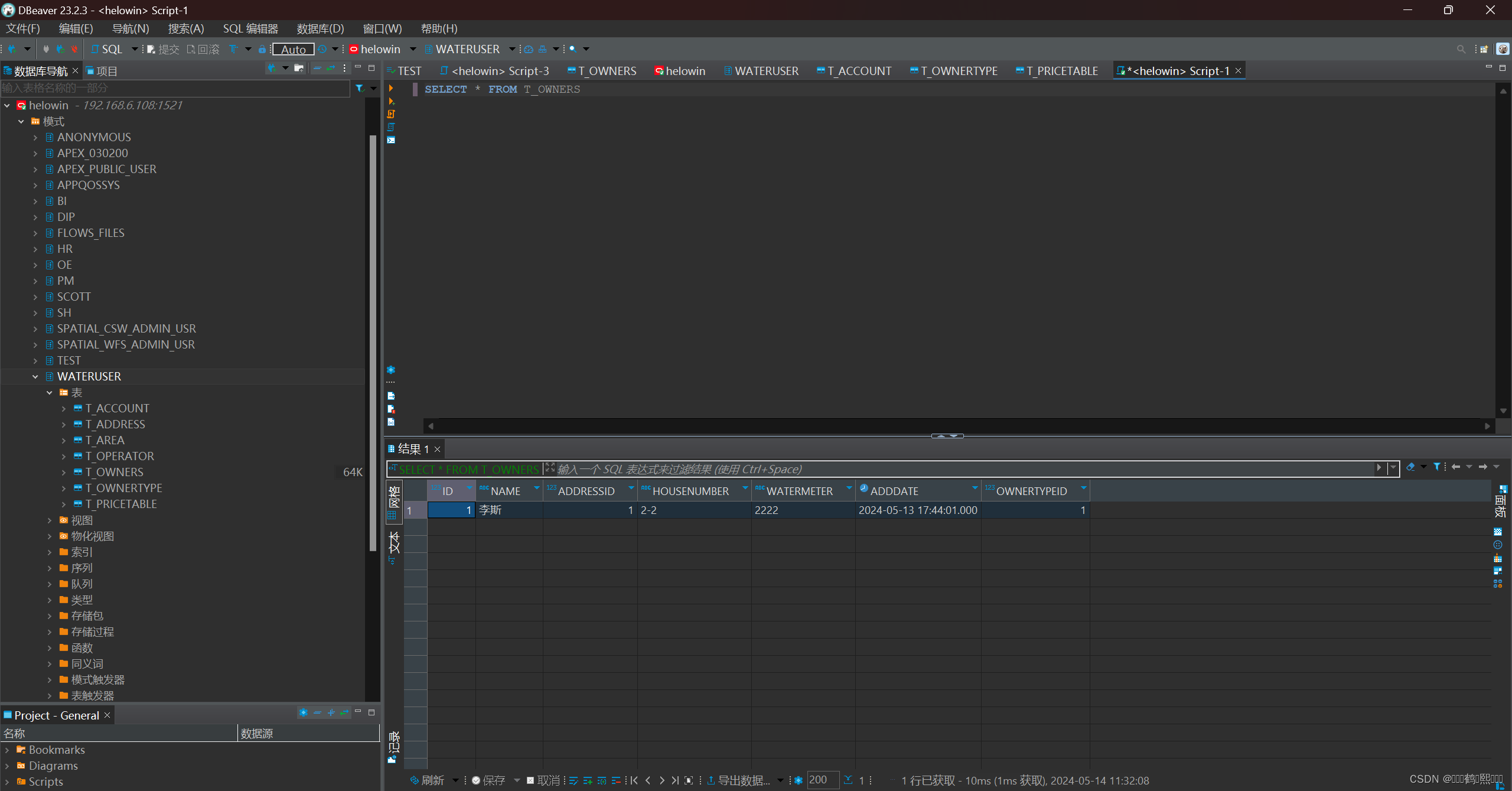
INSERT INTO T_OWNERS VALUES(1, '李斯', 2, '2-2', '2222', sysdate, 1);
(二)修改数据
UPDATE 表名 SET 列名1=值1, 列名2=值2, ...WHERE 修改条件;
需求:将ID为1的业主的登记日期更改为三天前的日期
UPDATE T_OWNERS SET adddate=adddate-3 where id=1;
(三)删除数据
DELETE FROM 表名 WHERE 删除条件;
需求:删除业主ID为2的业主信息
DELETE FROM T_OWNERS WHERE id=2;
TRUNCATE TABLE 表名称;
比较truncate与delete实现数据删除
1、delete删除的数据可以rollback
2、delete删除可能产生碎片,并且不释放空间
3、truncate是先摧毁表结构,再重构表结构
六、JDBC连接ORACLE
JDBC连接在现有项目中已经不常见了,都是框架集成,本文使用的是SpringBoot+Mybatis+druid调用oracle数据库。
若依框架集成
若依框架自带有集成多数据库方法
(1)导入oracle坐标依赖
<!--oracle-->
<dependency>
<groupId>com.oracle.database.jdbc</groupId>
<artifactId>ojdbc8</artifactId>
<version>19.3.0.0</version>
</dependency>
(2)修改application-druid.yml配置文件
注意:oracle是以用户作为账号、密码进行连接
# 数据源配置
spring:
datasource:
type: com.alibaba.druid.pool.DruidDataSource
druid:
# 主库数据源
master:
url: jdbc:mysql://127.0.0.1:3306/ry-vue?useUnicode=true&characterEncoding=utf8&zeroDateTimeBehavior=convertToNull&useSSL=true&serverTimezone=GMT%2B8
username: root
password: 111111
# 从库数据源
slave:
# 从数据源开关/默认关闭
enabled: true
url: jdbc:oracle:thin:@//192.168.6.108:1521/helowin
username: wateruser
password: 123456
# 初始连接数
initialSize: 5
# 最小连接池数量
minIdle: 10
# 最大连接池数量
maxActive: 20
# 配置获取连接等待超时的时间
maxWait: 60000
# 配置连接超时时间
connectTimeout: 30000
# 配置网络超时时间
socketTimeout: 60000
# 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒
timeBetweenEvictionRunsMillis: 60000
# 配置一个连接在池中最小生存的时间,单位是毫秒
minEvictableIdleTimeMillis: 300000
# 配置一个连接在池中最大生存的时间,单位是毫秒
maxEvictableIdleTimeMillis: 900000
# 配置检测连接是否有效
validationQuery: SELECT 1 FROM DUAL
testWhileIdle: true
testOnBorrow: false
testOnReturn: false
webStatFilter:
enabled: true
statViewServlet:
enabled: true
# 设置白名单,不填则允许所有访问
allow:
url-pattern: /druid/*
# 控制台管理用户名和密码
login-username: ruoyi
login-password: 123456
filter:
stat:
enabled: true
# 慢SQL记录
log-slow-sql: true
slow-sql-millis: 1000
merge-sql: true
wall:
config:
multi-statement-allow: true
(3)新建返回VO类、Controller层、Service层
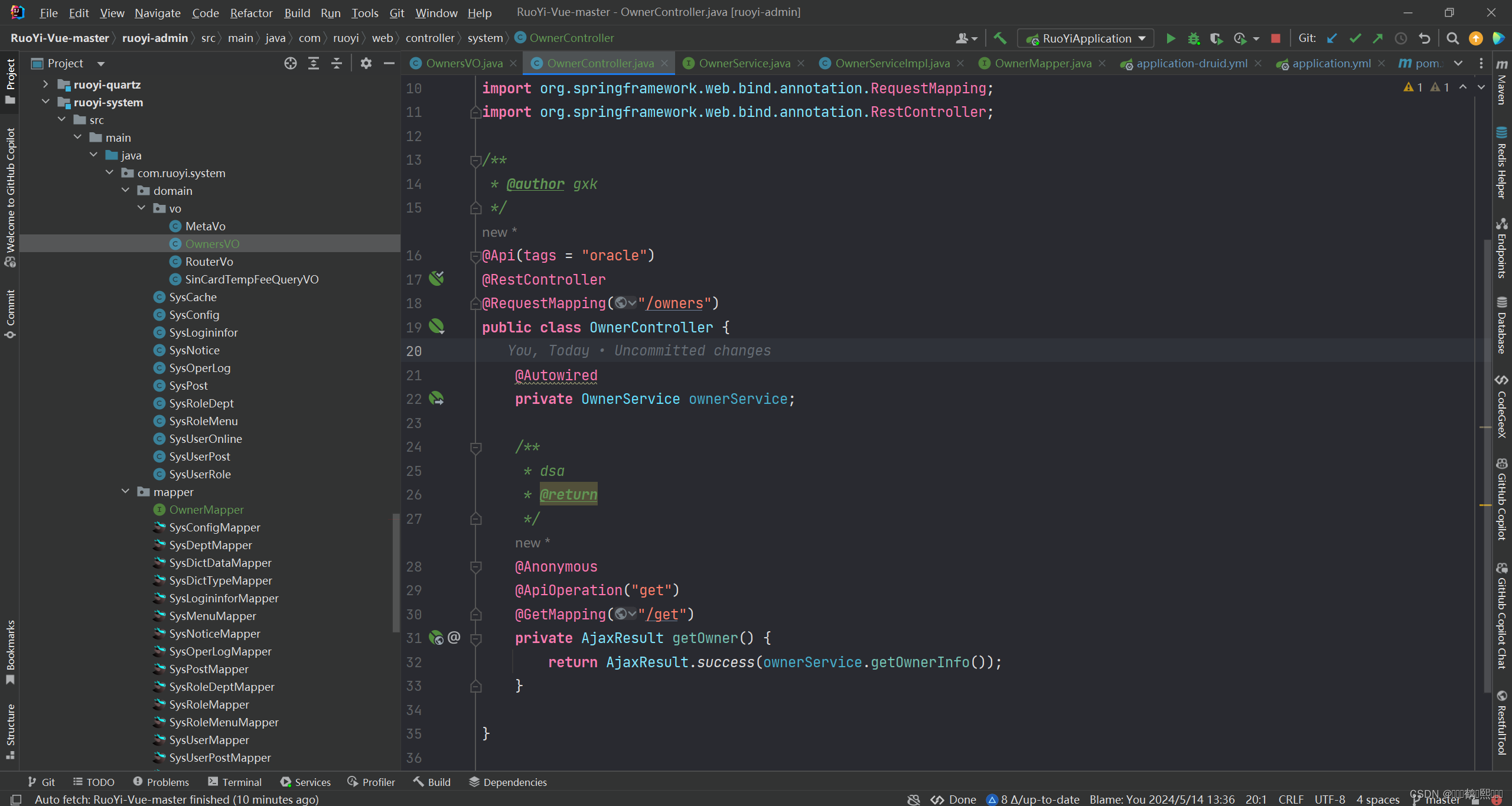
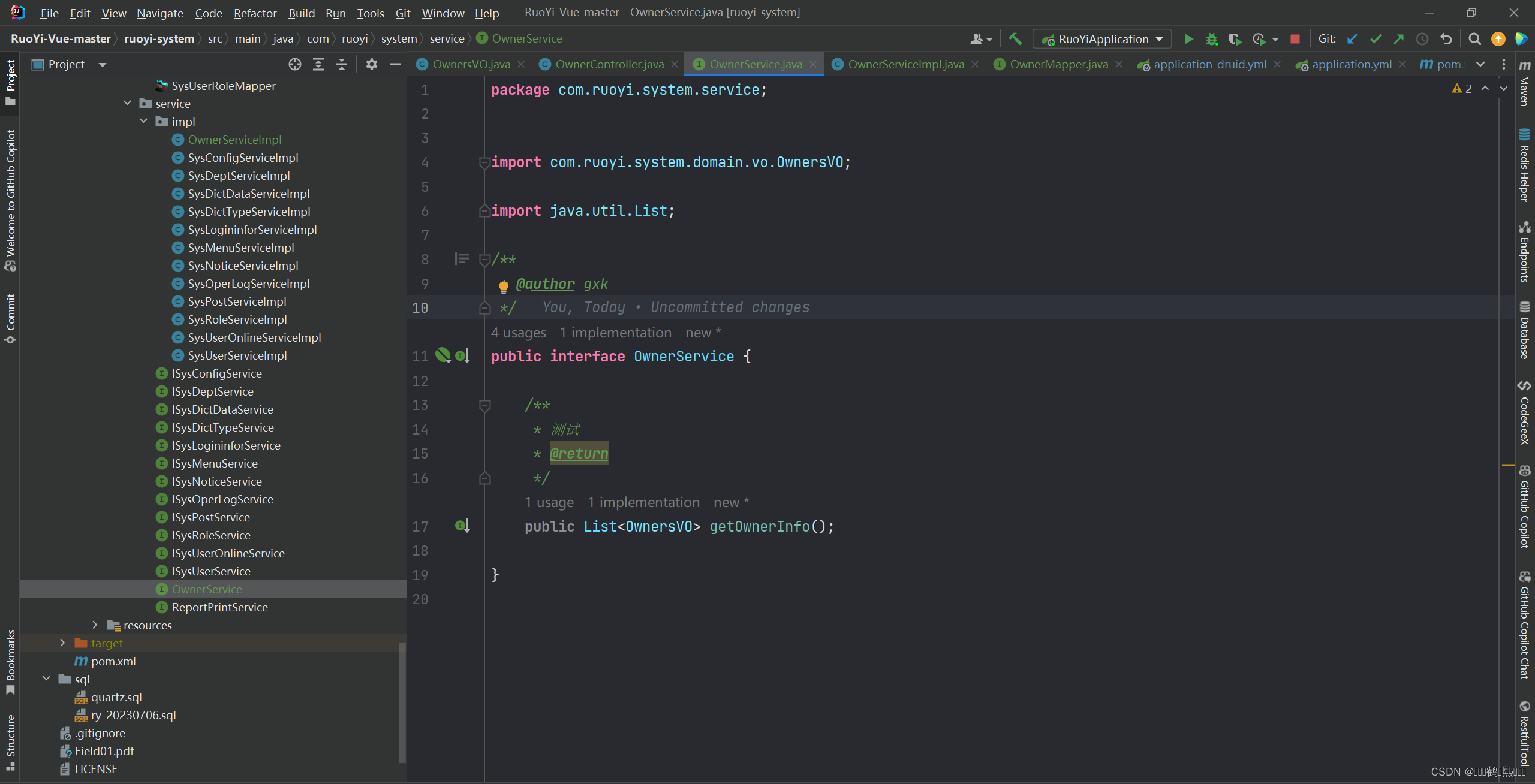
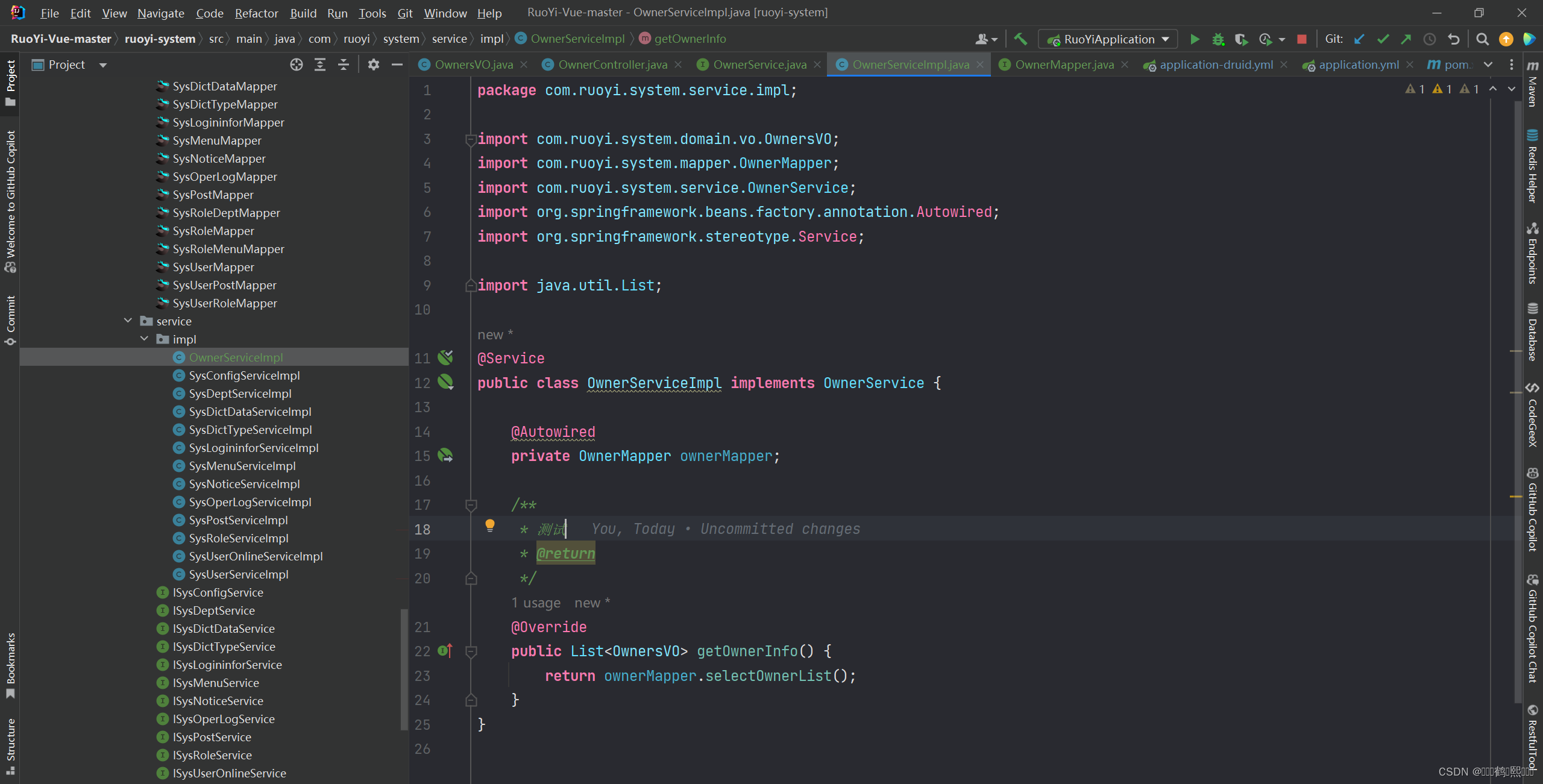
(3)在实现类XxImpl.java或者Xxmapper.java中添加注解
@DataSource(value = DataSourceType.SLAVE)

(4)结果

七、数据导出与导入
场景:测试库向生产库的一个数据迁移
(一) 整库的导出与导入(一般不使用)
一下所有的用户名/密码都默认写system和其密码,可以理解为最高权限
导出
exp 用户名/密码 full=y file=xxx.dmp
file=xxx.dmp是指定导出文件名,可写可不写
实例
exp system/123456 full=y file=water.dmp
导入
imp 用户名/密码 full=y file=xxx.dmp
实例
imp system/123456 full=y file=water.dmp
(二)按用户导出与导入
(1)、按用户导出
exp 用户名/密码 owner=wateruser file=xxx.dmp
实例
exp system/123456 owner=wateruser file=water.dmp
(2)、按用户导入
imp 用户名/密码 file=xxx.dmp fromuser=需要导入的用户名
实例
imp system/123456 file=water.dmp fromuser=wateruser
(三) 按表导出与导入
(1)、按表导出
exp 表的所在用户/密码 file=xxx.dmp tables=表名1, 表名2
实例
exp wateruser/123456 file=water.dmp tables=t_account, t_area
(2)、按表导入
imp 表的所在用户/密码 file=water.dmp tables=表名1, 表名2